
Cours
Introduction à Python
4 h
6.9M
Exécutez et modifiez le code de ce tutoriel en ligne
Exécuter le codeL'installation de pandas est simple ; il suffit d'utiliser la commande pip install dans votre terminal.
pip install pandasVous pouvez également l'installer via conda :
conda install pandasAprès avoir installé pandas, il est conseillé de vérifier la version installée pour s'assurer que tout fonctionne correctement :
import pandas as pd
print(pd.__version__) # Prints the pandas versionCela confirme que pandas est installé correctement et vous permet de vérifier la compatibilité avec d'autres paquets.
Pour commencer à travailler avec pandas, importez le paquetage Python pandas comme indiqué ci-dessous. Lors de l'importation de pandas, l'alias le plus courant pour pandas est pd.
import pandas as pdUtilisez read_csv() avec le chemin d'accès au fichier CSV pour lire un fichier de valeurs séparées par des virgules (voir notre tutoriel sur l'importation de données avec read_csv() pour plus de détails).
df = pd.read_csv("diabetes.csv")Cette opération de lecture charge le fichier CSV diabetes.csv pour générer un objet DataFrame pandas df. Tout au long de ce didacticiel, vous verrez comment manipuler de tels objets DataFrame.
La lecture des fichiers texte est similaire à celle des fichiers CSV. La seule nuance est que vous devez spécifier un séparateur avec l'argument sep, comme indiqué ci-dessous. L'argument séparateur fait référence au symbole utilisé pour séparer les lignes dans un DataFrame. La virgule (sep = ","), l'espace (sep = "\s"), la tabulation (sep = "\t") et les deux points (sep = ":") sont les séparateurs couramment utilisés. Ici, \s représente un seul caractère d'espace blanc.
df = pd.read_csv("diabetes.txt", sep="\s")La lecture des fichiers Excel (XLS et XLSX) est aussi simple que la fonction read_excel(), en utilisant le chemin d'accès au fichier comme entrée.
df = pd.read_excel('diabetes.xlsx')Vous pouvez également spécifier d'autres arguments, tels que header pour spécifier quelle ligne devient l'en-tête du DataFrame. La valeur par défaut est 0, ce qui indique la première ligne en tant qu'en-tête ou nom de colonne. Vous pouvez également spécifier les noms de colonnes sous forme de liste dans l'argument names. L'argument index_col ( None par défaut) peut être utilisé si le fichier contient un index de ligne.
Note : Dans un DataFrame ou une Series pandas, l'index est un identifiant qui pointe vers l'emplacement d'une ligne ou d'une colonne dans un DataFrame pandas. En bref, l'index étiquette la ligne ou la colonne d'un DataFrame et vous permet d'accéder à une ligne ou une colonne spécifique en utilisant son index (vous verrez cela plus loin). L'index de ligne d'un DataFrame peut être une plage (par exemple, de 0 à 303), une série temporelle (dates ou horodatages), un identifiant unique (par exemple, employee_ID dans un tableauemployees ) ou d'autres types de données. Pour les colonnes, il s'agit généralement d'une chaîne de caractères (indiquant le nom de la colonne).
La lecture de fichiers Excel comportant plusieurs feuilles n'est pas très différente. Il vous suffit de spécifier un argument supplémentaire, sheet_name, où vous pouvez passer soit une chaîne de caractères pour le nom de la feuille, soit un entier pour la position de la feuille (notez que Python utilise l'indexation 0, où la première feuille peut être accédée avec sheet_name = 0).
# Extracting the second sheet since Python uses 0-indexing
df = pd.read_excel('diabetes_multi.xlsx', sheet_name=1)Comme pour la fonction read_csv(), vous pouvez utiliser read_json() pour les types de fichiers JSON avec le nom du fichier JSON comme argument (pour plus de détails, lisez ce tutoriel sur l'importation de données JSON et HTML dans pandas). Le code ci-dessous lit un fichier JSON sur le disque et crée un objet DataFrame df.
df = pd.read_json("diabetes.json")Si vous souhaitez en savoir plus sur l'importation de données avec pandas, consultez cette antisèche sur l'importation de différents types de fichiers avec Python.
Pour charger des données à partir d'une base de données relationnelle, utilisez pd.read_sql() avec une connexion à la base de données.
import sqlite3
# Establish a connection to an SQLite database
conn = sqlite3.connect("my_database.db")
# Read data from a table
df = pd.read_sql("SELECT * FROM my_table", conn)Pour les grands ensembles de données, envisagez d'utiliser SQLAlchemy pour optimiser les requêtes.
Si vos données proviennent d'une API web, pandas peut les lire directement en utilisant pd.read_json():
df = pd.read_json("https://api.example.com/data.json")Si la réponse de l'API est paginée ou dans un format JSON imbriqué, il se peut que vous ayez besoin d'un traitement supplémentaire en utilisant json_normalize() à partir de pandas.io.json.
Tout comme pandas peut importer des données à partir de différents types de fichiers, il vous permet également d'exporter des données dans différents formats. Cela se produit surtout lorsque les données sont transformées à l'aide de pandas et doivent être sauvegardées localement sur votre machine. Vous trouverez ci-dessous la procédure à suivre pour convertir les DataFrame pandas en différents formats.
Un DataFrame pandas (ici nous utilisons df) est enregistré en tant que fichier CSV à l'aide de la méthode .to_csv(). Les arguments comprennent le nom du fichier avec le chemin d'accès et index - où index = True implique l'écriture de l'index du DataFrame.
df.to_csv("diabetes_out.csv", index=False)Exportez l'objet DataFrame dans un fichier JSON en appelant la méthode .to_json().
df.to_json("diabetes_out.json")Note : Un fichier JSON stocke un objet tabulaire tel qu'un DataFrame sous la forme d'une paire clé-valeur. Ainsi, vous observerez des en-têtes de colonne répétitifs dans un fichier JSON.
Comme pour l'écriture de DataFrame dans des fichiers CSV, vous pouvez appeler .to_csv(). Les seules différences sont que le format du fichier de sortie est en .txt, et que vous devez spécifier un séparateur en utilisant l'argument sep.
df.to_csv('diabetes_out.txt', header=df.columns, index=None, sep=' ')Appelez .to_excel() à partir de l'objet DataFrame pour l'enregistrer en tant que fichier “.xls” ou “.xlsx”.
df.to_excel("diabetes_out.xlsx", index=False)Après avoir lu des données tabulaires sous forme de DataFrame, vous avez besoin d'avoir un aperçu des données. Vous pouvez visualiser un petit échantillon de l'ensemble de données ou un résumé des données sous la forme de statistiques sommaires.
.head() et .tail()Vous pouvez afficher les premières ou les dernières lignes d'un DataFrame à l'aide des méthodes .head() ou .tail(), respectivement. Vous pouvez spécifier le nombre de lignes à l'aide de l'argument n (la valeur par défaut est 5).
df.head()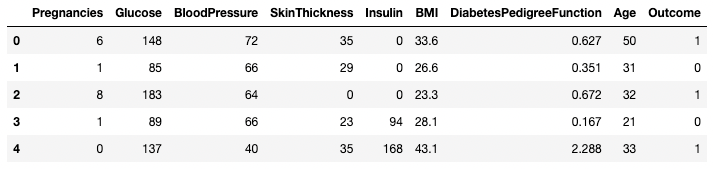
Cinq premières lignes du DataFrame
df.tail(n = 10)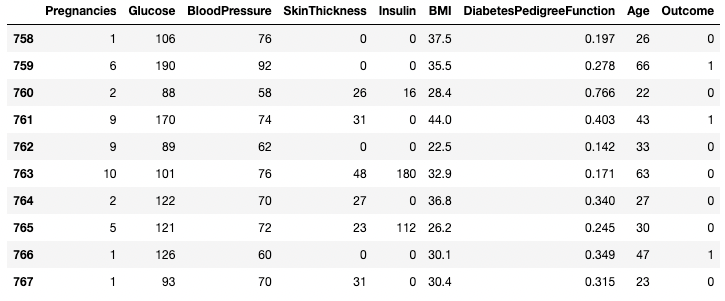
Les 10 premières lignes du DataFrame
.describe()La méthode .describe() permet d'imprimer les statistiques récapitulatives de toutes les colonnes numériques, telles que le nombre, la moyenne, l'écart type, l'étendue et les quartiles des colonnes numériques.
df.describe()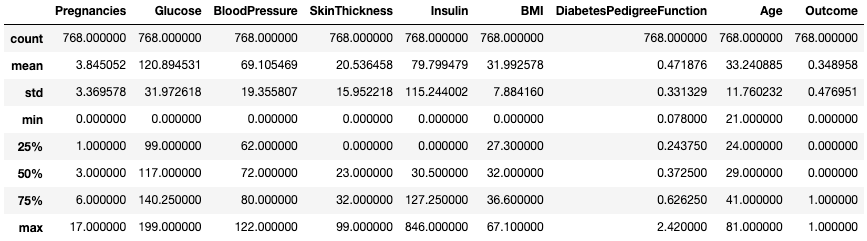
Obtenez des statistiques sommaires avec .describe()
Il permet de visualiser rapidement l'échelle, l'inclinaison et l'étendue des données numériques.
Vous pouvez également modifier les quartiles en utilisant l'argument percentiles. Ici, par exemple, nous examinons les percentiles 30 %, 50 % et 70 % des colonnes numériques du DataFrame df.
df.describe(percentiles=[0.3, 0.5, 0.7])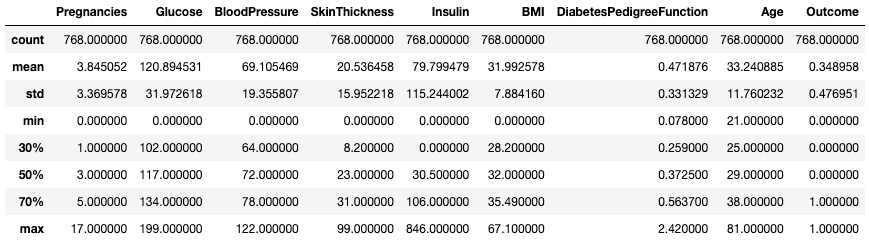
Obtenir des statistiques sommaires avec des percentiles spécifiques
Vous pouvez également isoler des types de données spécifiques dans votre résumé en utilisant l'argument include. Ici, par exemple, nous ne résumons que les colonnes avec le type de données integer.
df.describe(include=[int])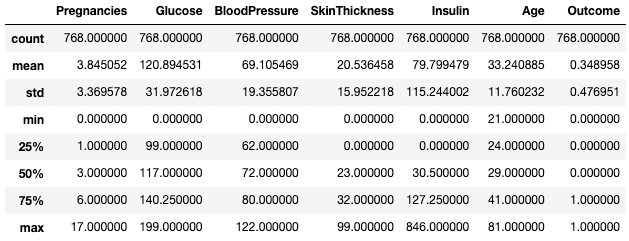
Obtenez des statistiques sommaires pour les colonnes de nombres entiers uniquement
De même, vous pouvez vouloir exclure certains types de données en utilisant l'argument exclude.
df.describe(exclude=[int])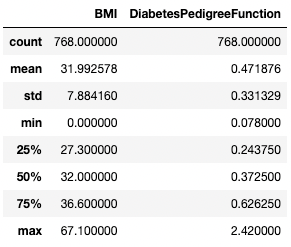
Obtenir des statistiques sommaires pour les colonnes non entières uniquement
Souvent, les praticiens trouvent facile de visualiser ces statistiques en les transposant à l'aide de l'attribut .T.
df.describe().T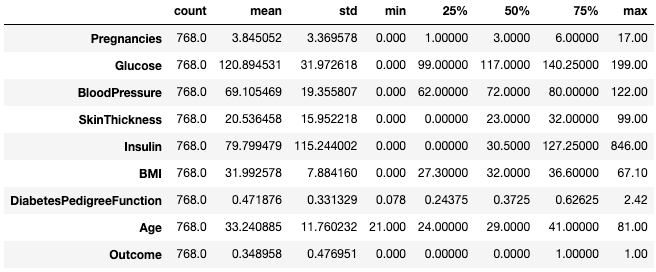
Transposez les statistiques sommaires avec .T
Pour en savoir plus sur la description des DataFrame, consultez l'aide-mémoire suivant.
.info()La méthode .info() est un moyen rapide d'examiner les types de données, les valeurs manquantes et la taille des données d'un DataFrame. Ici, nous fixons l'argument show_counts à True, ce qui donne quelques valeurs sur le total des valeurs non manquantes dans chaque colonne. Nous attribuons également la valeur memory_usage à True, qui indique l'utilisation totale de la mémoire des éléments du DataFrame. Lorsque verbose est défini sur True, il imprime le résumé complet de .info().
df.info(show_counts=True, memory_usage=True, verbose=True)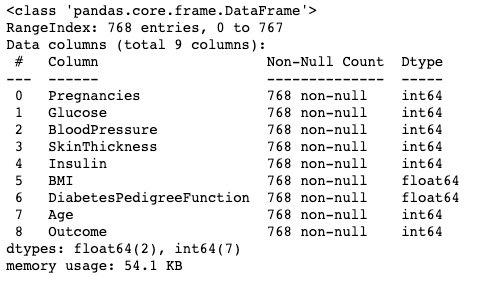
.shapeLe nombre de lignes et de colonnes d'un DataFrame peut être identifié à l'aide de l'attribut .shape du DataFrame. Il renvoie un tuple (ligne, colonne) et peut être indexé pour n'obtenir que des lignes, et seules les colonnes sont comptabilisées en sortie.
df.shape # Get the number of rows and columns
df.shape[0] # Get the number of rows only
df.shape[1] # Get the number of columns only(768,9)
768
9L'appel de l'attribut .columns d'un objet DataFrame renvoie les noms des colonnes sous la forme d'un objet Index. Pour rappel, un index pandas est l'adresse/l'étiquette de la ligne ou de la colonne.
df.columns
Il peut être converti en liste à l'aide d'une fonction list().
list(df.columns)
.isnull()Le DataFrame de l'échantillon ne contient aucune valeur manquante. Présentons-en quelques-uns pour rendre les choses plus intéressantes. La méthode .copy() crée une copie du DataFrame original. Cela permet de s'assurer que toute modification apportée à la copie ne se répercute pas sur le DataFrame d'origine. En utilisant .loc (voir plus loin), vous pouvez attribuer aux lignes deux à cinq de la colonne Pregnancies des valeurs NaN, qui indiquent des valeurs manquantes.
df2 = df.copy()
df2.loc[2:5,'Pregnancies'] = None
df2.head(7)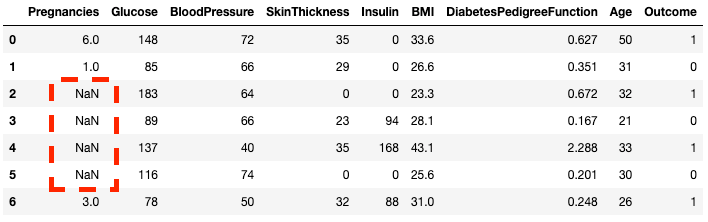
Vous pouvez constater que les lignes 2 à 5 sont maintenant NaN
Vous pouvez vérifier si chaque élément d'un DataFrame est manquant à l'aide de la méthode .isnull().
df2.isnull().head(7)Étant donné qu'il est souvent plus utile de connaître le nombre de données manquantes, vous pouvez combiner .isnull() avec .sum() pour compter le nombre de données nulles dans chaque colonne.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64Vous pouvez également effectuer une double somme pour obtenir le nombre total de zéros dans le DataFrame.
df2.isnull().sum().sum()4Le package pandas offre plusieurs façons de trier, de sous-ensembler, de filtrer et d'isoler les données dans vos DataFrame. Nous verrons ici les moyens les plus courants.
Pour trier un DataFrame en fonction d'une colonne spécifique :
df.sort_values(by="Age", ascending=False, inplace=True) # Sort by Age in descending orderVous pouvez trier sur plusieurs colonnes :
df.sort_values(by=["Age", "Glucose"], ascending=[False, True], inplace=True)Si vous filtrez ou triez un DataFrame, votre index risque d'être mal aligné. Utilisez .reset_index() pour résoudre ce problème :
df.reset_index(drop=True, inplace=True) # Resets index and removes old index columnPour extraire des données en fonction d'une condition :
df[df["BloodPressure"] > 100] # Selects rows where BloodPressure is greater than 100[ ] Vous pouvez isoler une seule colonne à l'aide d'un crochet [ ] contenant le nom d'une colonne. Le résultat est un objet pandas Series. Une série pandas est un tableau unidimensionnel contenant des données de n'importe quel type, notamment des entiers, des flottants, des chaînes de caractères, des booléens, des objets python, etc. Un DataFrame est composé de nombreuses séries qui jouent le rôle de colonnes.
df['Outcome']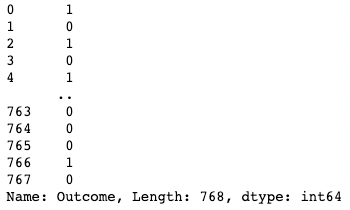
Isolation d'une colonne dans pandas
[[ ]] Vous pouvez également fournir une liste de noms de colonnes à l'intérieur des crochets pour récupérer plus d'une colonne. Ici, les crochets sont utilisés de deux manières différentes. Nous utilisons les crochets extérieurs pour indiquer un sous-ensemble d'un DataFrame, et les crochets intérieurs pour créer une liste.
df[['Pregnancies', 'Outcome']]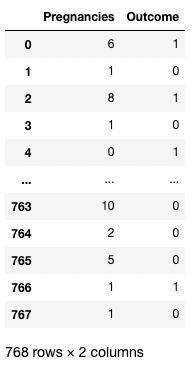
Isolation de deux colonnes dans pandas
[ ] Une seule ligne peut être récupérée en transmettant une série booléenne avec une valeur True. Dans l'exemple ci-dessous, la deuxième ligne contenant index = 1 est renvoyée. Ici, .index renvoie les étiquettes de ligne du DataFrame, et la comparaison les transforme en un tableau unidimensionnel booléen.
df[df.index==1]
Isolation d'une ligne dans pandas
[ ] De même, deux lignes ou plus peuvent être renvoyées à l'aide de la méthode .isin() au lieu de l'opérateur ==.
df[df.index.isin(range(2,10))]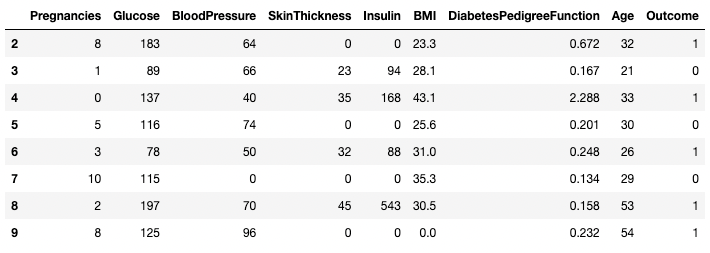
Isoler des lignes spécifiques dans pandas
.loc[] et .iloc[] pour récupérer les lignesVous pouvez rechercher des lignes spécifiques par étiquettes ou conditions en utilisant .loc[] et .iloc[] ("location" et "integer location"). .loc[] utilise une étiquette pour pointer vers une ligne, une colonne ou une cellule, tandis que .iloc[] utilise la position numérique. Pour comprendre la différence entre les deux, modifions l'index de df2 créé précédemment.
df2.index = range(1,769)L'exemple ci-dessous renvoie un pandas Series au lieu d'un DataFrame. Le 1 représente l'index de la ligne (étiquette), tandis que le 1 dans .iloc[] est la position de la ligne (première ligne).
df2.loc[1]Pregnancies 6.000
Glucose 148.000
BloodPressure 72.000
SkinThickness 35.000
Insulin 0.000
BMI 33.600
DiabetesPedigreeFunction 0.627
Age 50.000
Outcome 1.000
Name: 1, dtype: float64df2.iloc[1]Pregnancies 1.000
Glucose 85.000
BloodPressure 66.000
SkinThickness 29.000
Insulin 0.000
BMI 26.600
DiabetesPedigreeFunction 0.351
Age 31.000
Outcome 0.000
Name: 2, dtype: float64Vous pouvez également récupérer plusieurs lignes en indiquant un intervalle entre crochets.
df2.loc[100:110]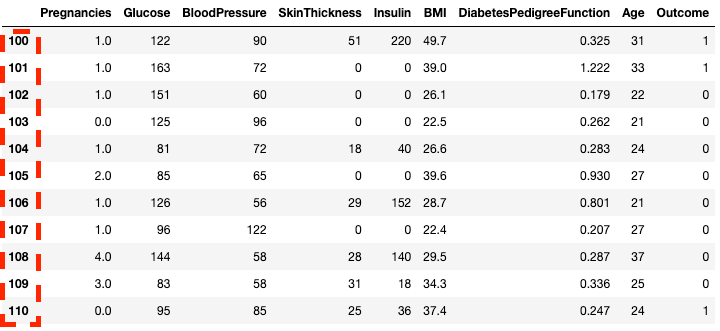
Isoler les lignes dans pandas avec .loc[]
df2.iloc[100:110]![Isoler les lignes dans pandas avec .loc[]](https://images.datacamp.com/image/upload/v1668597143/image28_07af2245c8.png)
Isoler les lignes dans pandas avec .iloc[]
Vous pouvez également utiliser les sous-ensembles .loc[] et .iloc[] en utilisant une liste au lieu d'un intervalle.
df2.loc[[100, 200, 300]]![Isoler des lignes en utilisant une liste dans pandas avec .loc[]](https://images.datacamp.com/image/upload/v1668597142/image31_c5acf2a9bd.png)
Isoler des lignes à l'aide d'une liste dans pandas avec .loc[]
df2.iloc[[100, 200, 300]]
Isoler des lignes à l'aide d'une liste dans pandas avec .iloc[]
Vous pouvez également sélectionner des colonnes et des lignes spécifiques. C'est là que .iloc[] diffère de .loc[] - il requiert l'emplacement des colonnes et non les étiquettes des colonnes.
df2.loc[100:110, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isoler des colonnes à l'aide d'une liste dans pandas avec .loc[]](https://images.datacamp.com/image/upload/v1668597142/image7_40bb6ca301.png)
Isolement des colonnes dans pandas avec .loc[]
df2.iloc[100:110, :3]![Isolation des colonnes dans pandas avec .iloc[]](https://images.datacamp.com/image/upload/v1668597143/image42_bf1e7b2f49.png)
Isolement des colonnes à l'aide de .iloc[]
Pour des flux de travail plus rapides, vous pouvez transmettre l'indice de départ d'une ligne sous la forme d'une plage.
df2.loc[760:, ['Pregnancies', 'Glucose', 'BloodPressure']]![Isolation des colonnes dans pandas avec .loc[]](https://images.datacamp.com/image/upload/v1668597142/image33_863cb34962.png)
Isoler les colonnes et les lignes dans pandas avec .loc[]
df2.iloc[760:, :3]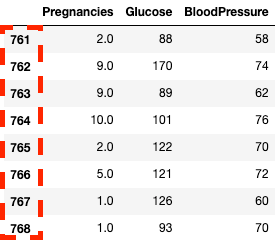
Isoler les colonnes et les lignes dans pandas avec .iloc[]
Vous pouvez mettre à jour/modifier certaines valeurs en utilisant l'opérateur d'affectation =
df2.loc[df['Age']==81, ['Age']] = 80pandas vous permet de filtrer les données par des conditions sur les valeurs des lignes/colonnes. Par exemple, le code ci-dessous sélectionne la ligne où la tension artérielle est exactement de 122. Ici, nous isolons les lignes à l'aide des crochets [ ], comme nous l'avons vu dans les sections précédentes. Cependant, au lieu de saisir des indices de ligne ou des noms de colonne, nous saisissons une condition dans laquelle la colonne BloodPressure est égale à 122. Nous désignons cette condition par df.BloodPressure == 122.
df[df.BloodPressure == 122]
Isoler des lignes en fonction d'une condition dans pandas
L'exemple ci-dessous extrait toutes les lignes pour lesquelles Outcome est égal à 1. Ici, df.Outcome sélectionne cette colonne, df.Outcome == 1 renvoie une série de valeurs booléennes déterminant lesquelles Outcomes sont égales à 1, puis [] prend un sous-ensemble de df où cette série booléenne est True.
df[df.Outcome == 1]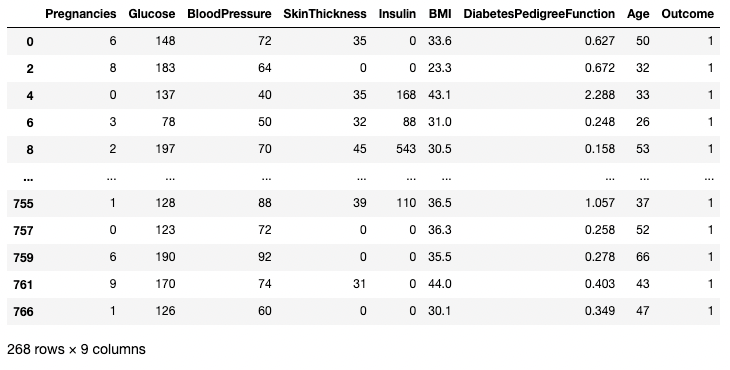
Isoler des lignes en fonction d'une condition dans pandas
Vous pouvez utiliser un opérateur > pour établir des comparaisons. Le code ci-dessous recherche Pregnancies, Glucose, et BloodPressure pour tous les enregistrements dont BloodPressure est supérieur à 100.
df.loc[df['BloodPressure'] > 100, ['Pregnancies', 'Glucose', 'BloodPressure']]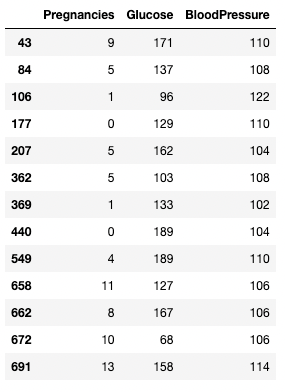
Isoler des lignes et des colonnes en fonction d'une condition dans pandas
Le nettoyage des données est l'une des tâches les plus courantes en science des données. pandas vous permet de prétraiter les données pour n'importe quelle utilisation, y compris, mais sans s'y limiter, l'entraînement des modèles d'apprentissage automatique et d'apprentissage profond. Utilisons le DataFrame df2 de tout à l'heure, avec quatre valeurs manquantes, pour illustrer quelques cas d'utilisation du nettoyage de données. Pour rappel, voici comment vous pouvez voir le nombre de valeurs manquantes dans un DataFrame.
df2.isnull().sum()Pregnancies 4
Glucose 0
BloodPressure 0
SkinThickness 0
Insulin 0
BMI 0
DiabetesPedigreeFunction 0
Age 0
Outcome 0
dtype: int64L'une des façons de traiter les données manquantes est de les supprimer. Ceci est particulièrement utile dans les cas où vous disposez de nombreuses données et où la perte d'une petite partie n'aura pas d'impact sur l'analyse en aval. Vous pouvez utiliser la méthode .dropna() comme indiqué ci-dessous. Ici, nous enregistrons les résultats de .dropna() dans un DataFrame df3.
df3 = df2.copy()
df3 = df3.dropna()
df3.shape(764, 9) # this is 4 rows less than df2L'argument axis vous permet de spécifier si vous abandonnez les lignes ou les colonnes contenant des valeurs manquantes. La valeur par défaut axis supprime les lignes contenant des NaN. Utilisez axis = 1 pour supprimer les colonnes contenant une ou plusieurs valeurs NaN. Remarquez également que nous utilisons l'argument inplace=True qui vous permet de ne pas enregistrer la sortie de .dropna() dans un nouveau DataFrame.
df3 = df2.copy()
df3.dropna(inplace=True, axis=1)
df3.head()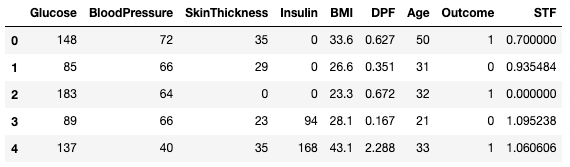
Suppression des données manquantes dans pandas
Vous pouvez également supprimer les lignes et les colonnes comportant des valeurs manquantes en définissant l'argument how comme suit 'all'
df3 = df2.copy()
df3.dropna(inplace=True, how='all')Au lieu d'abandonner, remplacer les valeurs manquantes par une statistique récapitulative ou une valeur spécifique (en fonction du cas d'utilisation) est peut-être la meilleure solution. Par exemple, s'il manque une ligne dans une colonne indiquant les températures au cours des jours de la semaine, le remplacement de cette valeur manquante par la température moyenne de cette semaine peut être plus efficace que l'abandon complet des valeurs. Vous pouvez remplacer les données manquantes par la moyenne de la ligne ou de la colonne à l'aide du code ci-dessous.
df3 = df2.copy()
# Get the mean of Pregnancies
mean_value = df3['Pregnancies'].mean()
# Fill missing values using .fillna()
df3 = df3.fillna(mean_value)Ajoutons quelques doublons aux données d'origine pour apprendre à éliminer les doublons dans un DataFrame. Ici, nous utilisons la méthode .concat() pour concaténer les lignes du DataFrame df2 au DataFrame df2, en ajoutant des doublons parfaits de chaque ligne dans df2.
df3 = pd.concat([df2, df2])
df3.shape(1536, 9)Vous pouvez supprimer toutes les lignes dupliquées (par défaut) du DataFrame à l'aide de la méthode .drop_duplicates() .
df3 = df3.drop_duplicates()
df3.shape(768, 9)Une tâche courante de nettoyage des données consiste à renommer les colonnes. Avec la méthode .rename(), vous pouvez utiliser columns comme argument pour renommer des colonnes spécifiques. Le code ci-dessous montre le dictionnaire permettant de faire correspondre les anciens et les nouveaux noms de colonnes.
df3.rename(columns = {'DiabetesPedigreeFunction':'DPF'}, inplace = True)
df3.head()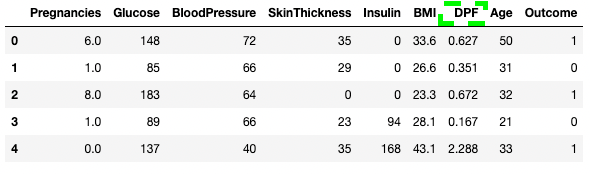
Renommer des colonnes dans pandas
Vous pouvez également attribuer directement des noms de colonnes sous forme de liste au DataFrame.
df3.columns = ['Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DPF', 'Age', 'Outcome', 'STF']
df3.head()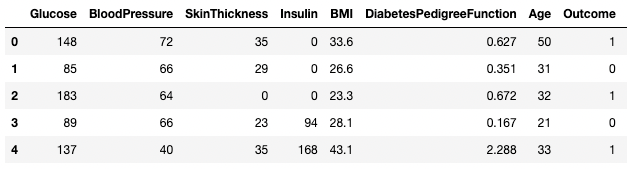
Renommer des colonnes dans pandas
Pour en savoir plus sur le nettoyage des données, et pour des flux de travail plus faciles et plus prévisibles, consultez la liste de contrôle suivante, qui vous fournit un ensemble complet de tâches courantes de nettoyage des données.
La principale proposition de valeur de pandas réside dans sa fonctionnalité d'analyse rapide des données. Dans cette section, nous nous concentrerons sur un ensemble de techniques d'analyse que vous pouvez utiliser dans pandas.
Comme vous l'avez vu précédemment, vous pouvez obtenir la moyenne de chaque valeur de colonne en utilisant la méthode .mean().
df.mean()
Impression de la moyenne des colonnes dans pandas
Un mode peut être calculé de la même manière en utilisant la méthode .mode().
df.mode()
Impression du mode des colonnes dans pandas
De même, la médiane de chaque colonne est calculée à l'aide de la méthode .median().
df.median()
Impression de la médiane des colonnes en pandas
pandas permet des calculs rapides et efficaces en combinant deux colonnes ou plus comme des variables scalaires. Le code ci-dessous divise chaque valeur de la colonne Glucose avec la valeur correspondante de la colonne Insulin pour calculer une nouvelle colonne nommée Glucose_Insulin_Ratio.
df2['Glucose_Insulin_Ratio'] = df2['Glucose']/df2['Insulin']
df2.head()
Créez une nouvelle colonne à partir de colonnes existantes dans pandas
.value_counts()Vous travaillez souvent avec des valeurs catégorielles et vous souhaitez compter le nombre d'observations de chaque catégorie dans une colonne. Les valeurs des catégories peuvent être comptées à l'aide des méthodes .value_counts(). Ici, par exemple, nous comptons le nombre d'observations où Outcome est diabétique (1) et le nombre d'observations où Outcome n'est pas diabétique (0).
df['Outcome'].value_counts()
Utilisation de .value_counts() dans pandas
L'ajout de l'argument normalize renvoie des proportions au lieu de chiffres absolus.
df['Outcome'].value_counts(normalize=True)
Utilisation de .value_counts() dans pandas avec normalisation
Désactive le tri automatique des résultats utilisant l'argument sort (True par défaut). Le tri par défaut est basé sur les nombres dans l'ordre décroissant.
df['Outcome'].value_counts(sort=False)
Utilisation de .value_counts() dans pandas avec le tri
Vous pouvez également appliquer .value_counts() à un objet DataFrame et à des colonnes spécifiques à l'intérieur de celui-ci au lieu d'une seule colonne. Ici, par exemple, nous appliquons value_counts() à df avec l'argument subset, qui prend en compte une liste de colonnes.
df.value_counts(subset=['Pregnancies', 'Outcome'])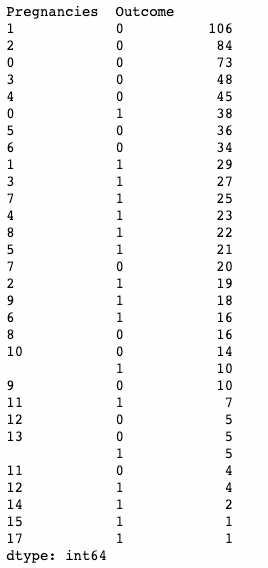
Utilisation de .value_counts() dans pandas lors du sous-ensemble des colonnes
.groupby() dans les pandaspandas vous permet d'agréger des valeurs en les regroupant par valeurs de colonnes spécifiques. Vous pouvez le faire en combinant la méthode .groupby() avec une méthode de synthèse de votre choix. Le code ci-dessous affiche la moyenne de chacune des colonnes numériques regroupées par Outcome.
df.groupby('Outcome').mean()
Agréger des données par une colonne dans pandas
.groupby() permet de regrouper les données en fonction de plusieurs colonnes en transmettant une liste de noms de colonnes, comme indiqué ci-dessous.
df.groupby(['Pregnancies', 'Outcome']).mean()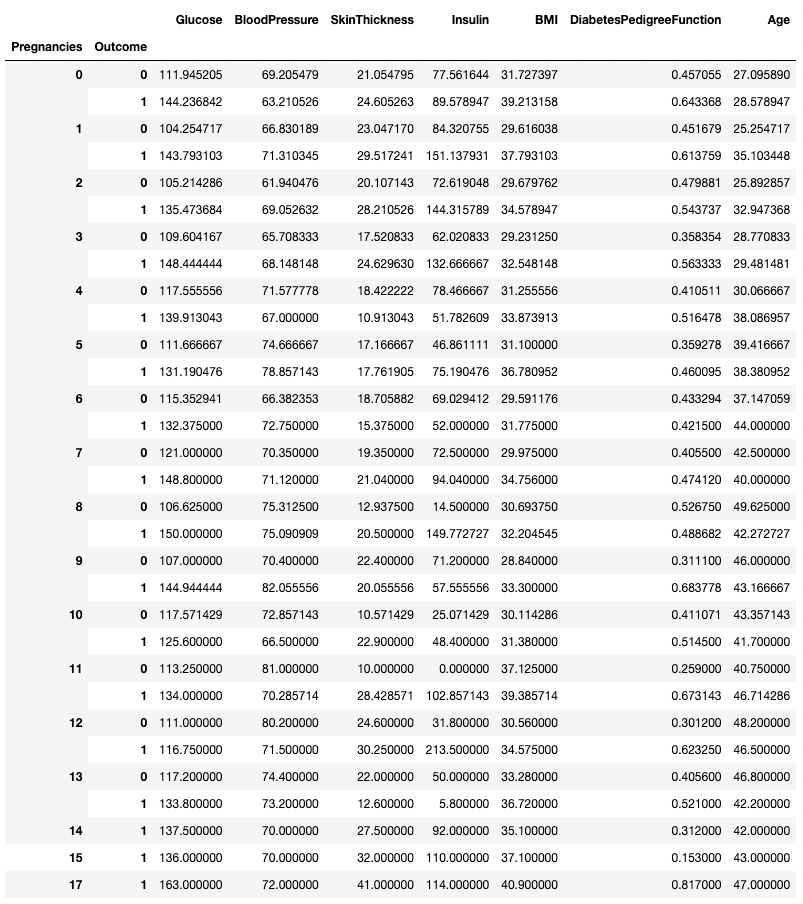
Agrégation de données sur deux colonnes dans pandas
Toute méthode de résumé peut être utilisée avec .groupby(), y compris .min(), .max(), .mean(), .median(), .sum(), .mode(), et bien d'autres encore.
pandas vous permet également de calculer des statistiques récapitulatives sous forme de tableaux croisés dynamiques. Il est donc facile de tirer des conclusions sur la base d'une combinaison de variables. Le code ci-dessous sélectionne les lignes comme valeurs uniques de Pregnancies, les valeurs des colonnes sont les valeurs uniques de Outcome, et les cellules contiennent la valeur moyenne de BMI dans le groupe correspondant.
Par exemple, pour Pregnancies = 5 et Outcome = 0, l'IMC moyen est de 31,1.
pd.pivot_table(df, values="BMI", index='Pregnancies',
columns=['Outcome'], aggfunc=np.mean)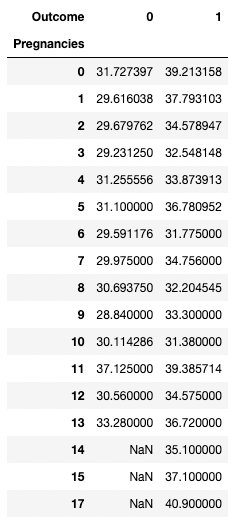
Agrégation de données par pivotement avec pandas
pandas fournit des wrappers de commodité aux fonctions de traçage de Matplotlib pour faciliter la visualisation de vos DataFrame. Ci-dessous, vous verrez comment réaliser des visualisations de données courantes à l'aide de pandas.
pandas vous permet de représenter graphiquement les relations entre les variables à l'aide de tracés linéaires. Vous trouverez ci-dessous un graphique linéaire de l'IMC et du glucose en fonction de l'indice de rangée.
df[['BMI', 'Glucose']].plot.line()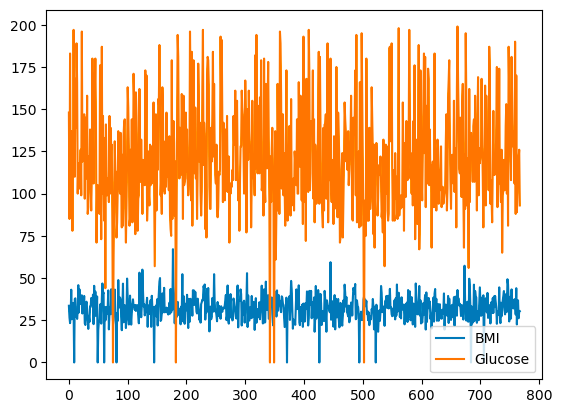
Graphique linéaire de base avec pandas
Vous pouvez sélectionner le choix de couleurs en utilisant l'argument de couleur.
df[['BMI', 'Glucose']].plot.line(figsize=(20, 10),
color={"BMI": "red", "Glucose": "blue"})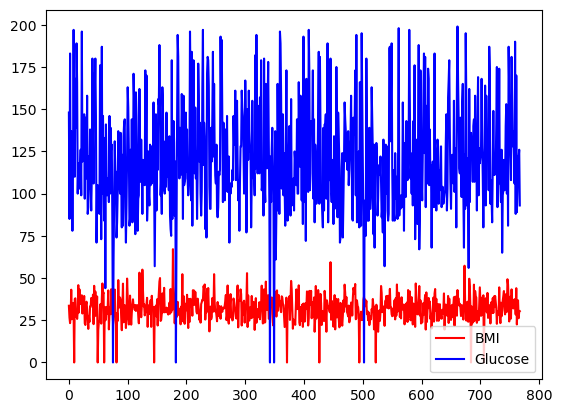
Tracé linéaire de base avec pandas, avec des couleurs personnalisées
Toutes les colonnes de df peuvent également être représentées sur des échelles et des axes différents en utilisant l'argument subplots.
df.plot.line(subplots=True)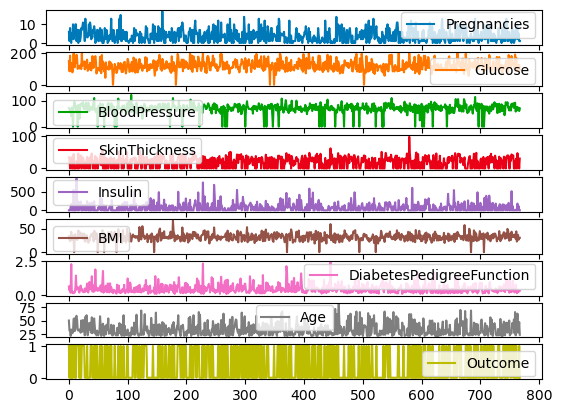
Sous-plots pour les tracés linéaires avec pandas
Pour les colonnes discrètes, vous pouvez utiliser un diagramme à barres sur les nombres de catégories pour visualiser leur distribution. La variable Outcome avec des valeurs binaires est visualisée ci-dessous.
df['Outcome'].value_counts().plot.bar()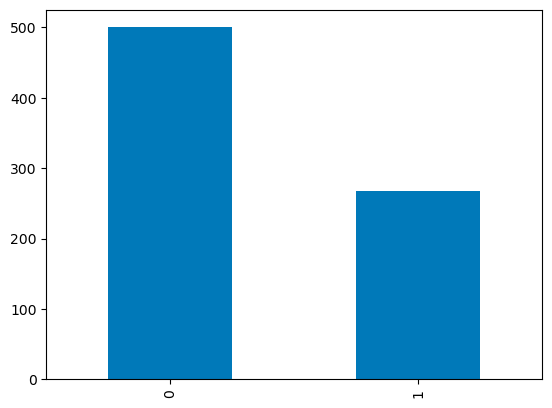
Diagrammes en barres dans les pandas
La distribution des quartiles des variables continues peut être visualisée à l'aide d'un diagramme en boîte. Le code ci-dessous vous permet de créer un diagramme en boîte avec pandas.
df.boxplot(column=['BMI'], by='Outcome')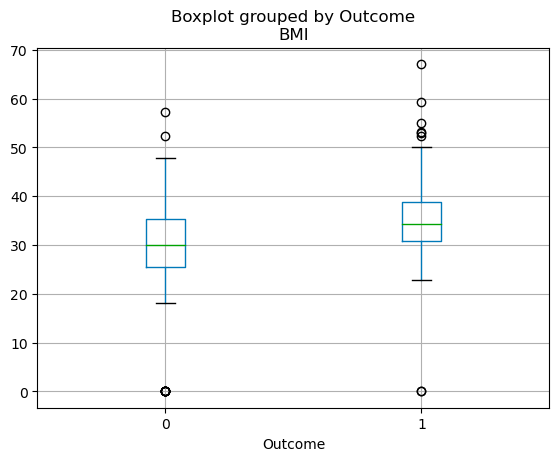
Boxplots en pandas
Le tutoriel ci-dessus ne fait qu'effleurer les possibilités offertes par les pandas. Qu'il s'agisse d'analyser des données, de les visualiser, de les filtrer ou de les agréger, pandas offre un ensemble de fonctionnalités incroyablement riche qui vous permet d'accélérer n'importe quel flux de données. De plus, en combinant pandas avec d'autres progiciels de science des données, vous pourrez créer des tableaux de bord interactifs, des modèles prédictifs à l'aide de l'apprentissage automatique, automatiser les flux de données, et bien plus encore. Consultez les ressources ci-dessous pour accélérer votre parcours d'apprentissage des pandas :
Plus de cours sur les pandas
Cours
Cours
Cours
Tutoriel
Sejal Jaiswal
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
Matt Crabtree
Tutoriel
Sejal Jaiswal
Tutoriel
Mark Pedigo