
Curso
Introdução à Regressão em R
4 h
77.1K
A realização de pesquisas completas é complexa e exige um planejamento cuidadoso, incluindo a forma como os participantes são designados para os grupos de tratamento que incluem o tratamento (ou, em outras palavras, a intervenção) em comparação com os grupos de controle em que não o incluem.
Uma dessas abordagens é atribuir aleatoriamente os participantes a um ou outro grupo para minimizar o viés. Essa atribuição aleatória ajuda a atribuir as diferenças nos resultados ao tratamento, e não a outras variáveis. No entanto, as atribuições aleatórias nem sempre são possíveis devido a limitações éticas, práticas ou logísticas. Nesses casos, os pesquisadores recorrem a alternativas, como estudos observacionais, pois eles se baseiam simplesmente na observação do que ocorre naturalmente no mundo real. Embora valiosos, esses projetos de pesquisa podem levar a vieses de seleção, influenciando os resultados do estudo.
Para abordar a questão do viés de seleção, os pesquisadores geralmente usam pontuações de propensão - e esse é o foco desta postagem. Quando você terminar, espero que também faça nosso curso Causal Inference with R - Regression, que é um ótimo recurso com muita prática aplicada. A realização dos exercícios certamente tornará você um analista de dados, cientista de dados ou estatístico mais forte. Agora, vamos começar!
Entendemos que há situações em que a atribuição aleatória não é uma opção. Além disso, também devemos abordar o viés de seleção. É nesse ponto que um método chamado pontuação de propensão é usado para equilibrar grupos em estudos observacionais. Uma pontuação de propensão é a probabilidade de um participante receber um tratamento específico com base em suas características observadas.
Esse método foi desenvolvido por Rosenbaum e Rubin na década de 1980 e tem sido amplamente usado na área da saúde, ciências sociais e economia. Veja como isso funciona:
Antes de prosseguirmos, vamos entender o que significa confundir. A confusão ocorre quando uma variável externa, conhecida como variável de confusão ou confundidora, influencia tanto a variável independente (tratamento) quanto a variável dependente (resultado), podendo levar a conclusões incorretas sobre a relação entre elas.
Por exemplo, o exercício físico é um fator de confusão para um estudo que examina se o consumo de café (variável independente) está associado a uma maior produtividade (variável dependente). Isso se deve ao fato de que as pessoas que se exercitam mais também podem beber mais café e ter maior produtividade, o que torna difícil dizer se o café sozinho influencia a produtividade ou se o exercício é parcialmente responsável.
Nesse caso, o exercício, o fator de confusão, poderia induzir os pesquisadores ao erro, sugerindo falsamente uma relação mais forte do que a existente entre o café e a produtividade.
Os quatro principais métodos de aplicação de escores de propensão em estudos observacionais são a correspondência, a estratificação, a ponderação de probabilidade inversa e o ajuste de covariáveis. Vamos discutir cada um deles em detalhes.
A correspondência de escore de propensão emparelha os participantes do grupo de tratamento com os participantes do grupo de controle que têm escores de propensão semelhantes. Esse processo de emparelhamento leva em conta que os grupos são os mais semelhantes possíveis, reduzindo assim a possibilidade de viés. Em outras palavras, os indivíduos com probabilidades comparáveis de receber o tratamento são emparelhados para criar uma amostra equilibrada.
A correspondência é ideal quando o objetivo é criar grupos diretamente comparáveis e reduzir ao máximo as diferenças nas características. É preferível ter uma amostra de tamanho moderado a grande, pois isso facilita encontrar boas correspondências.
Em um estudo que avaliasse o impacto do trabalho remoto na produtividade dos funcionários, os pesquisadores poderiam comparar os funcionários que trabalham remotamente (tratamento) com funcionários semelhantes que trabalham no local (controle) com base em variáveis como cargo, anos de experiência e métricas de desempenho anteriores. Isso permitiria que os pesquisadores comparassem os resultados de produtividade e, ao mesmo tempo, reduzissem o impacto das diferenças de histórico.
A estratificação é o processo de dividir os participantes em grupos distintos, também chamados de estratos, com base em suas pontuações de propensão. Geralmente, esses grupos são divididos em quintis, ou seja, cinco partes iguais. Cada estrato contém participantes com pontuações de propensão semelhantes, e os resultados em cada estrato são comparados entre os grupos de tratamento e controle.
Esse método é eficaz quando o tamanho da amostra é grande o suficiente para criar vários estratos significativos, pois um número menor de participantes por estrato pode não levar a comparações eficazes.
Para avaliar a eficácia de um novo medicamento como parte de um estudo de saúde, os pacientes podem ser estratificados em quintis com base em pontuações de propensão calculadas a partir de dados demográficos e condições de saúde de base. Cada estrato pode incluir pacientes com características semelhantes, o que leva a comparações mais precisas do efeito do tratamento em cada grupo.
O IPW atribui pesos com base em escores de propensão para dar mais "importância" a determinadas observações ao estimar os efeitos do tratamento. Os participantes com menor probabilidade de estar em seus respectivos grupos recebem mais peso para equilibrar as diferenças nas características do grupo.
Considerando que ele aproveita proporcionalmente os dados de ambos os grupos, o IPW é preferível quando os pesquisadores precisam generalizar os resultados para toda a população da amostra.
Em um estudo de saúde pública que avaliasse uma intervenção comunitária, o IPW poderia ser aplicado para levar em conta as diferenças demográficas e socioeconômicas entre as comunidades que receberam a intervenção e as que não receberam. Isso permite conclusões generalizáveis sem a criação de pares combinados. Aqui estão as etapas:
Em seguida, calculamos os pesos com base no inverso da pontuação de propensão, conforme mostrado abaixo:
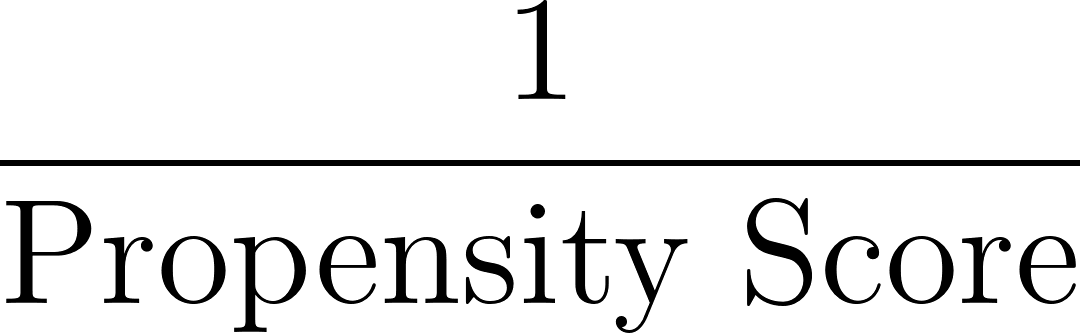
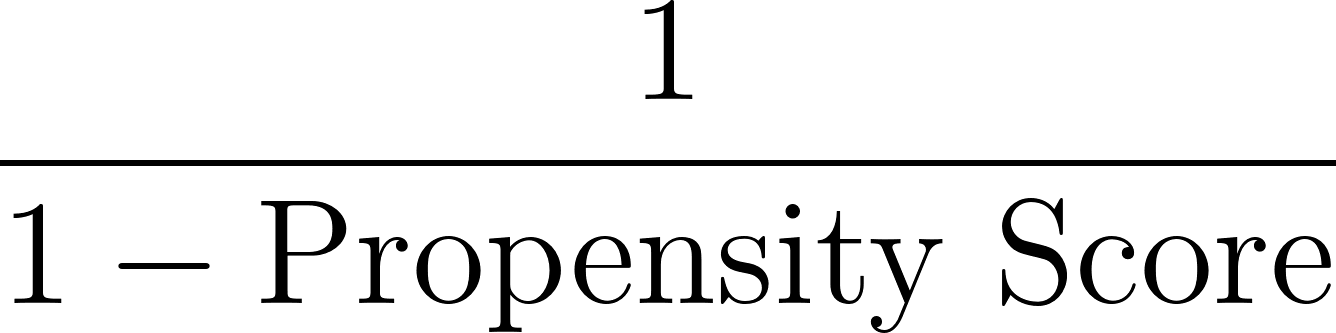
Em nosso exemplo, para o indivíduo com uma pontuação de propensão de 0,8:
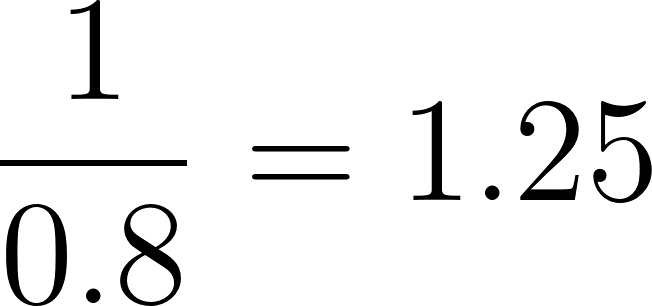
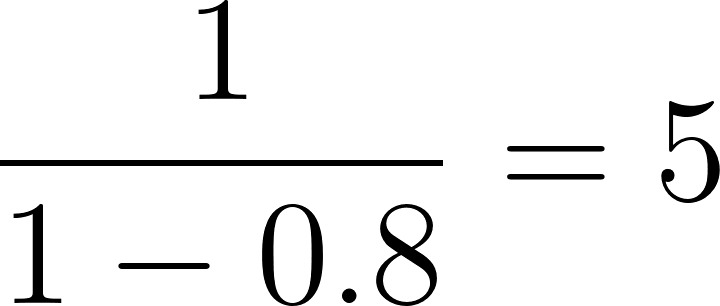
Agora, aplique esses pesos a cada indivíduo no estudo para criar uma "pseudopopulação" em que a influência de cada indivíduo na análise seja ajustada pelo seu peso. Essa pseudopopulação equilibra as características de linha de base entre os grupos de tratamento e controle. Na pseudopopulação resultante, a probabilidade de um indivíduo estar no grupo de tratamento ou controle é independente de suas características de linha de base, reduzindo assim a confusão.
Como observação, o IPTW pode ser usado para abordar um grande número de variáveis de confusão. Ele também pode ser aplicado a estudos longitudinais para levar em conta a confusão dependente do tempo.
Algumas outras considerações importantes ao usar o IPTW incluem:
No ajuste de covariável, usamos os escores de propensão como uma variável de covariável adicional em um modelo de regressão para controlar os fatores de confusão. Esse ajuste melhora a estimativa do efeito do tratamento, ajustando os escores de propensão dentro do modelo estatístico e, assim, levando em conta a confusão.
Por exemplo, ao estudar o efeito de um programa de treinamento no local de trabalho sobre o desempenho dos funcionários, os pesquisadores poderiam usar as pontuações de propensão como covariáveis em um modelo de regressão para ajustar fatores como idade ou anos de experiência.
Até agora, discutimos diferentes projetos de pesquisa, incluindo randomização e métodos de pesquisa de observação (quando a randomização não é viável). No caso dos estudos de observação, discutimos a importância das pontuações de propensão e seus quatro métodos. Agora, vamos discutir as vantagens do uso de escores de propensão.
Os escores de propensão proporcionam uma comparação mais equilibrada entre os grupos de tratamento e controle, igualando as covariáveis, ou características de fundo, entre os grupos. Isso permite que os pesquisadores criem uma comparação mais justa com distribuições semelhantes de variáveis-chave (como idade, status socioeconômico ou condições de saúde), o que leva a uma estimativa precisa do efeito do tratamento.
Ao estudar o impacto do aprendizado on-line sobre os resultados dos alunos, a correspondência da pontuação de propensão poderia equilibrar o desempenho acadêmico anterior dos alunos, o acesso à Internet e os níveis de motivação entre os grupos de aprendizado on-line e tradicional. Isso ajuda a garantir que as diferenças nos resultados sejam mais provavelmente devidas ao método de aprendizado do que às diferenças nos históricos dos alunos.
Os escores de propensão se ajustam às diferenças nas características observadas, reduzindo assim o viés nas análises. Isso é particularmente valioso em estudos não randomizados, nos quais os pesquisadores não conseguem controlar a atribuição do tratamento.
As pontuações de propensão são flexíveis e podem ser usadas tanto com tratamentos binários (por exemplo, perguntas de sim/não sobre se alguém recebeu tratamento) quanto com tratamentos contínuos (por exemplo, quanto de um tratamento alguém recebeu).
Embora as pontuações de propensão sejam poderosas, também é importante considerar suas limitações, tais como
Os escores de propensão só podem ser ajustados para covariáveis observadas, ou seja, as variáveis que os pesquisadores mediram e incluíram no modelo. Mas isso não necessariamente leva em conta fatores de confusão ocultos que podem não ser observados ou medidos. Inevitavelmente, isso ainda deixa de lado preconceitos ocultos que podem afetar o resultado.
Por exemplo, ao comparar os efeitos de dois tipos de terapia sobre os resultados de saúde mental, os pesquisadores podem ter dados sobre a idade, o sexo e a saúde de base dos pacientes. No entanto, se fatores não medidos, como apoio social ou mecanismos de enfrentamento individuais, não forem verificados, eles ainda poderão influenciar os resultados da terapia.
Os métodos de pontuação de propensão funcionam melhor com grandes conjuntos de dados para garantir que haja sobreposição suficiente entre os grupos de tratamento e controle. Amostras menores geralmente levam a uma falta de participantes suficientes com pontuações de propensão semelhantes em todos os grupos, o que torna difícil conseguir boas combinações ou ponderações significativas.
A seleção da variável certa e da forma funcional do modelo é fundamental para especificar corretamente o modelo de propensão, o que afeta ainda mais sua precisão. A não inclusão das variáveis relevantes ou a especificação inadequada do modelo pode levar a estimativas distorcidas, mas a pior parte é que problemas como esses são difíceis de detectar.
Técnicas avançadas foram desenvolvidas para abordar algumas das limitações dos métodos tradicionais de pontuação de propensão.
Os métodos duplamente robustos são uma abordagem de duas etapas, em que os pesquisadores primeiro estimam as pontuações de propensão e combinam ou ponderam os participantes de acordo. Em seguida, eles ajustam um modelo de regressão para prever o resultado com base no tratamento e em outras covariáveis. A estimativa final do efeito do tratamento é obtida com o ajuste do escore de propensão e do modelo de regressão.
Nos métodos bayesianos, a incerteza é incorporada à estimativa dos escores de propensão. Isso nos permite fazer estimativas mais precisas, especialmente em situações com tamanhos de amostra menores ou maior incerteza sobre os dados. Se você estiver interessado em abordagens bayesianas, que estão se tornando cada vez mais comuns, faça nosso curso Fundamentals of Bayesian Data Analysis in R.
Ao usar pontuações de propensão, você deve evitar alguns erros comuns.
Após aplicar os métodos de pontuação de propensão, é importante verificar se as covariáveis estão equilibradas entre os grupos de tratamento e controle. Sem equilíbrio suficiente, nossos resultados ainda podem ser tendenciosos.
A especificação do modelo é fundamental ao calcular os escores de propensão, pois uma especificação inadequada pode levar a vieses significativos nas estimativas do efeito do tratamento. Os pesquisadores geralmente cometem erros ao ajustar demais o modelo (incluindo muitas covariáveis) ou ao omitir fatores de confusão importantes.
Equilibrar as características dos grupos de tratamento e controle nos ajuda a minimizar o viés e a fornecer estimativas mais confiáveis dos efeitos do tratamento. Entretanto, como qualquer método estatístico, eles devem ser aplicados com cuidado, com atenção às possíveis limitações e erros.
Espero que você aprecie as pontuações de propensão, que são um método importante para minimizar o viés em estudos observacionais, pois elas fazem um bom trabalho ao equilibrar os grupos de tratamento e controle com base em suas respectivas características. Técnicas como correspondência, estratificação e ponderação ajudam a garantir inferências causais mais precisas, abordando fatores de confusão.
Para aplicar esses métodos com eficácia, faça nosso curso Causal Inference with R - Regression (Inferência causal com R - Regressão ), que oferece treinamento prático usando o pacote MatchIt. Esse excelente curso orienta os alunos na implementação da correspondência de pontuação de propensão e outras técnicas para que você possa realizar pesquisas mais confiáveis e imparciais em estudos observacionais. Também sugiro nosso curso de carreira completo de estatístico em R. Mesmo que você não esteja planejando ser um estatístico, o curso ainda é um ótimo recurso com muito aprendizado para torná-lo um ótimo analista ou cientista de dados.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Elena Kosourova
15 min
Tutorial
Bex Tuychiev
Tutorial
Amberle McKee
Tutorial
Zoumana Keita
Tutorial
Tutorial
Somil Asthana




