
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Les grands modèles de langage (LLM) sont devenus très importants pour le développement de modèles d'apprentissage automatique, en particulier pour améliorer les capacités des algorithmes de traitement du langage naturel. Des chatbots aux générateurs de contenu, ces modèles transforment la manière dont nous interagissons avec la technologie.
Cependant, à mesure que la présence des LLM augmente en nombre et en complexité, l'évaluation de leurs performances devient plus importante. Sans une évaluation appropriée et précise, il est difficile de savoir si un modèle fonctionne comme prévu ou s'il nécessite des ajustements.
C'est là que MLflow intervient. MLflow est un outil open-source conçu pour faciliter la gestion des expériences d'apprentissage automatique. Il nous aide à suivre les résultats des différentes expériences, à gérer les modèles et à tout organiser !
Dans ce tutoriel, nous allons explorer le rôle de MLflow dans l'amélioration des flux de travail LLM. Je vous guiderai à travers sa configuration et vous montrerai comment enregistrer les métriques et suivre les paramètres dans les expériences LLM. Enfin, nous verrons comment MLflow permet une gestion et un déploiement efficaces des modèles.
MLflow est une plateforme open-source conçue pour gérer le cycle de vie de l'apprentissage automatique de bout en bout. Il fournit des outils pour rationaliser le processus de développement, de cursus et de déploiement des modèles d'apprentissage automatique.
Que nous travaillions sur un petit projet ou que nous gérions des expériences complexes avec de grands modèles, MLflow peut nous aider à rester organisés et efficaces.
Voici quelques-uns des avantages de l'utilisation de MLflow dans le cycle de vie de l'apprentissage automatique :
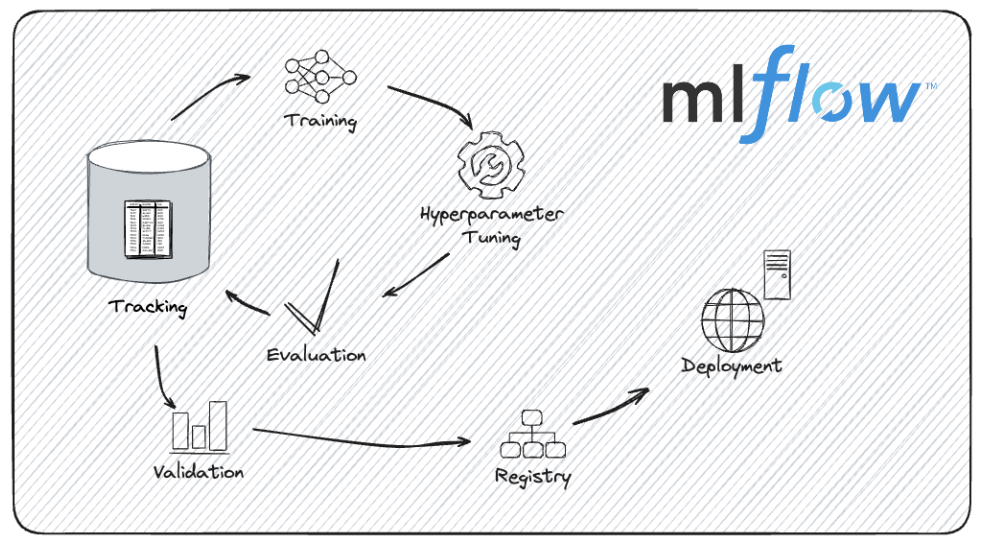
Le cycle de vie du développement de modèles avec MLflow. Source de l'image : Documentation MLflow.
MLflow est conçu pour faciliter la gestion des projets d'apprentissage automatique et la rendre plus transparente. Ceci est particulièrement utile lorsque vous travaillez avec des modèles complexes tels que les LLM, comme nous allons le voir maintenant.
L'utilisation de MLflow pour l'évaluation du LLM présente plusieurs avantages, tels que le cursus des versions du modèle, l'enregistrement des métriques d'évaluation et la comparaison des performances entre les champs.
Voyons ces avantages plus en détail.
Le développement des MLD implique des itérations et des améliorations fréquentes. Chaque nouvelle version apporte de petites améliorations ou des changements de comportement. MLflow gère ces différentes itérations en effectuant un cursus systématique des versions du modèle. Cette capacité nous permet de reproduire les résultats, de comparer efficacement les différentes versions et de conserver un historique clair de l'évolution du modèle.
Disons que nous expérimentons différentes techniques de mise au point; MLflow peut nous aider à gérer et à examiner les résultats de chaque version, ce qui facilite l'identification de l'itération qui donne les meilleures performances.
Parce que MLflow garantit que chaque expérience et ses résultats associés sont enregistrés de manière exhaustive, nous pouvons partager nos résultats en toute confiance, en sachant que d'autres peuvent les reproduire exactement.
Si notre projet implique l'expérimentation de différentes architectures LLM ou méthodologies de formation, les capacités de suivi de MLflow faciliteront la documentation et le partage de notre travail.
L'évaluation des LLM implique le contrôle de plusieurs paramètres, tels que la précision, la perplexité et le score F1, entre autres.
La fonctionnalité de journalisation de MLflow nous permet d'enregistrer ces mesures de manière efficace et organisée. L'analyse de ces paramètres nous donne une bonne idée de la performance de notre modèle.
Par exemple, nous pourrions vouloir comparer la façon dont différents hyperparamètres ou ensembles de données d'entraînement affectent les mesures de performance du modèle. Avec MLflow, nous pouvons enregistrer et visualiser ces mesures pour en tirer des informations exploitables.
Au fur et à mesure que les modèles sont déployés et utilisés dans des applications réelles, ils peuvent subir une dérive, c'est-à-dire que leurs performances se dégradent en raison de changements dans les données ou l'environnement. Nous pouvons tirer parti de MLflow pour surveiller et gérer la dérive des modèles en suivant leur performance au fil du temps.
Nous pouvons mettre en place des évaluations régulières et utiliser MLflow pour enregistrer et analyser l'évolution des mesures de performance, afin de prendre des décisions concrètes en temps réel.
L'un des principaux avantages de MLflow est sa capacité à simplifier les comparaisons de modèles. En stockant des enregistrements détaillés de différentes expériences, MLflow nous permet de comparer la performance de différents LLM et configurations d'hyperparamètres côte à côte.
Trouver les bons hyperparamètres peut déterminer le succès d'un modèle lors du développement de LLM.
Imaginez que nous affinions un LLM et que nous souhaitions évaluer l'impact de différents paramètres hyperparamétriques. Grâce à MLFlow, nous pouvons enregistrer et comparer les résultats de différents taux d'apprentissage, tailles de lots ou taux d'abandon afin de déterminer quelle configuration produit les meilleures performances, optimisant ainsi notre processus de développement de modèles.
Les fonctionnalités de registre et de suivi des modèles de MLflow entrent en jeu lors de l'évaluation de plusieurs LLM en vue de leur déploiement.
Supposons que nous disposions de plusieurs versions d'un modèle linguistique que nous envisageons d'utiliser dans un environnement de production. MLflow peut nous aider à enregistrer les mesures de performance de chaque modèle, à les comparer et à prendre une décision éclairée basée sur des preuves empiriques plutôt que sur la seule intuition.
Maintenant que nous avons une image plus claire de MLflow et de ses avantages, passons à la pratique !
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Avant d'évaluer les LLM avec MLflow, nous devons configurer la plateforme correctement. Il s'agit d'installer MLflow, de configurer éventuellement un serveur de suivi pour la journalisation à distance, et de s'assurer que notre environnement est prêt pour la gestion des expériences et le suivi des cursus.
Voyons comment procéder.
1. Assurez-vous que Python est installé :
Tout d'abord, nous devons nous assurer que Python est installé sur notre machine. MLflow est compatible avec Python 3.6 et plus (sachez que Python 3.8 est maintenant déprécié, il est donc recommandé d'utiliser Python >= 3.9). Nous pouvons vérifier notre version de Python avec :
python --version2. Créez un environnement virtuel (facultatif mais recommandé) :
Il est conseillé d'utiliser un environnement virtuel lors du cursus des expériences avec MLFlow, en particulier si vous travaillez avec Mac OS X. Nous pouvons en créer un en utilisant venv ou virtualenv.
python -m venv mlflow-envNous activons l'environnement virtuel :
Sous Windows :
mlflow-env\Scripts\activateSur Mac/Linux :
source mlflow-env/bin/activate3. Installez MLflow en utilisant pip :
Avec l'environnement virtuel activé (si utilisé), nous pouvons installer MLflow via pip :
pip install mlflow4. Installez les dépendances supplémentaires :
MLflow dispose de quelques dépendances optionnelles pour améliorer ses fonctionnalités. Si nous avons besoin d'utiliser des fonctionnalités spécifiques, comme les capacités de modèle de desserte de MLflow, nous devons installer gunicorn.
pip install gunicornSi nous utilisons des bibliothèques comme TensorFlow ou PyTorch, il se peut que nous devions installer leurs intégrations MLflow respectives :
pip install mlflow[extras]4. Vérifiez l'installation :
Nous devons ensuite nous assurer que MLflow est correctement installé en vérifiant sa version :
mlflow --versionSi nous travaillons dans un environnement collaboratif ou si nous sommes amenés à effectuer des enregistrements à distance, nous devonsmettre en place un serveur de suivi MLflow. Cette fonctionnalité nous permet de centraliser le suivi et la gestion de nos expériences.
1. Exécutez le serveur de suivi :
Nous pouvons démarrer le serveur MLflow en spécifiant le magasin backend et l'emplacement de l'artefact.
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlruns--backend-store-uri spécifie l'endroit où les données de l'expérience sont stockées. Nous pouvons utiliser n'importe quel système de base de données (PostgreSQL, MySQL, etc.).--default-artifact-root spécifie le répertoire dans lequel les artefacts, par exemple les fichiers de modèle, sont stockés.2. Configurez le serveur de cursus :
Nous devons nous assurer que nos clients MLflow sont configurés pour se connecter au serveur de cursus. Nous pouvons définir la variable d'environnement MLFLOW_TRACKING_URI pour qu'elle pointe vers notre serveur.
export MLFLOW_TRACKING_URI=http://localhost:50003. Accédez à l'interface utilisateur du cursus :
Nous pouvons maintenant ouvrir un navigateur Web et naviguervers http://localhost:5000 pouraccéder à l'interface utilisateur MLflow. Cette interface permet de visualiser les expériences, de comparer les résultats et de gérer vos projets MLflow, comme nous le verrons plus loin.
MLflow étant installé et prêt, il est temps de se plonger dans les tâches principales de chargement et d'évaluation des LLM. Voyons comment nous pouvons sélectionner un LLM pré-entraîné, le charger à l'aide de différentes bibliothèques et préparer un ensemble de données d'évaluation pour mesurer la performance du modèle.
Lors de la sélection d'un LLM pré-entraîné, les bibliothèques telles que Hugging Face Transformers offrent de nombreuses options. Par exemple, nous pouvons charger un modèle pré-entraîné, tel que GPT (pour la génération de texte) ou BERT (pour la classification de texte et d'autres tâches).
1. Installer des transformateurs Hugging Face
Tout d'abord, nous allons nous assurer que la bibliothèque Hugging Face Transformers est installée. Nous pouvons y parvenir en utilisant pip.
pip install transformers2. Charger un modèle pré-entraîné et un tokenizer
Nous chargeons maintenant le modèle BERT à l'aide de la bibliothèque transformers, y compris le modèle et le tokenizer, qui sont nécessaires pour traiter le texte et générer des prédictions.
from transformers import (
BertForSequenceClassification,
BertTokenizer
)
# Load pre-trained model and tokenizer
model_name = "textattack/bert-base-uncased-yelp-polarity"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)Le modèle bert-base-uncased est utilisé lorsque les données textuelles avec lesquelles nous travaillons sont principalement en minuscules et en majuscules, mais que nous n'avons pas besoin du modèle pour différencier les mots en majuscules et en minuscules.
Pour évaluer un LLM, nous avons besoin d'un ensemble de données approprié qui correspond à la tâche que nous évaluons. Voyons comment préparer un ensemble de données d'évaluation textuelle pour l'analyse des sentiments:
1. Charger ou créer et prétraiter l'ensemble de données
Nos données peuvent être stockées à plusieurs endroits : sur le disque de notre machine locale, dans un dépôt Github ou dans The Hugging Face Hub, une vaste collection d'ensembles de données de recherche populaires et créés par la communauté.
Pour ce tutoriel, nous utiliserons un grand ensemble de données de critiques de films pour l'analyse des sentiments, appelé IMDB. Nousutiliserons la bibliothèque datasets pour charger le jeu de données préconstruit:
Installation de la bibliothèque de jeux de données :
pip install datasetsChargement d'un jeu de données :
from datasets import load_dataset
# Load the dataset IMDb for sentiment analysis
dataset = load_dataset("imdb")2. Prétraitement pour l'analyse des sentiments
Nous utiliserons le tokenizer BERT précédemment chargé pour prétraiter l'ensemble de données en vue de l'analyse des sentiments.
def preprocess_function(examples):
return tokenizer(examples['text'], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(preprocess_function, batched=True)Maintenant que nos LLM sont chargés et que notre ensemble de données d'évaluation est préparé, il est temps d'exécuter les évaluations et d'enregistrer les mesures.
1. Importez MLflow et démarrez une nouvelle expérience
Pour suivre les expériences avec MLflow, nous devons d'abord démarrer une nouvelle expérience et enregistrer les métadonnées pertinentes, telles que le nom du modèle, la version et les paramètres d'évaluation.
import mlflow
import mlflow.pytorch
# Start a new experiment
mlflow.set_experiment("LLM_Evaluation")
with mlflow.start_run() as run:
# Log experiment metadata
mlflow.log_param("model_name", "bert")
mlflow.log_param("model_version", "v1.0")
mlflow.log_param("evaluation_task", "sentiment_analysis")2. Paramètres d'évaluation des journaux
Nous pouvons maintenant enregistrer tous les paramètres liés au processus d'évaluation, tels que la taille de l'ensemble de données d'évaluation ou les configurations spécifiques utilisées pendant l'évaluation.
with mlflow.start_run() as run:
mlflow.log_param("dataset_size", len(dataset['test']))Une fois que nous avons formé et fait les prédictions correspondantes à l'aide de notre modèle, nous pouvons évaluer le LLM et enregistrer diverses mesures qui reflètent sa performance.
L'analyse des sentiments étant un problème de classification, nous pouvons évaluer notre modèle à l'aide de mesures telles que la précision et le score F1. Pour les tâches de génération de texte, des mesures telles que le score BLEU ou la perplexité sont couramment utilisées.
from sklearn.metrics import accuracy_score, f1_score
# Assuming y_true and y_pred are true labels and model predictions
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
with mlflow.start_run() as run:
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)Une fois que plusieurs cycles d'évaluation sont cursus avec MLflow, la comparaison de leurs performances est essentielle pour déterminer les modèles et les configurations les plus performants.
Comprenons comment suivre plusieurs cursus et utiliser l'interface utilisateur de MLflow pour visualiser et comparer efficacement les résultats.
Tout d'abord, nous devons effectuer un cursus multiple au sein d'une même expérience ou entre différentes expériences afin de comparer les performances de différentes versions de LLM.
1. Enregistrez plusieurs exécutions
Nous pouvons enregistrer plusieurs exécutions dans le cadre d'une seule expérience en lançant de nouvelles exécutions pour chaque modèle ou configuration que nous voulons évaluer.
models = [("bert-base-cased", "v1.0"), ("bert-base-uncased", "v1.0")]
y_pred_dict = {
"bert-base-cased": y_pred_case,
"bert-base-uncased": y_pred_uncase
}
for model_name, model_version in models:
with mlflow.start_run() as run:
# Log model and version
mlflow.log_param("model_name", model_name)
mlflow.log_param("model_version", model_version)
# Perform evaluation and log metrics
y_pred = y_pred_dict[model_name]
accuracy = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='weighted')
mlflow.log_metric("accuracy", accuracy)
mlflow.log_metric("f1_score", f1)2. Cursus d'expériences avec différents modèles
Imaginons que nous souhaitions évaluer différents types de modèles. À cette fin, nous pouvons utiliser MLFlow pour créer une expérience et enregistrer les modèles ensemble.
L'enregistrement des modèles dans MLFlow revient à contrôler les versions des modèles d'apprentissage automatique. L'enregistrement des détails du modèle et de l'environnement garantit la reproductibilité.
Tout d'abord, nous allons mettre en place une expérience. Ensuite, nous enregistrons chaque modèle dans une exécution MLFlow distincte, y compris les identifiants d'exécution et les chemins d'artefact.
# Create an experiments for the different models
mlflow.set_experiment("sentiment_analysis_comparison")
model_names = ["bert-base-cased", "bert-base-uncased"]
run_ids = []
artifact_paths = []
for model, name in zip([betcased, bertuncased], model_names):
with mlflow.start_run(run_name=f"log_model_{name}"):
artifact_path = f"models/{name}"
mlflow.pyfunc.log_model(
artifact_path=artifact_path,
python_model=model,
)
run_ids.append(mlflow.active_run().info.run_id)
artifact_paths.append(artifact_path)Nous pouvons maintenant évaluer les modèles et enregistrer les résultats. MLflow fournit une API, mlflow.evaluate(), pour aider à évaluer nos LLM.
for i in len(model_names):
with mlflow.start_run(run_id=run_ids[i]):
# reopen the run with the stored run ID
evaluation_results = mlflow.evaluate(
model=f"runs:/{run_ids[i]}/{artifact_paths[i]}",
model_type="text",
data=dataset['test'],
)Après avoir enregistré les différentes métriques et les différents modèles dans MLFlow, nous pouvons procéder à une comparaison. Nous pouvons utiliser l'interface conviviale de MLflow pour visualiser et comparer les mesures d'évaluation de différentes exécutions. Pour ce faire, nous devons démarrer le serveur MLflow s'il n'est pas déjà en cours d'exécution
mlflow server --backend-store-uri sqlite:///mlruns.db --default-artifact-root ./mlrunsNous ouvrons ensuite un navigateur web et naviguons vers http://localhost:5000 pouraccéder à l'interface utilisateur MLflow. Dans l'interface utilisateur de MLflow, nous allons sur la page "Experiments" pour voir toutes nos expériences. En cliquant sur le nom de l'expérience, vous obtiendrez la liste des essais qui y sont associés.
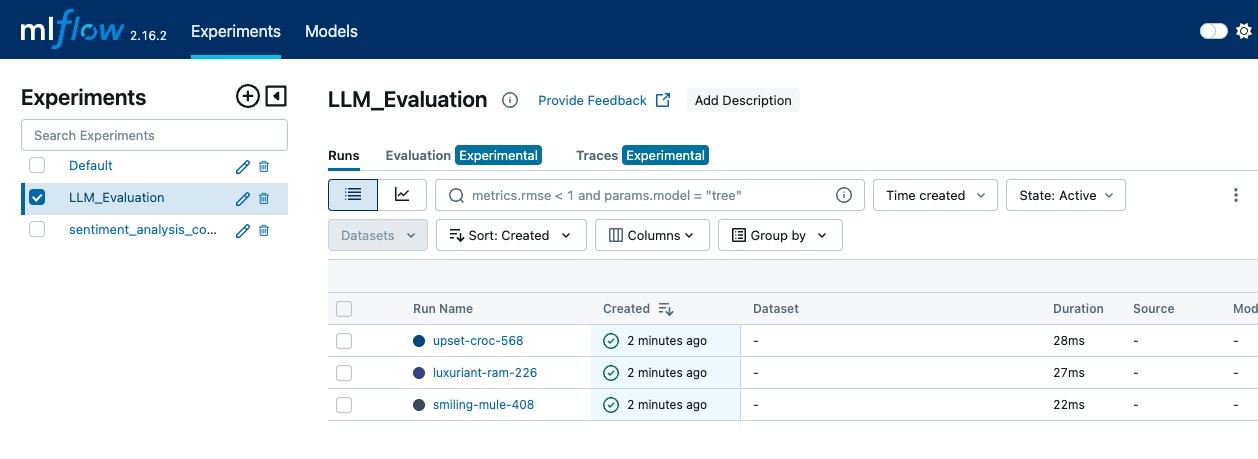
L'interface MLFLow montre l'onglet Expériences, où les différentes exécutions et les événements du journal peuvent être vus - image par Auteur.
Au sein d'une expérience, nous pouvons comparer différentes exécutions en sélectionnant plusieurs exécutions et en affichant leurs mesures côte à côte.
L'interface utilisateur nous permet de voir une représentation visuelle des mesures telles que la précision, le score F1 et d'autres mesures d'évaluation. Nous pouvons également utiliser les visualisations intégrées de MLflow pour générer des tracés et des graphiques permettant des comparaisons plus détaillées.
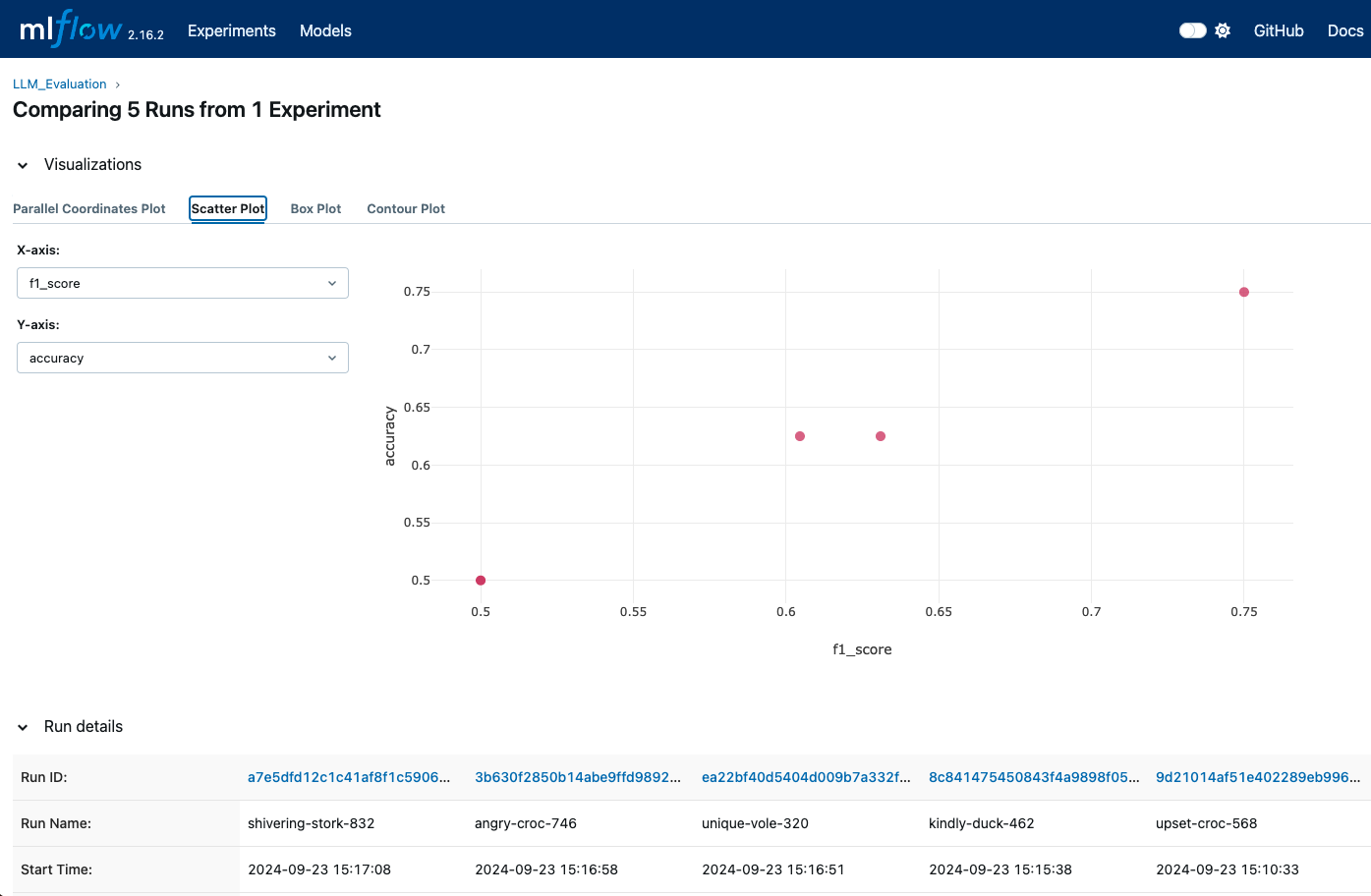
Les visualisations MLFlow peuvent nous montrer quand différentes exécutions sont enregistrées afin que nous puissions comparer différentes métriques - image par Auteur.
L'interface utilisateur MLflow fournit des graphiques et des journaux détaillés pour chaque exécution. Nous pouvons accéder à ces journaux et à ces visualisations pour comprendre quel modèle ou quelle configuration est le plus performant sur la base des métriques enregistrées.
Pour une évaluation plus approfondie et plus complète des LLM, MLflow offre des techniques avancées qui améliorent le cursus et l'analyse. Nous verrons comment enregistrer les artefacts du modèle pour un suivi approfondi et utiliser MLflow pour le réglage des hyperparamètres afin d'optimiser les performances du LLM .
L'enregistrement des artefacts du modèle est très important pour préserver et analyser les détails de nos expériences. Les artefacts peuvent fournir une image complète de la performance de notre modèle et aider à reproduire les résultats.
Parmi les artefacts que nous pouvons enregistrer, nous pouvons trouver :
joblib pour scikit-learn ou le format TensorFlow SavedModel ).En voici un exemple :
import matplotlib.pyplot as plt
from sklearn.metrics import ConfusionMatrixDisplay
with mlflow.start_run() as run:
# Log the model
mlflow.pytorch.save_model(model, "model")
# Log the model weights
joblib.dump(model, "model_weights.pkl")
mlflow.log_artifact("model", artifact_path="model")
# Log the confusion matrix as image
confusion_matrix = pd.DataFrame(confusion_matrix(y_test, predictions))
cm = ConfusionMatrixDisplay(confusion_matrix=cm)
plt.savefig("confusion_matrix.png")
mlflow.log_artifact("confusion_matrix.png")
# Generate predictions
outputs = dataset['test']
outputs['prediction'] = model.predict(dataset['test'])
with open("generated_outputs.txt", "w") as f:
for output in outputs:
f.write(output + "\n")
# Log the file
mlflow.log_artifact("generated_outputs.txt")Le réglage des hyperparamètres est un élément clé de l'optimisation des performances du LLM. Dans nos expériences, nous pouvons utiliser MLflow pour enregistrer différentes configurations d'hyperparamètres. Cela nous permet de comparer les effets de différents paramètres et de trouver la configuration optimale.
from transformers import Trainer, TrainingArguments
def train_and_log_model(model, lr, bs):
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
learning_rate=learning_rate,
evaluation_strategy="epoch")
trainer = Trainer(model=model,
args=training_args,
train_dataset=(X_train, y_train)
eval_dataset=(X_test, y_test))
with mlflow.start_run() as run:
# Log hyperparameters
mlflow.log_param("learning_rate", lr)
mlflow.log_param("batch_size", bs)
trainer.train()
eval_result = trainer.evaluate()
mlflow.log_metric("eval_accuracy",
eval_result['eval_accuracy'])
hyperparameter_grid = [{"learning_rate": 5e-5, "batch_size": 8},
{"learning_rate": 3e-5, "batch_size": 16}]
for params in hyperparameter_grid:
train_and_log_model(params["learning_rate"],
params["batch_size"])Un autre avantage de MLflow est qu'il peut être utilisé avec des bibliothèques d'optimisation d'hyperparamètres comme Optuna ou Ray Tune pour automatiser le processus de réglage.
Une évaluation précise des LLM ne se limite pas à l'exécution de tests et à l'enregistrement de mesures. Elle nécessite une approche stratégique pour garantir la cohérence, la précision et l'efficacité. L'adoption des meilleures pratiques peut améliorer la fiabilité et l'efficacité du processus d'évaluation.
L'utilisation d'ensembles de données stables et représentatifs est l'une des premières choses qui contribuent à une évaluation efficace. En veillant à ce que nos ensembles de données d'évaluation soient stables et représentatifs des tâches pour lesquelles notre LLM est conçu, nous obtiendrons des comparaisons significatives dans le temps et entre différents modèles ou versions. Si l'ensemble de données change, il peut être difficile d'attribuer les changements de performance au modèle plutôt qu'à l'ensemble de données lui-même.
Non seulement l'ensemble de données, mais aussi la façon dont nous le prétraiter sont importants. Wous devons appliquer les mêmes étapes de prétraitement à tous les ensembles de données d'évaluation afin de garantir des résultats comparables. Cela comprend la tokenisation, la normalisation et le traitement des cas particuliers. Un prétraitement cohérent garantit que les variations de performance du modèle ne sont pas dues à des différences dans la manière dont les données sont traitées.
Comme nous l'avons vu plus haut, l'utilisation du registre de modèles de MLflow pour permettre le contrôle des versions nous aide à suivre les différentes versions de nos LLM. Cela permet de comparer les performances des modèles et de revenir à des versions antérieures si nécessaire. Nous devons consigner tous les détails et garder une trace des changements apportés aux modèles, y compris les modifications de l'architecture, des hyperparamètres ou des données d'entraînement.
Enfin, l'automatisation du processus d'évaluation en l'intégrant dans les pipelines d'intégration continue/déploiement continu (CI/CD) peut nous aider à nous assurer que les modèles sont évalués de manière cohérente et rapide lorsque des mises à jour sont effectuées. Nous devrions mettre en place des évaluations programmées afin d'évaluer périodiquement les performances du modèle. Cela nous permet de surveiller la dérive des modèles et de nous assurer qu'ils respectent les normes de performance au fil du temps.
L'évaluation efficace des LLM nécessite une approche structurée et systématique, et MLflow fournit un cadre pour soutenir ce processus.
Dans ce tutoriel, nous avons installé MLflow et mis en place un serveur de suivi. Ensuite, nous avons évalué notre LLM en enregistrant les métriques importantes, en effectuant le cursus de plusieurs exécutions pour les comparer et en utilisant l'interface utilisateur de MLflow pour visualiser et analyser ces comparaisons de manière efficace.
Si vous souhaitez approfondir vos connaissances sur MLflow, consultez notre cours d'introduction à MLflow!
Apprenez-en plus sur les LLM grâce à ces cours !
Cours
Cours
Cours