
Curso
Introducción a la regresión en R
4 h
77.2K
Llevar a cabo una investigación exhaustiva es complejo y requiere una planificación cuidadosa, que incluya cómo se asignan los participantes a los grupos de tratamiento que incluyen el tratamiento (o, en otras palabras, la intervención) frente a los grupos de control en los que no lo incluyen.
Uno de estos enfoques consiste en asignar aleatoriamente a los participantes a uno u otro grupo para minimizar el sesgo. Esta asignación aleatoria ayuda a atribuir las diferencias en los resultados al tratamiento, en lugar de a otras variables. Sin embargo, las asignaciones aleatorias no siempre son posibles debido a limitaciones éticas, prácticas o logísticas. En tales casos, los investigadores recurren a alternativas, como los estudios observacionales, ya que se basan en la simple observación de lo que ocurre de forma natural en el mundo real. Aunque valiosos, estos diseños de investigación pueden dar lugar a sesgos de selección, lo que influye en los resultados del estudio.
Para abordar el problema del sesgo de selección, los investigadores suelen utilizar puntuaciones de propensión, y ése es el tema central de este post. Cuando termines, espero que también sigas nuestro curso Inferencia causal con R - Regresión, que es un gran recurso con mucha práctica aplicada. Realizar los ejercicios te convertirá en un analista de datos, un científico de datos o un estadístico más fuerte. Ahora, ¡empecemos!
Entendemos que hay situaciones en las que la asignación aleatoria no es una opción. Además, debemos abordar también el sesgo de selección. Aquí se utiliza un método llamado puntuación de propensión para equilibrar los grupos en los estudios observacionales. Una puntuación de propensión es la probabilidad de que un participante reciba un tratamiento concreto en función de sus características observadas.
Este método fue desarrollado por Rosenbaum y Rubin en los años 80 y se ha utilizado ampliamente en sanidad, ciencias sociales y economía. Funciona así:
Antes de seguir adelante, entendamos qué significa confusión. La confusión se produce cuando una variable externa, conocida como variable de confusión o factor de confusión, influye tanto en la variable independiente (tratamiento) como en la variable dependiente (resultado), lo que puede llevar a conclusiones incorrectas sobre la relación entre ambas.
Por ejemplo, el ejercicio físico es un factor de confusión para un estudio que examine si beber café (variable independiente) está asociado a una mayor productividad (variable dependiente). Esto se debe a que las personas que hacen más ejercicio también pueden beber más café y tener una mayor productividad, lo que hace difícil saber si el café por sí solo influye en la productividad o si el ejercicio es en parte responsable.
En este caso, el ejercicio, el factor de confusión, podría inducir a error a los investigadores al sugerir falsamente una relación más fuerte de la que podría existir entre el café y la productividad.
Los cuatro métodos principales para aplicar puntuaciones de propensión en estudios observacionales son el emparejamiento, la estratificación, la ponderación de probabilidad inversa y el ajuste de covariables. Hablemos de cada uno de ellos en detalle.
El emparejamiento de puntuaciones de propensión empareja a los participantes del grupo de tratamiento con participantes del grupo de control que tienen puntuaciones de propensión similares. Este proceso de emparejamiento tiene en cuenta que los grupos sean lo más parecidos posible, reduciendo así la posibilidad de sesgo. En otras palabras, los individuos con probabilidades comparables de recibir el tratamiento se emparejan para crear una muestra equilibrada.
El emparejamiento es ideal cuando el objetivo es crear grupos directamente comparables y reducir al máximo las diferencias de características. Es preferible tener un tamaño de muestra de moderado a grande, ya que facilita encontrar buenas coincidencias.
En un estudio que evalúe el impacto del trabajo a distancia en la productividad de los empleados, los investigadores podrían emparejar a los empleados que trabajan a distancia (tratamiento) con empleados similares que trabajan in situ (control) basándose en variables como la función laboral, los años de experiencia y las métricas de rendimiento anteriores. Esto permitiría a los investigadores comparar los resultados de productividad reduciendo al mismo tiempo el impacto de las diferencias de fondo.
La estratificación es el proceso de dividir a los participantes en grupos distintos, también llamados estratos, basándose en sus puntuaciones de propensión. A menudo, estos grupos se dividen en quintiles, es decir, en cinco partes iguales. Cada estrato contiene participantes con puntuaciones de propensión similares, y los resultados dentro de cada estrato se comparan entre los grupos de tratamiento y de control.
Este método es eficaz cuando el tamaño de la muestra es lo suficientemente grande como para crear varios estratos significativos, ya que un menor número de participantes por estrato podría no dar lugar a comparaciones eficaces.
Para evaluar la eficacia de un nuevo medicamento en el marco de un estudio sanitario, se puede estratificar a los pacientes en quintiles basándose en puntuaciones de propensión calculadas a partir de los datos demográficos y las condiciones de salud basales. Cada estrato puede incluir pacientes con características similares, lo que conduce a comparaciones más precisas del efecto del tratamiento dentro de cada grupo.
IPW asigna ponderaciones basadas en puntuaciones de propensión para dar más "importancia" a determinadas observaciones al estimar los efectos del tratamiento. A los participantes con menor probabilidad de estar en sus respectivos grupos se les da más peso para equilibrar las diferencias en las características de los grupos.
Teniendo en cuenta que aprovecha proporcionalmente los datos de ambos grupos, el IPW es preferible cuando los investigadores necesitan generalizar los resultados a toda la población de la muestra.
En un estudio de salud pública que evalúe una intervención comunitaria, el IPW podría aplicarse para tener en cuenta las diferencias demográficas y socioeconómicas entre las comunidades que recibieron la intervención y las que no. Esto permite obtener conclusiones generalizables sin crear pares emparejados. Aquí tienes los pasos:
A continuación, calculamos las ponderaciones basándonos en la inversa de la puntuación de propensión, como se muestra a continuación:
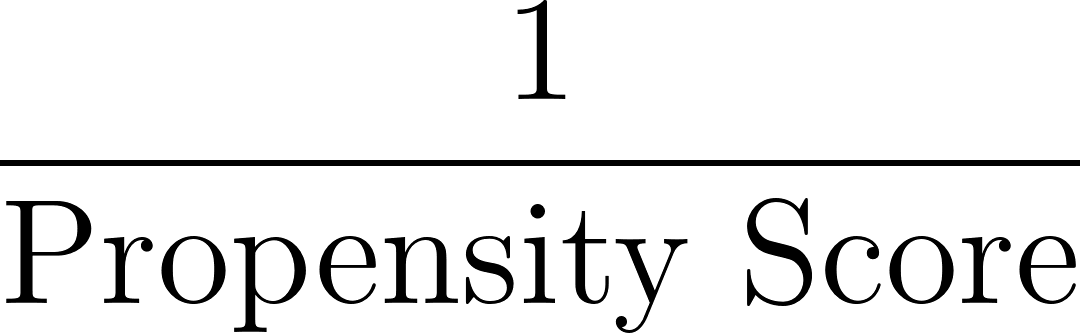
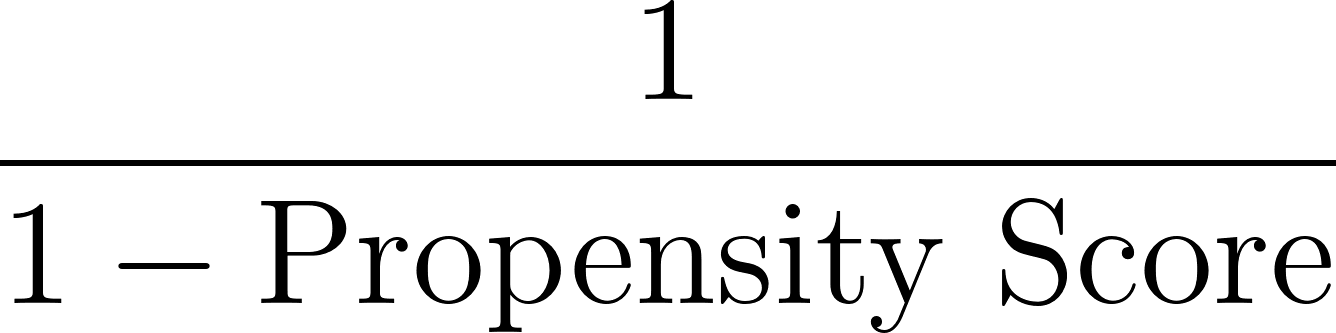
En nuestro ejemplo, para el individuo con una puntuación de propensión de 0,8:
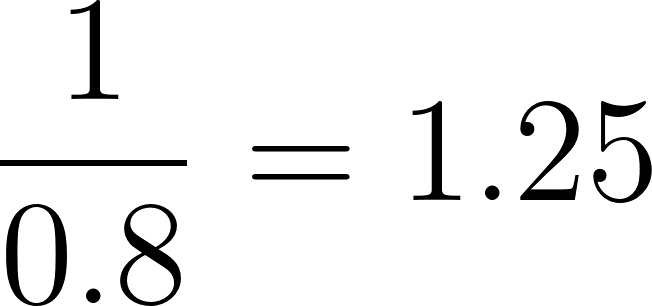
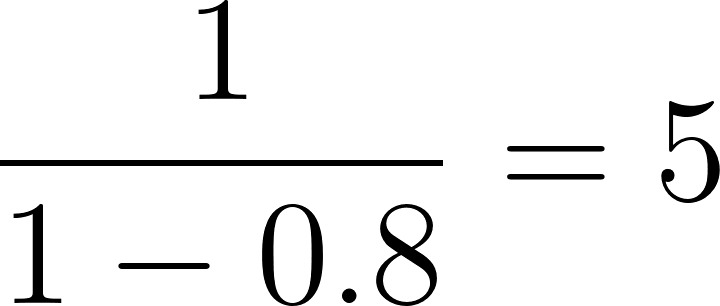
Ahora, aplica estos pesos a cada individuo del estudio para crear una "pseudopoblación" en la que la influencia de cada individuo en el análisis se ajuste por su peso. Esta pseudopoblación equilibra las características basales entre los grupos de tratamiento y de control. En la pseudopoblación resultante, la probabilidad de que un individuo esté en el grupo de tratamiento o de control es independiente de sus características basales, lo que reduce los factores de confusión.
Como nota, el IPTW puede utilizarse para abordar un gran número de variables de confusión. También puede aplicarse a estudios longitudinales para tener en cuenta los factores de confusión dependientes del tiempo.
Otras consideraciones importantes al utilizar el IPTW son:
En el ajuste de covariables, utilizamos las puntuaciones de propensión como variable covariable adicional en un modelo de regresión para controlar los factores de confusión. Este ajuste mejora la estimación del efecto del tratamiento al ajustar las puntuaciones de propensión dentro del modelo estadístico, teniendo así en cuenta los factores de confusión.
Por ejemplo, al estudiar el efecto de un programa de formación en el lugar de trabajo sobre el rendimiento de los empleados, los investigadores podrían utilizar puntuaciones de propensión como covariables en un modelo de regresión para ajustar factores como la edad o los años de experiencia.
Hasta ahora, hemos hablado de diferentes diseños de investigación, incluyendo la aleatorización y los métodos de investigación por observación (cuando la aleatorización no es factible). En el caso de los estudios de observación, discutimos la importancia de las puntuaciones de propensión y sus cuatro métodos. Analicemos ahora las ventajas de utilizar puntuaciones de propensión.
Las puntuaciones de propensión proporcionan una comparación más equilibrada entre los grupos de tratamiento y control al igualar las covariables, o características de fondo, entre los grupos. Esto permite a los investigadores crear una comparación más justa con distribuciones similares de variables clave (como la edad, el estatus socioeconómico o las condiciones de salud), lo que permite estimar con precisión el efecto del tratamiento.
Al estudiar el impacto del aprendizaje en línea en los resultados de los estudiantes, el emparejamiento de puntuaciones de propensión podría equilibrar el rendimiento académico previo de los estudiantes, el acceso a Internet y los niveles de motivación entre los grupos de aprendizaje en línea y tradicional. Esto ayuda a garantizar que las diferencias en los resultados se deban más al método de aprendizaje que a las diferencias en los antecedentes de los alumnos.
Las puntuaciones de propensión ajustan las diferencias en las características observadas, reduciendo así el sesgo de los análisis. Esto es especialmente valioso en los estudios no aleatorizados, en los que los investigadores no pueden controlar la asignación del tratamiento.
Las puntuaciones de propensión son flexibles y pueden utilizarse tanto con tratamientos binarios (p. ej., preguntas de sí/no sobre si alguien recibió el tratamiento) como con tratamientos continuos (p. ej., qué cantidad de un tratamiento recibió alguien).
Aunque las puntuaciones de propensión son potentes, también es importante tener en cuenta sus limitaciones, como:
Las puntuaciones de propensión sólo pueden ajustar las covariables observadas, es decir, las variables que los investigadores han medido e incluido en el modelo. Pero eso no tiene en cuenta necesariamente los factores de confusión ocultos que podrían ser no observados o no medidos. Inevitablemente, sigue dejando sin abordar sesgos ocultos que aún podrían afectar al resultado.
Por ejemplo, al comparar los efectos de dos tipos de terapia en los resultados de salud mental, los investigadores pueden disponer de datos sobre la edad, el sexo y el estado de salud inicial de los pacientes. Sin embargo, si no se tienen en cuenta factores no medidos, como el apoyo social o los mecanismos individuales de afrontamiento, aún podrían influir en los resultados de la terapia.
Los métodos de puntuación de la propensión funcionan mejor con grandes conjuntos de datos para garantizar que haya suficiente solapamiento entre los grupos de tratamiento y de control. Las muestras más pequeñas suelen conducir a una falta de suficientes participantes con puntuaciones de propensión similares en todos los grupos, lo que dificulta lograr buenas coincidencias o una ponderación significativa.
Seleccionar la variable adecuada y la forma funcional del modelo es crucial para especificar correctamente el modelo de propensión, lo que repercute aún más en su precisión. No incluir las variables relevantes o una especificación inadecuada del modelo puede dar lugar a estimaciones sesgadas, pero lo peor es que problemas como éstos son difíciles incluso de detectar.
Se han desarrollado técnicas avanzadas para abordar algunas de las limitaciones de los métodos tradicionales de puntuación de la propensión.
Los métodos doblemente robustos son un enfoque de dos pasos, en el que los investigadores estiman primero las puntuaciones de propensión y emparejan o ponderan a los participantes en consecuencia. A continuación, ajustan un modelo de regresión para predecir el resultado basándose en el tratamiento y otras covariables. La estimación final del efecto del tratamiento se obtiene ajustando tanto la puntuación de propensión como el modelo de regresión.
En los métodos bayesianos, la incertidumbre se incorpora a la estimación de las puntuaciones de propensión. Esto nos permite hacer estimaciones más precisas, sobre todo en situaciones con tamaños de muestra más pequeños o mayor incertidumbre sobre los datos. Si te interesan los enfoques bayesianos, que cada vez son más comunes, cursa nuestro curso Fundamentos del análisis bayesiano de datos en R.
Al utilizar puntuaciones de propensión, hay errores comunes que debes evitar.
Tras aplicar los métodos de puntuación de la propensión, es importante comprobar si las covariables están equilibradas entre los grupos de tratamiento y control. Sin un equilibrio suficiente, nuestros resultados podrían estar sesgados.
La especificación del modelo es fundamental a la hora de calcular las puntuaciones de propensión, ya que una especificación inadecuada puede dar lugar a sesgos significativos en las estimaciones del efecto del tratamiento. Los investigadores suelen cometer errores, ya sea por sobreajustar el modelo (incluyendo demasiadas covariables) o por omitir importantes factores de confusión.
Equilibrar las características de los grupos de tratamiento y de control nos ayuda a minimizar el sesgo y a proporcionar estimaciones más fiables de los efectos del tratamiento. Sin embargo, como cualquier método estadístico, deben aplicarse con cuidado, prestando atención a las posibles limitaciones y errores.
Espero que aprecies las puntuaciones de propensión, que son un método importante para minimizar el sesgo en los estudios observacionales, porque hacen un buen trabajo equilibrando los grupos de tratamiento y control en función de sus características respectivas. Técnicas como el emparejamiento, la estratificación y la ponderación ayudan a garantizar unas inferencias causales más precisas al abordar los factores de confusión.
Para aplicar eficazmente estos métodos, sigue nuestro curso de Inferencia causal con R - Regresión, que ofrece formación práctica utilizando el paquete MatchIt. Este magnífico curso guía a los alumnos en la aplicación del emparejamiento de puntuaciones de propensión y otras técnicas para que puedas realizar investigaciones más fiables e imparciales en estudios observacionales. También sugiero nuestra carrera completa de Estadístico en R. Aunque no estés pensando en ser estadístico, el curso sigue siendo un gran recurso con mucho aprendizaje para convertirte en un gran analista o científico de datos.
Aprende con DataCamp
Curso
Curso
Curso
blog
Arun Nanda
15 min
Tutorial
Bex Tuychiev
Tutorial
Łukasz Deryło
Tutorial
Arunn Thevapalan
Tutorial
Tutorial
Avinash Navlani


