Curso
Colocando IA em Produção com FastAPI
4 h
4.5K
O GPT-OSS ( ) é a primeira série de modelos de peso aberto da OpenAI, e você pode rodá-lo direto no seu computador. Feito pra raciocínio poderoso, tarefas de agência e casos de uso flexíveis pra desenvolvedores, o GPT-OSS se destaca pelo esforço de raciocínio configurável e recursos transparentes de cadeia de pensamento.
Neste tutorial, vou te mostrar como configurar os modelos GPT-OSS da OpenAI localmente usando o Ollama e demonstrar como criar uma demonstração interativa que mostra as capacidades únicas de raciocínio do modelo. Vamos dar uma olhada nas funcionalidades configuráveis da cadeia de pensamento do modelo e criar um aplicativo Streamlit que mostra o processo de raciocínio do modelo.
A gente mantém nossos leitores por dentro das últimas novidades em IA com o The Median, nosso boletim informativo gratuito que sai toda sexta-feira e traz as principais notícias da semana. Inscreva-se e fique por dentro em só alguns minutos por semana:
A série GPT-OSS da OpenAI é o primeiro lançamento de peso aberto desde o GPT-2, permitindo acesso a modelos de raciocínio de alto desempenho sob a licença Apache 2.0. Esses modelos de linguagem de última geração oferecem um ótimo desempenho por um preço baixo e são melhores do que modelos abertos de tamanho parecido em tarefas de raciocínio.
Tem duas versões: gpt-oss-120b e gpt-oss-20b.

Fonte: OpenAI
O gpt-oss-120b é o principal modelo de peso aberto da OpenAI, com desempenho que compete com sistemas proprietários como o o4‑mini em benchmarks de raciocínio complexos. Mesmo com 117 bilhões de parâmetros, ele foi feito pra rodar em uma única GPU de 80 GB. Isso torna essa opção realista para laboratórios de pesquisa e equipes empresariais que querem hospedar modelos de linguagem poderosos localmente.
O modelo foi feito pra dar suporte a fluxos de trabalho complexos, como o uso de ferramentas, raciocínio em várias etapas e controle detalhado sobre quanto esforço de “pensamento” é necessário pra cada tarefa. Sua natureza de peso aberto e licença Apache 2.0 fazem dele uma escolha flexível para equipes que querem inspecionar, personalizar ou ajustar o modelo em detalhes.
O gpt-oss-20b tem uma capacidade de raciocínio incrível em um tamanho que cabe nos laptops comuns. Com só 21 bilhões de parâmetros no total, ainda é melhor que o o3-mini da OpenAI. o3-mini em alguns benchmarks e funciona bem em aparelhos com 16 GB de memória. É quantizado e preparado para uma rápida implantação local, além de ser compatível com ferramentas como Ollama, vLLMe até mesmo a plataforma Metal da Apple.
Esse modelo é ideal para desenvolvedores que querem criar aplicativos de IA responsivos e privados sem depender da infraestrutura em nuvem. Assim como o seu irmão maior, ele dá suporte a profundidade de raciocínio ajustável e etapas intermediárias claras — ótimo para experimentos, assistentes leves e aplicativos de dispositivos de ponta dispositivos de ponta.
Executar o GPT-OSS localmente oferece várias vantagens atraentes em relação às alternativas baseadas em nuvem:
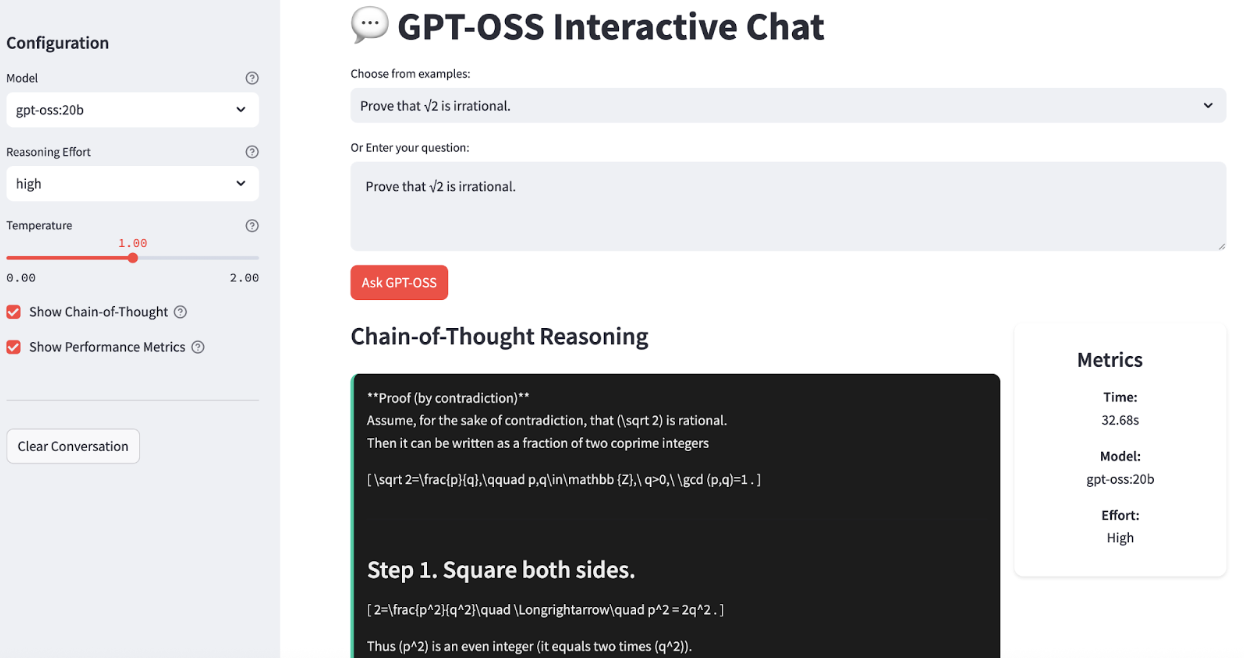
O Ollama facilita muito a execução local de grandes modelos de linguagem, cuidando dos downloads, da quantização e da execução. Vou te ajudar passo a passo a configurar o GPT-OSS no seu sistema. No final, nosso aplicativo vai ficar assim:
Primeiro, baixa e instala o Ollama no site oficial.
Depois de instalar, dá pra conferir se tá tudo certo abrindo um terminal e digitando:
ollama --versionIsso vai mostrar a versão mais recente do Ollama que tá instalada no seu sistema.
A OpenAI oferece duas versões do GPT-OSS que são ótimas para diferentes casos de uso, mas, pra essa demonstração, vamos usar só a versão gpt-oss-20b:
# For production and high reasoning tasks
ollama pull gpt-oss:120b
# For lower latency and local deployment
ollama pull gpt-oss:20bO modelo 20B é ideal para desenvolvimento local e pode funcionar em sistemas com 16 GB ou mais de memória, enquanto o modelo 120B oferece mais recursos, mas precisa de 80 GB ou mais de memória.
Vamos ver se tá tudo certo:
ollama run gpt-oss:20bVocê deve ver uma mensagem onde pode interagir diretamente com o modelo. Tenta perguntar: “Mostra que √2 é irracional.”
Agora vamos criar rapidamente um aplicativo simples que mostra as capacidades de raciocínio do GPT-OSS. Nosso aplicativo vai ter:
Execute os comandos a seguir para instalar as dependências necessárias:
pip install streamlit ollamaO trecho de código acima instala o Streamlit para criar a interface web e o cliente Python Ollama para interagir com o modelo GPT-OSS local.
Antes de mergulharmos na lógica central do chat, precisamos reunir todas as ferramentas e configurar nossa interface de usuário.
import streamlit as st
import json
import ollama
import time
from typing import Dict, Any, List
import re
from datetime import datetime
# Configure page
st.set_page_config(
page_title="GPT-OSS Chat Demo",
layout="wide",
page_icon="💬"
)
# Custom CSS for UI
st.markdown("""
<style>
.reasoning-box {
background-
border-radius: 10px;
border-left: 4px solid #00d4aa;
}
.answer-box {
background-
border-radius: 10px;
border-left: 4px solid #007bff;
}
.metric-card {
background-
border-radius: 10px;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
text-align: center;
}
.chat-message {
border-radius: 10px;
}
.user-message {
background-
border-left: 4px solid #2196f3;
}
.assistant-message {
background-
border-left: 4px solid #9c27b0;
}
</style>
""", unsafe_allow_html=True)Importamos alguns pacotes essenciais, como Streamlit para nossa interface web, Ollama para chamar o modelo GPT-OSS local, junto com módulos utilitários como json, time, typing e re. Depois, usamos st.set_page_config() pra dar um título pra página, um layout amplo e um ícone, e colocamos um CSS leve pra que as etapas do raciocínio e as respostas apareçam em painéis diferentes.
Com nossa estrutura de interface do usuário pronta, vamos criar nossa função principal de integração do modelo e call_model():
def call_model(messages: List[Dict], model_name: str = "gpt-oss:20b", temperature: float = 1.0) -> Dict[str, Any]:
try:
start_time = time.time()
# Prepare options for Ollama
options = {
'temperature': temperature,
'top_p': 1.0,
}
response = ollama.chat(
model=model_name,
messages=messages,
options=options
)
end_time = time.time()
if isinstance(response, dict) and 'message' in response:
content = response['message'].get('content', '')
elif hasattr(response, 'message'):
content = getattr(response.message, 'content', '')
else:
content = str(response)
return {
'content': content,
'response_time': end_time - start_time,
'success': True
}
except Exception as e:
return {
'content': f"Error: {e}",
'response_time': 0,
'success': False
}O código acima:
start_time e end_time em torno da chamada ollama.chat() para informar os tempos de resposta ao usuário.call_model() ” coloca toda a chamada dentro de um bloco “ try/except ” pra pegar erros.Pra deixar nossa demonstração bem transparente, precisamos separar o “monólogo interno” do modelo do seu veredicto final. A função ` parse_reasoning_response() ` faz exatamente isso:
def parse_reasoning_response(content: str) -> Dict[str, str]:
patterns = [
r"<thinking>(.*?)</thinking>",
r"Let me think.*?:(.*?)(?=\n\n|\nFinal|Answer:)",
r"Reasoning:(.*?)(?=\n\n|\nAnswer:|\nConclusion:)",
]
reasoning = ""
answer = content
for pat in patterns:
m = re.search(pat, content, re.DOTALL | re.IGNORECASE)
if m:
reasoning = m.group(1).strip()
answer = content.replace(m.group(0), "").strip()
break
if not reasoning and len(content.split('\n')) > 3:
lines = content.split('\n')
for i, l in enumerate(lines):
if any(k in l.lower() for k in ['therefore', 'in conclusion', 'final answer', 'answer:']):
reasoning = '\n'.join(lines[:i]).strip()
answer = '\n'.join(lines[i:]).strip()
break
return {
'reasoning': reasoning or "No explicit reasoning detected.",
'answer': answer or content
}A gente separa o “pensamento” oculto do modelo do seu veredicto final para que os usuários possam, se quiserem, dar uma olhada em cada etapa do raciocínio. Veja como a resposta é analisada:
… Primeiro, o modelo procura por tags ou frases de raciocínio, como “Raciocínio:” e “Deixe-me pensar”, usando expressões regulares.parse_reasoning_response() ” sempre dá uma resposta.Agora que já criamos cada bloco, vamos juntar tudo em um aplicativo de chat interativo.
# Initialize history
if 'history' not in st.session_state:
st.session_state.history = []
# Sidebar for settings
with st.sidebar:
st.header("Configuration")
model_choice = st.selectbox(
"Model",
["gpt-oss:20b", "gpt-oss:120b"],
help="Choose between 20B (faster) or 120B (more capable)"
)
effort = st.selectbox(
"Reasoning Effort",
["low", "medium", "high"],
index=1,
help="Controls depth of reasoning shown"
)
temperature = st.slider(
"Temperature",
0.0, 2.0, 1.0, 0.1,
help="Controls response randomness"
)
show_reasoning = st.checkbox(
"Show Chain-of-Thought",
True,
help="Display model's thinking process"
)
show_metrics = st.checkbox(
"Show Performance Metrics",
True,
help="Display response time and model info"
)
st.markdown("---")
if st.button("Clear Conversation"):
st.session_state.history = []
st.rerun()
# Main Chat Interface
st.title("💬 GPT-OSS Interactive Chat")
examples = [
"",
"If a train travels 120km in 1.5 hours, then 80km in 45 minutes, what's its average speed?",
"Prove that √2 is irrational.",
"Write a function to find the longest palindromic substring.",
"Explain quantum entanglement in simple terms.",
"How would you design a recommendation system?",
]
selected_from_dropdown = st.selectbox("Choose from examples:", examples)
# Get the question text
question_value = ""
if hasattr(st.session_state, 'selected_example'):
question_value = st.session_state.selected_example
del st.session_state.selected_example
elif selected_from_dropdown:
question_value = selected_from_dropdown
question = st.text_area(
"Or Enter your question:",
value=question_value,
height=100,
placeholder="Ask anything! Try different reasoning effort levels to see how the model's thinking changes..."
)
# Submit button
col1, col2 = st.columns([1, 4])
with col1:
submit_button = st.button("Ask GPT-OSS", type="primary")
if submit_button and question.strip():
# System prompts
system_prompts = {
'low': 'You are a helpful assistant. Provide concise, direct answers.',
'medium': f'You are a helpful assistant. Show brief reasoning before your answer. Reasoning effort: {effort}',
'high': f'You are a helpful assistant. Show complete chain-of-thought reasoning step by step. Think through the problem carefully before providing your final answer. Reasoning effort: {effort}'
}
# Message history
msgs = [{'role': 'system', 'content': system_prompts[effort]}]
msgs.extend(st.session_state.history[-6:])
msgs.append({'role': 'user', 'content': question})
with st.spinner(f"GPT-OSS thinking ({effort} effort)..."):
res = call_model(msgs, model_choice, temperature)
if res['success']:
parsed = parse_reasoning_response(res['content'])
st.session_state.history.append({'role': 'user', 'content': question})
st.session_state.history.append({'role': 'assistant', 'content': res['content']})
col1, col2 = st.columns([3, 1] if show_metrics else [1])
with col1:
if show_reasoning and parsed['reasoning'] != 'No explicit reasoning detected.':
st.markdown("### Chain-of-Thought Reasoning")
st.markdown(f"<div class='reasoning-box'>{parsed['reasoning']}</div>", unsafe_allow_html=True)
st.markdown("### Answer")
st.markdown(f"<div class='answer-box'>{parsed['answer']}</div>", unsafe_allow_html=True)
if show_metrics:
with col2:
st.markdown(f"""
<div class="metric-card">
<h4> Metrics</h4>
<p><strong>Time:</strong><br>{res['response_time']:.2f}s</p>
<p><strong>Model:</strong><br>{model_choice}</p>
<p><strong>Effort:</strong><br>{effort.title()}</p>
</div>
""", unsafe_allow_html=True)
else:
st.error(f"{res['content']}")
if st.session_state.history:
st.markdown("---")
st.subheader("Conversation History")
recent_history = st.session_state.history[-8:] # Last 8 messages (4 exchanges)
for i, msg in enumerate(recent_history):
if msg['role'] == 'user':
st.markdown(f"""
<div class="chat-message user-message">
<strong>You:</strong> {msg['content']}
</div>
""", unsafe_allow_html=True)
else:
parsed_hist = parse_reasoning_response(msg['content'])
with st.expander(f"GPT-OSS Response", expanded=False):
if parsed_hist['reasoning'] != 'No explicit reasoning detected.':
st.markdown("**Reasoning Process:**")
st.code(parsed_hist['reasoning'], language='text')
st.markdown("**Final Answer:**")
st.markdown(parsed_hist['answer'])
# Footer
st.markdown("---")
st.markdown("""
<div style='text-align: center;'>
<p><strong>Powered by GPT-OSS-20B via Ollama</strong></p>
</div>
""", unsafe_allow_html=True)Nessa etapa final, juntamos todas as partes do nosso aplicativo, incluindo o estado da sessão, os controles da barra lateral, os prompts de exemplo, a montagem de mensagens, a invocação do modelo, a análise e a exibição em um único loop:
st.session_state.history pra lembrar de todas as interações entre usuários e assistentes em repetições.call_model(), que:parse_reasoning_response() ”, dividimos a saída do modelo em uma resposta em cadeia de pensamentos chamada “raciocínio” e uma resposta limpa chamada “resposta”.st.session_state.history, para que a próxima execução inclua essas informações para contextualização.Para experimentar, salva o código como gpt_oss_demo.py e abre:
streamlit run gpt_oss_demo.pyAprenda IA com esses cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
Tutorial
Tutorial
Moez Ali
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Moez Ali



