

Programa
Llama Fundamentals
4 h
Os modelos LLaMA 4 mais recentes da Meta, Scout e Maverick, foram desenvolvidos para raciocínio de contexto longo, compreensão multimodal e inferência eficiente em escala. Quando combinados com o vLLM, um mecanismo de inferência de alto rendimento com APIs compatíveis com OpenAI, esses modelos se tornam práticos para aplicativos do mundo real.
Nesta postagem do blog, mostrarei a você como implantar o LLaMA 4 Scout em uma instância RunPod com várias GPUs usando o vLLM e como servi-lo por meio de um endpoint de API local ou remoto compatível com OpenAI. Abordaremos a configuração do modelo, a implantação e a interação com a API usando entradas de texto e imagem.
Ao final deste tutorial, você também terá duas demonstrações completas:
Mantemos nossos leitores atualizados sobre as últimas novidades em IA enviando o The Median, nosso boletim informativo gratuito de sexta-feira que detalha as principais histórias da semana. Inscreva-se e fique atento em apenas alguns minutos por semana:
O vLLM (virtual large language model) é uma estrutura de inferência LLM otimizada, desenvolvida originalmente no Sky Computing Lab da UC Berkeley, que apresenta o PagedAttention, um novo sistema de gerenciamento de memória que minimiza a fragmentação da memória da GPU e permite o armazenamento em cache eficiente de valores-chave para sequências extremamente longas. Para saber mais, confira este tutorial sobre vLLM.
Veja por que o vLLM é o mecanismo ideal para atender ao LLaMA 4:
Nesta seção, veremos como provisionar uma instância avançada de várias GPUs no RunPod, implantar o modelo LLaMA 4 Scout do Meta usando o vLLM e expor uma API compatível com OpenAI para inferência local e remota.
Antes de iniciar o modelo, certifique-se de que sua conta RunPod esteja configurada:
Agora, vamos fornecer um pod capaz de hospedar o modelo 17B LLaMA 4 Scout:

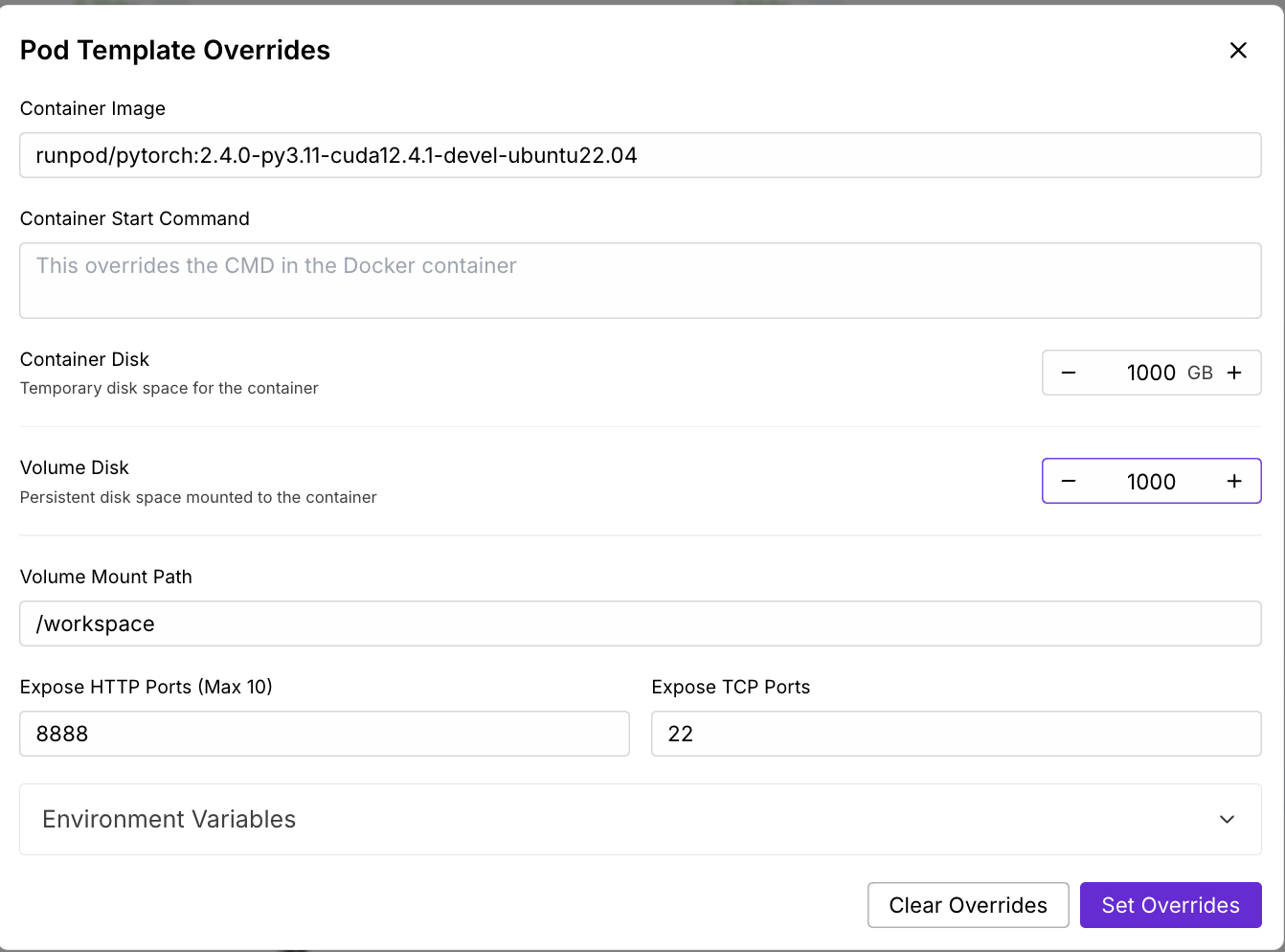
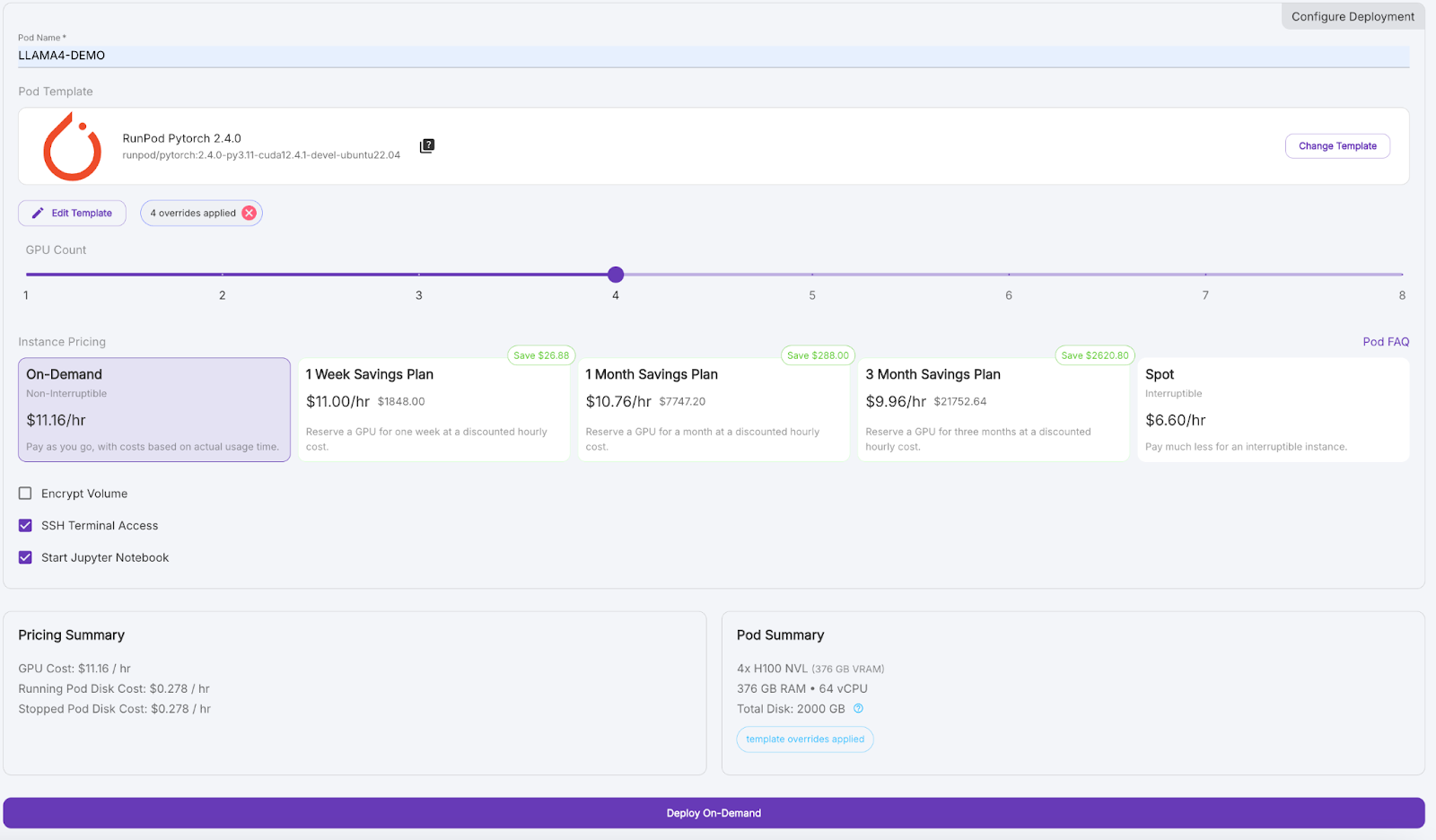
Aguarde alguns minutos para que o pod seja provisionado.
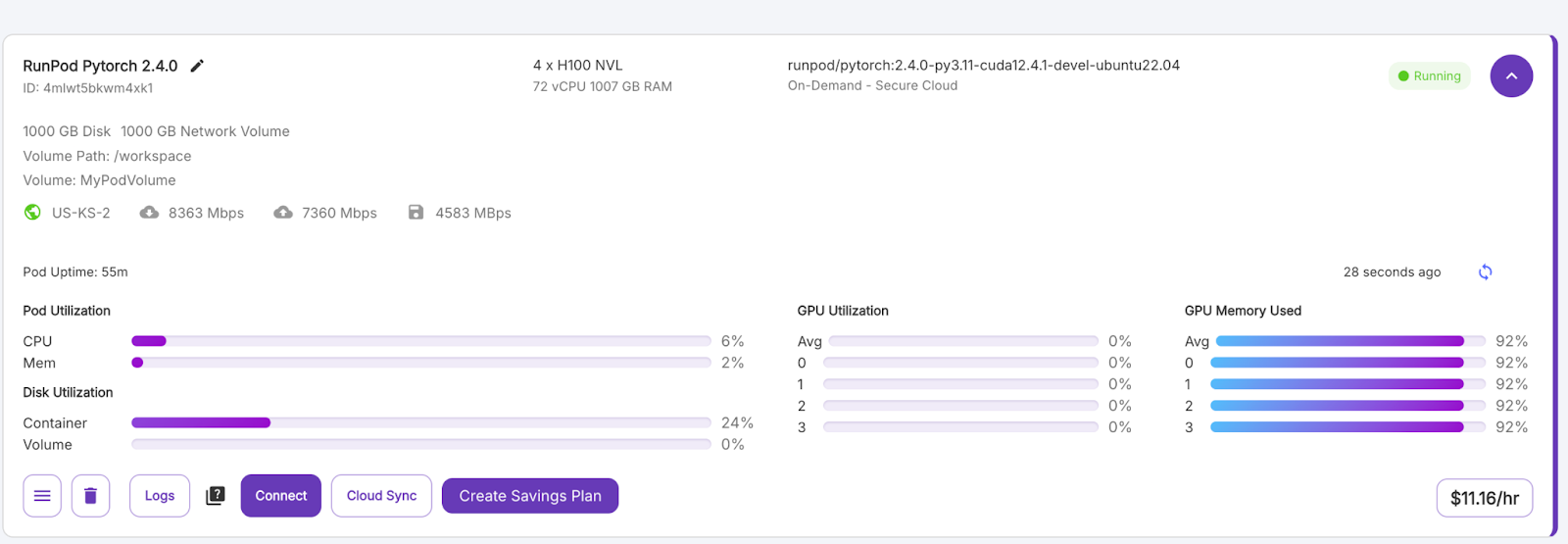
Quando o botão "Connect" ficar roxo, clique nele. Você verá várias opções de conexão - você pode:
No terminal dentro de seu pod, instale o vLLM e suas dependências. Instale o vLLM e outras bibliotecas dentro do ambiente do pod.
pip install -U vllm
pip install transformers accelerate pillow #optionalEm seguida, iniciamos o servidor do modelo LLaMA 4 Scout usando o seguinte comando:
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 4 \
--max-model-len 100000 --override-generation-config='{"attn_temperature_tuning": true}'Esse comando faz o seguinte:

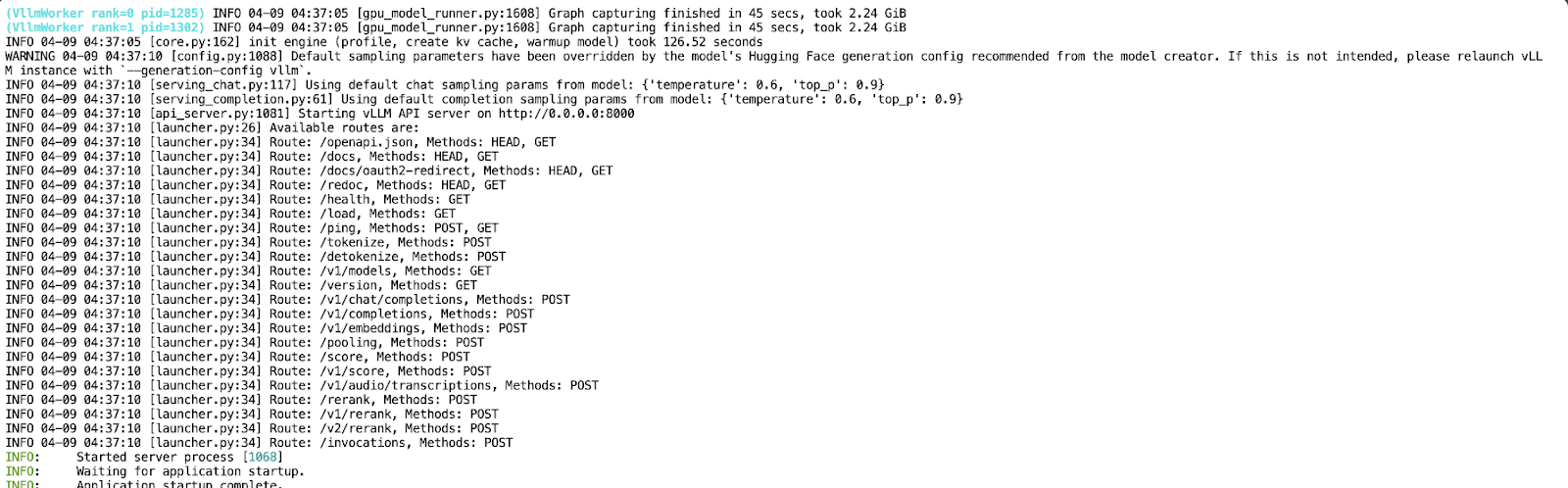
Agora que sua API está sendo executada na porta 8000, crie um novo Jupyter Notebook no mesmo ambiente de pod.
Nesta demonstração, vamos interagir com o modelo LLaMA 4 Scout hospedado localmente e servido via vLLM usando um script Python simples. O modelo é exposto por meio da API, o que nos permite criar um assistente de conversação que ofereça suporte a diálogos com várias voltas.
Usaremos o SDK oficial do Python da OpenAI para nos comunicarmos com a API vLLM e a biblioteca Colorama para a saída colorida do terminal. Você pode instalar ambos usando:
pip install openai coloramaDepois de instalado, importe os módulos necessários:
from openai import OpenAI
from colorama import Fore, Style, initConfiguramos o cliente OpenAI para apontar para o nosso servidor vLLM em execução local. Se a sua implantação não exigir uma chave de API (o comportamento padrão para execuções locais), passe "EMPTY" como a chave:
# Initialize colorama
init(autoreset=True)
# Set up client
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)Esse código inicializa a biblioteca Colorama para a saída colorida do terminal com uma redefinição automática após cada impressão. Em seguida, ele configura um cliente compatível com OpenAI usando a classe OpenAI, apontando para uma API vLLM hospedada localmente.
Etapa 3: Iniciar o loop de bate-papo
Em seguida, implementamos um loop simples para permitir a interação contínua com o modelo. O histórico da conversa é preservado em todos os turnos, permitindo o comportamento de diálogo em vários turnos.
# Initialize message history
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
print("Start chatting with the assistant! Type 'exit' or 'quit' to end.\n")
while True:
user_input = input(f"{Fore.BLUE}User: {Style.RESET_ALL}")
if user_input.strip().lower() in ["exit", "quit"]:
print("Exiting chat. Goodbye!")
break
messages.append({"role": "user", "content": user_input})
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
assistant_message = chat_response.choices[0].message.content
print(f"{Fore.GREEN}Assistant: {assistant_message}\n{Style.RESET_ALL}")
messages.append({"role": "assistant", "content": assistant_message})Uma interface de bate-papo simples baseada em terminal é inicializada com um histórico de conversas e um prompt do sistema que aceita continuamente a entrada do usuário em um loop. Cada mensagem do usuário é anexada ao histórico de mensagens e enviada ao modelo Llama-4-Scout-17B-16E-Instruct por meio da chamada à API client.chat.completions.create().
A resposta do modelo é impressa em verde usando Colorama e adicionada novamente ao histórico de mensagens, permitindo um diálogo de várias voltas até que o usuário digite "sair" ou "quit".
Na próxima seção, exploraremos como executar a inferência multimodal com entradas de imagem + texto usando a mesma API.
Nesta demonstração, exploraremos como enviar entradas de imagem e texto para o modelo do LLaMA 4 Scout hospedado via vLLM usando seus recursos multimodais nativos. Isso permite que você execute raciocínio visual, legendagem de imagens ou perguntas e respostas multimodais, tudo por meio de uma única API compatível com OpenAI.
Este exemplo usa o OpenAI SDK para fazer a interface com o servidor vLLM. Se ainda não estiver instalado, você pode executar:
pip install openaiEm seguida, importe o módulo necessário:
from openai import OpenAIConecte-se ao seu servidor vLLM local usando a interface compatível com OpenAI. Se o seu servidor não exigir autenticação, use "EMPTY" como a chave da API.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)O trecho de código acima inicializa um cliente compatível com OpenAI para inferência local usando o servidor vLLM. O endereço api_key está definido como "EMPTY" (sem necessidade de autenticação) e base_url aponta para o endpoint local da API vLLM.
Agora enviaremos um prompt de bate-papo que inclui uma imagem e uma instrução de texto. O LLaMA 4 Scout processará a imagem juntamente com a consulta e retornará uma resposta descritiva.
messages = [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url1}},
{"type": "text", "text": "Can you describe what's in this image?"}
]
}
]
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
print("Response:", chat_response.choices[0].message.content)Depois que a inferência multimodal usando o modelo LLaMA 4 Scout é atendida, criamos uma entrada no estilo de bate-papo contendo um URL de imagem e um prompt de texto, formatados de acordo com o esquema de bate-papo da OpenAI. O método client.chat.completions.create() é usado para enviar essa solicitação multimodal ao modelo, que processa a imagem e o texto que a acompanha para gerar uma resposta contextual.

Neste tutorial, hospedamos o modelo LLaMA 4 Scout do Meta usando vLLM no RunPod, tornando-o acessível por meio de pontos de extremidade compatíveis com OpenAI para inferência de texto e multimodal. Ao combinar o alto rendimento do vLLM e a infraestrutura avançada do RunPod, criamos uma configuração econômica para atender a LLMs de última geração com recursos de visão e contexto longos.
Para saber mais sobre o LLaMA 4 e o vLLM, confira:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Stanislav Karzhev
9 min
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan

