

programa
Llama Fundamentals
4 h
Los últimos modelos LLaMA 4 de Meta, Scout y Maverick, están construidos para el razonamiento en contextos largos, la comprensión multimodal y la inferencia eficiente a escala. Cuando se combinan con vLLM, un motor de inferencia de alto rendimiento con API compatibles con OpenAI, estos modelos resultan prácticos para las aplicaciones del mundo real.
En esta entrada de blog, te explicaré cómo desplegar LLaMA 4 Scout en una instancia RunPod multi-GPU utilizando vLLM y servirlo a través de un punto final de API local o remoto compatible con OpenAI. Cubriremos la configuración del modelo, el despliegue y la interacción con la API utilizando entradas de texto y de imagen.
Al final de este tutorial, también tendrás dos demostraciones completas:
Mantenemos a nuestros lectores al día de lo último en IA enviándoles The Median, nuestro boletín gratuito de los viernes que desglosa las noticias clave de la semana. Suscríbete y mantente alerta en sólo unos minutos a la semana:
vLLM (virtual large language model) es un marco optimizado de inferencia LLM desarrollado originalmente en el Sky Computing Lab de la UC Berkeley, que introduce PagedAttention, un novedoso sistema de gestión de memoria que minimiza la fragmentación de la memoria de la GPU y permite un almacenamiento eficiente en caché de valores clave para secuencias extremadamente largas. Para saber más, consulta este tutorial sobre vLLM.
He aquí por qué vLLM es el motor ideal para servir a LLaMA 4:
En esta sección, veremos cómo aprovisionar una potente instancia multi-GPU en RunPod, desplegar el modelo LLaMA 4 Scout de Meta utilizando vLLM, y exponer una API compatible con OpenAI para la inferencia local y remota.
Antes de lanzar el modelo, asegúrate de que tu cuenta RunPod está configurada:
Ahora, vamos a aprovisionar una vaina capaz de albergar el modelo 17B LLaMA 4 Scout:

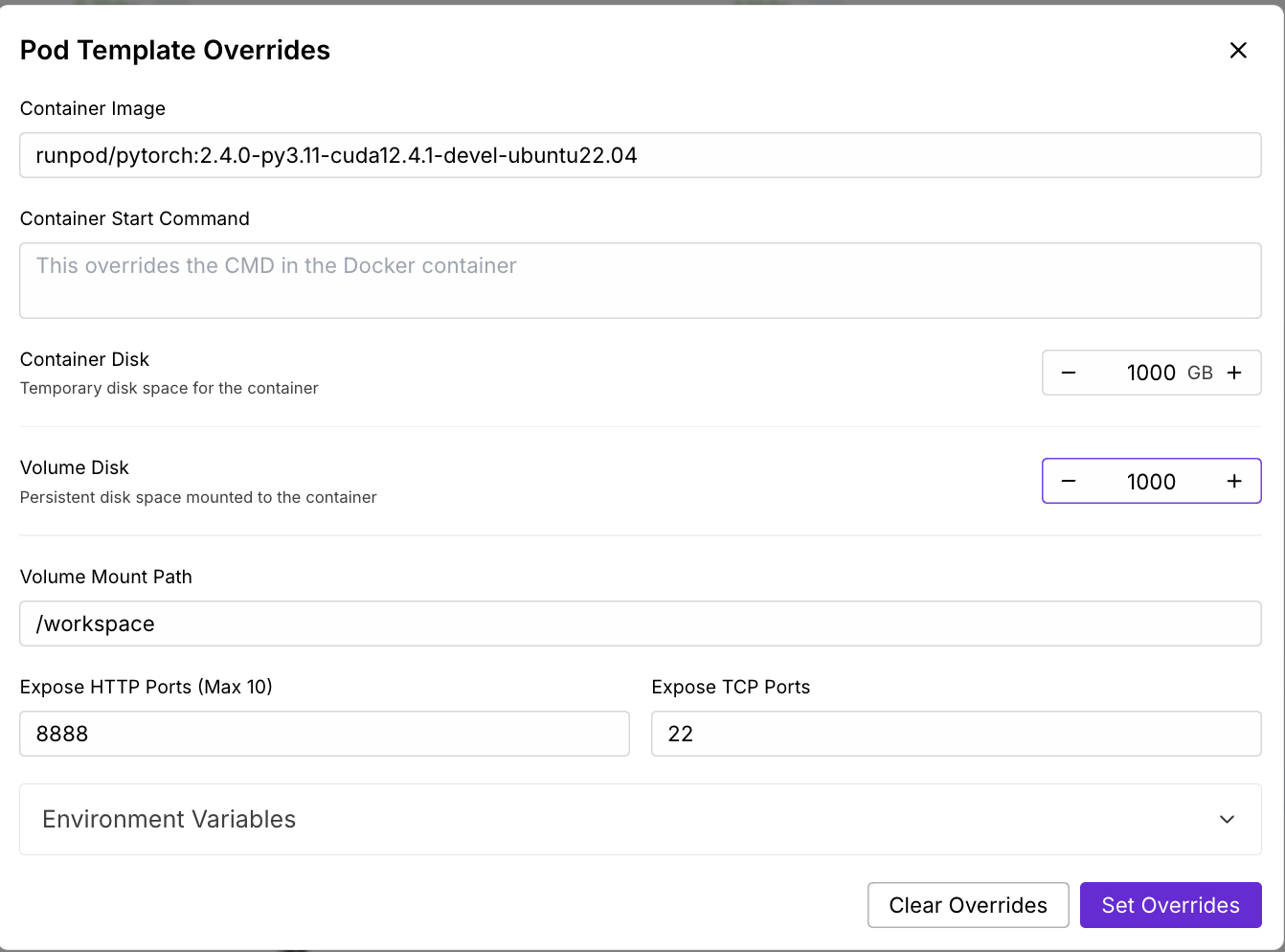
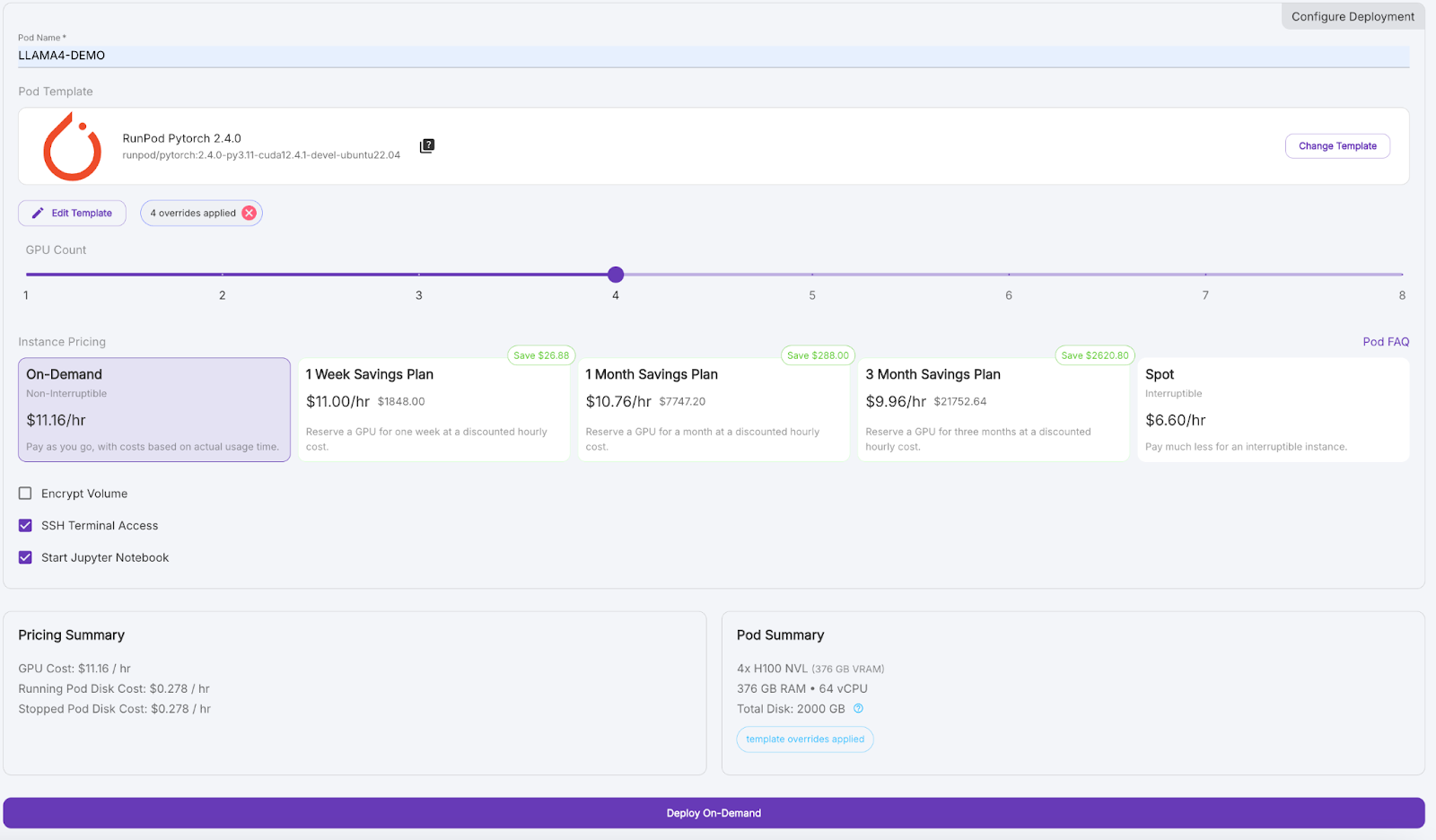
Espera unos minutos a que se aprovisione el pod.
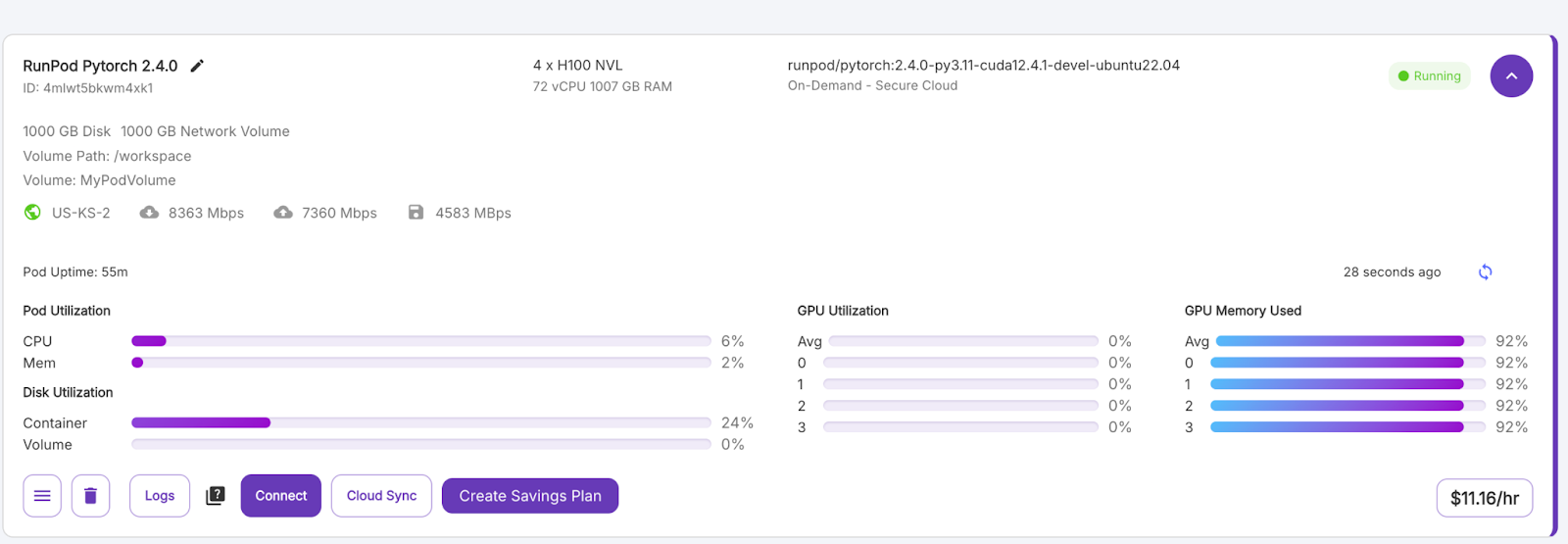
Cuando el botón "Conectar" se vuelva morado, haz clic en él. Verás varias opciones de conexión: puedes:
En el terminal dentro de tu pod, instala vLLM y sus dependencias. Instala vLLM y otras librerías dentro del entorno pod.
pip install -U vllm
pip install transformers accelerate pillow #optionalA continuación, lanzamos el servidor del modelo LLaMA 4 Scout mediante el siguiente comando:
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 4 \
--max-model-len 100000 --override-generation-config='{"attn_temperature_tuning": true}'Este comando hace lo siguiente:

Ahora que tu API se ejecuta en el puerto 8000, crea un nuevo Jupyter Notebook en el mismo entorno pod.
En esta demostración, interactuaremos con el modelo LLaMA 4 Scout alojado localmente y servido a través de vLLM mediante un sencillo script de Python. El modelo se expone a través de la API, lo que nos permite construir un asistente conversacional que admita el diálogo multiturno.
Utilizaremos el SDK Python oficial de OpenAI para comunicarnos con la API vLLM y la biblioteca Colorama para la salida del terminal coloreado. Puedes instalar ambos utilizando:
pip install openai coloramaUna vez instalado, importa los módulos necesarios:
from openai import OpenAI
from colorama import Fore, Style, initConfiguramos el cliente OpenAI para que apunte a nuestro servidor vLLM que se ejecuta localmente. Si tu implantación no requiere una clave API (el comportamiento por defecto para las ejecuciones locales), pasa "VACÍO" como clave:
# Initialize colorama
init(autoreset=True)
# Set up client
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)Este código inicializa la biblioteca Colorama para la salida de terminal en color con un reinicio automático después de cada impresión. A continuación, configura un cliente compatible con OpenAI utilizando la clase OpenAI, apuntando a una API vLLM alojada localmente.
Paso 3: Inicia el bucle de chat
A continuación, implementamos un bucle sencillo para permitir la interacción continua con el modelo. El historial de la conversación se conserva a lo largo de los turnos, lo que permite un comportamiento de diálogo multivuelta.
# Initialize message history
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
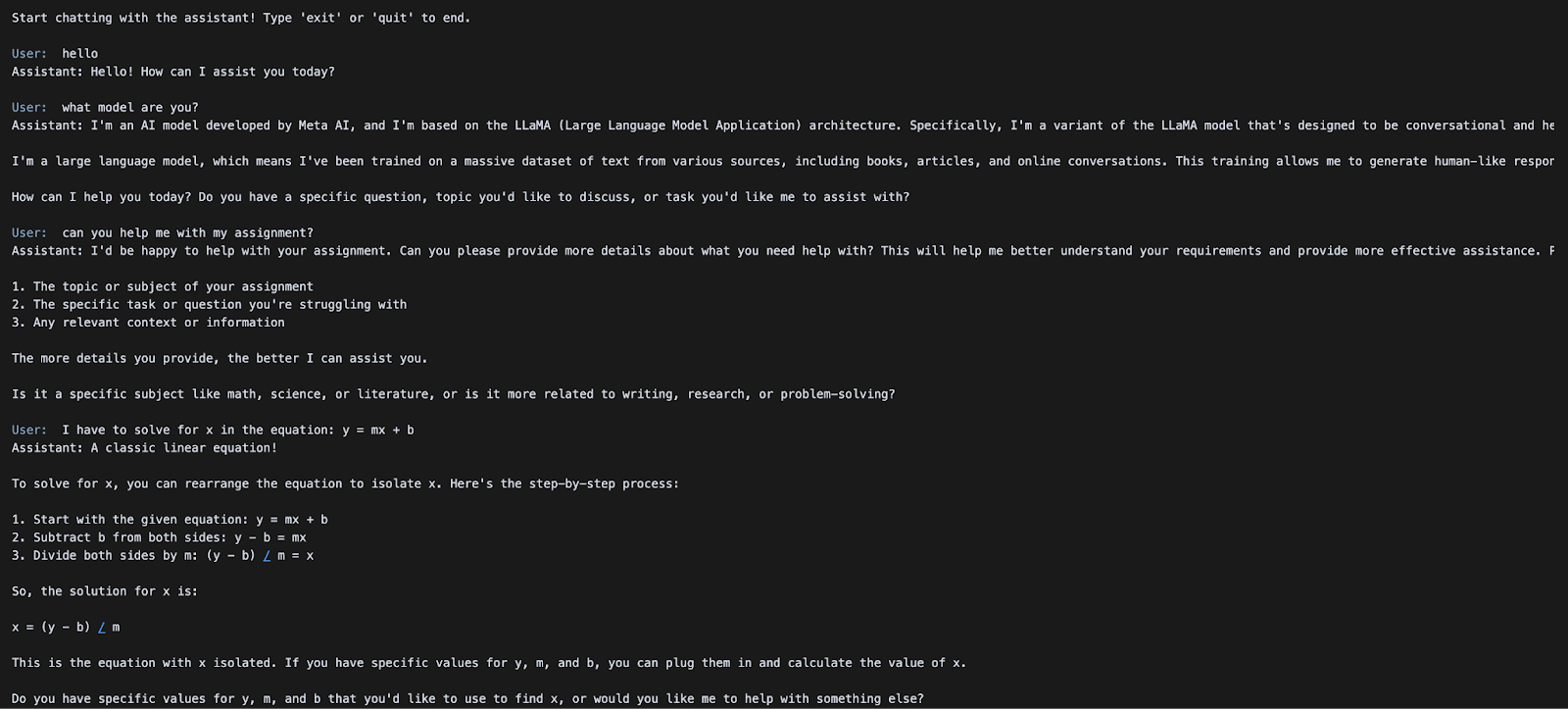
print("Start chatting with the assistant! Type 'exit' or 'quit' to end.\n")
while True:
user_input = input(f"{Fore.BLUE}User: {Style.RESET_ALL}")
if user_input.strip().lower() in ["exit", "quit"]:
print("Exiting chat. Goodbye!")
break
messages.append({"role": "user", "content": user_input})
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
assistant_message = chat_response.choices[0].message.content
print(f"{Fore.GREEN}Assistant: {assistant_message}\n{Style.RESET_ALL}")
messages.append({"role": "assistant", "content": assistant_message})Una sencilla interfaz de chat basada en un terminal se inicializa con un historial de conversaciones y un indicador del sistema que acepta continuamente la entrada del usuario en un bucle. Cada mensaje de usuario se añade al historial de mensajes y se envía al modelo Llama-4-Scout-17B-16E-Instruct a través de la llamada a la API client.chat.completions.create().
La respuesta del modelo se imprime en verde utilizando Colorama y se añade de nuevo al historial de mensajes, lo que permite un diálogo de varias vueltas hasta que el usuario escribe "salir" o "abandonar".
En la siguiente sección, exploraremos cómo ejecutar la inferencia multimodal con entradas de imagen + texto utilizando la misma API.
En esta demostración, exploraremos cómo enviar entradas tanto de imagen como de texto al modelo LLaMA 4 Scout alojado a través de vLLM utilizando sus capacidades multimodales nativas. Esto te permite realizar razonamiento visual, subtitulado de imágenes o preguntas y respuestas multimodales, todo ello a través de una única API compatible con OpenAI.
Este ejemplo utiliza el SDK OpenAI para interactuar con el servidor vLLM. Si aún no está instalado, puedes ejecutarlo:
pip install openaiA continuación, importa el módulo necesario:
from openai import OpenAIConéctate a tu servidor vLLM local utilizando la interfaz compatible con OpenAI. Si tu servidor no requiere autenticación, utiliza "EMPTY" como clave API.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)El fragmento de código anterior inicializa un cliente compatible con OpenAI para la inferencia local utilizando el servidor vLLM. El api_key está configurado como "VACÍO" (no se requiere autenticación), y base_url apunta al punto final local de la API vLLM.
Ahora enviaremos un mensaje de chat que incluye una imagen y una instrucción de texto. LLaMA 4 Scout procesará la imagen junto con la consulta y devolverá una respuesta descriptiva.
messages = [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url1}},
{"type": "text", "text": "Can you describe what's in this image?"}
]
}
]
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
print("Response:", chat_response.choices[0].message.content)Una vez servida la inferencia multimodal mediante el modelo LLaMA 4 Scout, construimos una entrada tipo chat que contiene tanto una URL de imagen como una indicación de texto, formateadas según el esquema de chat de OpenAI. El método client.chat.completions.create() se utiliza para enviar esta solicitud multimodal al modelo, que procesa la imagen y el texto que la acompaña para generar una respuesta contextual.

En este tutorial, alojamos el modelo LLaMA 4 Scout de Meta utilizando vLLM en RunPod, haciéndolo accesible a través de puntos finales compatibles con OpenAI tanto para inferencia textual como multimodal. Combinando el alto rendimiento de vLLM y la potente infraestructura de RunPod, creamos una configuración rentable para servir LLMs de última generación con capacidades de contexto y visión prolongadas.
Para saber más sobre LLaMA 4 y vLLM, echa un vistazo:
Aprende IA con estos cursos
programa
Curso
Curso
blog
Stanislav Karzhev
9 min
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze
