
Programa
Associate Data Scientist em Python
90 h
Ao longo dos anos, aprendi que mesmo a menor alteração no código pode ter consequências inesperadas. O que pode parecer uma pequena mudança no começo pode acabar estragando algo que estava funcionando perfeitamente.
É por isso que os testes de regressão são importantes. É basicamente uma proteção que garante que o progresso não venha às custas da estabilidade.
Na minha experiência com projetos baseados em dados, onde modelos, APIs e pipelines estão sempre mudando, os testes de regressão têm sido essenciais para manter resultados consistentes e confiáveis.
Sem isso, até pequenos ajustes, como mexer numa função de transformação ou atualizar um pacote, podem causar um comportamento inesperado que é difícil de rastrear.
Se você é novo no Python ou quer dar uma repassada nos fundamentos de programação antes de mergulhar mais fundo nos testes, dáuma olhada no nossoprograma de habilidades em Python.
Resumindo, o teste de regressão é quando a gente testa de novo as funcionalidades que já existem depois de mudar o código, só pra ter certeza de que nada ficou “regressado” e quebrado.
Mesmo que a palavra “regressão” pareça matemática, nos testes, ela na verdade significa “um passo para trás”.
Sempre que você modifica o código (o que pode incluir corrigir um bug ou adicionar um recurso), existe a possibilidade de que a nova alteração danifique componentes que antes funcionavam, e é por isso que precisamos de testes de regressão.
O teste de regressão responde à seguinte pergunta importante:
Depois dessa mudança, tudo que funcionava antes ainda funciona agora?
Diferente dos testes unitários, que validam componentes isolados, ou dos testes de integração, que verificam como os módulos funcionam juntos, os testes de regressão têm uma visão mais ampla e de longo prazo.
Isso garante que seu software continue estável e consistente a cada nova versão, mesmo à medida que evolui.
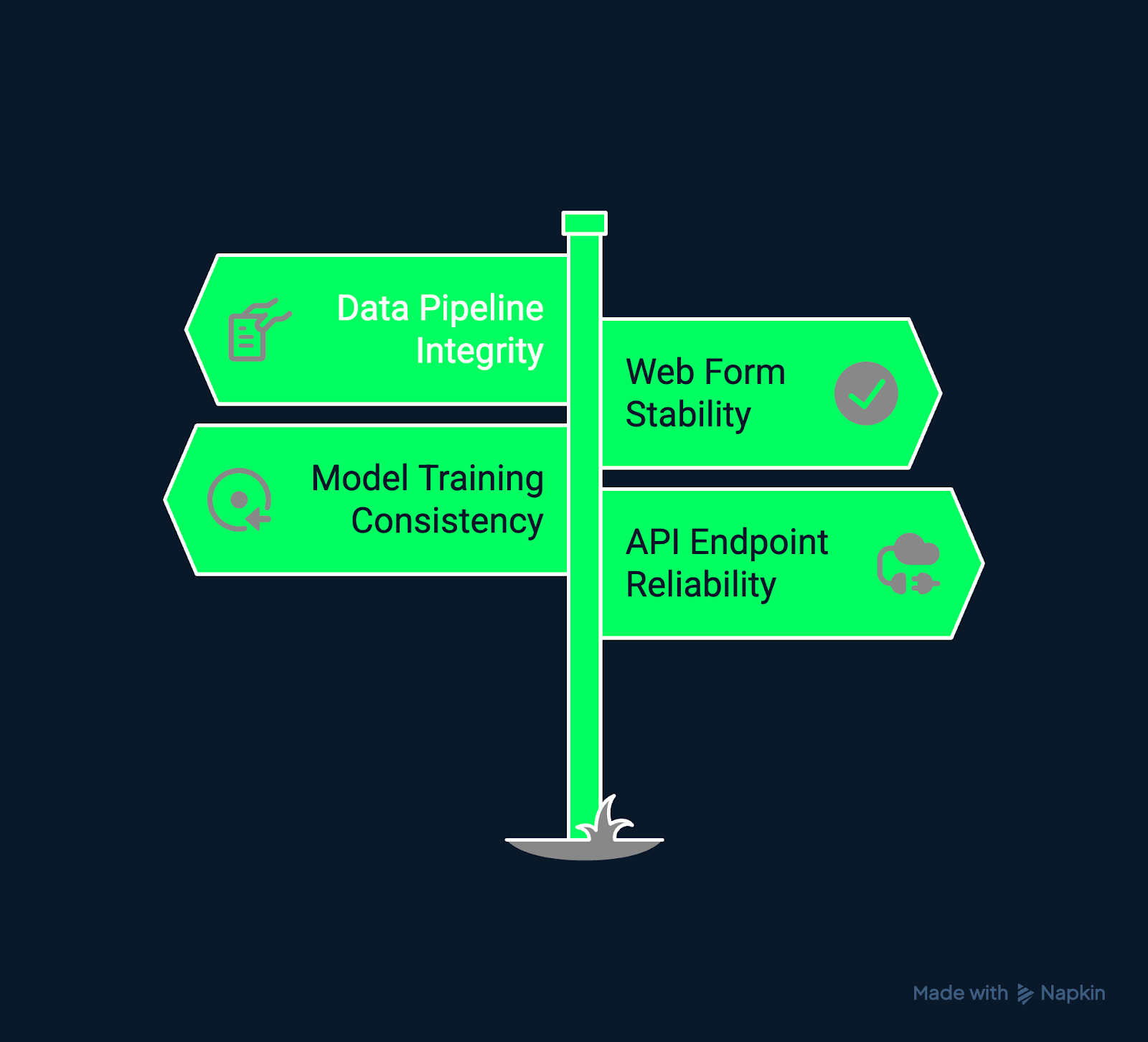
Exemplos de testes de regressão. Imagem criada pelo autor usando o Napkin AI.
Por exemplo:
Em ambientes de desenvolvimento contínuo (principalmente Agile e DevOps), os testes de regressão são tipo uma rede de segurança que te deixa fazer iterações rápidas sem perder a estabilidade.
Ele dá aquele suporte de confiança que a gente precisa pra fazer implantações frequentes, fluxos de trabalho automatizados e práticas de integração contínua.
O teste de regressão é uma das maneiras mais confiáveis de garantir que a qualidade do seu software continue consistente à medida que o sistema evolui. Isso ajuda você a detectar e prevenir esses efeitos em cascata logo no início, o que, por sua vez, mantém a estabilidade e a confiança dos usuários.
Um novo código muitas vezes traz efeitos colaterais indesejados. Uma simples refatoração ou atualização de dependência pode prejudicar a funcionalidade em módulos distantes.
Os testes de regressão ajudam a identificar esses problemas antes que eles afetem a produção ou os usuários. Conjuntos de regressão automatizados podem ser executados após cada envio de código, o que pode destacar conflitos entre a lógica nova e a antiga. Esse feedback inicial economiza seu tempo, reduz a sobrecarga de depuração e mantém a confiança no desenvolvimento.
Em equipes ágeis ou DevOps que trabalham rápido, a regressão automatizada funciona como uma proteção que deixa os desenvolvedores inovarem sem medo de quebrar recursos já estabelecidos.
|
Benefício |
Descrição |
Exemplo |
|
Detecção precoce |
Identifica bugs logo depois de novos commits |
Uma nova rota API interrompe uma solicitação de cliente existente |
|
Depuração mais rápida |
Identifica exatamente onde a nova lógica falha |
Os relatórios de CI mostram os testes que não deram certo em módulos específicos. |
|
Confiança dos desenvolvedores |
Incentiva lançamentos frequentes e seguros |
As equipes fazem implantações direto, sem precisar de verificações manuais. |
Uma das coisas mais chatas na manutenção de software é ver um bug antigo voltar.
Os testes de regressão funcionam como proteções permanentes (ou seja, depois que um bug é corrigido, o teste correspondente garante que ele continue corrigido e não volte a aparecer).
Com o tempo, isso cria uma rede de segurança com base no histórico de bugs do seu próprio projeto.
Incorporar essa prática ao seu fluxo de trabalho significa que seu conjunto de testes valida não só novas funcionalidades, mas também todas as correções que foram implementadas antes.
|
Antes dos testes de regressão |
Depois dos testes de regressão |
|
Os bugs antigos voltam a aparecer sem aviso prévio |
Problemas corrigidos ficam permanentemente verificados |
|
As correções de bugs dependem da memória ou da documentação. |
Os testes confirmam automaticamente as correções anteriores. |
|
As equipes de controle de qualidade repetem as verificações manuais. |
Os guardas automatizados evitam que as coisas se repitam |
A confiabilidade não é algo que se possa negociar, principalmente do ponto de vista do usuário. Recursos que funcionam um dia e falham no outro acabam com a confiança e a satisfação do usuário.
Os testes de regressão garantem uma experiência consistente entre as atualizações, o que reforça a confiança no seu produto.
Em aplicativos baseados em dados, essa confiabilidade significa manter resultados consistentes e comportamentos previsíveis, mesmo com a evolução dos modelos, fontes de dados e APIs.
|
Área de aplicação |
O que os testes de regressão protegem |
|
Painéis |
Garantir que as visualizações sejam renderizadas corretamente após atualizações no backend ou no esquema de dados. |
|
Modelos de API |
Verifica se as previsões do modelo continuam estáveis e reproduzíveis. |
|
Pipelines de dados |
Confirma que as exportações de dados mantêm a consistência do esquema e do formato. |
O teste de regressão também é uma parte importante da gestão de riscos. Sem isso, bugs inesperados podem aparecer no final do ciclo de lançamento, o que pode causar interrupções ou reversões caras.
Verificar a estabilidade a cada iteração pode ajudar sua equipe a lançar com confiança, sabendo que as mudanças não comprometeram a funcionalidade.
|
Com testes de regressão |
Sem testes de regressão |
|
Lançamentos previsíveis e de baixo risco |
Erros e reversões de última hora frequentes |
|
Pipelines de CI/CD confiáveis |
Implantações hesitantes, gargalos de controle de qualidade manual |
|
Garantia de qualidade contínua |
Combate a incêndios após a implantação |
O teste de regressão não é igual para todos. A abordagem certa depende de fatores como o tamanho da base de código, a frequência das alterações e o impacto nos negócios.
Cada um desses métodos equilibra velocidade, cobertura e custo de recursos de maneira diferente.
A forma mais simples de teste de regressão envolve executar todos os testes existentes após uma alteração.
Mesmo garantindo que nada seja esquecido, isso se torna cada vez mais impraticável à medida que os sistemas crescem.
Por isso, essa abordagem é frequentemente usada no início do ciclo de vida de um projeto ou quando se valida uma grande refatoração.
A regressão seletiva só afeta as áreas diretamente afetadas pelas mudanças recentes.
Ele usa análise de impacto para ver quais são as dependências e limitar o escopo dos testes.
Por exemplo, se um módulo de transformação de dados mudar, os testes relacionados à autenticação ou renderização da interface do usuário podem não precisar ser executados novamente.
Essa abordagem equilibra precisão com velocidade e depende de um bom rastreamento de dependências.
Em sistemas grandes, o tempo e os recursos raramente permitem uma cobertura completa da regressão.
Os testes de regressão priorizados classificam os casos de teste por importância e nível de risco, o que garante que os caminhos críticos (como pagamentos ou autenticação) sejam verificados primeiro.
Os testes com prioridade mais baixa podem ser executados mais tarde ou de forma assíncrona.
A tabela abaixo mostraos níveis de prioridade típicos, com exemplos de áreas cobertas e o foco de teste correspondente.
|
Nível de prioridade |
Exemplo de área |
Foco nos testes |
|
Alto |
Processamento de pagamentos, autenticação |
Nunca pode falhar e sempre testado primeiro |
|
Médio |
Visuais do painel, notificações por e-mail |
Deve funcionar de forma consistente |
|
Baixo |
Ajustes de layout, dicas de ferramentas |
Cosmético e menos crítico durante ciclos rápidos |
Os testes de regressão manuais rapidamente se tornam insustentáveis à medida que os projetos crescem.
Já a automação transforma o teste de regressão de uma etapa lenta em uma maneira de trabalhar mais rápido e com mais confiança.
Suítes automatizadas rodam em cada compilação ou solicitação de pull, dão feedback na hora e se integram com ferramentas de CI como Jenkins, GitHub Actions ou GitLab CI/CD.
Elas permitem uma verificação contínua em todos os ambientes, o que é essencial para equipes ágeis e de DevOps que querem “agir rápido sem quebrar nada”.
|
Benefício da automação |
Impacto no desenvolvimento |
|
Feedback contínuo |
Identificação mais rápida de alterações significativas |
|
Execução consistente |
Acaba com os erros humanos em testes repetitivos |
|
Escalabilidade |
Os testes são executados simultaneamente em todos os ambientes |
|
Pronto para integração |
Se encaixa direitinho nos fluxos de trabalho de CI/CD |
A tabela abaixo dá umavisão geral rápidadas principais técnicas de teste de regressão que falamos acima.
|
Tipo |
Descrição |
Pros |
Contras |
Ideal para |
|
Teste tudo de novo |
Executa todos os casos de teste após cada alteração |
Cobertura completa e validação minuciosa |
Muito demorado e caro |
Sistemas pequenos e testes de linha de base |
|
Regressão seletiva |
Os testes afetaram apenas os componentes baseados em alterações de código. |
Feedback eficiente e mais rápido |
Precisa de um mapeamento preciso das dependências |
Sistemas modulares e lançamentos frequentes |
|
Regressão priorizada |
Faz testes classificados por impacto nos negócios |
Foca primeiro nas funcionalidades essenciais |
Pode pular áreas menos importantes, mas que ainda são relevantes. |
Ciclos de testes com prazo limitado |
|
Regressão automatizada |
É executado automaticamente via CI/CD após o commit do código. |
Rápido, escalável, repetível |
Precisa de configuração e manutenção |
Projetos grandes ou que mudam rápido |
Criar um conjunto de regressão é um investimento contínuo na qualidade do software.
Com o tempo, ele se torna um dos ativos mais valiosos no seu processo de desenvolvimento.
A imagem abaixo mostra as etapas envolvidas na criação e manutenção de um conjunto de regressão.
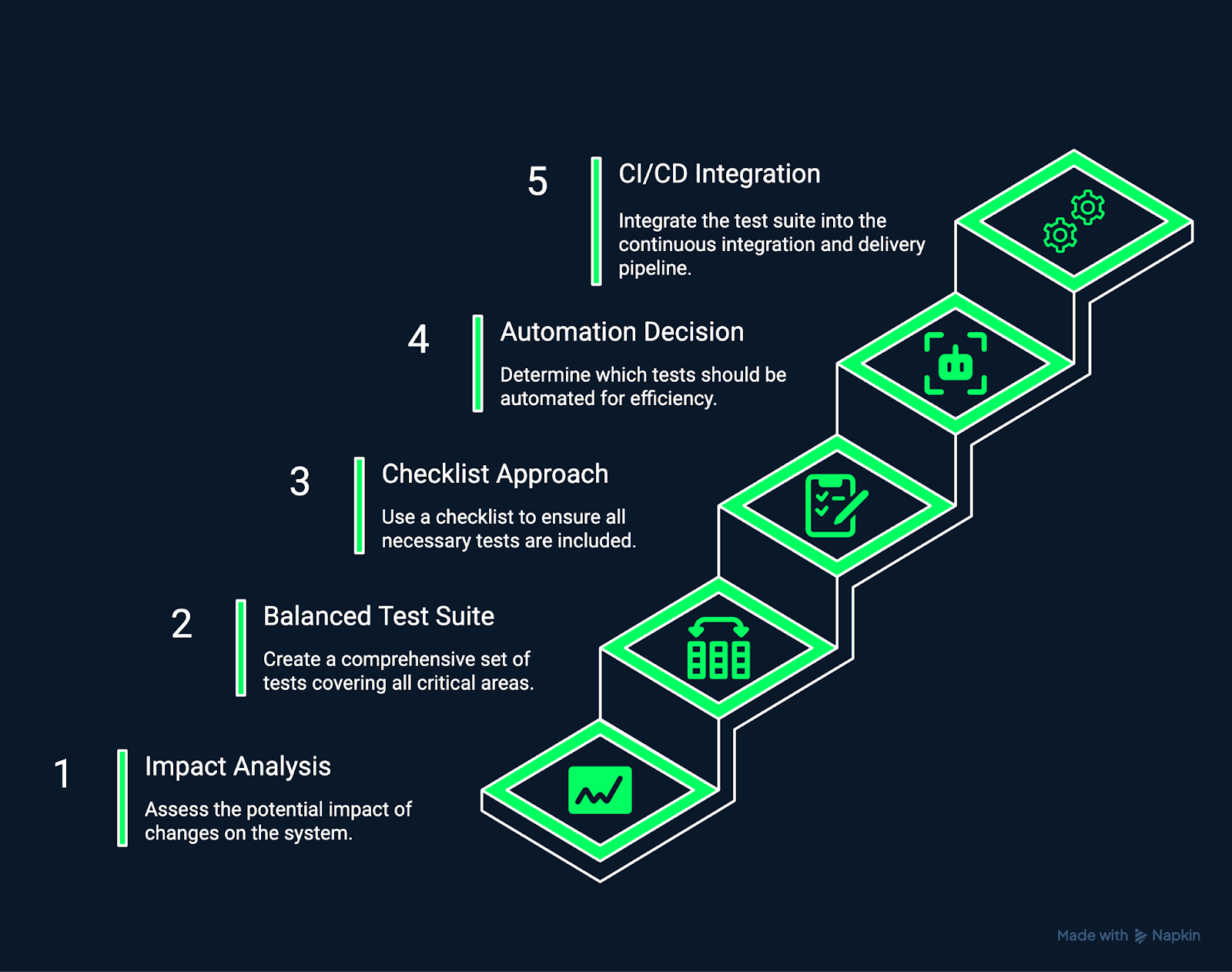
Criando e mantendo um conjunto de regressão. Imagem criada pelo autor usando o Napkin AI.
Comece entendendo quais partes do sistema são afetadas por uma mudança.
É uma boa ideia usar ferramentas como analisadores de cobertura de código ou gráficos de dependência para ver quais testes devem ser executados de novo.
Priorize os módulos que interagem com o código modificado, compartilham estruturas de dados comuns ou que já falharam antes depois de atualizações parecidas.
Crie um conjunto de testes que cubra completamente os fluxos de trabalho críticos da empresa, os processos de dados essenciais e as jornadas comuns dos usuários.
Certifique-se de que cada teste tenha um objetivo e um escopo específicos e tente evitar redundâncias ou sobreposições.
Testes modulares e reutilizáveis facilitam a manutenção à medida que seu sistema evolui.
Uma lista de verificação estruturada ajuda a garantir a consistência e a integridade dos testes de regressão manuais e automatizados.
Isso reduz a supervisão, padroniza a execução e promove processos de garantia de qualidade repetíveis.
|
Passo |
Objetivo |
|
Defina as condições prévias |
Definir o estado do sistema e inserir dados |
|
Executar caso de teste |
Faça o teste em condições controladas. |
|
Confira os resultados |
Confira se o resultado esperado e os efeitos colaterais estão certinhos. |
|
Resultados recordes |
Aprovações, reprovações e quaisquer anomalias nos documentos |
Esse método traz estrutura,transparência e responsabilidade, o que é super útil quando a gente está integrando novos engenheiros de controle de qualidade.
Nem todos os testes devem ser automatizados.
Automatize testes estáveis, repetíveis e de alta frequência, incluindo aqueles que validam fluxos de trabalho essenciais ou áreas atualizadas com frequência.
Mantenha um manual de testes exploratórios e de usabilidade, já que o julgamento humano agrega valor.
|
Automatizar quando: |
Guarde o manual quando: |
|
Os cenários são repetitivos e estáveis |
Os cenários precisam de interpretação humana. |
|
Os dados de teste são previsíveis |
A experiência do usuário ou o comportamento da interface do usuário está sendo avaliado. |
|
Os testes são feitos com frequência por meio de CI/CD. |
São realizados testes únicos ou exploratórios. |
Integrar testes de regressão nos pipelines de CI/CD garante que todas as mudanças sejam verificadas automaticamente.
Configure as compilações para falharem se os testes de regressão detectarem novos problemas, gere relatórios para triagem imediata e aplique a filosofia de “testar cedo, testar sempre”.
Essa abordagem evita que as regressões se acumulem e permite uma verdadeira cultura de qualidade contínua.
|
Benefício da integração CI/CD |
Resultado |
|
Verificação automática após cada commit |
Detecção precoce de regressões |
|
Alerta de falha na compilação |
Triagem rápida de código problemático |
|
Ciclo contínuo de feedback |
Qualidade consistente em iterações rápidas |
Uma variedade de ferramentas modernas ajuda a fazer testes de regressão eficientes e escaláveis.
A ferramenta certa depende da tecnologia do seu projeto, dos objetivos de automação e do nível de maturidade da equipe.
Abaixo estão várias opções amplamente adotadas que simplificam e aceleram os fluxos de trabalho de regressão.
O Katalon Studio é uma plataforma completa de automação de testes que dá suporte a testes na web, API, dispositivos móveis e desktop.
Tem uma interface gráfica fácil de usar e recursos de scripting robustos. Então, isso é usado por equipes que estão mudando de testes de regressão manuais para automatizados.
O Katalon oferece testes integrados baseados em palavras-chave e dados, reconhecimento inteligente de objetos e painéis de relatórios detalhados.
Uma das maiores vantagens é a acessibilidade: quem não tem muita experiência em programação pode criar casos de teste complexos de forma visual, enquanto os usuários mais avançados podem personalizar o comportamento usando Groovy ou JavaScript.
A plataforma se integra perfeitamente com sistemas CI/CD, como Jenkins e GitLab, o que permite a execução automatizada de regressões em cada compilação.
O Cypress é uma estrutura de testes completa, rápida e fácil de usar para desenvolvedores, feita especialmente para aplicativos web modernos. Diferente das ferramentas tradicionais baseadas em Selenium, o Cypress roda direto no navegador, o que permite observar, controlar e depurar o comportamento da web em tempo real.
Essa arquitetura oferece feedback instantâneo, recarga em tempo real e execução de testes super confiável, sem aquela instabilidade que às vezes atrapalha a automação do navegador.
É ideal para equipes que já usam frameworks como React, Angular ou Vue, pois sua sintaxe baseada em JavaScript se encaixa naturalmente nos fluxos de trabalho de desenvolvimento front-end.
O Cypress também oferece ferramentas de depuração avançadas, espera automática e registros detalhados de testes com capturas de tela e vídeos, perfeitos para diagnosticar regressões rapidamente.
A Testsigma oferece uma plataforma moderna de automação de testes baseada em nuvem que usa processamento de linguagem natural (NLP) para escrever casos de teste em inglês simples.
Essa abordagem reduz bastante a barreira de entrada, o que permite que membros da equipe sem conhecimentos técnicos, como analistas de controle de qualidade ou proprietários de produtos, contribuam diretamente para o conjunto de testes de regressão.
Ele suporta testes na web, em dispositivos móveis, API e desktop em um ambiente unificado, ajudando as equipes ágeis a alcançar ampla cobertura sem grande sobrecarga de codificação.
O Testsigma também se adapta facilmente a diferentes navegadores, sistemas operacionais e dispositivos, o que é super útil para equipes que gerenciam vários destinos de implantação.
Ele se integra perfeitamente às ferramentas populares de DevOps e pipelines de CI/CD, oferecendo execução em tempo real, testes paralelos e manutenção de testes com ajuda de IA.
Além dessas plataformas principais, outras ferramentas especializadas podem ajudar nos fluxos de trabalho de testes de regressão.
O Selenium continua sendo uma opção fundamental de código aberto para automação de navegadores, principalmente para equipes que se sentem à vontade para gerenciar estruturas e scripts personalizados. O Playwright, desenvolvido pela Microsoft, oferece recursos parecidos, mas com execução mais rápida e suporte mais amplo para vários navegadores.
Para testes em dispositivos móveis, ferramentas como o Appium estendem a automação para as plataformas iOS e Android usando uma API unificada.
Essas ferramentas formam um ecossistema robusto para testes de regressão. Cada um deles dá suporte à integração com pipelines de CI/CD, sistemas de controle de versão e infraestrutura em nuvem.
O teste de regressão é importante, mas tem suas dificuldades.
À medida que os sistemas evoluem e os conjuntos de testes crescem, manter a velocidade, a confiabilidade e a precisão se torna cada vez mais complexo.
Entender os desafios comuns e como lidar com eles ajuda as equipes a manter práticas de regressão eficientes e de alto impacto ao longo do tempo.
A imagem abaixo mostra alguns dos desafios comuns nos testes de regressão.
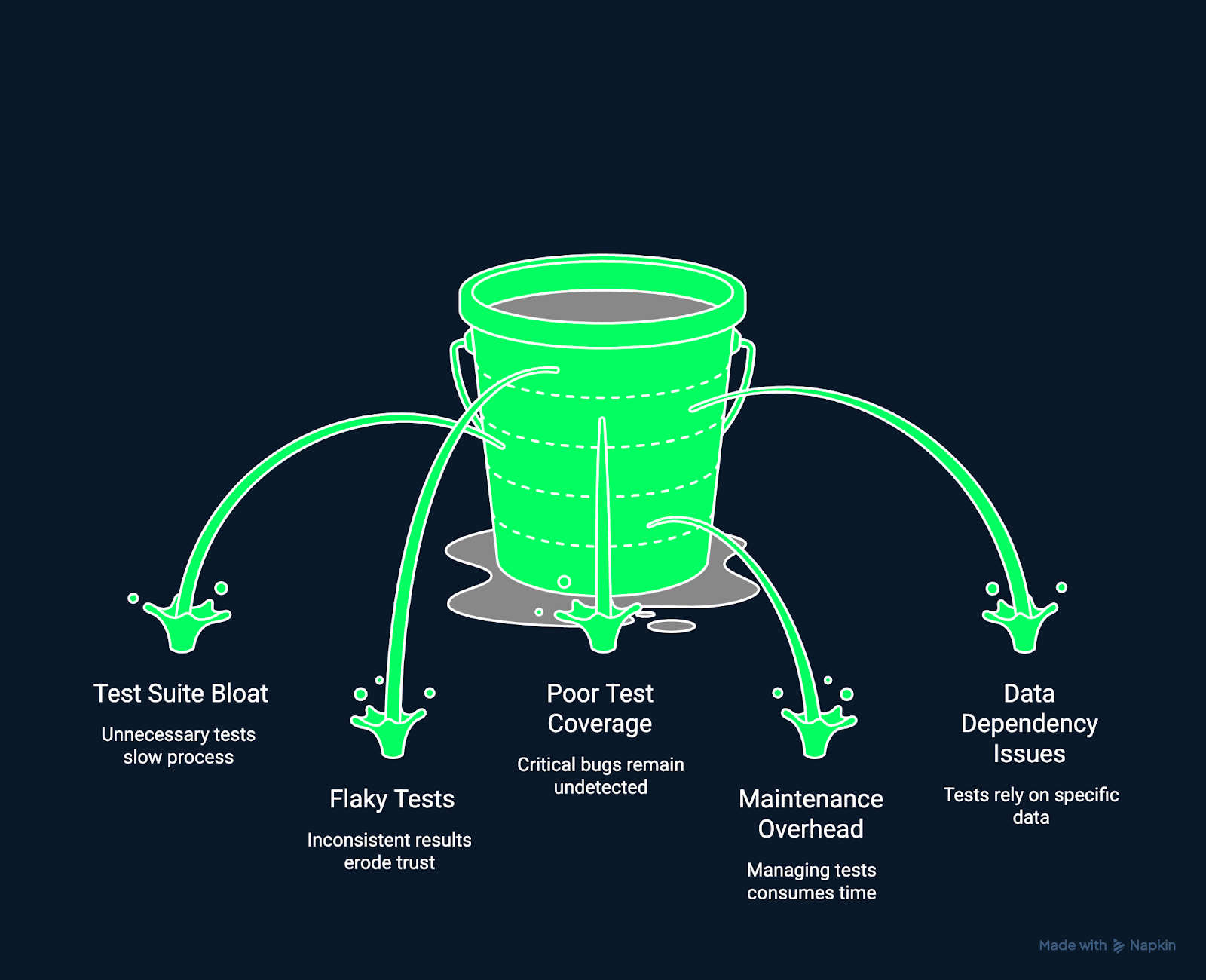
Desafios nos testes de regressão. Imagem criada pelo autor usando o Napkin AI.
Conforme os projetos vão avançando, os casos de teste podem se acumular mais rápido do que conseguimos revisar. Isso faz com que os conjuntos fiquem cheios de coisas desnecessárias, demorem mais para rodar e tenham testes que já não servem mais ou estão desatualizados. Conjuntos de testes muito grandes atrasam os ciclos de feedback e diminuem a eficiência dos testes.
A solução é fazer auditorias e refatorações regulares do seu conjunto de testes. Tire os testes que já não servem ou que estão repetidos, junte os cenários que se misturam e guarde os casos antigos que já não valem mais.
Testes que falham aleatoriamente podem frustrar os desenvolvedores. Testes instáveis, aqueles que passam ou falham de forma inconsistente, podem surgir de operações assíncronas ou ambientes instáveis. Elas diminuem a confiança no seu sistema de testes e escondem as regressões reais.
A solução é estabilizar os ambientes de teste, usar dados simulados em vez de chamadas reais e adicionar esperas explícitas ou sincronização quando necessário. Programa e deixe de lado os testes instáveis até que sejam corrigidos, para manter a confiança nos resultados da automação.
Mesmo com testes extensivos, os caminhos críticos podem permanecer sem teste devido à pressão do tempo ou à falta de clareza sobre a responsabilidade. Uma cobertura insuficiente permite que regressões passem despercebidas.
A solução é usar ferramentas de cobertura de código e análise de testes para identificar áreas não testadas. Concentre-se primeiro em cobrir os módulos de alto risco e alto impacto e garanta que os novos recursos incluam cobertura de teste de regressão desde o início.
Os testes de regressão automatizados podem ficar meio frágeis, quebrando mesmo depois de pequenas atualizações na interface do usuário ou na API. Os altos custos de manutenção desestimulam os testes contínuos e atrasam a entrega.
A solução é criar testes modulares e reutilizáveis e usar localizadores de elementos robustos ou contratos de API. Coloque camadas de abstração entre os testes e a lógica da aplicação para minimizar as reescritas depois das atualizações.
Testes que dependem de fontes de dados ativas ou mutáveis podem produzir resultados inconsistentes, o que dificulta a distinção entre falhas reais e ruído ambiental.
A solução é usar dados de teste controlados ou serviços simulados para garantir resultados previsíveis e reproduzíveis. Versione e documente seus dados de teste para garantir a consistência entre os ambientes.
|
Desafio |
Descrição |
Estratégia de mitigação |
|
Conjunto de testes inchado |
Os casos de teste vão se acumulando com o tempo, deixando a execução mais lenta. |
Refaça e tire os testes que não servem mais de vez em quando. |
|
Testes instáveis |
Os testes falham de vez em quando por causa de sincronização, dependências ou inconsistências no ambiente. |
Refaça e tire os testes que não servem mais de vez em quando. |
|
Cobertura de teste insuficiente |
Alguns caminhos críticos não são testados por falta de atenção ou falta de tempo. |
Use ferramentas de cobertura de código para ver onde tem falhas |
|
Custos gerais de manutenção |
Os testes automatizados param de funcionar depois de pequenas mudanças na interface do usuário ou na API. |
Use design de teste modular e seletores robustos |
|
Problemas de dependência de dados |
Os testes dependem de fontes de dados dinâmicas ou em tempo real. |
Use fixtures, mocks ou conjuntos de dados sintéticos |
Se você quiser entender melhor sobre validação estatística e testes analíticos, dá uma olhada no nosso curso Teste de Hipóteses em Python.
Testes de regressão robustos envolvem a execução de testes, bem como a criação de uma estrutura sustentável para garantir a qualidade contínua.
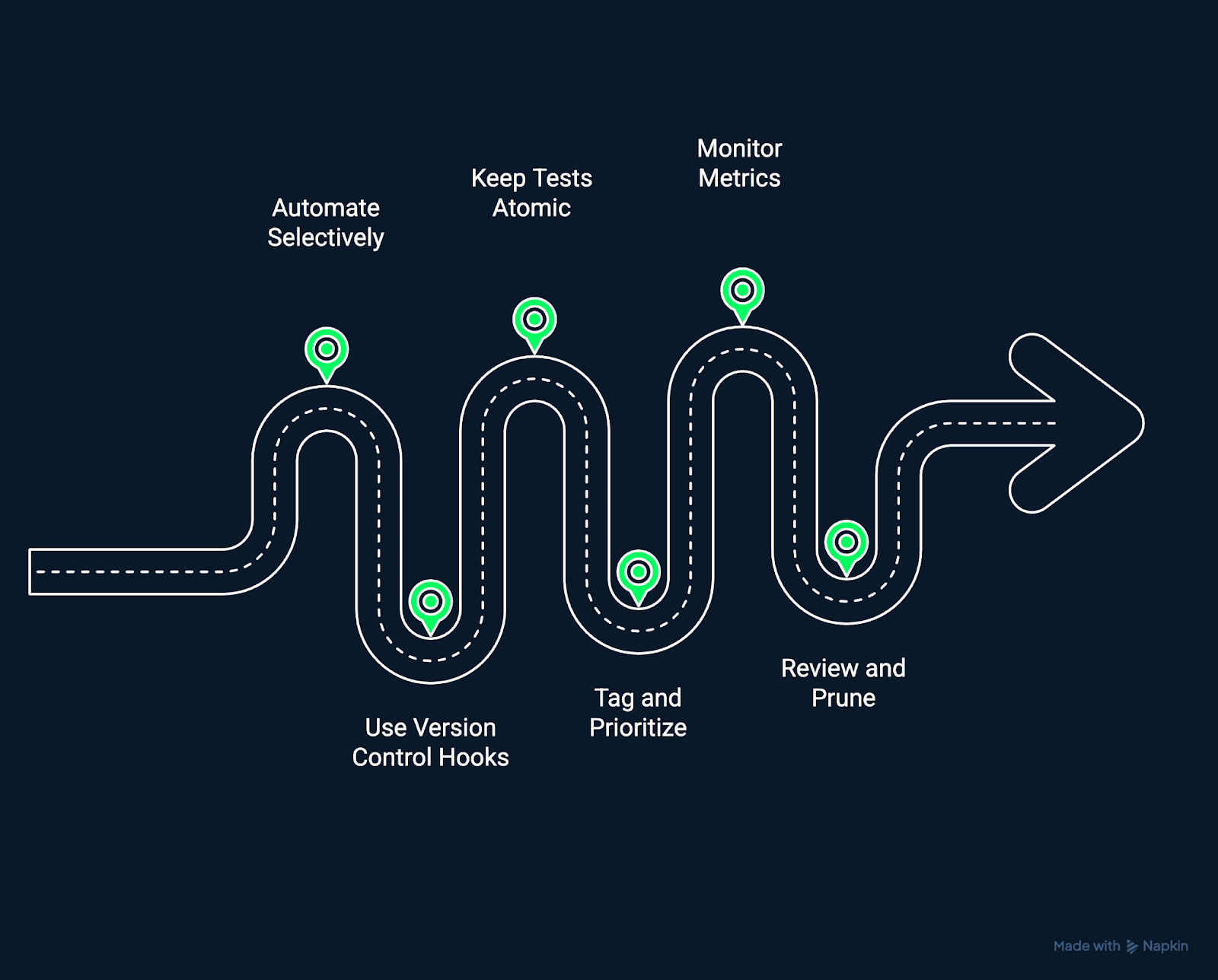
Melhores práticas para testes de regressão eficazes. Imagem criada pelo autor usando o Napkin AI.
A automação aumenta o poder dos testes, mas nem todos os testes precisam ser automatizados. Comece automatizando testes estáveis e de alto valor que validam os fluxos de trabalho principais. Evite automatizar áreas voláteis até que sua funcionalidade se estabilize para reduzir os custos de manutenção.
Integre os testes de regressão diretamente no seu sistema de controle de versão. Faça testes automáticos em pull requests ou mesclagens pra detectar regressões antes que as mudanças sejam mescladas nos ramos principais. Isso cria uma abordagem proativa e preventiva de testes.
Cada teste deve validar um comportamento isoladamente. Os testes atômicos facilitam o diagnóstico de falhas e reduzem os problemas em cascata quando um componente falha. Testes independentes também podem ser feitos ao mesmo tempo, acelerando os ciclos de feedback de CI/CD.
Marque os testes com base na importância, como “fumaça”, “regressão” ou “desempenho”. Faça testes de alto impacto em cada commit, enquanto conjuntos mais amplos podem ser executados todas as noites ou antes do lançamento. A priorização garante que os testes estejam alinhados com as restrições de tempo e os riscos comerciais.
Quantifique o desempenho dos seus testes ao longo do tempo. Programa métricas como taxas de falha, tempo de execução e tendências de cobertura para identificar gargalos e oportunidades de melhoria. A medição contínua mantém seus testes de regressão ágeis e confiáveis.
Os conjuntos de testes de regressão são sistemas vivos. Com o tempo, tire os testes que já não servem mais, atualize as expectativas e ajuste as prioridades. Um conjunto de testes enxuto e relevante oferece insights mais rápidos e precisos, com menos ruído.
|
Prática |
Objetivo |
Exemplo ou resultado |
|
Automatize logo, mas com cuidado |
Concentre seus esforços em testes estáveis e de alto valor |
Reduzir os custos de manutenção |
|
Use ganchos de controle de versão |
Detecte regressões antes de juntar o código |
Executar testes automaticamente em solicitações pull |
|
Mantenha os testes atômicos e independentes |
Simplifique a depuração e habilite execuções paralelas |
Cada teste verifica um comportamento específico. |
|
Use marcação de teste e priorização |
Alocar recursos de teste de forma eficiente |
Testes críticos são feitos em cada commit |
|
Monitorar métricas de teste |
Programa a saúde e a eficiência do pacote |
Identifique áreas lentas ou instáveis |
|
Revise e apare regularmente |
Mantenha o pacote rápido e relevante |
Tira os casos que já não servem ou que são desnecessários. |
Essas práticas juntas são a base de umacultura saudávelde testes de regressão, que prioriza velocidade, confiabilidade e manutenção a longo prazo.
Para melhorar sua habilidade de escrever código fácil de manter e testar , dá uma olhada no nosso curso Princípios de Engenharia de Software em Python.
Lembre-se de que, à medida que os sistemas de software evoluem e se tornam mais complexos, os testes de regressão se tornam uma proteção essencial para manter a estabilidade e a confiança do usuário. Toda alteração no código, por menor que seja, traz um risco potencial. Uma estratégia forte de testes de regressão pode te ajudar a lançar atualizações com confiança e agir rápido sem prejudicar o software que seus usuários dependem.
Para continuar a desenvolver sua experiência em testes de software, confira nosso curso Introdução aos Testes em Python. Se você quer integrar estratégias de teste robustas em pipelines de implantação modernos, dê uma olhada no nosso curso CI/CD para machine learning.
Aprenda com o DataCamp
Programa
Programa
Curso
Tutorial
Eladio Montero Porras
Tutorial
Zoumana Keita
Tutorial
Vidhi Chugh
Tutorial
DataCamp Team
Tutorial
Avinash Navlani

