

Lernpfad
Llama-Grundlagen
4 Std.
Die neuesten LLaMA 4-Modelle von Meta, Scout und Maverick, sind für Long-Context-Reasoning, multimodales Verstehen und effiziente Inferenz in großem Maßstab ausgelegt. In Verbindung mit vLLM, einer durchsatzstarken Inferenzmaschine mit OpenAI-kompatiblen APIs, werden diese Modelle für reale Anwendungen praktisch.
In diesem Blogpost zeige ich dir, wie du LLaMA 4 Scout auf einer Multi-GPU-RunPod-Instanz mit vLLM einsetzt und über einen lokalen oder entfernten OpenAI-kompatiblen API-Endpunkt bereitstellst. Wir behandeln die Einrichtung des Modells, den Einsatz und die API-Interaktion mit Text- und Bildeingaben.
Am Ende dieses Tutorials wirst du auch zwei vollständige Demos haben:
Wir halten unsere Leserinnen und Leser mit The Median auf dem Laufenden, unserem kostenlosen Freitags-Newsletter, der die wichtigsten Meldungen der Woche aufschlüsselt. Melde dich an und bleibe in nur ein paar Minuten pro Woche auf dem Laufenden:
vLLM (virtual large language model) ist ein optimiertes LLM-Inferenz-Framework, das ursprünglich am Sky Computing Lab der UC Berkeley entwickelt wurde. Es führt PagedAttention ein, ein neuartiges Speichermanagement-System, das die Fragmentierung des GPU-Speichers minimiert und ein effizientes Key-Value-Caching für extrem lange Sequenzen ermöglicht. Wenn du mehr erfahren möchtest, schau dir dieses Tutorial über vLLM.
Hier erfährst du, warum vLLM die ideale Engine für LLaMA 4 ist:
In diesem Abschnitt zeigen wir dir, wie du eine leistungsstarke Multi-GPU-Instanz auf RunPod bereitstellst, das LLaMA 4 Scout-Modell von Meta mit vLLM einsetzt und eine OpenAI-kompatible API für lokale und entfernte Inferenzen bereitstellst.
Bevor du das Modell startest, stelle sicher, dass dein RunPod-Konto eingerichtet ist:
Jetzt wollen wir einen Pod bereitstellen, der das 17B LLaMA 4 Scout Modell aufnehmen kann:

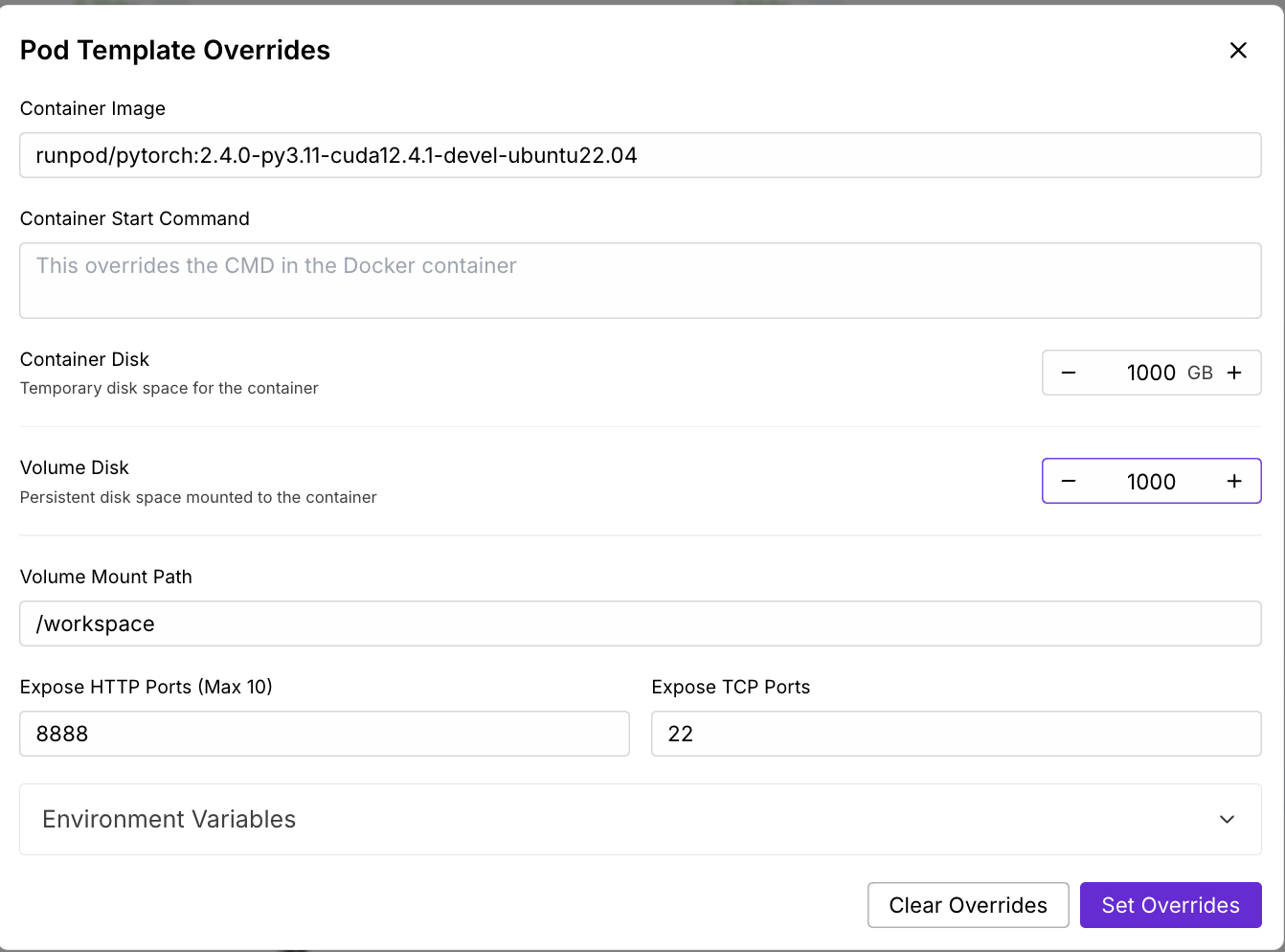
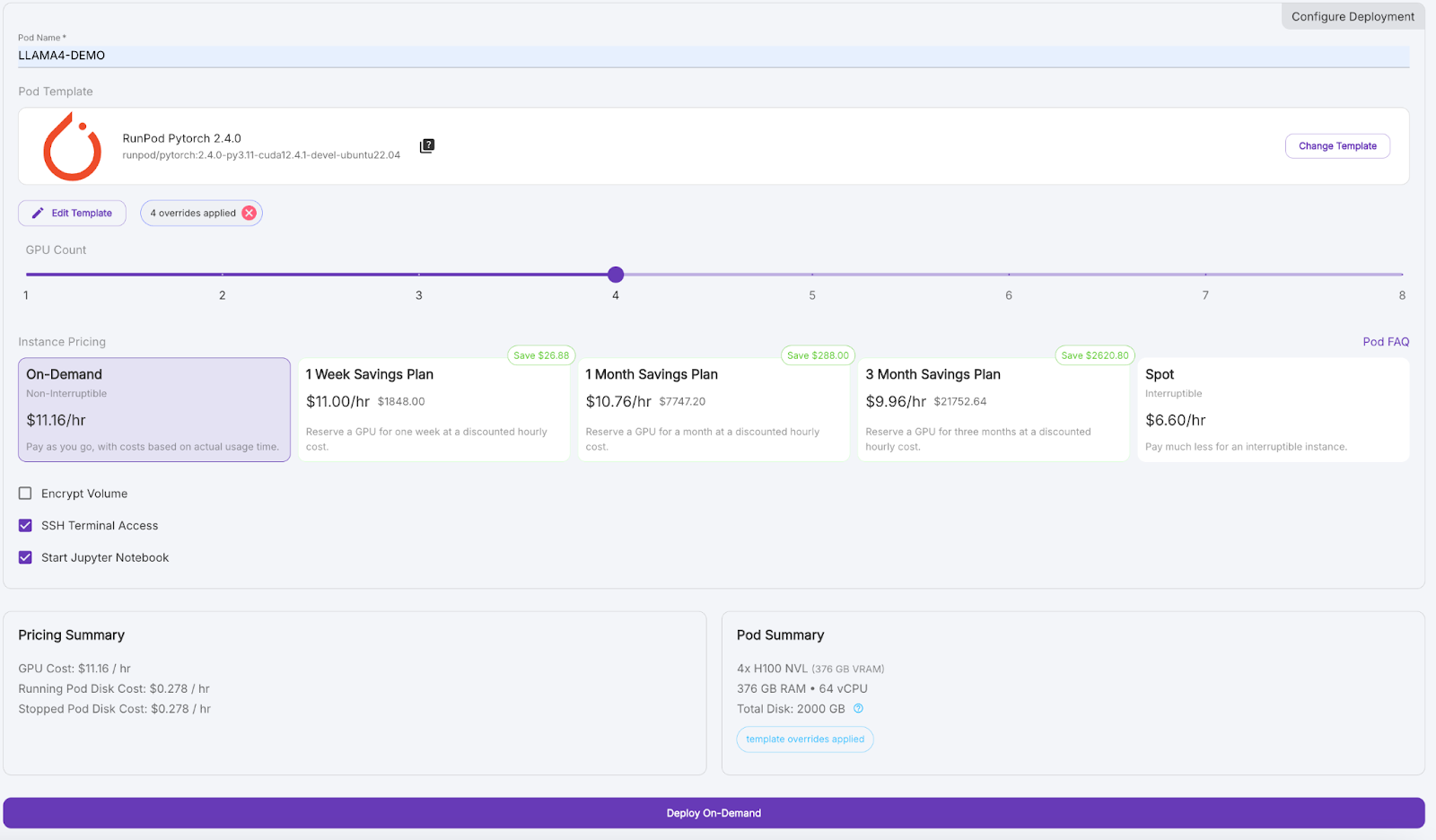
Warte ein paar Minuten, bis der Pod provisioniert ist.
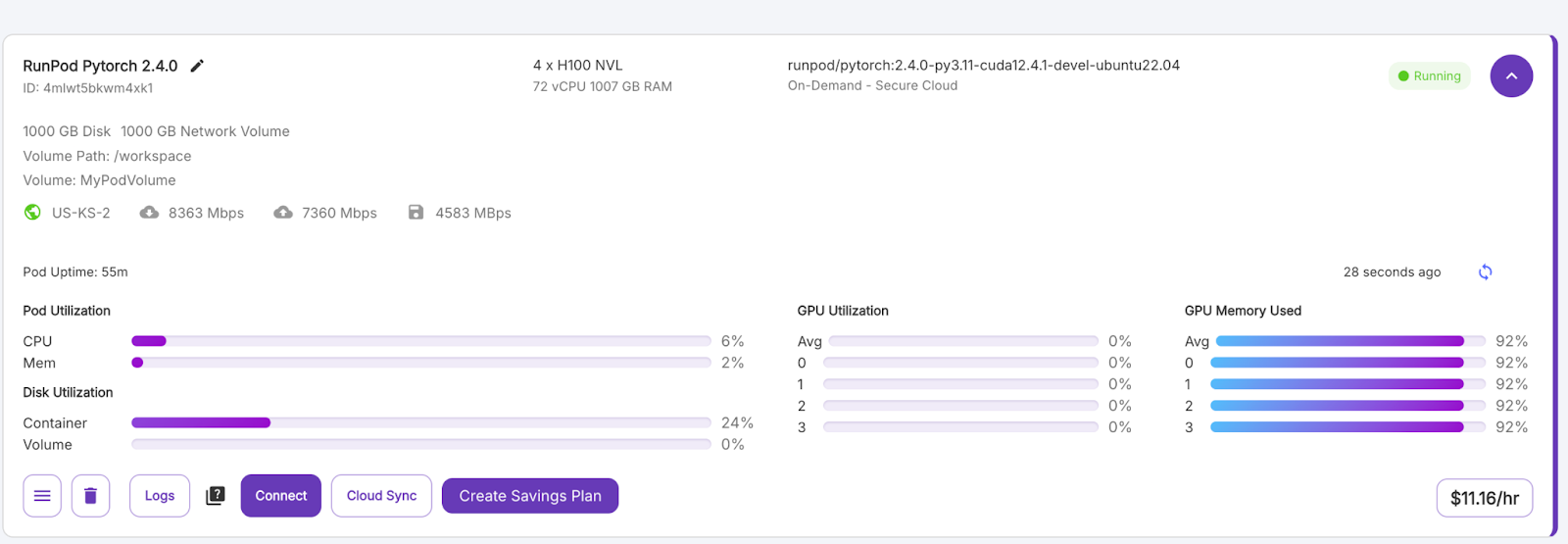
Sobald die Schaltfläche "Verbinden" lila wird, klicke sie an. Du wirst mehrere Verbindungsoptionen sehen - du kannst entweder:
Installiere im Terminal deines Pods vLLM und seine Abhängigkeiten. Installiere vLLM und andere Bibliotheken innerhalb der Pod-Umgebung.
pip install -U vllm
pip install transformers accelerate pillow #optionalAls Nächstes starten wir den LLaMA 4 Scout Modellserver mit dem folgenden Befehl:
VLLM_DISABLE_COMPILE_CACHE=1 vllm serve meta-llama/Llama-4-Scout-17B-16E-Instruct \
--tensor-parallel-size 4 \
--max-model-len 100000 --override-generation-config='{"attn_temperature_tuning": true}'Dieser Befehl macht Folgendes:

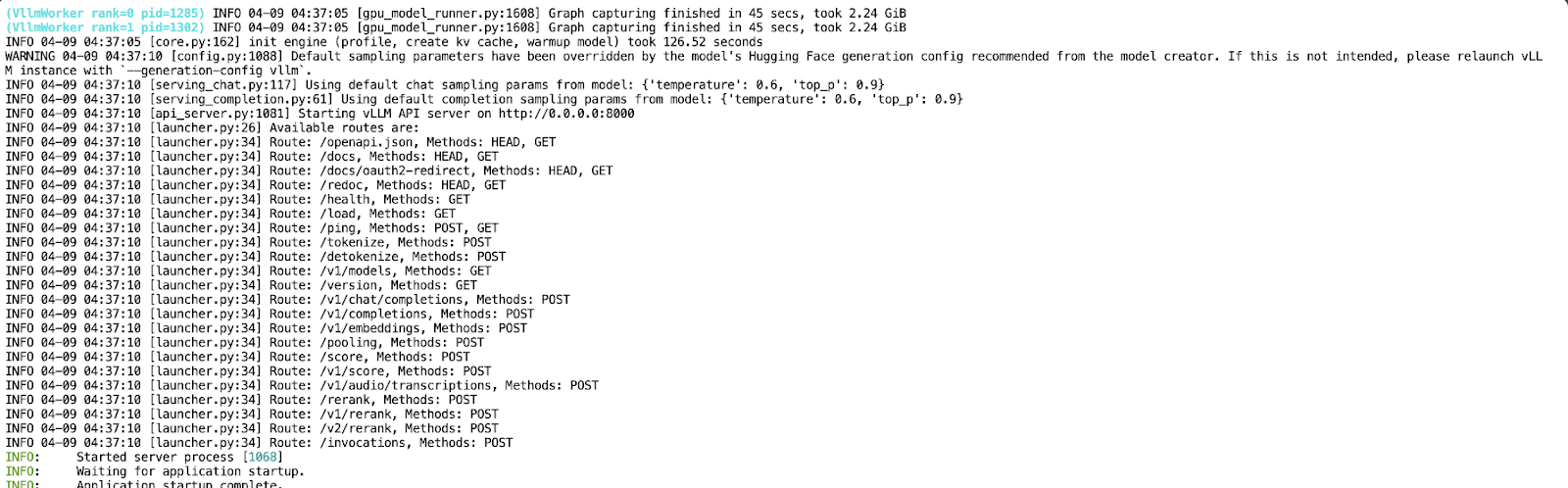
Jetzt, wo deine API auf Port 8000 läuft, erstellst du ein neues Jupyter Notebook in derselben Pod-Umgebung.
In dieser Demo werden wir mit einem einfachen Python-Skript mit dem lokal gehosteten LLaMA 4 Scout-Modell interagieren, das über vLLM bereitgestellt wird. Das Modell wird über eine API offengelegt, die es uns ermöglicht, einen Gesprächsassistenten zu entwickeln, der den Dialog mit mehreren Gesprächspartnern unterstützt.
Wir verwenden das offizielle OpenAI Python SDK, um mit der vLLM API zu kommunizieren, und die Colorama-Bibliothek für die farbige Terminalausgabe. Du kannst beides mit installieren:
pip install openai coloramaNach der Installation importierst du die erforderlichen Module:
from openai import OpenAI
from colorama import Fore, Style, initWir konfigurieren den OpenAI-Client so, dass er auf unseren lokal laufenden vLLM-Server zeigt. Wenn dein Einsatz keinen API-Schlüssel erfordert (das ist das Standardverhalten für lokale Läufe), gib "EMPTY" als Schlüssel an:
# Initialize colorama
init(autoreset=True)
# Set up client
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)Dieser Code initialisiert die Colorama-Bibliothek für die farbige Terminalausgabe mit einem automatischen Reset nach jedem Druck. Anschließend wird ein OpenAI-kompatibler Client mit der OpenAI-Klasse eingerichtet, der auf eine lokal gehostete vLLM-API verweist.
Schritt 3: Start der Chatschleife
Als Nächstes implementieren wir eine einfache Schleife, um eine kontinuierliche Interaktion mit dem Modell zu ermöglichen. Der Gesprächsverlauf bleibt über mehrere Runden hinweg erhalten, so dass der Dialog über mehrere Runden hinweg geführt werden kann.
# Initialize message history
messages = [
{"role": "system", "content": "You are a helpful assistant."}
]
print("Start chatting with the assistant! Type 'exit' or 'quit' to end.\n")
while True:
user_input = input(f"{Fore.BLUE}User: {Style.RESET_ALL}")
if user_input.strip().lower() in ["exit", "quit"]:
print("Exiting chat. Goodbye!")
break
messages.append({"role": "user", "content": user_input})
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
assistant_message = chat_response.choices[0].message.content
print(f"{Fore.GREEN}Assistant: {assistant_message}\n{Style.RESET_ALL}")
messages.append({"role": "assistant", "content": assistant_message})Ein einfaches terminalbasiertes Chat-Interface wird mit einem Gesprächsverlauf und einem Systemprompt initialisiert, das kontinuierlich Benutzereingaben in einer Schleife entgegennimmt. Jede Nutzernachricht wird an den Nachrichtenverlauf angehängt und über den API-Aufruf client.chat.completions.create() an das Modell Llama-4-Scout-17B-16E-Instruct gesendet.
Die Antwort des Modells wird mit Colorama in grüner Farbe gedruckt und dem Nachrichtenverlauf hinzugefügt, so dass ein Dialog mit mehreren Umdrehungen möglich ist, bis der Benutzer "exit" oder "quit" eingibt.
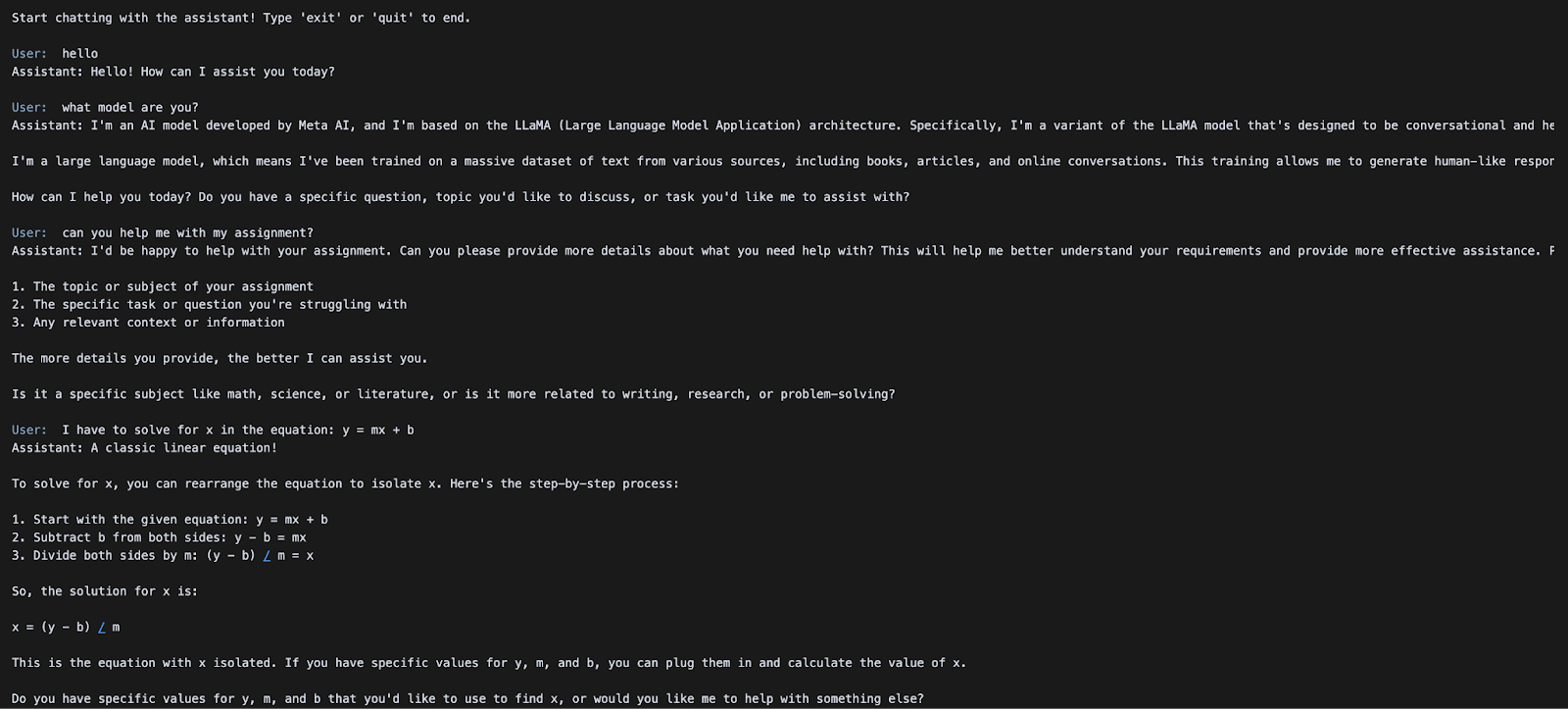
Im nächsten Abschnitt werden wir untersuchen, wie man multimodale Inferenzen mit Bild- und Texteingaben über dieselbe API durchführen kann.
In dieser Demo zeigen wir dir, wie du sowohl Bild- als auch Texteingaben an das LLaMA 4 Scout-Modell senden kannst, das über vLLM gehostet wird und dessen native multimodale Fähigkeiten nutzt. Damit kannst du visuelles Reasoning, Bildunterschriften oder multimodale Fragen und Antworten durchführen - alles über eine einzige OpenAI-kompatible API.
In diesem Beispiel wird das OpenAI SDK als Schnittstelle zum vLLM-Server verwendet. Wenn du es noch nicht installiert hast, kannst du es ausführen:
pip install openaiImportiere dann das gewünschte Modul:
from openai import OpenAIVerbinde dich mit deinem lokalen vLLM-Server über die OpenAI-kompatible Schnittstelle. Wenn dein Server keine Authentifizierung verlangt, verwende "EMPTY" als API-Schlüssel.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)Das obige Codeschnipsel initialisiert einen OpenAI-kompatiblen Client für lokale Inferenzen mit dem vLLM-Server. api_key ist auf "EMPTY" gesetzt (keine Anmeldung erforderlich) und base_url verweist auf den lokalen vLLM-API-Endpunkt.
Wir senden jetzt eine Chat-Aufforderung, die sowohl ein Bild als auch eine Textanweisung enthält. LLaMA 4 Scout verarbeitet das Bild zusammen mit der Abfrage und gibt eine beschreibende Antwort zurück.
messages = [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url1}},
{"type": "text", "text": "Can you describe what's in this image?"}
]
}
]
chat_response = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=messages,
)
print("Response:", chat_response.choices[0].message.content)Nachdem die multimodale Inferenz mit dem LLaMA 4 Scout-Modell durchgeführt wurde, erstellen wir eine Chat-Eingabe, die sowohl eine Bild-URL als auch eine Textaufforderung enthält, die nach dem OpenAI-Chat-Schema formatiert sind. Die Methode client.chat.completions.create() wird verwendet, um diese multimodale Anfrage an das Modell zu senden, das das Bild und den dazugehörigen Text verarbeitet, um eine kontextbezogene Antwort zu generieren.

In diesem Tutorial haben wir das LLaMA 4 Scout-Modell von Meta mit vLLM auf RunPod gehostet und es über OpenAI-kompatible Endpunkte für Text- und multimodale Inferenzen zugänglich gemacht. Durch die Kombination des hohen Durchsatzes von vLLM und der leistungsstarken Infrastruktur von RunPod haben wir ein kosteneffizientes Setup für die Bedienung moderner LLMs mit langen Kontext- und Vision-Fähigkeiten geschaffen.
Wenn du mehr über LLaMA 4 und vLLM erfahren möchtest, schau mal rein:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
Blog
Nisha Arya Ahmed
15 Min.
