
Cursus
Associate Data Scientist en Python
90 h
Au fil des années, j'ai appris que même la plus petite modification de code peut avoir des conséquences imprévues. Ce qui peut initialement sembler être un changement mineur peut discrètement perturber quelque chose qui fonctionnait parfaitement.
C'est pourquoi les tests de régression sont importants. Il s'agit essentiellement d'une mesure de protection qui garantit que le progrès ne se fait pas au détriment de la stabilité.
D'après mon expérience dans le domaine des projets axés sur les données, où les modèles, les API et les pipelines évoluent constamment, les tests de régression se sont révélés essentiels pour garantir des résultats cohérents et fiables.
Sans cela, même de petits ajustements tels que la modification d'une fonction de transformation ou la mise à jour d'un package peuvent entraîner un comportement inattendu difficile à détecter.
Si vous débutez avec Python ou souhaitez rafraîchir vos connaissances fondamentales en codage avant de vous plonger davantage dans les tests, nous vous invitons à consulternotrecursus de compétences en programmation Python.
En résumé, les tests de régression consistent à tester à nouveau les fonctionnalités existantes après des modifications du code afin de confirmer qu'aucune régression n'est survenue.
Bien que le terme « régression » puisse sembler mathématique, dans le domaine des tests, il signifie en réalité « un pas en arrière ».
Chaque fois que vous modifiez du code (ce qui peut inclure la correction d'un bug ou l'ajout d'une fonctionnalité), il existe un risque que la nouvelle modification perturbe le fonctionnement de composants qui fonctionnaient auparavant. C'est pourquoi nous avons besoin de tests de régression.
Les tests de régression permettent de répondre à la question cruciale suivante :
Après cette modification, est-ce que tout ce qui fonctionnait auparavant fonctionne toujours actuellement ?
Contrairement aux tests unitaires, qui valident des composants isolés, ou aux tests d'intégration, qui vérifient le fonctionnement conjoint des modules, les tests de régression adoptent une perspective plus large et à plus long terme.
Il garantit que votre logiciel reste stable et cohérent d'une version à l'autre, même à mesure qu'il évolue.
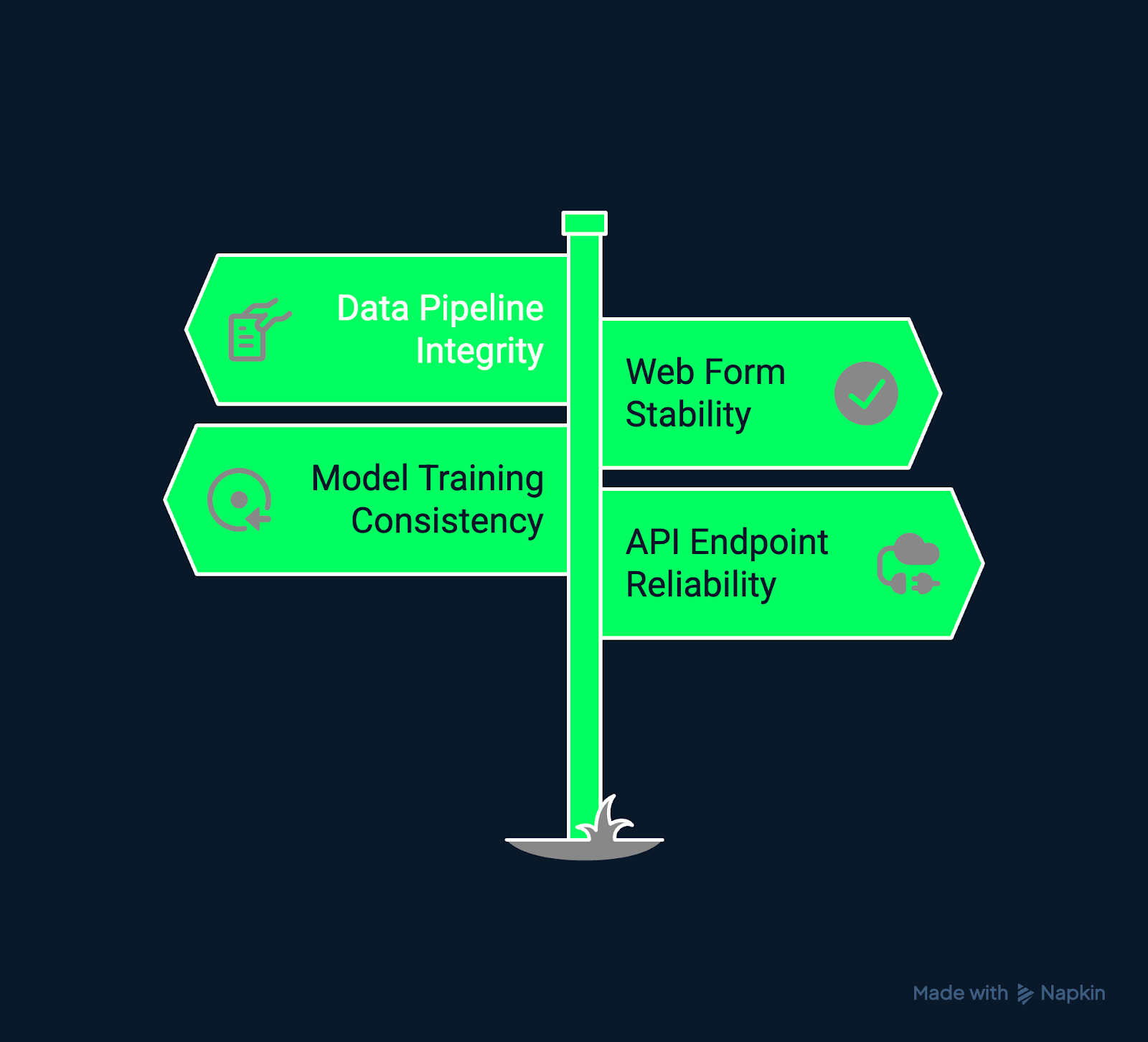
Exemples de tests de régression. Image créée par l'auteur à l'aide de Napkin AI.
Par exemple :
Dans les environnements de développement continu (en particulier Agile et DevOps), les tests de régression agissent comme un filet de sécurité qui vous permet d'itérer rapidement sans compromettre la stabilité.
Il renforce la confiance nécessaire pour les déploiements fréquents, les flux de travail automatisés et les pratiques d'intégration continue.
Les tests de régression constituent l'un des moyens les plus fiables de garantir la qualité constante de votre logiciel à mesure que votre système évolue. Il vous aide à détecter et à prévenir ces répercussions à un stade précoce, ce qui permet de préserver la stabilité et la confiance des utilisateurs.
Les nouveaux codes entraînent souvent des effets secondaires imprévus. Une simple refonte ou mise à niveau de dépendance pourrait perturber le fonctionnement de modules éloignés.
Les tests de régression vous permettent d'identifier ces problèmes avant qu'ils n'affectent la production ou les utilisateurs. Les suites de régression automatisées peuvent être exécutées après chaque mise à jour du code, ce qui permet de mettre en évidence les conflits entre la nouvelle logique et l'ancienne. Ces premiers commentaires vous permettent de gagner du temps, de réduire les coûts liés au débogage et de maintenir la confiance dans le développement.
Dans les équipes Agile ou DevOps qui évoluent rapidement, la régression automatisée agit comme un garde-fou qui permet aux développeurs d'innover sans craindre de perturber les fonctionnalités établies.
|
Avantage |
Description |
Exemple |
|
Détection précoce |
Identifie les bogues peu après les nouveaux commits |
Une nouvelle route API interrompt une requête client existante |
|
Débogage plus rapide |
Identifie précisément les points faibles de la nouvelle logique |
Les rapports CI associent les tests ayant échoué à des modules spécifiques. |
|
Confiance des développeurs |
Encourage les publications fréquentes et sécurisées |
Les équipes procèdent à des déploiements continus sans vérifications manuelles. |
L'un des aspects les plus frustrants de la maintenance logicielle est de constater qu'un ancien bug réapparaît.
Les tests de régression agissent comme des mesures de protection permanentes (c'est-à-dire qu'une fois qu'un bug est corrigé, le test correspondant garantit qu'il reste corrigé et ne réapparaît pas).
Au fil du temps, cela permet de créer un filet de sécurité basé sur l'historique des bogues de votre projet.
En intégrant cette pratique à votre flux de travail, votre suite de tests valide non seulement les nouvelles fonctionnalités, mais également toutes les corrections précédemment mises en œuvre.
|
Avant les tests de régression |
Après les tests de régression |
|
Les anciens bugs réapparaissent de manière imprévisible. |
Les problèmes résolus restent vérifiés de manière permanente. |
|
Les corrections de bogues dépendent de la mémoire ou de la documentation. |
Les tests confirment automatiquement les corrections précédentes. |
|
Les équipes d'assurance qualité effectuent des vérifications manuelles répétées. |
Les dispositifs de sécurité automatisés empêchent la récurrence des incidents. |
La fiabilité est un élément non négociable, en particulier du point de vue de l'utilisateur. Les fonctionnalités qui fonctionnent un jour et ne fonctionnent plus le lendemain nuisent à la confiance et à la satisfaction des utilisateurs.
Les tests de régression garantissent une expérience cohérente entre les mises à jour, ce qui renforce la confiance dans votre produit.
Dans les applications basées sur les données, cette fiabilité implique de maintenir des résultats cohérents et des comportements prévisibles, même lorsque les modèles, les sources de données et les API évoluent.
|
Domaine d'application |
Ce que protège le test de régression |
|
Tableaux de bord |
Garantit que les visualisations s'affichent correctement après les mises à jour du backend ou du schéma de données. |
|
API modèles |
Vérifie que les prévisions du modèle restent stables et reproductibles. |
|
Pipelines de données |
Confirme que les exportations de données préservent la cohérence du schéma et du format. |
Les tests de régression constituent également un élément essentiel de la gestion des risques. Sans cela, des bogues imprévus peuvent apparaître à un stade avancé du cycle de publication, ce qui pourrait entraîner des pannes ou des retours en arrière coûteux.
Vérifier la stabilité à chaque itération peut aider votre équipe à procéder à des mises en production en toute confiance, sachant que les modifications n'ont pas compromis les fonctionnalités.
|
Avec les tests de régression |
Sans tests de régression |
|
Lancements prévisibles et à faible risque |
Des bogues et des retours en arrière fréquents de dernière minute |
|
Pipelines CI/CD fiables |
Déploiements hésitants, goulots d'étranglement liés à l'assurance qualité manuelle |
|
Assurance qualité continue |
Lutte contre les incendies après le déploiement |
Les tests de régression ne sont pas universels. L'approche appropriée dépend de facteurs tels que la taille du code, la fréquence des modifications et l'impact sur l'activité.
Chacune des méthodes suivantes offre un équilibre différent entre vitesse, couverture et coût des ressources.
La forme la plus simple de test de régression consiste à exécuter tous les tests existants après une modification.
Bien qu'il garantisse que rien n'est omis, il devient de moins en moins pratique à mesure que les systèmes se développent.
Par conséquent, cette approche est souvent utilisée au début du cycle de vie d'un projet ou lors de la validation d'une refonte majeure.
La régression sélective ne vise que les zones directement touchées par les changements récents.
Il utilise l'analyse d'impact pour déterminer les dépendances et limiter la portée des tests.
Par exemple, si un module de transformation des données est modifié, il n'est pas nécessaire de réexécuter les tests associés à l'authentification ou au rendu de l'interface utilisateur.
Cette approche concilie précision et rapidité et repose sur un suivi efficace des dépendances.
Dans les systèmes de grande envergure, le temps et les ressources disponibles permettent rarement une couverture complète de la régression.
Les tests de régression prioritaires classent les cas de test par ordre d'importance et de niveau de risque, ce qui garantit que les chemins critiques (tels que les paiements ou l'authentification) sont vérifiés en premier.
Les tests de priorité inférieure peuvent être exécutés ultérieurement ou de manière asynchrone.
Le tableau ci-dessous présenteles niveaux de priorité types, avec des exemples de domaines couverts et les tests correspondants.
|
Niveau de priorité |
Exemple de zone |
Objectif des tests |
|
Élevé |
Traitement des paiements, authentification |
Il est impératif de ne jamais échouer et de toujours procéder à des essais préalables. |
|
Moyen |
Visuels du tableau de bord, notifications par e-mail |
Doit fonctionner de manière cohérente |
|
Faible |
Ajustements de mise en page, info-bulles |
Cosmétique et moins critique lors de cycles rapides |
Les tests de régression manuels deviennent rapidement difficiles à gérer à mesure que les projets prennent de l'ampleur.
L'automatisation, quant à elle, transforme les tests de régression, qui étaient auparavant une étape lente, en un moyen de travailler plus rapidement et avec plus de confiance.
Les suites automatisées s'exécutent à chaque build ou pull request, fournissent des commentaires instantanés et s'intègrent à des outils CI tels que Jenkins, GitHub Actions ou GitLab CI/CD.
Ils permettent une vérification continue dans tous les environnements, ce qui est une fonctionnalité essentielle pour les équipes Agile et DevOps qui cherchent à « avancer rapidement sans causer de problèmes ».
|
Avantage de l'automatisation |
Incidence sur le développement |
|
Retour d'information continu |
Identification plus rapide des modifications importantes |
|
Exécution cohérente |
Élimine les erreurs humaines dans les tests répétitifs |
|
Évolutivité |
Les tests sont exécutés simultanément dans tous les environnements. |
|
Prêt pour l'intégration |
S'intègre directement dans les flux de travail CI/CD |
Le tableau ci-dessous présente unaperçudes principales techniques de tests de régression mentionnées précédemment.
|
Type |
Description |
Pros |
Cons |
Idéal pour |
|
Veuillez effectuer un nouveau test complet. |
Exécute tous les cas de test après chaque modification. |
Couverture complète et validation approfondie |
Très chronophage et coûteux |
Systèmes de petite taille et tests de référence |
|
Régression sélective |
Les tests ne concernent que les composants affectés par les modifications du code. |
Retour d'information efficace et plus rapide |
Nécessite une cartographie précise des dépendances. |
Systèmes modulaires et mises à jour fréquentes |
|
Régression prioritaire |
Exécute les tests classés par impact commercial. |
Priorité aux fonctionnalités essentielles |
Il est possible de ne pas traiter les domaines moins critiques mais pertinents. |
Cycles de test limités dans le temps |
|
Régression automatisée |
S'exécute automatiquement via CI/CD après la validation du code. |
Rapide, évolutif, reproductible |
Nécessite une configuration et une maintenance |
Projets de grande envergure ou à évolution rapide |
La création d'une suite de régression représente un investissement continu dans la qualité des logiciels.
Au fil du temps, il devient l'un des atouts les plus précieux de votre processus de développement.
L'image ci-dessous illustre les étapes nécessaires à la création et à la maintenance d'une suite de régression.
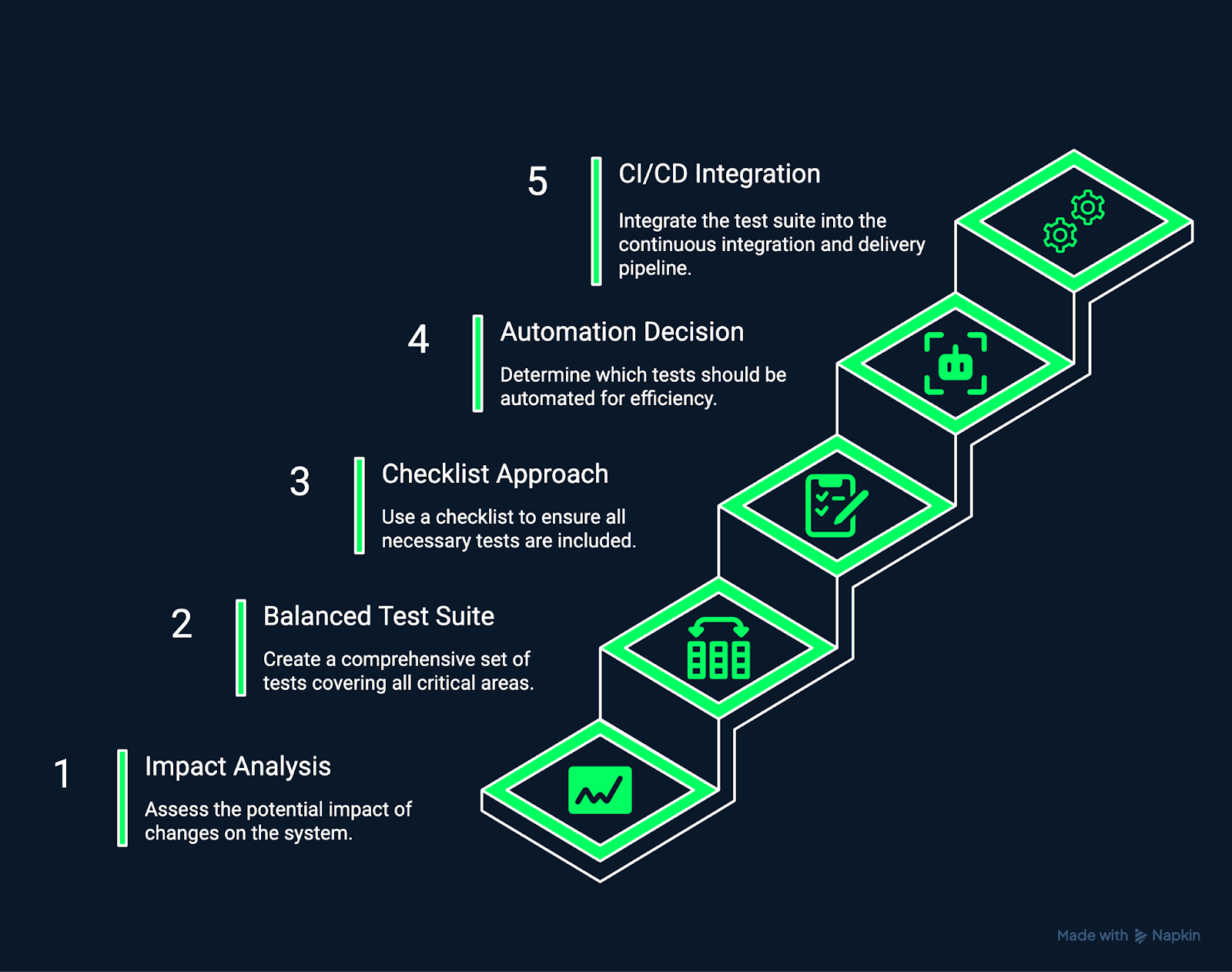
Création et maintenance d'une suite de régression. Image réalisée par l'auteur à l'aide de Napkin AI.
Commencez par identifier les composantes du système qui sont affectées par un changement.
Il est recommandé d'utiliser des outils tels que des analyseurs de couverture de code ou des graphiques de dépendance pour déterminer les tests à réexécuter.
Veuillez donner la priorité aux modules qui interagissent avec le code modifié, partagent des structures de données communes ou ont déjà rencontré des difficultés après des mises à jour similaires.
Développez une suite de tests qui couvre de manière exhaustive les flux de travail critiques, les processus de données essentiels et les parcours utilisateurs courants.
Veuillez vous assurer que chaque test a un objectif et une portée spécifiques, et essayez d'éviter toute redondance ou chevauchement.
Les tests modulaires et réutilisables facilitent la maintenance à mesure que votre système évolue.
Une liste de contrôle structurée contribue à garantir la cohérence et l'exhaustivité des tests de régression manuels et automatisés.
Il réduit les contrôles, normalise l'exécution et favorise des processus d'assurance qualité reproductibles.
|
Étape |
Objectif |
|
Définir les conditions préalables |
Définir l'état du système et saisir les données |
|
Exécuter le scénario de test |
Effectuer le test dans des conditions contrôlées |
|
Vérifier les résultats |
Vérifier à la fois les résultats attendus et les effets secondaires. |
|
Résultats exceptionnels |
Documents acceptés, refusés et anomalies éventuelles |
Cette méthode apporte structure,transparence et responsabilité, ce qui est particulièrement utile lors de l'intégration de nouveaux ingénieurs QA.
Tous les tests ne devraient pas être automatisés.
Automatisez les tests stables, reproductibles et à haute fréquence, notamment ceux qui valident les flux de travail critiques ou les domaines fréquemment mis à jour.
Conservez un manuel d'exploration et de test d'utilisabilité, car le jugement humain apporte une valeur ajoutée.
|
Automatiser lorsque : |
Conservez le manuel lorsque : |
|
Les scénarios sont répétitifs et stables. |
Les scénarios nécessitent une interprétation humaine |
|
Les données de test sont prévisibles. |
L'expérience utilisateur ou le comportement de l'interface utilisateur est en cours d'évaluation. |
|
Les tests sont fréquemment exécutés via CI/CD. |
Des tests ponctuels ou exploratoires sont effectués. |
L'intégration des tests de régression dans les pipelines CI/CD garantit que chaque modification est vérifiée automatiquement.
Configurez les builds pour qu'ils échouent si les tests de régression détectent de nouveaux problèmes, générez des rapports pour un triage immédiat et appliquez la philosophie « tester tôt, tester souvent ».
Cette approche empêche l'accumulation des régressions et favorise une véritable culture de la qualité continue.
|
Avantages de l'intégration CI/CD |
Résultat |
|
Vérification automatique après chaque validation |
Détection précoce des régressions |
|
Avertissements en cas d'échec de la compilation |
Triage rapide du code problématique |
|
Boucle de rétroaction continue |
Qualité constante tout au long des itérations rapides |
Une gamme d'outils modernes facilite la réalisation de tests de régression efficaces et évolutifs.
Le choix de l'outil approprié dépend de la pile technologique de votre projet, de vos objectifs en matière d'automatisation et du niveau de maturité de votre équipe.
Vous trouverez ci-dessous plusieurs options largement adoptées qui simplifient et accélèrent les workflows de régression.
Katalon Studio est une plateforme complète d'automatisation des tests qui prend en charge les tests Web, API, mobiles et de bureau.
Il dispose d'une interface graphique conviviale et de solides capacités de script. Par conséquent, cette méthode est utilisée par les équipes qui passent des tests de régression manuels aux tests de régression automatisés.
Katalon propose des tests intégrés basés sur des mots-clés et des données, une reconnaissance intelligente des objets et des tableaux de bord détaillés pour la création de rapports.
L'un de ses principaux avantages est son accessibilité : les testeurs qui ne possèdent pas de connaissances approfondies en programmation peuvent concevoir visuellement des cas de test complexes, tandis que les utilisateurs avancés peuvent personnaliser le comportement à l'aide de Groovy ou JavaScript.
La plateforme s'intègre parfaitement aux systèmes CI/CD tels que Jenkins et GitLab, ce qui permet d'effectuer des tests de régression automatisés à chaque compilation.
Cypress est un framework de test complet, rapide et convivial pour les développeurs, spécialement conçu pour les applications web modernes. Contrairement aux outils traditionnels basés sur Selenium, Cypress s'exécute directement dans le navigateur, ce qui lui permet d'observer, de contrôler et de déboguer le comportement Web en temps réel.
Cette architecture offre un retour d'information instantané, un rechargement en direct et une exécution des tests hautement fiable, sans les instabilités qui affectent parfois l'automatisation des navigateurs.
Il est particulièrement adapté aux équipes qui utilisent déjà des frameworks tels que React, Angular ou Vue, car sa syntaxe basée sur JavaScript s'intègre naturellement dans les workflows de développement front-end.
Cypress fournit également des outils de débogage avancés, une mise en attente automatique et des journaux de test détaillés avec des captures d'écran et des vidéos, ce qui est idéal pour diagnostiquer rapidement les régressions.
Testsigma propose une plateforme moderne d'automatisation des tests basée sur le cloud qui utilise le traitement du langage naturel (NLP) pour rédiger des cas de test en anglais courant.
Cette approche réduit considérablement les obstacles à l'entrée, ce qui permet aux membres non techniques de l'équipe, tels que les analystes QA ou les propriétaires de produits, de contribuer directement à la suite de tests de régression.
Il prend en charge les tests Web, mobiles, API et de bureau dans un environnement unifié, aidant les équipes Agile à obtenir une large couverture sans charge de codage importante.
Testsigma s'adapte également facilement à tous les navigateurs, systèmes d'exploitation et appareils, ce qui est particulièrement utile pour les équipes qui gèrent plusieurs cibles de déploiement.
Il s'intègre parfaitement aux outils DevOps et aux pipelines CI/CD courants, offrant une exécution en temps réel, des tests parallèles et une maintenance des tests assistée par l'IA.
Au-delà de ces plateformes de premier plan, d'autres outils spécialisés peuvent compléter les workflows de tests de régression.
Selenium demeure une option open source fondamentale pour l'automatisation des navigateurs, en particulier pour les équipes qui maîtrisent la gestion des frameworks et des scripts personnalisés. Développé par Microsoft, Playwright offre des fonctionnalités similaires avec une exécution plus rapide et une compatibilité multi-navigateurs plus étendue.
Pour les tests mobiles, des outils tels qu'Appium étendent l'automatisation aux plateformes iOS et Android à l'aide d'une API unifiée.
Ces outils constituent un écosystème robuste pour les tests de régression. Chacun prend en charge l'intégration avec les pipelines CI/CD, les systèmes de contrôle de version et l'infrastructure cloud.
Les tests de régression sont importants, mais ils présentent certaines difficultés.
À mesure que les systèmes évoluent et que les suites de tests se développent, il devient de plus en plus complexe de maintenir la rapidité, la fiabilité et la précision.
Comprendre les défis courants et la manière de les relever aide les équipes à maintenir des pratiques de régression efficaces et à fort impact au fil du temps.
L'image ci-dessous illustre certains des défis courants rencontrés lors des tests de régression.
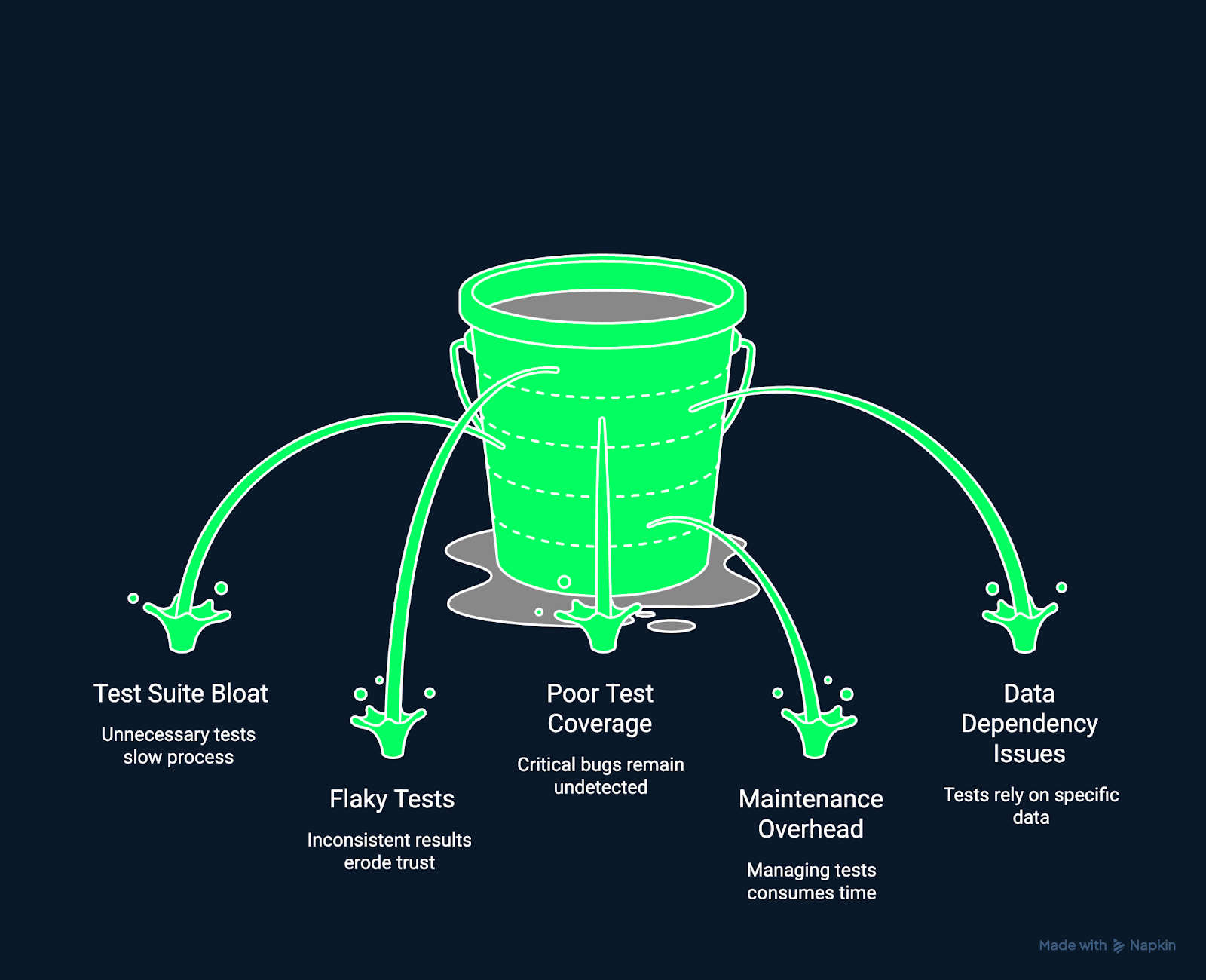
Difficultés rencontrées lors des tests de régression. Image réalisée par l'auteur à l'aide de Napkin AI.
Au fur et à mesure que les projets évoluent, les cas de test peuvent s'accumuler plus rapidement qu'ils ne sont examinés. Cela conduit à des suites volumineuses qui prennent plus de temps à exécuter et contiennent des tests redondants ou obsolètes. Les suites de tests trop volumineuses ralentissent les boucles de rétroaction et réduisent l'efficacité des tests.
La solution consiste à auditer et à refactoriser régulièrement votre suite de tests. Veuillez supprimer les tests obsolètes ou en double, regrouper les scénarios qui se recoupent et archiver les cas historiques qui ne sont plus pertinents.
Les tests qui échouent de manière aléatoire peuvent être source de frustration pour les développeurs. Les tests instables, c'est-à-dire ceux qui réussissent ou échouent de manière incohérente, peuvent résulter d'opérations asynchrones ou d'environnements instables. Ils diminuent la confiance dans votre système de test et masquent les régressions réelles.
La solution consiste à stabiliser les environnements de test, à utiliser des données fictives à la place des appels réels et à ajouter des attentes explicites ou une synchronisation lorsque cela est nécessaire. Suivez et mettez de côté les tests instables jusqu'à ce qu'ils soient corrigés afin de préserver la confiance dans les résultats de l'automatisation.
Même après des tests approfondis, certains chemins critiques peuvent rester non testés en raison de contraintes de temps ou d'une responsabilité mal définie. Une couverture insuffisante permet aux régressions de passer inaperçues.
La solution consiste à utiliser des outils de couverture de code et d'analyse des tests pour identifier les zones non testées. Concentrez-vous d'abord sur les modules à haut risque et à fort impact, et assurez-vous que les nouvelles fonctionnalités incluent dès le départ une couverture des tests de régression.
Les tests de régression automatisés peuvent devenir fragiles et cesser de fonctionner après de petites mises à jour de l'interface utilisateur ou de l'API. Les coûts d'entretien élevés peuvent dissuader la réalisation de tests continus et ralentir la livraison.
La solution consiste à concevoir des tests modulaires et réutilisables et à utiliser des localisateurs d'éléments robustes ou des contrats API. Mettre en place des couches d'abstraction entre les tests et la logique d'application afin de minimiser les réécritures après les mises à jour.
Les tests qui s'appuient sur des sources de données en temps réel ou modifiables peuvent produire des résultats incohérents, ce qui rend difficile la distinction entre les défaillances réelles et le bruit ambiant.
La solution consiste à utiliser des données de test contrôlées ou des services fictifs afin de garantir des résultats prévisibles et reproductibles. Vérifiez et documentez vos données de test afin d'assurer leur cohérence dans tous les environnements.
|
Défi |
Description |
Stratégie d'atténuation |
|
Surcharge de la suite de tests |
Les cas de test s'accumulent au fil du temps, ce qui ralentit l'exécution. |
Réorganisez et supprimez régulièrement les tests redondants. |
|
Tests instables |
Les tests échouent de manière intermittente en raison de problèmes de synchronisation, de dépendances ou d'incohérences environnementales. |
Réorganisez et supprimez régulièrement les tests redondants. |
|
Couverture insuffisante des tests |
Certains chemins critiques ne sont pas testés en raison d'une omission ou d'un manque de temps. |
Veuillez utiliser des outils de couverture de code pour identifier les lacunes. |
|
Frais généraux de maintenance |
Les tests automatisés cessent de fonctionner après des modifications mineures de l'interface utilisateur ou de l'API. |
Utilisez une conception de test modulaire et des sélecteurs robustes. |
|
Problèmes de dépendance des données |
Les tests s'appuient sur des sources de données variables ou en temps réel. |
Veuillez utiliser des fixtures, des mocks ou des ensembles de données synthétiques. |
Si vous souhaitez approfondir vos connaissances en matière de validation statistique et de tests analytiques, nous vous invitons à suivre notre cours « Tests d'hypothèses en Python ».
Les tests de régression rigoureux consistent à exécuter des tests et à mettre en place un cadre durable pour garantir une qualité continue.
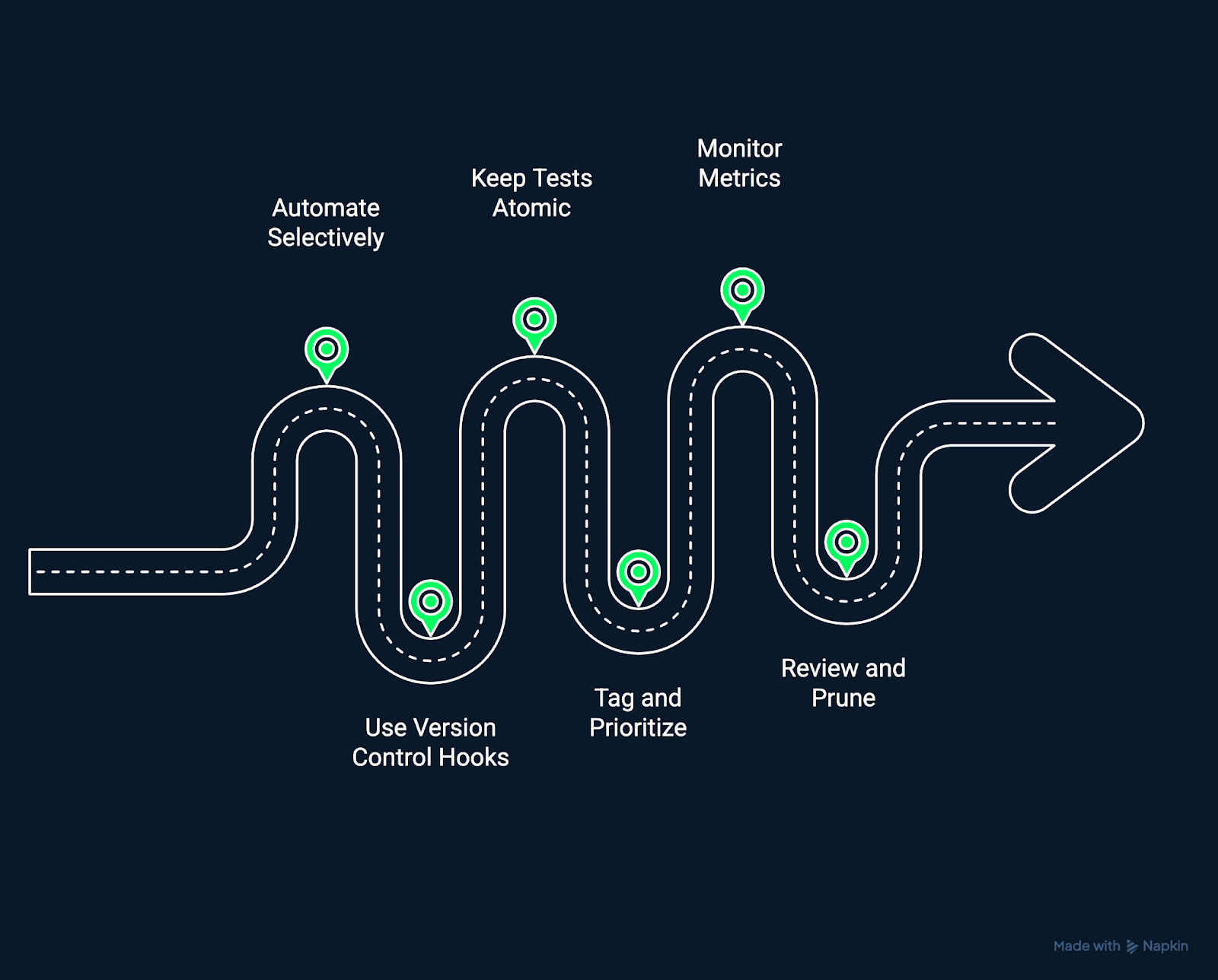
Meilleures pratiques pour des tests de régression efficaces. Image réalisée par l'auteur à l'aide de Napkin AI.
L'automatisation renforce la puissance des tests, mais tous les tests ne doivent pas nécessairement être automatisés. Commencez par automatiser les tests stables et à forte valeur ajoutée qui valident les workflows essentiels. Veuillez éviter d'automatiser les zones instables jusqu'à ce que leur fonctionnalité se stabilise afin de réduire les frais généraux liés à la maintenance.
Intégrez les tests de régression directement dans votre système de contrôle de version. Déclenchez des tests automatisés sur les pull requests ou les fusions afin de détecter les régressions avant que les modifications ne soient fusionnées dans les branches principales. Cela permet d'adopter une approche proactive et préventive en matière de tests.
Chaque test doit valider un comportement de manière isolée. Les tests atomiques facilitent le diagnostic des défaillances et réduisent les problèmes en cascade lorsqu'un composant tombe en panne. Des tests indépendants peuvent également être exécutés en parallèle, ce qui accélère les boucles de rétroaction CI/CD.
Étiquetez les tests en fonction de leur importance, par exemple « fumée », « régression » ou « performance ». Effectuez des tests à fort impact à chaque validation, tandis que des suites plus complètes peuvent être exécutées chaque nuit ou avant la publication. La hiérarchisation garantit que les tests sont adaptés aux contraintes de temps et aux risques commerciaux.
Évaluez vos performances en matière de tests au fil du temps. Suivez les indicateurs tels que les taux d'échec, la durée d'exécution et les tendances de couverture afin d'identifier les goulots d'étranglement et les possibilités d'amélioration. La mesure continue garantit la flexibilité et la fiabilité de vos tests de régression.
Les suites de tests de régression sont des systèmes évolutifs. Au fil du temps, veuillez supprimer les tests obsolètes, mettre à jour les attentes et ajuster les priorités. Une suite de tests pertinente et allégée fournit des informations plus rapides et plus précises, avec moins de bruit.
|
Pratique |
Objectif |
Exemple ou résultat |
|
Automatisez dès le début, mais de manière sélective |
Concentrer les efforts sur des tests stables et de grande valeur |
Réduire les frais généraux liés à la maintenance |
|
Utiliser les hooks de contrôle de version |
Détecter les régressions avant de fusionner le code |
Exécutez automatiquement des tests sur les demandes de modification. |
|
Veuillez vous assurer que les tests restent atomiques et indépendants. |
Simplifier le débogage et permettre les exécutions parallèles |
Chaque test évalue un comportement spécifique. |
|
Veuillez utiliser le marquage des tests et la hiérarchisation des priorités. |
Allouer efficacement les ressources de test |
Tests critiques effectués à chaque validation |
|
Surveiller les indicateurs de test |
Cursus de suivi de la santé et de l'efficacité de la suite |
Identifier les zones lentes ou instables |
|
Veuillez examiner et élaguer régulièrement. |
Assurez-vous que la suite reste rapide et pertinente. |
Supprimer les cas obsolètes ou redondants |
Ces pratiques combinées constituent le fondement d'uneculture saineen matière de tests de régression, qui privilégie la rapidité, la fiabilité et la maintenabilité à long terme.
Pour renforcer votre capacité à écrire du code facile à maintenir et à tester , veuillez consulter notre cours Principes d'ingénierie logicielle en Python.
Il est important de noter qu'à mesure que les systèmes logiciels évoluent et gagnent en complexité, les tests de régression deviennent une mesure de protection essentielle pour maintenir la stabilité et la confiance des utilisateurs. Chaque modification du code, aussi minime soit-elle, comporte un risque potentiel. Une stratégie solide de tests de régression peut vous aider à fournir des mises à jour en toute confiance et à agir rapidement sans perturber le fonctionnement du logiciel sur lequel vos utilisateurs comptent.
Pour continuer à développer votre expertise en matière de tests logiciels, nous vous invitons à explorer notre cours Introduction aux tests en Python. Si vous souhaitez intégrer des stratégies de test robustes dans des pipelines de déploiement modernes, nous vous invitons à consulter notre cours CI/CD pour l'apprentissage automatique.
Apprenez avec DataCamp
Cursus
Cursus
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Moez Ali
Tutoriel
Satyabrata Pal
Tutoriel
Matt Crabtree