
Kurs
Einführung in Regression mit R
4 Std.
77.1K
Die Durchführung gründlicher Untersuchungen ist komplex und erfordert eine sorgfältige Planung. Dazu gehört auch, wie die Teilnehmer/innen den Behandlungsgruppen, die die Behandlung (oder anders gesagt, die Intervention) enthalten, gegenüber den Kontrollgruppen, die sie nicht enthalten, zugewiesen werden.
Ein solcher Ansatz besteht darin, die Teilnehmenden nach dem Zufallsprinzip einer der beiden Gruppen zuzuweisen, um Verzerrungen zu minimieren. Diese zufällige Zuweisung hilft dabei, die Unterschiede in den Ergebnissen auf die Behandlung und nicht auf andere Variablen zurückzuführen. Zufällige Zuweisungen sind jedoch aus ethischen, praktischen oder logistischen Gründen nicht immer möglich. In solchen Fällen greifen die Forscher auf Alternativen zurück, wie z.B. Beobachtungsstudien, da sie sich darauf verlassen, einfach zu beobachten, was in der realen Welt passiert. Diese Forschungsdesigns sind zwar wertvoll, können aber zu einer Verzerrung der Auswahl führen und die Ergebnisse der Studie beeinflussen.
Um das Problem der Selektionsverzerrung zu lösen, verwenden Forscher oft Propensity Scores - und das ist der Schwerpunkt dieses Beitrags. Wenn du fertig bist, hoffe ich, dass du auch unseren Kurs Kausalschluss mit R - Regression belegst, der eine großartige Ressource mit vielen praktischen Übungen ist. Wenn du die Übungen durcharbeitest, wirst du zu einem besseren Datenanalysten, Datenwissenschaftler oder Statistiker. Und jetzt lass uns loslegen!
Wir verstehen, dass es Situationen gibt, in denen eine zufällige Zuordnung nicht möglich ist. Hinzu kommt, dass wir uns auch mit Selektionsverzerrungen auseinandersetzen müssen. Hier wird eine Methode namens Propensity Score verwendet, um Gruppen in Beobachtungsstudien auszugleichen. Ein Propensity Score ist die Wahrscheinlichkeit, dass ein Teilnehmer aufgrund seiner beobachteten Merkmale eine bestimmte Behandlung erhalten würde.
Diese Methode wurde in den 1980er-Jahren von Rosenbaum und Rubin entwickelt und ist im Gesundheitswesen, in den Sozial- und Wirtschaftswissenschaften weit verbreitet. So funktioniert es:
Bevor wir weitermachen, müssen wir erst einmal verstehen, was "verwirren" bedeutet. Eine Verwechslung liegt vor, wenn eine externe Variable, die als Verwechslungsvariable oder Confounder bezeichnet wird, sowohl die unabhängige Variable (Behandlung) als auch die abhängige Variable (Ergebnis) beeinflusst, was zu falschen Schlussfolgerungen über die Beziehung zwischen ihnen führen kann.
Zum Beispiel ist körperliche Bewegung ein Störfaktor für eine Studie, die untersucht, ob Kaffeetrinken (unabhängige Variable) mit höherer Produktivität (abhängige Variable) verbunden ist. Das liegt daran, dass Menschen, die mehr Sport treiben, auch mehr Kaffee trinken und produktiver sind. Deshalb ist es schwer zu sagen, ob Kaffee allein die Produktivität beeinflusst oder ob Sport mitverantwortlich ist.
In diesem Fall könnte der Störfaktor Bewegung die Forscher in die Irre führen, indem er fälschlicherweise einen stärkeren Zusammenhang zwischen Kaffee und Produktivität suggeriert, als er tatsächlich besteht.
Die vier wichtigsten Methoden zur Anwendung von Propensity Scores in Beobachtungsstudien sind Matching, Stratifizierung, inverse Wahrscheinlichkeitsgewichtung und Kovariatenanpassung. Lasst uns jede von ihnen im Detail besprechen.
Beim Propensity-Score-Matching werden die Teilnehmer aus der Behandlungsgruppe mit Teilnehmern aus der Kontrollgruppe gepaart, die ähnliche Propensity-Scores haben. Bei diesem Paarungsprozess wird darauf geachtet, dass die Gruppen so ähnlich wie möglich sind, um die Möglichkeit einer Verzerrung zu verringern. Mit anderen Worten: Die Personen mit vergleichbaren Wahrscheinlichkeiten, die Behandlung zu erhalten, werden gepaart, um eine ausgewogene Stichprobe zu erhalten.
Matching ist ideal, wenn das Ziel darin besteht, direkt vergleichbare Gruppen zu bilden und die Unterschiede in den Merkmalen so weit wie möglich zu reduzieren. Eine mittelgroße bis große Stichprobe ist vorzuziehen, da sie es erleichtert, gute Übereinstimmungen zu finden.
In einer Studie, in der die Auswirkungen von Fernarbeit auf die Produktivität der Beschäftigten untersucht werden, könnten die Forscher/innen Mitarbeiter/innen, die ferngesteuert arbeiten (Treatment), mit ähnlichen Mitarbeiter/innen, die vor Ort arbeiten (Control), auf der Grundlage von Variablen wie der Funktion, den Jahren der Erfahrung und früheren Leistungskennzahlen vergleichen. Dies würde es den Forschern ermöglichen, die Produktivitätsergebnisse zu vergleichen und gleichzeitig die Auswirkungen von Hintergrundunterschieden zu verringern.
Bei der Stratifizierung werden die Teilnehmer auf der Grundlage ihrer Propensity Scores in verschiedene Gruppen, auch Strata genannt, eingeteilt. Oft werden diese Gruppen in Quintile, d.h. fünf gleiche Teile, unterteilt. Jede Schicht enthält Teilnehmer mit ähnlichen Propensity Scores, und die Ergebnisse innerhalb jeder Schicht werden zwischen Behandlungs- und Kontrollgruppen verglichen.
Diese Methode ist sinnvoll, wenn die Stichprobengröße groß genug ist, um mehrere aussagekräftige Schichten zu bilden, da weniger Teilnehmer/innen pro Schicht möglicherweise nicht zu effektiven Vergleichen führen.
Um die Wirksamkeit eines neuen Medikaments im Rahmen einer Gesundheitsstudie zu bewerten, können die Patienten anhand von Propensity Scores, die anhand der demografischen Daten und des Gesundheitszustands berechnet werden, in Quintile eingeteilt werden. Jede Schicht kann Patienten mit ähnlichen Merkmalen umfassen, was zu genaueren Vergleichen der Behandlungseffekte innerhalb jeder Gruppe führt.
IPW vergibt Gewichte auf der Grundlage von Propensity Scores, um bestimmten Beobachtungen bei der Schätzung der Behandlungseffekte mehr "Bedeutung" zu verleihen. Teilnehmer mit einer geringeren Wahrscheinlichkeit, in ihrer jeweiligen Gruppe zu sein, werden stärker gewichtet, um Unterschiede in den Gruppenmerkmalen auszugleichen.
Da er die Daten beider Gruppen proportional nutzt, wird der IPW bevorzugt, wenn Forscher die Ergebnisse auf die gesamte Stichprobenpopulation verallgemeinern müssen.
In einer Studie zur öffentlichen Gesundheit, in der eine kommunale Intervention evaluiert wird, könnte der IPW angewandt werden, um demografische und sozioökonomische Unterschiede zwischen den Gemeinden, die die Intervention erhalten haben, und denen, die sie nicht erhalten haben, zu berücksichtigen. Dies ermöglicht verallgemeinerbare Ergebnisse, ohne dass passende Paare gebildet werden. Hier sind die Schritte:
Als Nächstes berechnen wir Gewichte, die auf dem Kehrwert des Propensity Scores basieren, wie unten dargestellt:
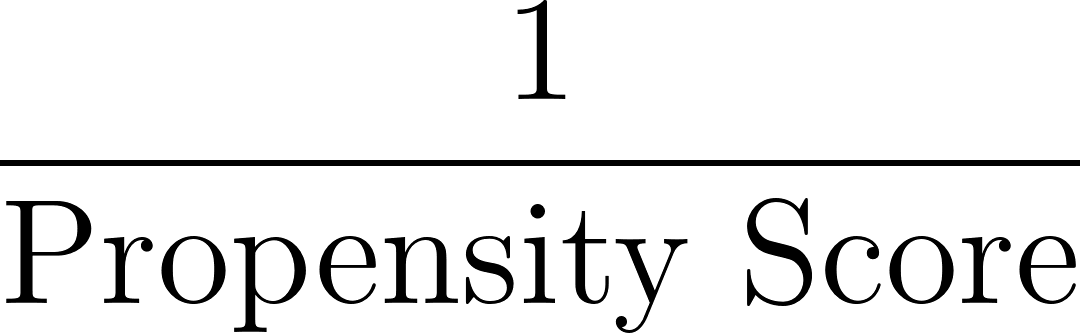
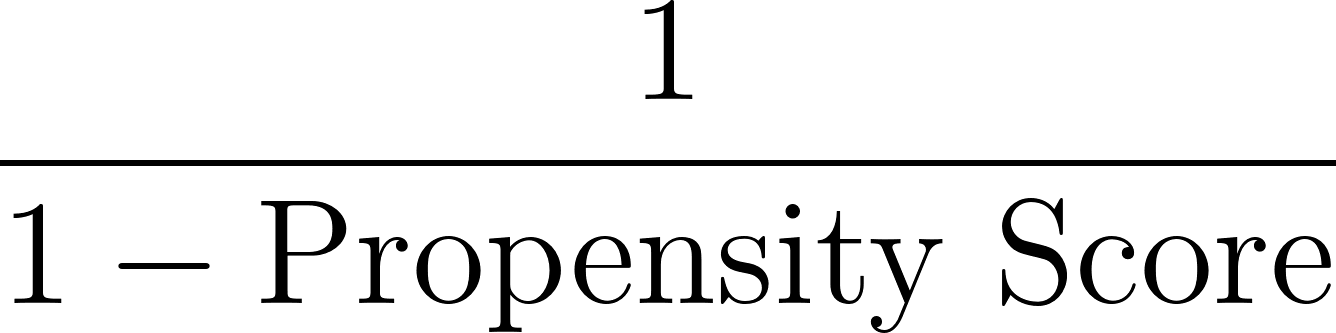
In unserem Beispiel für die Person mit einem Propensity Score von 0,8:
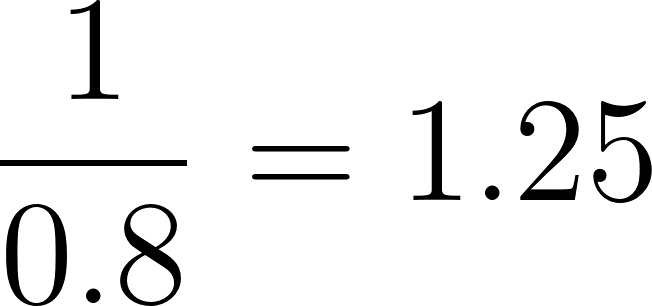
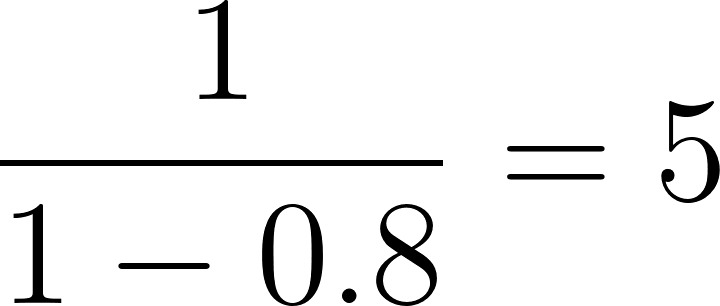
Wende diese Gewichte nun auf jede Person in der Studie an, um eine "Pseudo-Population" zu erstellen, bei der der Einfluss jeder Person auf die Analyse um ihr Gewicht angepasst wird. Diese Pseudopopulation gleicht die Ausgangsmerkmale der Behandlungs- und Kontrollgruppen aus. In der daraus resultierenden Pseudopopulation ist die Wahrscheinlichkeit, dass eine Person der Behandlungs- oder Kontrollgruppe angehört, unabhängig von ihren Ausgangsmerkmalen, was die Verwechslungsgefahr verringert.
Übrigens kann IPTW verwendet werden, um eine große Anzahl von Störvariablen zu berücksichtigen. Sie kann auch auf Längsschnittstudien angewendet werden, um zeitabhängige Störfaktoren zu berücksichtigen.
Einige andere wichtige Überlegungen bei der Nutzung von IPTW sind:
Bei der Kovariatenanpassung verwenden wir die Propensity Scores als zusätzliche Kovariate in einem Regressionsmodell, um für Störfaktoren zu kontrollieren. Diese Anpassung verbessert die Schätzung des Behandlungseffekts, indem sie die Propensity Scores innerhalb des statistischen Modells anpasst und so die Störfaktoren berücksichtigt.
Bei der Untersuchung der Auswirkungen eines Schulungsprogramms am Arbeitsplatz auf die Leistung der Mitarbeiter könnten die Forscher beispielsweise Propensity Scores als Kovariaten in einem Regressionsmodell verwenden, um Faktoren wie Alter oder Berufserfahrung zu berücksichtigen.
Bisher haben wir verschiedene Forschungsdesigns besprochen, darunter Randomisierung und Beobachtungsmethoden (wenn eine Randomisierung nicht möglich ist). Im Fall von Beobachtungsstudien haben wir die Bedeutung von Propensity Scores und ihre vier Methoden besprochen. Jetzt wollen wir die Vorteile der Verwendung von Propensity Scores besprechen.
Propensity Scores sorgen für einen ausgewogeneren Vergleich zwischen der Behandlungs- und der Kontrollgruppe, indem sie Kovariaten oder Hintergrundmerkmale in den Gruppen gleichsetzen. Dies ermöglicht den Forschern einen faireren Vergleich mit ähnlichen Verteilungen von Schlüsselvariablen (wie Alter, sozioökonomischer Status oder Gesundheitszustand), was zu einer genauen Schätzung des Behandlungseffekts führt.
Bei der Untersuchung der Auswirkungen des Online-Lernens auf die Lernergebnisse könnte ein Propensity-Score-Matching die früheren akademischen Leistungen, den Internetzugang und das Motivationsniveau der Schüler in den Online- und traditionellen Lerngruppen ausgleichen. So kann sichergestellt werden, dass Unterschiede in den Ergebnissen eher auf die Lernmethode als auf Unterschiede im Hintergrund der Schüler/innen zurückzuführen sind.
Propensity Scores gleichen Unterschiede in den beobachteten Merkmalen aus und verringern so die Verzerrungen in den Analysen. Dies ist besonders wertvoll bei nicht-randomisierten Studien, bei denen die Forscher die Zuordnung der Behandlung nicht kontrollieren können.
Propensity Scores sind flexibel und können sowohl für binäre Behandlungen (z. B. Ja/Nein-Fragen dazu, ob jemand eine Behandlung erhalten hat) als auch für kontinuierliche Behandlungen (z. B. wie viel von einer Behandlung jemand erhalten hat) verwendet werden.
Propensity Scores sind zwar leistungsfähig, aber es ist wichtig, auch ihre Grenzen zu beachten, wie zum Beispiel:
Propensity Scores können nur für beobachtete Kovariaten angepasst werden, d. h. für die Variablen, die die Forscher gemessen und in das Modell aufgenommen haben. Aber das berücksichtigt nicht unbedingt versteckte Störfaktoren, die entweder unbeobachtet oder nicht gemessen sein könnten. Dabei bleiben zwangsläufig versteckte Vorurteile unberücksichtigt, die das Ergebnis immer noch beeinflussen können.
Wenn zum Beispiel die Auswirkungen zweier Therapien auf die psychische Gesundheit verglichen werden, können die Forscher Daten über das Alter, das Geschlecht und den Ausgangszustand der Patienten haben. Wenn jedoch nicht gemessene Faktoren wie soziale Unterstützung oder individuelle Bewältigungsmechanismen unberücksichtigt bleiben, können sie die Therapieergebnisse beeinflussen.
Propensity-Score-Methoden funktionieren am besten bei großen Datensätzen, um sicherzustellen, dass es eine ausreichende Überschneidung zwischen den Behandlungs- und Kontrollgruppen gibt. Kleinere Stichproben führen oft zu einem Mangel an genug Teilnehmer mit ähnlichen Propensity Scores in den Gruppen, was es schwierig macht, gute Übereinstimmungen oder eine sinnvolle Gewichtung zu erreichen.
Die Auswahl der richtigen Variablen und der funktionalen Form des Modells ist entscheidend für die korrekte Spezifikation des Neigungsmodells, was sich wiederum auf seine Genauigkeit auswirkt. Die Nichteinbeziehung der relevanten Variablen oder eine ungeeignete Modellspezifikation können zu verzerrten Schätzungen führen, aber das Schlimmste ist, dass es schwierig ist, solche Probleme überhaupt zu erkennen.
Es wurden fortschrittliche Techniken entwickelt, um einige der Einschränkungen der traditionellen Propensity-Score-Methoden zu überwinden.
Doppelt robuste Methoden sind ein zweistufiger Ansatz, bei dem die Forscher zunächst Propensity Scores schätzen und die Teilnehmer entsprechend anpassen oder gewichten. Dann passen sie ein Regressionsmodell an, um das Ergebnis auf der Grundlage der Behandlung und anderer Kovariaten vorherzusagen. Die endgültige Schätzung des Behandlungseffekts ergibt sich aus der Anpassung für den Propensity Score und das Regressionsmodell.
Bei Bayes'schen Methoden wird die Unsicherheit in die Schätzung der Propensity Scores einbezogen. Dadurch können wir genauere Schätzungen vornehmen, vor allem in Situationen mit kleineren Stichprobengrößen oder größerer Unsicherheit der Daten. Wenn du dich für Bayes'sche Ansätze interessierst, die immer mehr Verbreitung finden, besuche unseren Kurs Grundlagen der Bayes'schen Datenanalyse in R.
Bei der Verwendung von Propensity Scores gibt es häufige Fehler, die du vermeiden solltest.
Nach der Anwendung von Propensity-Score-Methoden ist es wichtig zu prüfen, ob die Kovariaten zwischen der Behandlungs- und der Kontrollgruppe ausgeglichen sind. Ohne ausreichende Ausgewogenheit könnten unsere Ergebnisse immer noch verzerrt sein.
Die Modellspezifikation ist bei der Berechnung von Propensity Scores von entscheidender Bedeutung, da eine falsche Spezifikation zu erheblichen Verzerrungen bei den Schätzungen des Behandlungseffekts führen kann. Forscher machen oft Fehler, indem sie entweder das Modell zu stark anpassen (zu viele Kovariaten einbeziehen) oder wichtige Störfaktoren auslassen.
Die Ausgewogenheit der Merkmale von Behandlungs- und Kontrollgruppen hilft uns, Verzerrungen zu minimieren und zuverlässigere Schätzungen der Behandlungseffekte zu liefern. Wie jede statistische Methode muss sie jedoch sorgfältig angewendet werden, wobei auf mögliche Einschränkungen und Fehler zu achten ist.
Ich hoffe, du weißt die Propensity Scores zu schätzen, die eine wichtige Methode zur Minimierung von Verzerrungen in Beobachtungsstudien sind, weil sie Behandlungs- und Kontrollgruppen anhand ihrer jeweiligen Merkmale gut ausbalancieren. Techniken wie Matching, Stratifizierung und Gewichtung helfen dabei, genauere kausale Rückschlüsse zu ziehen, indem sie Störfaktoren ausschließen.
Um diese Methoden effektiv anzuwenden, besuche unseren Kurs "Causal Inference with R - Regression ", der praktische Übungen mit dem Paket MatchIt bietet. Dieser großartige Kurs führt die Lernenden durch die Implementierung von Propensity Score Matching und anderen Techniken, damit du verlässlichere und unverzerrte Untersuchungen in Beobachtungsstudien durchführen kannst. Ich empfehle auch unseren Lernpfad zum Statistiker in R. Auch wenn du nicht vorhast, Statistiker zu werden, ist der Kurs eine großartige Ressource mit vielen Lerninhalten, die dich zu einem großartigen Analysten oder Datenwissenschaftler machen.
Lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
8 Min.
