

Cursus
Les fondamentaux du lama
4 h
Les derniers modèles LLaMA 4 de Meta, Scout et Maverick, sont conçus pour le raisonnement en contexte long, la compréhension multimodale et l'inférence efficace à grande échelle. Associés à vLLM, un moteur d'inférence à haut débit doté d'API compatibles avec l'OpenAI, ces modèles deviennent pratiques pour les applications du monde réel.
Dans cet article de blog, je vais vous expliquer comment déployer LLaMA 4 Scout sur une instance RunPod multi-GPU à l'aide de vLLM et le servir via un point d'extrémité d'API local ou distant compatible avec OpenAI. Nous aborderons la configuration du modèle, le déploiement et l'interaction avec l'API à l'aide d'entrées textuelles et d'images.
À la fin de ce tutoriel, vous aurez également deux démonstrations complètes :
Nous tenons nos lecteurs informés des dernières nouveautés en matière d'IA en leur envoyant The Median, notre lettre d'information gratuite du vendredi qui analyse les principaux sujets de la semaine. Abonnez-vous et restez à la pointe de la technologie en quelques minutes par semaine :
vLLM (virtual large language model) est un cadre d'inférence LLM optimisé, développé à l'origine au Sky Computing Lab de l'université de Berkeley, qui introduit PagedAttention, un nouveau système de gestion de la mémoire qui minimise la fragmentation de la mémoire du GPU et permet une mise en cache efficace des clés-valeurs pour les séquences extrêmement longues. Pour en savoir plus, consultez ce tutoriel sur le système vLLM.
Voici pourquoi vLLM est le moteur idéal pour servir LLaMA 4 :
Dans cette section, nous verrons comment provisionner une puissante instance multi-GPU sur RunPod, déployer le modèle LLaMA 4 Scout de Meta en utilisant vLLM, et exposer une API compatible OpenAI pour l'inférence locale et distante.
Avant de lancer le modèle, assurez-vous que votre compte RunPod est configuré :
Maintenant, prévoyons un pod capable d'accueillir le modèle 17B LLaMA 4 Scout :

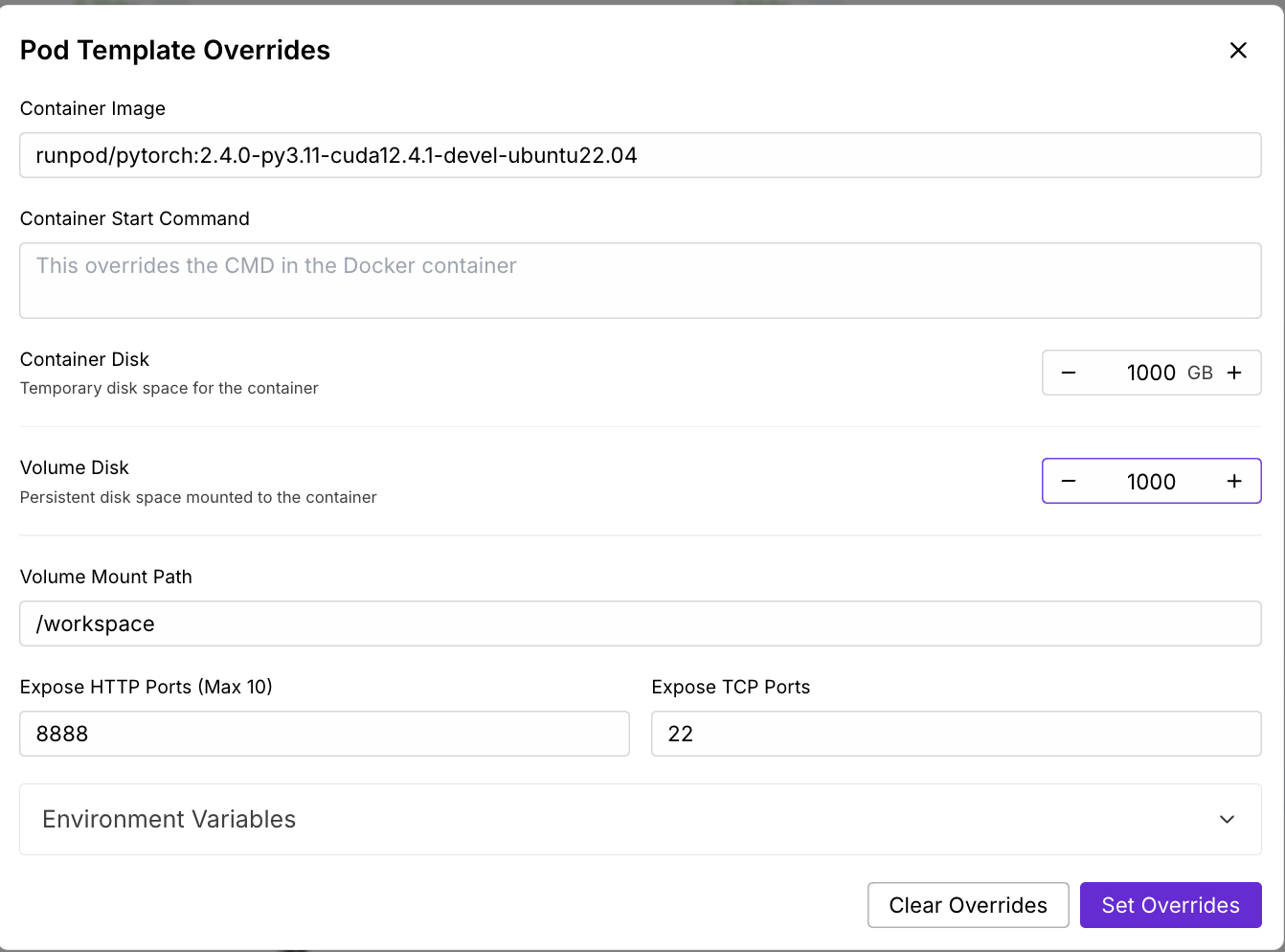
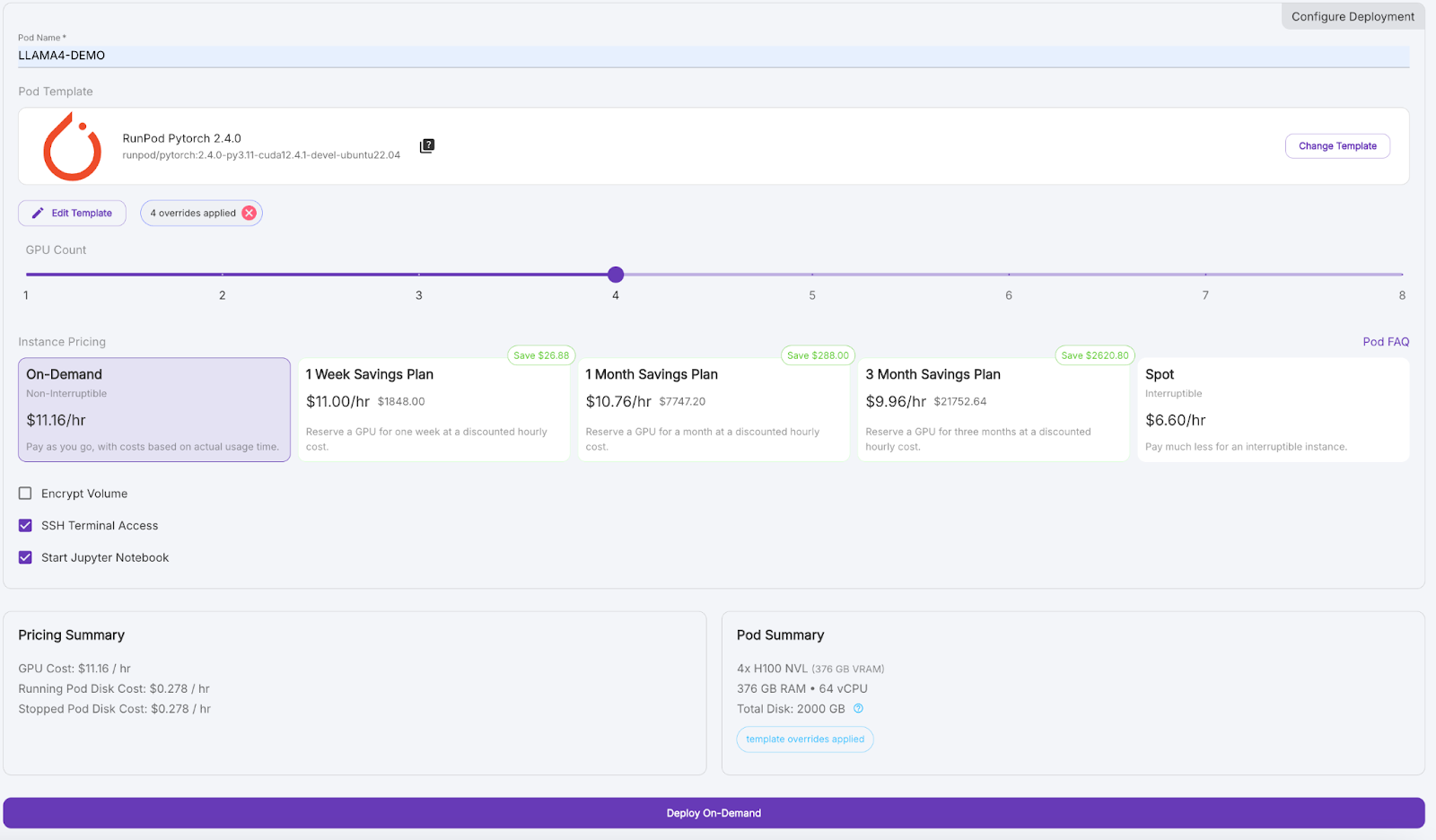
Attendez quelques minutes pour que le pod soit approvisionné.
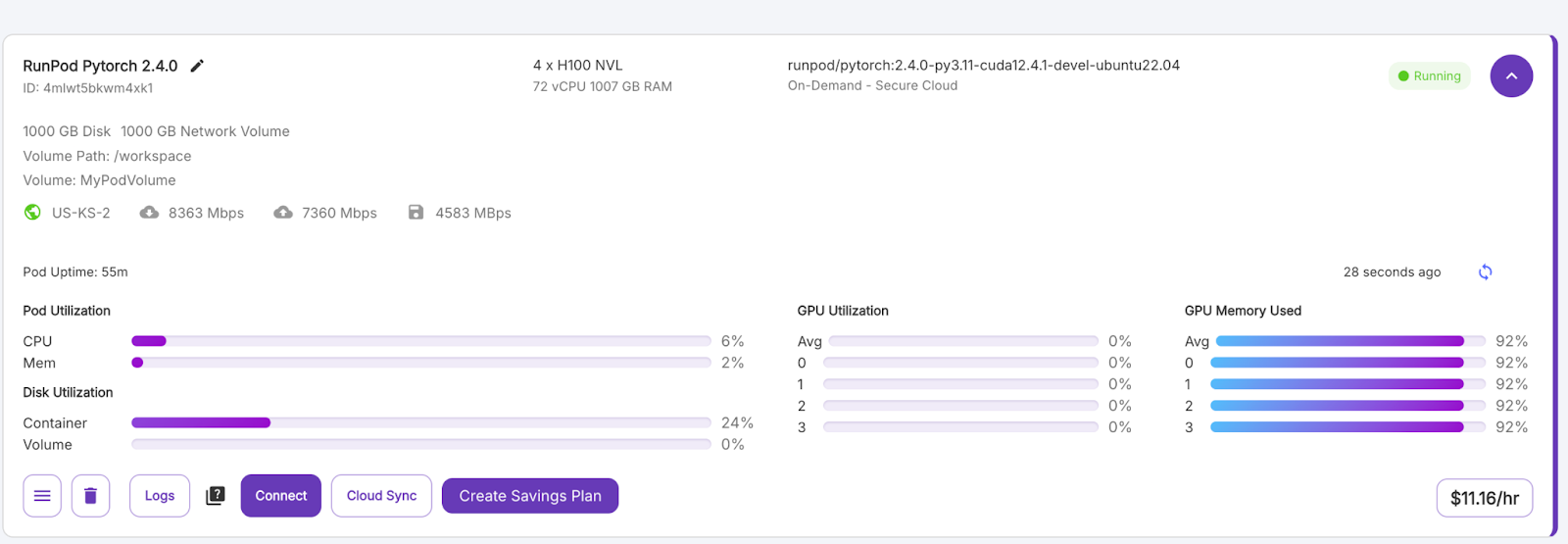
Une fois que le bouton "Connect" devient violet, cliquez dessus. Plusieurs options de connexion s'offrent à vous :
Dans le terminal à l'intérieur de votre pod, installez vLLM et ses dépendances. Installez vLLM et d'autres bibliothèques dans l'environnement pod.
pip install -U vllm
pip install transformers accelerate pillow #optionalEnsuite, nous lançons le serveur de modèle LLaMA 4 Scout à l'aide de la commande suivante :
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 4 \
--max-model-len 100000 --override-generation-config='{"attn_temperature_tuning": true}'Cette commande permet d'effectuer les opérations suivantes :

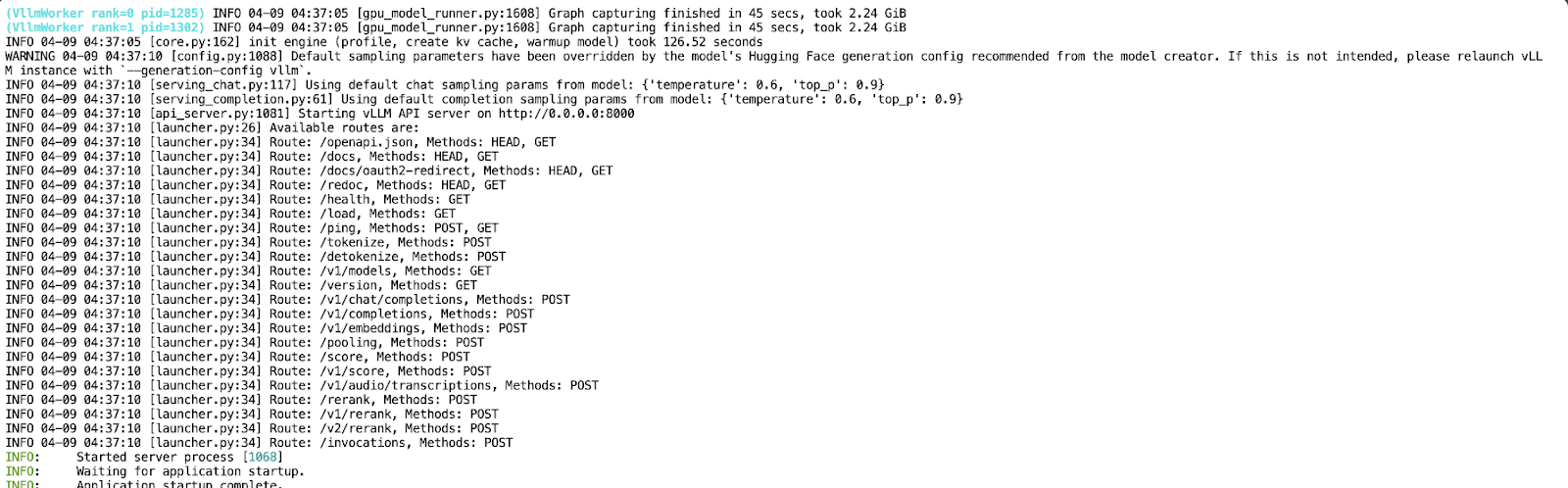
Maintenant que votre API fonctionne sur le port 8000, créez un nouveau bloc-notes Jupyter dans le même environnement pod.
Dans cette démo, nous allons interagir avec le modèle LLaMA 4 Scout hébergé localement et servi via vLLM à l'aide d'un simple script Python. Le modèle est exposé par le biais d'une API, ce qui nous permet de construire un assistant conversationnel qui prend en charge le dialogue multi-tour.
Nous utiliserons le SDK officiel OpenAI Python pour communiquer avec l'API vLLM et la bibliothèque Colorama pour la sortie colorée des terminaux. Vous pouvez installer les deux en utilisant :
pip install openai coloramaUne fois installé, importez les modules nécessaires :
from openai import OpenAI
from colorama import Fore, Style, initNous configurons le client OpenAI pour qu'il pointe vers notre serveur vLLM local. Si votre déploiement ne nécessite pas de clé API (comportement par défaut pour les exécutions locales), indiquez "EMPTY" comme clé :
# Initialize colorama
init(autoreset=True)
# Set up client
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)Ce code initialise la bibliothèque Colorama pour une sortie colorée du terminal avec une remise à zéro automatique après chaque impression. Il met ensuite en place un client compatible avec OpenAI à l'aide de la classe OpenAI, qui pointe vers une API vLLM hébergée localement.
Étape 3 : Démarrer la boucle de chat
Ensuite, nous mettons en place une boucle simple pour permettre une interaction continue avec le modèle. L'historique de la conversation est conservé d'un tour à l'autre, ce qui permet un comportement de dialogue à plusieurs tours.
# Initialize message history
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
print("Start chatting with the assistant! Type 'exit' or 'quit' to end.\n")
while True:
user_input = input(f"{Fore.BLUE}User: {Style.RESET_ALL}")
if user_input.strip().lower() in ["exit", "quit"]:
print("Exiting chat. Goodbye!")
break
messages.append({"role": "user", "content": user_input})
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
assistant_message = chat_response.choices[0].message.content
print(f"{Fore.GREEN}Assistant: {assistant_message}\n{Style.RESET_ALL}")
messages.append({"role": "assistant", "content": assistant_message})Une interface de chat simple basée sur un terminal est initialisée avec un historique des conversations et une invite du système qui accepte continuellement les entrées de l'utilisateur dans une boucle. Chaque message d'utilisateur est ajouté à l'historique des messages et envoyé au modèle Llama-4-Scout-17B-16E-Instruct via l'appel API client.chat.completions.create().
La réponse du modèle est imprimée en vert à l'aide de Colorama et ajoutée à l'historique des messages, ce qui permet un dialogue à plusieurs tours jusqu'à ce que l'utilisateur tape "exit" ou "quit".
Dans la section suivante, nous verrons comment exécuter une inférence multimodale avec des entrées image + texte en utilisant la même API.
Dans cette démonstration, nous verrons comment envoyer des images et du texte au modèle LLaMA 4 Scout hébergé via vLLM en utilisant ses capacités multimodales natives. Cela vous permet d'effectuer un raisonnement visuel, un sous-titrage d'image ou des questions-réponses multimodales, le tout par le biais d'une seule API compatible avec l'OpenAI.
Cet exemple utilise le SDK OpenAI pour interfacer avec le serveur vLLM. S'il n'est pas déjà installé, vous pouvez le lancer :
pip install openaiImportez ensuite le module requis :
from openai import OpenAIConnectez-vous à votre serveur vLLM local en utilisant l'interface compatible avec OpenAI. Si votre serveur ne nécessite pas d'authentification, utilisez "EMPTY" comme clé API.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)L'extrait de code ci-dessus initialise un client compatible avec OpenAI pour l'inférence locale à l'aide du serveur vLLM. La valeur de api_key est "EMPTY" (pas d'authentification requise), et base_url pointe vers le point d'accès local à l'API vLLM.
Nous allons maintenant envoyer une invite de chat qui comprend à la fois une image et une instruction textuelle. LLaMA 4 Scout traitera l'image en même temps que la requête et renverra une réponse descriptive.
messages = [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url1}},
{"type": "text", "text": "Can you describe what's in this image?"}
]
}
]
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
print("Response:", chat_response.choices[0].message.content)Une fois que l'inférence multimodale utilisant le modèle LLaMA 4 Scout est servie, nous construisons une entrée de type chat contenant à la fois une image URL et une invite textuelle, formatée selon le schéma de chat de l'OpenAI. La méthode client.chat.completions.create() est utilisée pour envoyer cette demande multimodale au modèle, qui traite l'image et le texte qui l'accompagne pour générer une réponse contextuelle.

Dans ce tutoriel, nous avons hébergé le modèle LLaMA 4 Scout de Meta en utilisant vLLM sur RunPod, le rendant accessible via des points d'extrémité compatibles avec OpenAI pour l'inférence textuelle et multimodale. En combinant le haut débit de vLLM et la puissante infrastructure de RunPod, nous avons créé une configuration rentable pour servir des LLM de pointe avec un long contexte et des capacités de vision.
Pour en savoir plus sur LLaMA 4 et vLLM, consultez le site :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours