Cursus
Principes fondamentaux de l'intelligence artificielle dans le monde des affaires
12 h
QwQ-32B n'est pas un simple modèle d'IA de type chatbot - il appartient à une autre catégorie : les modèles de raisonnement.
Alors que la plupart des modèles d'IA à usage général, comme GPT-4.5 ou DeepSeek-V3sont conçus pour générer des textes fluides et conversationnels sur un large éventail de sujets, les modèles de raisonnement se concentrent sur la décomposition logique des problèmes, la réalisation d'étapes et l'obtention de réponses structurées.
Dans l'exemple ci-dessous, nous pouvons voir directement le processus de réflexion de QwQ-32B :
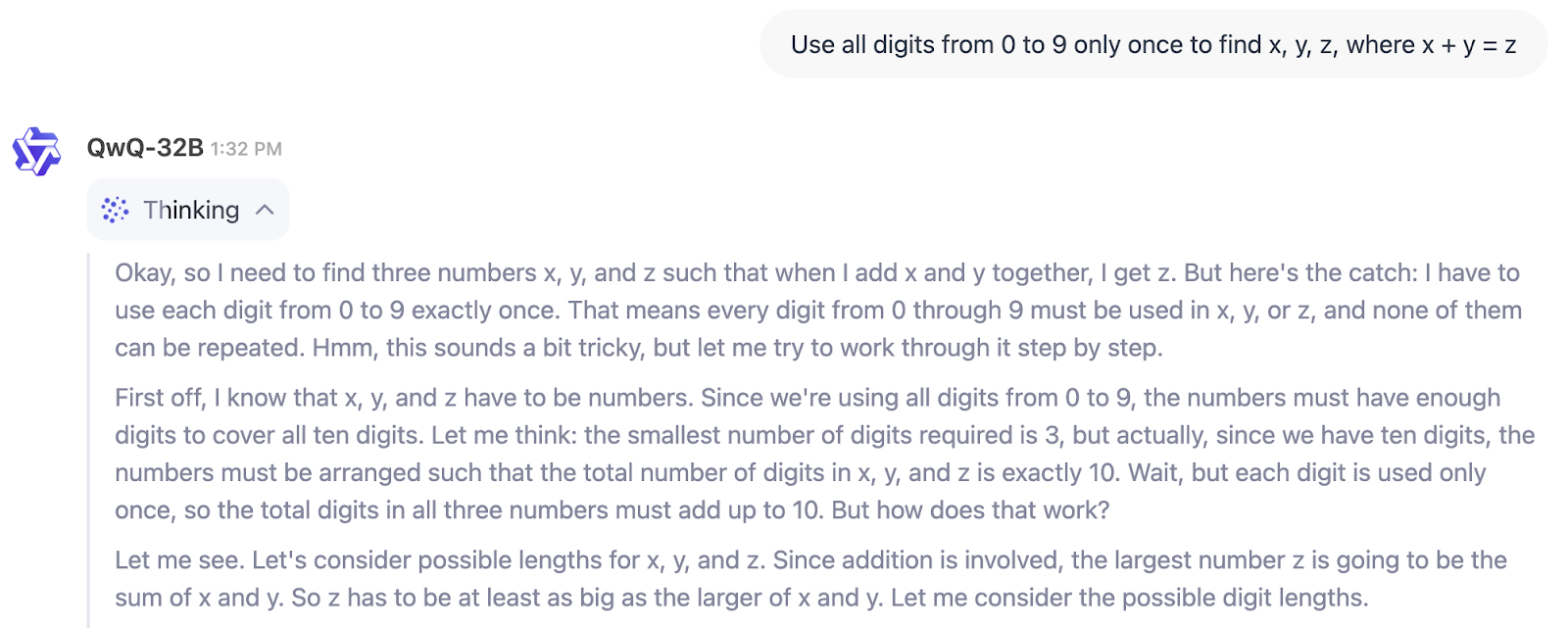
Alors, à qui s'adresse QwQ-32B ? Si vous cherchez un modèle pour vous aider à écrire, à réfléchir ou à résumer, ce n'est pas celui-là.
Mais si vous avez besoin d'un outil pour résoudre des problèmes techniques, vérifier des solutions en plusieurs étapes ou vous aider dans des domaines tels que la recherche scientifique, la finance ou le développement de logiciels, QwQ-32B est conçu pour ce type de raisonnement structuré. Il est particulièrement utile pour les ingénieurs, les chercheurs et les développeurs qui ont besoin d'une IA capable de gérer des flux de travail logiques plutôt que de simplement générer du texte.
Il faut également tenir compte d'une tendance plus générale du secteur. À l'instar de l'essor des petits modèles de langage (SLM)nous pourrions assister avec QwQ-32B à l'émergence de "petits modèles de raisonnement" (j'ai totalement inventé ce terme). Pourquoi est-ce que je dis cela ? Il y a une différence de 20 fois entre les paramètres 671B de DeepSeek-R1 et les 32B de QwQ-32B, mais QwQ-32B est encore proche en termes de performances (comme nous le verrons plus loin dans la section sur les benchmarks).
QwQ-32B est conçu pour résoudre des problèmes complexes, et cela est dû en grande partie à la façon dont il a été formé. Contrairement aux modèles d'IA traditionnels qui s'appuient uniquement sur le pré-entraînement et le réglage finQwQ-32B intègre l'apprentissage par renforcement (RL)une méthode qui permet au modèle d'affiner son raisonnement en apprenant par essais et erreurs.
Cette approche de formation a gagné du terrain dans le domaine de l'IA, avec des modèles comme DeepSeek-R1 qui utilisent une formation RL en plusieurs étapes pour obtenir des capacités de raisonnement plus fortes.
La plupart des modèles de langage apprennent en prédisant le mot suivant dans une phrase sur la base de grandes quantités de données textuelles. Si cette méthode fonctionne bien pour la fluidité, elle ne les rend pas nécessairement aptes à résoudre des problèmes.
L'apprentissage par renforcement modifie cette situation en introduisant un système de retour d'information : au lieu de simplement générer du texte, le modèle est récompensé lorsqu'il trouve la bonne réponse ou suit un chemin de raisonnement correct. Au fil du temps, cela aide l'IA à développer un meilleur jugement lorsqu'elle s'attaque à des problèmes complexes comme les mathématiques, le codage et le raisonnement logique .
QwQ-32B va plus loin en intégrant des capacités liées à l'agent, ce qui lui permet d'adapter son raisonnement en fonction des réactions de l'environnement. Cela signifie qu'au lieu de mémoriser des modèles, le modèle peut utiliser des outils, vérifier les résultats et affiner ses réponses de manière dynamique. Ces améliorations le rendent plus fiable pour les tâches de raisonnement structuré, où la simple prédiction de mots ne suffit pas.
L'un des aspects les plus impressionnants du développement de QwQ-32B est son efficacité. Bien qu'il ne dispose que de 32 milliards de paramètres, il atteint des performances comparables à celles de DeepSeek-R1, qui compte 671 milliards de paramètres (dont 37 milliards activés). Cela suggère que l'augmentation de l'apprentissage par renforcement peut avoir un impact tout aussi important que l'augmentation de la taille du modèle.
Un autre aspect clé de sa conception est sa fenêtre contextuelle de 131 072 mots, qui lui permet de traiter et de retenir des informations sur de longs passages de texte.
QwQ-32B est conçu pour rivaliser avec les modèles de raisonnement les plus récents, et ses résultats montrent qu'il est étonnamment proche de DeepSeek-R1, bien qu'il soit beaucoup plus petit. Le modèle a été testé sur une série de points de référence évaluant les mathématiques, le codage et le raisonnement structuré, où il a souvent obtenu des résultats équivalents ou proches des niveaux de DeepSeek-R1.
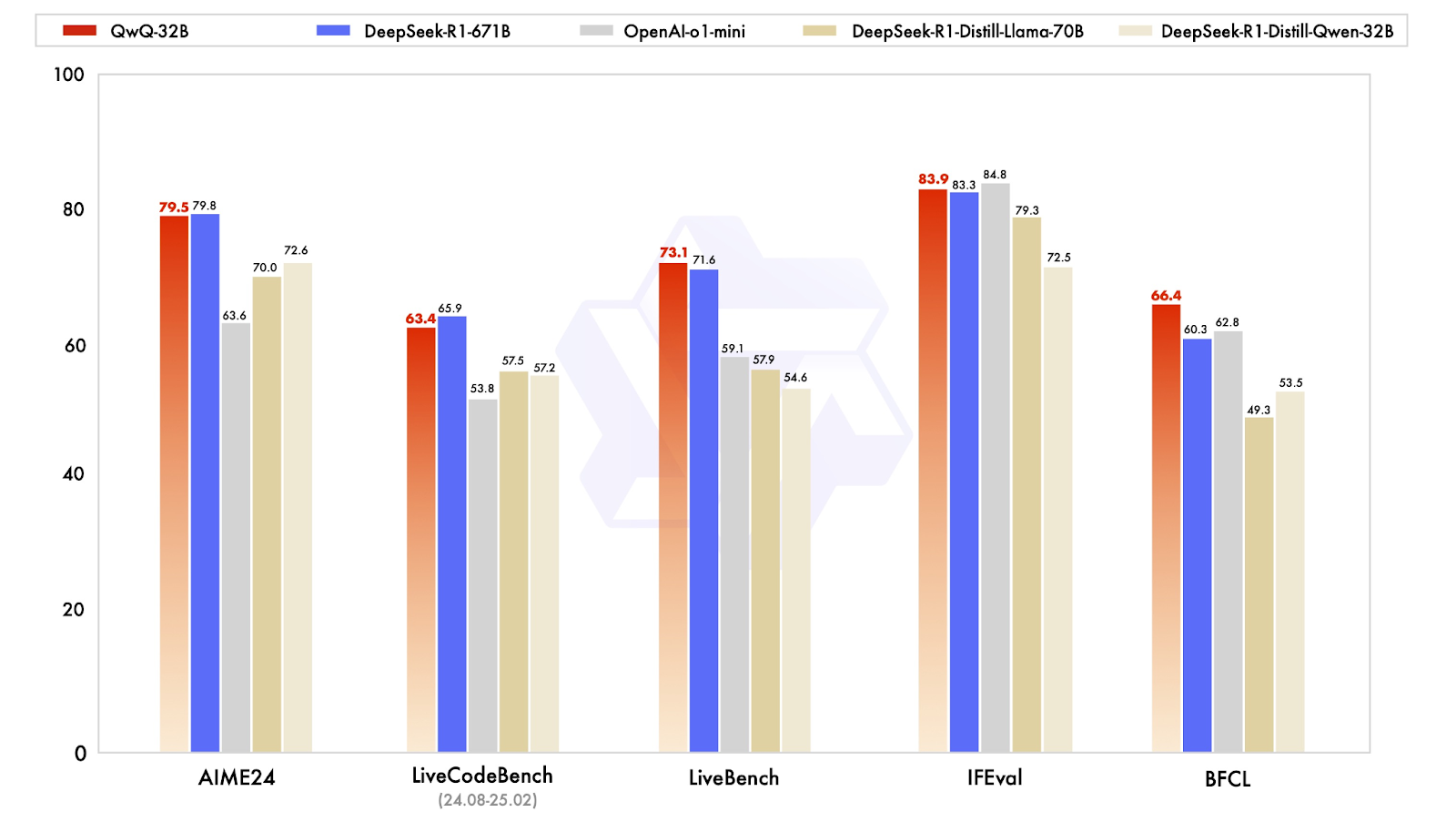
Source : Qwen
L'un des résultats les plus révélateurs provient de l'AIME24, un test de mathématiques conçu pour tester la résolution de problèmes mathématiques. QwQ-32B a obtenu un score de 79,5, juste derrière DeepSeek-R1 (79,8) et loin devant o1-mini d'OpenAI (63,6) et les modèles distillés de DeepSeek. modèles distillés de DeepSeek (70.0-72.6). Ce résultat est d'autant plus impressionnant que QwQ-32B ne compte que 32 milliards de paramètres, contre 671 milliards pour DeepSeek-R1.
Un autre critère clé, IFEval, qui teste le raisonnement fonctionnel et symbolique, a également permis à QwQ-32B d'atteindre un niveau compétitif, avec un score de 83,9, légèrement supérieur à celui de DeepSeek-R1 ! Il n'est devancé que de peu par l'o1-mini d'OpenAI, qui domine cette catégorie avec un score de 84,8.
Pour les modèles d'IA destinés à aider au développement de logiciels, les repères de codage sont essentiels. Dans LiveCodeBench, qui mesure la capacité à générer et à affiner le code, QwQ-32B a obtenu un score de 63,4, légèrement derrière DeepSeek-R1 (65,9), mais nettement devant o1-mini d'OpenAI (53,8) . Cela suggère que l'apprentissage par renforcement a joué un rôle important dans l'amélioration de la capacité de QwQ-32B à raisonner de manière itérative à travers les problèmes de codage plutôt que de simplement générer des solutions ponctuelles.
QwQ-32B a obtenu un score de 73,1 sur LiveBench, une évaluation des capacités générales de résolution de problèmes, dépassant légèrement le score de 71,6 de DeepSeek-R1. Ces deux modèles ont obtenu des résultats nettement supérieurs à ceux de l'o1-mini d'OpenAI, qui a obtenu un score de 59,1, ce qui confirme l'idée que de petits modèles bien optimisés peuvent combler l'écart avec les systèmes propriétaires massifs, au moins dans les tâches structurées.
Le résultat le plus intéressant est peut-être celui de BFCL, un test de référence évaluant le raisonnement fonctionnel général. Ici, QwQ-32B a obtenu 66,4, dépassant DeepSeek-R1 (60,3) et o1-mini d'OpenAI (62,8) . Cela suggère que l'approche de formation de QwQ-32B, en particulier ses capacités agentiques et ses stratégies d'apprentissage par renforcement, lui confère un avantage dans les domaines où la résolution de problèmes nécessite de la flexibilité et de l'adaptation plutôt que de simples schémas mémorisés.
QwQ-32B est entièrement open-source, ce qui en fait l'un des rares modèles de raisonnement très performants disponibles pour tout le monde. Que vous souhaitiez le tester de manière interactive, l'intégrer dans une application ou l'exécuter sur votre propre matériel, il existe de multiples façons d'accéder au modèle.
Pour ceux qui souhaitent simplement essayer le modèle sans rien mettre en place, Qwen Chat offre un moyen simple d'interagir avec QwQ-32B. L'interface web du chatbot vous permet de tester directement les capacités de raisonnement, de calcul et de codage du modèle. Bien qu'elle ne soit pas aussi souple que l'exécution locale du modèle, elle constitue un moyen simple de voir ses points forts en action.
Pour l'essayer, vous devez accéder à https://chat.qwen.ai/ et créer un compte. Une fois que vous êtes entré, commencez par sélectionner le modèle QwQ-32B dans le menu de sélection du modèle :
Le modeThinking (QwQ) est activé par défaut et ne peut pas être désactivé avec ce modèle. Vous pouvez commencer à poser des questions dans l'interface basée sur le chat :
Les développeurs qui souhaitent intégrer QwQ-32B dans leurs propres flux de travail peuvent le télécharger à l'adresse suivante Hugging Face ou de ModelScope. Ces plateformes permettent d'accéder aux poids du modèle, aux configurations et aux outils d'inférence, ce qui facilite le déploiement du modèle à des fins de recherche ou de production.
QwQ-32B remet en question l'idée selon laquelle seuls les modèles massifs peuvent être performants en matière de raisonnement structuré. Malgré un nombre de paramètres nettement inférieur à celui de DeepSeek-R1, il obtient d'excellents résultats en mathématiques, en codage et en résolution de problèmes en plusieurs étapes, ce qui montre que des techniques d'entraînement telles que l'apprentissage par renforcement et l'optimisation en contexte long peuvent avoir un impact significatif.
Ce qui me frappe le plus, c'est sa disponibilité en tant que source ouverte. Alors que de nombreux modèles de raisonnement très performants restent enfermés derrière des API propriétaires, QwQ-32B est accessible sur Hugging Face, ModelScope et Qwen Chat, ce qui permet aux chercheurs et aux développeurs de le tester et de le construire plus facilement.
Apprenez l'IA avec ces cours !
Cursus
Cursus
Cursus
blog
Nathaniel Taylor-Leach
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach