
Cours
Introduction à la régression dans R
4 h
77.1K
La réalisation d'une recherche approfondie est complexe et nécessite une planification minutieuse, notamment en ce qui concerne la répartition des participants dans les groupes de traitement qui incluent le traitement (ou, en d'autres termes, l'intervention) par rapport aux groupes de contrôle qui ne l'incluent pas.
L'une de ces approches consiste à répartir les participants de manière aléatoire dans l'un ou l'autre groupe afin de minimiser les biais. Cette affectation aléatoire permet d'attribuer les différences de résultats au traitement plutôt qu'à d'autres variables. Cependant, il n'est pas toujours possible de procéder à des affectations aléatoires pour des raisons éthiques, pratiques ou logistiques. Dans ce cas, les chercheurs ont recours à d'autres solutions, telles que les études d'observation, qui reposent sur la simple observation de ce qui se passe naturellement dans le monde réel. Bien que précieux, ces modèles de recherche peuvent conduire à un biais de sélection, influençant les résultats de l'étude.
Pour résoudre le problème du biais de sélection, les chercheurs utilisent souvent des scores de propension - et c'est l'objet de cet article. Lorsque vous aurez terminé, j'espère que vous suivrez également notre cours Inférence causale avec R - Régression qui est une excellente ressource avec beaucoup de pratique appliquée. Les exercices vous permettront de devenir un analyste de données, un scientifique de données ou un statisticien plus performant. Maintenant, commençons !
Nous comprenons qu'il existe des situations où l'assignation aléatoire n'est pas possible. En outre, nous devons également tenir compte du biais de sélection. C'est là qu'une méthode appelée score de propension est utilisée pour équilibrer les groupes dans les études d'observation. Un score de propension est la probabilité qu'un participant reçoive un traitement particulier en fonction de ses caractéristiques observées.
Cette méthode a été développée par Rosenbaum et Rubin dans les années 1980 et a été largement utilisée dans le domaine des soins de santé, des sciences sociales et de l'économie. Voici comment cela fonctionne :
Avant d'aller plus loin, il convient de comprendre ce que signifie le terme "confusion". Il y a confusion lorsqu'une variable extérieure, appelée variable confusionnelle, influence à la fois la variable indépendante (traitement) et la variable dépendante (résultat), ce qui peut conduire à des conclusions erronées sur la relation entre ces deux variables.
Par exemple, l'exercice physique est un facteur de confusion pour une étude visant à déterminer si la consommation de café (variable indépendante) est associée à une plus grande productivité (variable dépendante). En effet, les personnes qui font plus d'exercice physique peuvent également boire plus de café et avoir une productivité plus élevée, ce qui rend difficile de dire si le café seul influence la productivité ou si l'exercice physique en est en partie responsable.
Dans ce cas, l'exercice, le facteur de confusion, pourrait induire les chercheurs en erreur en suggérant à tort une relation plus forte qu'elle ne l'est entre le café et la productivité.
Les quatre principales méthodes d'application des scores de propension dans les études d'observation sont l'appariement, la stratification, la pondération par probabilité inverse et l'ajustement des covariables. Examinons chacun d'entre eux en détail.
L'appariement des scores de propension associe les participants du groupe de traitement aux participants du groupe de contrôle qui ont des scores de propension similaires. Ce processus d'appariement tient compte du fait que les groupes sont aussi similaires que possible, réduisant ainsi la possibilité de biais. En d'autres termes, les individus ayant des probabilités comparables de recevoir le traitement sont appariés afin de créer un échantillon équilibré.
L'appariement est idéal lorsque l'objectif est de créer des groupes directement comparables et de réduire autant que possible les différences de caractéristiques. Il est préférable de disposer d'un échantillon de taille moyenne à grande, car cela permet de trouver plus facilement de bonnes correspondances.
Dans une étude évaluant l'impact du travail à distance sur la productivité des employés, les chercheurs pourraient mettre en relation des employés travaillant à distance (traitement) avec des employés similaires travaillant sur place (contrôle) sur la base de variables telles que la fonction, le nombre d'années d'expérience et les mesures de performance antérieures. Cela permettrait aux chercheurs de comparer les résultats en matière de productivité tout en réduisant l'impact des différences de contexte.
La stratification consiste à diviser les participants en groupes distincts, également appelés strates, sur la base de leurs scores de propension. Souvent, ces groupes sont divisés en quintiles, c'est-à-dire en cinq parties égales. Chaque strate contient des participants ayant des scores de propension similaires, et les résultats au sein de chaque strate sont comparés entre les groupes de traitement et les groupes de contrôle.
Cette méthode est efficace lorsque la taille de l'échantillon est suffisamment importante pour créer plusieurs strates significatives, car un nombre réduit de participants par strate pourrait ne pas permettre des comparaisons efficaces.
Pour évaluer l'efficacité d'un nouveau médicament dans le cadre d'une étude sur les soins de santé, les patients peuvent être stratifiés en quintiles sur la base de scores de propension calculés à partir des données démographiques et de l'état de santé initial. Chaque strate peut inclure des patients présentant des caractéristiques similaires, ce qui permet de comparer plus précisément l'effet du traitement au sein de chaque groupe.
IPW attribue des poids basés sur des scores de propension afin de donner plus d'"importance" à certaines observations lors de l'estimation des effets du traitement. Les participants ayant une probabilité plus faible d'appartenir à leur groupe respectif se voient accorder plus de poids afin d'équilibrer les différences dans les caractéristiques des groupes.
Étant donné qu'il exploite proportionnellement les données des deux groupes, l'IPW est préférable lorsque les chercheurs doivent généraliser les résultats à l'ensemble de la population de l'échantillon.
Dans une étude de santé publique évaluant une intervention communautaire, l'IPW pourrait être appliqué pour tenir compte des différences démographiques et socio-économiques entre les communautés qui ont bénéficié de l'intervention et celles qui n'en ont pas bénéficié. Cela permet d'obtenir des résultats généralisables sans créer de paires appariées. Voici les étapes à suivre :
Ensuite, nous calculons les poids en fonction de l'inverse du score de propension, comme indiqué ci-dessous :
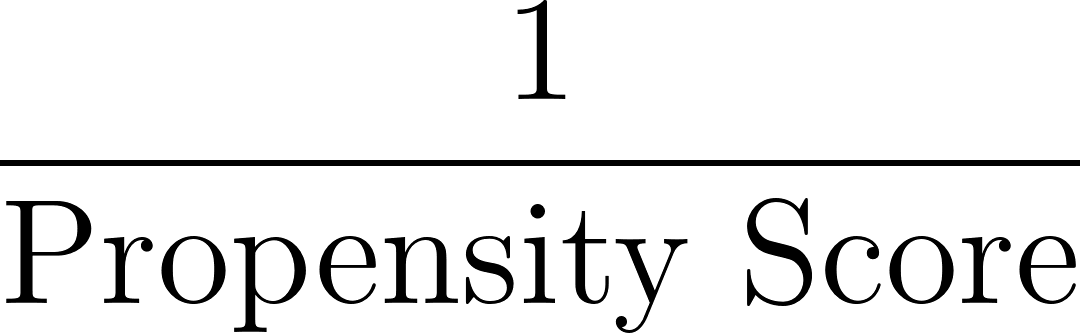
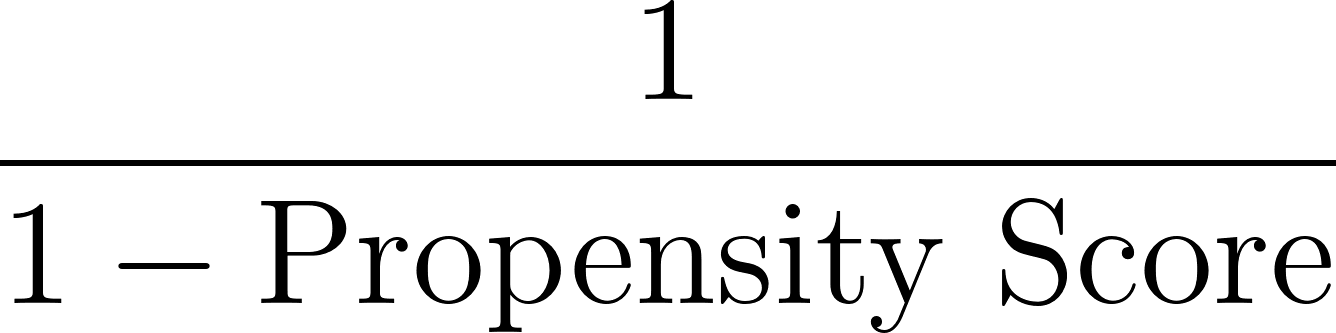
Dans notre exemple, pour l'individu ayant un score de propension de 0,8 :
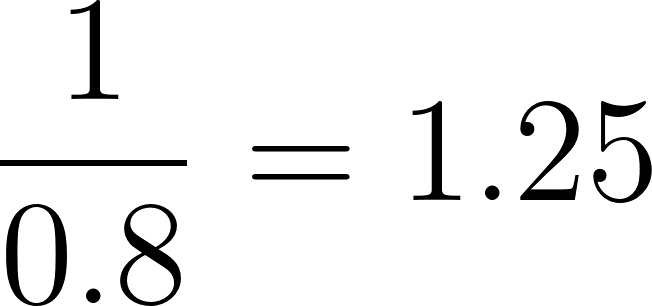
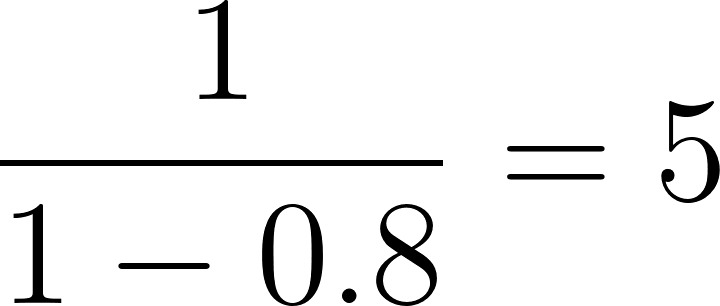
Appliquez ensuite ces poids à chaque individu de l'étude pour créer une "pseudo-population" où l'influence de chaque individu sur l'analyse est ajustée en fonction de son poids. Cette pseudo-population équilibre les caractéristiques de base entre les groupes de traitement et de contrôle. Dans la pseudo-population qui en résulte, la probabilité qu'un individu fasse partie du groupe de traitement ou du groupe de contrôle est indépendante de ses caractéristiques de base, ce qui réduit les facteurs de confusion.
Par ailleurs, l'IPTW peut être utilisé pour prendre en compte un grand nombre de variables confusionnelles. Elle peut également être appliquée aux études longitudinales pour tenir compte des facteurs de confusion liés au temps.
D'autres considérations importantes à prendre en compte lors de l'utilisation de l'IPTW sont les suivantes :
Dans l'ajustement des covariables, nous utilisons les scores de propension comme une variable covariable supplémentaire dans un modèle de régression pour contrôler les facteurs de confusion. Cet ajustement améliore l'estimation de l'effet du traitement en ajustant les scores de propension dans le modèle statistique, ce qui permet de tenir compte des facteurs de confusion.
Par exemple, lorsqu'ils étudient l'effet d'un programme de formation sur le lieu de travail sur les performances des employés, les chercheurs peuvent utiliser les scores de propension comme covariables dans un modèle de régression afin d'ajuster des facteurs tels que l'âge ou les années d'expérience.
Jusqu'à présent, nous avons abordé différents modèles de recherche, notamment la randomisation et les méthodes d'observation (lorsque la randomisation n'est pas possible). Dans le cas des études d'observation, nous avons discuté de l'importance des scores de propension et de leurs quatre méthodes. Examinons maintenant les avantages de l'utilisation des scores de propension.
Les scores de propension permettent une comparaison plus équilibrée entre les groupes de traitement et de contrôle en égalisant les covariables, ou les caractéristiques de base, entre les groupes. Cela permet aux chercheurs de créer une comparaison plus équitable avec des distributions similaires de variables clés (comme l'âge, le statut socio-économique ou les conditions de santé), ce qui permet d'estimer avec précision l'effet du traitement.
Lors de l'étude de l'impact de l'apprentissage en ligne sur les résultats des étudiants, l'appariement des scores de propension pourrait équilibrer les résultats scolaires antérieurs des étudiants, l'accès à Internet et les niveaux de motivation entre les groupes d'apprentissage en ligne et traditionnels. Cela permet de s'assurer que les différences de résultats sont plus probablement dues à la méthode d'apprentissage qu'aux différences d'origine des étudiants.
Les scores de propension corrigent les différences dans les caractéristiques observées, réduisant ainsi le biais dans les analyses. Ceci est particulièrement utile dans les études non randomisées, où les chercheurs ne sont pas en mesure de contrôler l'affectation du traitement.
Les scores de propension sont flexibles et peuvent être utilisés avec des traitements binaires (par exemple, des questions oui/non sur la question de savoir si une personne a reçu un traitement) et des traitements continus (par exemple, la quantité d'un traitement reçue par une personne).
Bien que les scores de propension soient puissants, il est important de tenir compte de leurs limites, notamment :
Les scores de propension ne peuvent s'ajuster qu'aux covariables observées, c'est-à-dire aux variables que les chercheurs ont mesurées et incluses dans le modèle. Mais cela ne tient pas nécessairement compte des facteurs de confusion cachés qui peuvent être non observés ou non mesurés. Inévitablement, cette méthode ne tient pas compte des préjugés cachés qui pourraient encore affecter le résultat.
Par exemple, lorsqu'ils comparent les effets de deux types de thérapie sur la santé mentale, les chercheurs peuvent disposer de données sur l'âge, le sexe et l'état de santé initial des patients. Cependant, si des facteurs non mesurés tels que le soutien social ou les mécanismes d'adaptation individuels ne sont pas pris en compte, ils peuvent encore influencer les résultats de la thérapie.
Les méthodes de score de propension fonctionnent mieux avec de grands ensembles de données afin de garantir un chevauchement suffisant entre les groupes de traitement et de contrôle. Des échantillons plus petits entraînent souvent un manque de Il n'y a pas assez de participants ayant des scores de propension similaires dans les différents groupes, ce qui rend difficile l'obtention de bonnes correspondances ou d'une pondération significative.
La sélection de la bonne variable et de la forme fonctionnelle du modèle est cruciale pour spécifier correctement le modèle de propension, ce qui a un impact supplémentaire sur sa précision. Le fait de ne pas inclure les variables pertinentes ou une spécification inappropriée du modèle peut conduire à des estimations biaisées, mais le pire, c'est que ces problèmes sont difficiles à détecter.
Des techniques avancées ont été développées pour remédier à certaines des limites des méthodes traditionnelles de score de propension.
Les méthodes doublement robustes sont une approche en deux étapes, dans laquelle les chercheurs estiment d'abord les scores de propension et comparent ou pondèrent les participants en conséquence. Ensuite, ils ajustent un modèle de régression pour prédire le résultat en fonction du traitement et d'autres covariables. L'estimation finale de l'effet du traitement est obtenue en ajustant à la fois le score de propension et le modèle de régression.
Dans les méthodes bayésiennes, l'incertitude est intégrée dans l'estimation des scores de propension. Cela nous permet de faire des estimations plus précises, en particulier dans des situations où les échantillons sont plus petits ou les données plus incertaines. Si vous êtes intéressé par les approches bayésiennes, qui deviennent de plus en plus courantes, suivez notre cours Fondamentaux de l'analyse bayésienne des données en R.
Lors de l'utilisation des scores de propension, il y a des erreurs communes à éviter.
Après avoir appliqué les méthodes de score de propension, il est important de vérifier si les covariables sont équilibrées entre les groupes de traitement et de contrôle. En l'absence d'un équilibre suffisant, nos résultats pourraient encore être biaisés.
La spécification du modèle est essentielle lors du calcul des scores de propension, car une mauvaise spécification peut entraîner des biais importants dans les estimations de l'effet de traitement. Les chercheurs commettent souvent des erreurs, soit en surajustant le modèle (en incluant trop de covariables), soit en omettant des facteurs de confusion importants.
L'équilibre des caractéristiques des groupes de traitement et de contrôle nous aide à minimiser les biais et à fournir des estimations plus fiables des effets du traitement. Toutefois, comme toute méthode statistique, elles doivent être appliquées avec prudence, en tenant compte des limites et des erreurs potentielles.
J'espère que vous appréciez les scores de propension, qui constituent une méthode importante pour minimiser les biais dans les études d'observation, car ils permettent d'équilibrer les groupes de traitement et de contrôle en fonction de leurs caractéristiques respectives. Des techniques telles que l'appariement, la stratification et la pondération permettent d'obtenir des conclusions causales plus précises en tenant compte des facteurs de confusion.
Pour appliquer efficacement ces méthodes, suivez notre cours Causal Inference with R - Regression qui propose une formation pratique à l'aide du package MatchIt. Cette excellente formation guide les apprenants dans la mise en œuvre de l'appariement des scores de propension et d'autres techniques afin que vous puissiez mener des recherches plus fiables et impartiales dans le cadre d'études d'observation. Je suggère également notre cursus complet de statisticien en R. Même si vous n'avez pas l'intention de devenir statisticien, ce cours est une excellente ressource qui vous permettra de devenir un excellent analyste ou data scientist.
Apprenez avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nathaniel Taylor-Leach
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Nathaniel Taylor-Leach