
Track
Associate Data Scientist in Python
90 hr
Over the years, I have learned that even the smallest code change can have unexpected consequences. What might initially seem like a small change can quietly break something that was working perfectly.
This is why regression testing is important. It is essentially a safeguard that ensures progress does not come at the expense of stability.
In my experience with data-driven projects, where models, APIs, and pipelines evolve constantly, regression testing has been essential for maintaining consistent, reliable outputs.
Without it, even small adjustments like tweaking a transformation function or updating a package can trigger unexpected behavior that’s hard to trace.
If you are new to Python or want to refresh your coding fundamentals before diving deeper into testing, have a look at our Python Programming skill track.
In short, regression testing means re-testing existing functionality after code changes to confirm nothing has ‘regressed’ to a broken state.
Even though the word ‘regression’ might sound mathematical, in testing, it actually means ‘a step backwards’.
Whenever you modify code (which could include fixing a bug or adding a feature), there is a chance the new change could break previously working components, which is why we need regression testing.
Regression testing answers the following crucial question:
After this change, does everything that worked before still work now?
Unlike unit testing, which validates isolated components, or integration testing, which checks how modules work together, regression testing takes a broader, long-term view.
It ensures that your software remains stable and consistent release after release, even as it evolves.
Regression testing examples. Image by Author using Napkin AI.
For example:
In continuous development environments (especially Agile and DevOps), regression testing acts as a safety net that enables you to iterate rapidly without sacrificing stability.
It supports the confidence needed for frequent deployments, automated workflows, and continuous integration practices.
Regression testing is one of the most reliable ways to ensure your software quality remains consistent as your system evolves. It helps you detect and prevent these ripple effects early, which in turn preserves stability and user trust.
New code often brings unintended side effects. A simple refactor or dependency upgrade might break functionality in distant modules.
Regression testing helps you identify such issues before they affect production or users. Automated regression suites can run after each code push, which can highlight conflicts between new and legacy logic. This early feedback saves you time, reduces debugging overhead, and maintains development confidence.
In fast-moving Agile or DevOps teams, automated regression acts as a guardrail that lets developers innovate without fear of breaking established features.
|
Benefit |
Description |
Example |
|
Early detection |
Identifies bugs soon after new commits |
A new API route breaks an existing client request |
|
Faster debugging |
Pinpoints exactly where new logic fails |
CI reports link failed tests to specific modules |
|
Developer confidence |
Encourages frequent, safe releases |
Teams deploy continuously without manual checks |
One of the most frustrating issues in software maintenance is seeing an old bug return.
Regression tests act as permanent safeguards (i.e., once a bug is fixed, its corresponding test ensures it stays fixed and does not resurface).
Over time, this creates a safety net based on your project’s own bug history.
Embedding this practice into your workflow means that your testing suite validates not only new functionality but also every fix that has been previously implemented.
|
Before regression tests |
After regression tests |
|
Old bugs reappear unpredictably |
Fixed issues stay permanently verified |
|
Bug fixes rely on memory or documentation |
Tests automatically confirm previous fixes |
|
QA teams repeat manual checks |
Automated guards prevent recurrence |
Reliability is non-negotiable, especially from the user’s perspective. Features that work one day and fail the next undermine trust and user satisfaction.
Regression testing ensures a consistent experience across updates, which reinforces confidence in your product.
In data-driven applications, this reliability means maintaining consistent results and predictable behaviors, even as models, data sources, and APIs evolve.
|
Application area |
What regression testing protects |
|
Dashboards |
Ensures visualizations render correctly after backend or data schema updates |
|
Model APIs |
Verifies that model predictions remain stable and reproducible |
|
Data Pipelines |
Confirms data exports preserve schema and format consistency |
Regression testing is also a critical part of risk management. Without it, unexpected bugs can slip through late in the release cycle, which could cause outages or costly rollbacks.
Verifying stability with each iteration can help your team release confidently, knowing that changes have not compromised functionality.
|
With regression testing |
Without regression testing |
|
Predictable, low-risk releases |
Frequent last-minute bugs and rollbacks |
|
Confident CI/CD pipelines |
Hesitant deployments, manual QA bottlenecks |
|
Continuous quality assurance |
Post-deployment firefighting |
Regression testing isn’t one-size-fits-all. The right approach depends on factors such as codebase size, change frequency, and business impact.
Each of these next methods balances speed, coverage, and resource cost differently.
The simplest form of regression testing involves running every existing test after a change.
Even though it ensures nothing is missed, it becomes increasingly impractical as systems grow.
Therefore, this approach is often used early in a project’s lifecycle or when validating a major refactor.
Selective regression targets only the areas directly affected by recent changes.
It uses impact analysis to determine dependencies and limit testing scope.
For example, if a data transformation module changes, related tests for authentication or UI rendering may not need to be rerun.
This approach balances accuracy with speed and relies on good dependency tracking.
In large systems, time and resources rarely allow for complete regression coverage.
Prioritized regression testing ranks test cases by importance and risk level, which ensures that critical paths (such as payments or authentication) are verified first.
Lower-priority tests can run later or asynchronously.
The table below outlines typical priority levels, with examples of areas covered and their corresponding testing focus.
|
Priority level |
Example area |
Testing focus |
|
High |
Payment processing, authentication |
Must never fail and always tested first |
|
Medium |
Dashboard visuals, email notifications |
Should function consistently |
|
Low |
Layout adjustments, tooltips |
Cosmetic and less critical during quick cycles |
Manual regression testing quickly becomes unsustainable as projects scale.
Automation, on the other hand, turns regression testing from a slow step into a way to work faster and with more confidence.
Automated suites run on every build or pull request, deliver instant feedback, and integrate with CI tools like Jenkins, GitHub Actions, or GitLab CI/CD.
They enable continuous verification across environments, which is an essential capability for Agile and DevOps teams aiming to ‘move fast without breaking things’.
|
Automation benefit |
Impact on development |
|
Continuous feedback |
Faster identification of breaking changes |
|
Consistent execution |
Eliminates human error in repetitive tests |
|
Scalability |
Tests run across environments simultaneously |
|
Integration-ready |
Fits directly into CI/CD workflows |
The table below provides a quick overview of the main regression testing techniques discussed above.
|
Type |
Description |
Pros |
Cons |
Best for |
|
Retest-all |
Runs all test cases after every change |
Full coverage and thorough validation |
Very time-consuming and high cost |
Small systems and baseline testing |
|
Selective regression |
Tests only affected components based on code changes |
Efficient and faster feedback |
Requires accurate dependency mapping |
Modular systems and frequent releases |
|
Prioritized regression |
Executes tests ranked by business impact |
Focuses on critical functionality first |
May skip less critical but relevant areas |
Time-limited testing cycles |
|
Automated regression |
Runs automatically via CI/CD after code commits |
Fast, scalable, repeatable |
Requires setup and maintenance |
Large or fast-evolving projects |
Creating a regression suite is an ongoing investment in software quality.
Over time, it becomes one of the most valuable assets in your development process.
The image below demonstrates the steps involved in building and maintaining a regression suite.
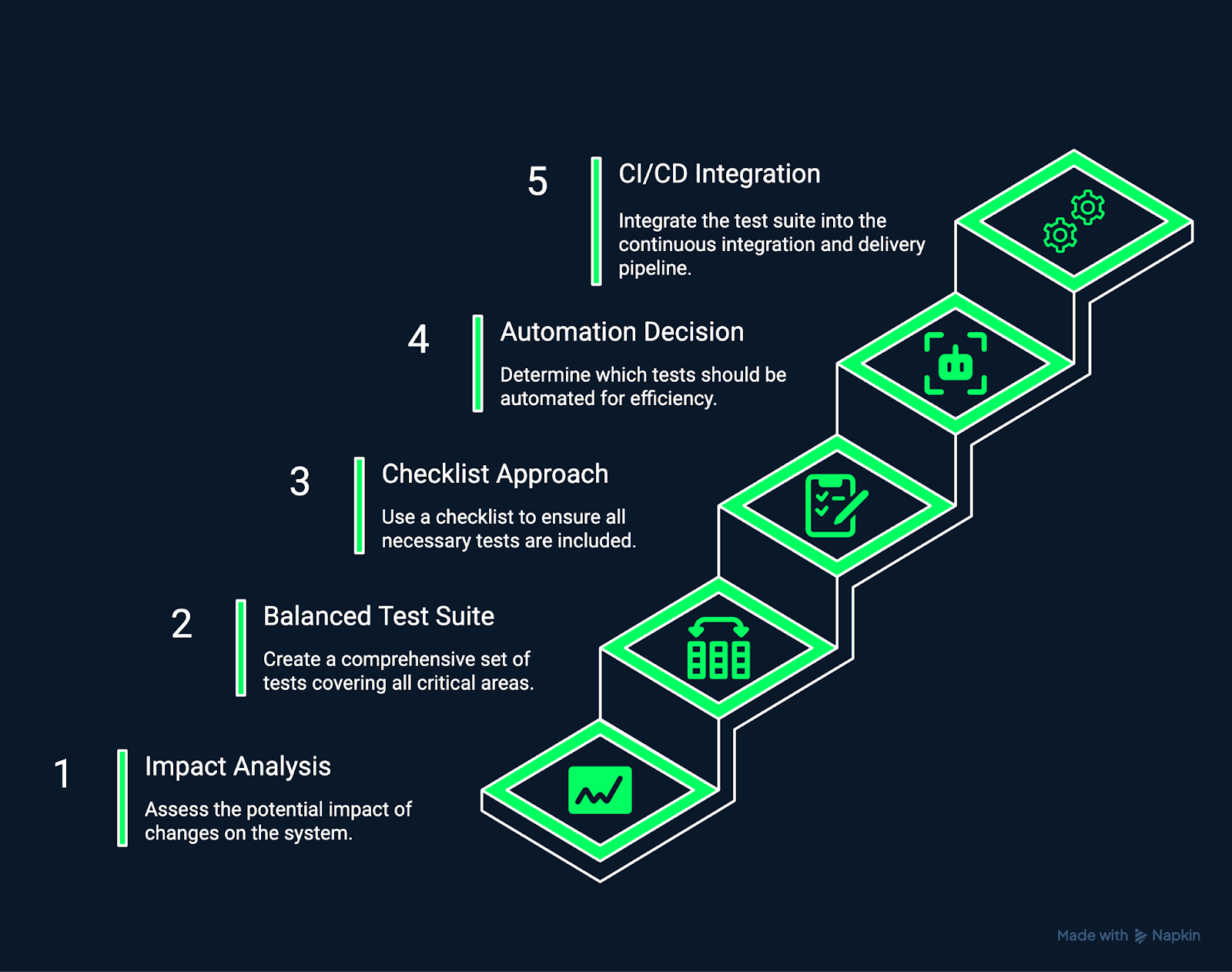
Building and maintaining a regression suite. Image by Author Using Napkin AI.
Begin by understanding which parts of the system are affected by a change.
It is a good idea to use tools such as code coverage analyzers or dependency graphs to determine which tests to rerun.
Prioritize modules that interact with modified code, share common data structures, or have previously failed after similar updates.
Develop a test suite that thoroughly covers critical business workflows, essential data processes, and common user journeys.
Make sure that each test has a specific purpose and scope, and try to avoid redundancy or overlap.
Modular, reusable tests make maintenance easier as your system evolves.
A structured checklist helps ensure consistency and completeness across both manual and automated regression testing.
It reduces oversight, standardizes execution, and promotes repeatable quality assurance processes.
|
Step |
Purpose |
|
Define preconditions |
Establish system state and input data |
|
Execute test case |
Run test under controlled conditions |
|
Verify outcomes |
Validate both expected output and side effects |
|
Record results |
Document passes, failures, and any anomalies |
This method provides structure, transparency, and accountability, particularly useful when onboarding new QA engineers.
Not all tests should be automated.
Automate stable, repeatable, and high-frequency tests, which include those that validate mission-critical workflows or frequently updated areas.
Keep an exploratory and usability testing manual, since human judgment adds value.
|
Automate when: |
Keep manual when: |
|
Scenarios are repetitive and stable |
Scenarios require human interpretation |
|
Test data is predictable |
User experience or UI behavior is being evaluated |
|
Tests run frequently via CI/CD |
One-time or exploratory tests are performed |
Integrating regression testing into CI/CD pipelines ensures every change is verified automatically.
Configure builds to fail if regression tests detect new issues, generate reports for immediate triage, and enforce a “test early, test often” philosophy.
This approach prevents regressions from accumulating and enables a true culture of continuous quality.
|
CI/CD integration benefit |
Outcome |
|
Automated verification after every commit |
Early detection of regressions |
|
Build failure alerts |
Quick triage of problematic code |
|
Continuous feedback loop |
Consistent quality across rapid iterations |
A range of modern tools supports efficient, scalable regression testing.
The right tool depends on your project’s technology stack, automation goals, and team maturity level.
Below are several widely adopted options that simplify and accelerate regression workflows.
Katalon Studio is a comprehensive test automation platform that supports web, API, mobile, and desktop testing.
It has a user-friendly graphical interface and robust scripting capabilities. Therefore, this is used by teams moving from manual to automated regression testing.
Katalon offers built-in keyword-driven and data-driven testing, smart object recognition, and detailed reporting dashboards.
One of its biggest advantages is accessibility: testers without deep programming expertise can design complex test cases visually, while advanced users can customize behavior using Groovy or JavaScript.
The platform integrates seamlessly with CI/CD systems such as Jenkins and GitLab, which enables automated regression runs on every build.
Cypress is a fast, developer-friendly end-to-end testing framework purpose-built for modern web applications. Unlike traditional Selenium-based tools, Cypress runs directly inside the browser, which allows it to observe, control, and debug web behavior in real time.
This architecture delivers instant feedback, live reloading, and highly reliable test execution without the flakiness that sometimes plagues browser automation.
It is ideal for teams already using frameworks like React, Angular, or Vue as its JavaScript-based syntax fits naturally into front-end development workflows.
Cypress also provides rich debugging tools, automatic waiting, and detailed test logs with screenshots and videos, perfect for diagnosing regressions quickly.
Testsigma offers a modern, cloud-based test automation platform that uses natural language processing (NLP) to write test cases in plain English.
This approach drastically reduces the barrier to entry, which allows non-technical team members, such as QA analysts or product owners, to contribute directly to the regression test suite.
It supports web, mobile, API, and desktop testing within a unified environment, helping Agile teams achieve broad coverage without heavy coding overhead.
Testsigma also scales easily across browsers, operating systems, and devices, particularly valuable for teams managing multiple deployment targets.
It integrates seamlessly with popular DevOps tools and CI/CD pipelines, providing real-time execution, parallel testing, and AI-assisted test maintenance.
Beyond these leading platforms, other specialized tools can complement regression testing workflows.
Selenium remains a foundational open-source option for browser automation, particularly for teams comfortable managing frameworks and custom scripts. Playwright, developed by Microsoft, provides similar capabilities with faster execution and broader cross-browser support.
For mobile testing, tools like Appium extend automation to both iOS and Android platforms using a unified API.
These tools form a robust ecosystem for regression testing. Each supports integration with CI/CD pipelines, version control systems, and cloud infrastructure.
Regression testing is important, but it has its difficulties.
As systems evolve and test suites grow, maintaining speed, reliability, and accuracy becomes increasingly complex.
Understanding common challenges and how to address them helps teams sustain efficient, high-impact regression practices over time.
The image below shows some of the common challenges in regression testing.
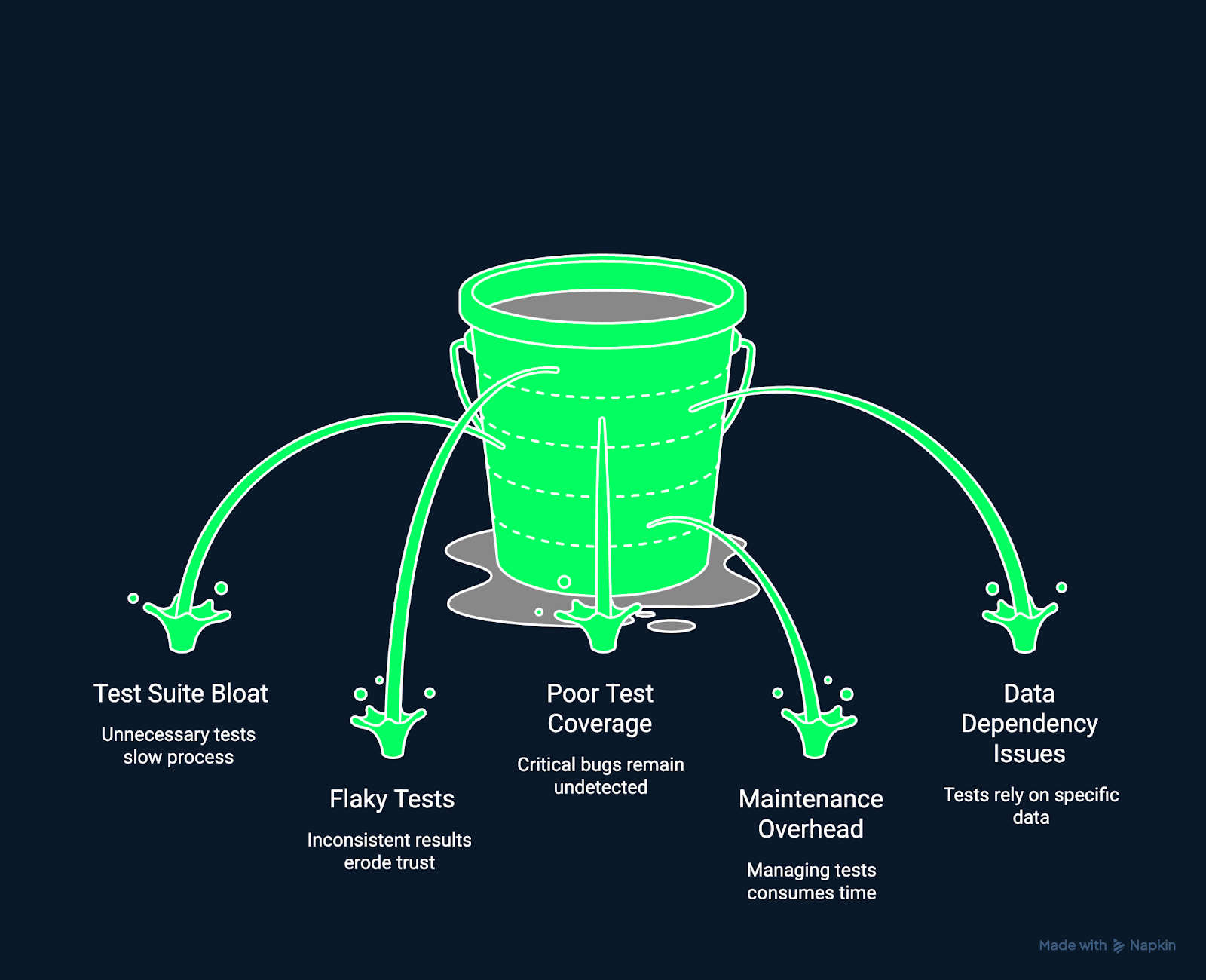
Challenges in regression testing. Image by Author Using Napkin AI.
As projects evolve, test cases can accumulate faster than they are reviewed. This leads to bloated suites that take longer to execute and contain redundant or outdated tests. Overly large test suites slow down feedback loops and reduce testing efficiency.
The solution is to regularly audit and refactor your test suite. Remove obsolete or duplicate tests, consolidate overlapping scenarios, and archive historical cases that no longer apply.
Tests that fail randomly can frustrate developers. Flaky tests, those that pass or fail inconsistently, can arise from asynchronous operations or unstable environments. They reduce trust in your testing system and obscure real regressions.
The solution is to stabilize test environments, use mock data instead of live calls, and add explicit waits or synchronization where necessary. Track and set aside flaky tests until they are fixed to preserve confidence in automation results.
Even with extensive testing, critical paths can remain untested due to time pressure or unclear ownership. Insufficient coverage allows regressions to slip through unnoticed.
The solution is to use code coverage tools and test analytics to identify untested areas. Focus on covering high-risk, high-impact modules first, and ensure new features include regression test coverage from the start.
Automated regression tests can become fragile, breaking after even small UI or API updates. High maintenance costs discourage continuous testing and slow down delivery.
The solution is to design modular, reusable tests and use robust element locators or API contracts. Implement abstraction layers between tests and application logic to minimize rewrites after updates.
Tests that rely on live or mutable data sources can produce inconsistent results, which makes it hard to distinguish between real failures and environmental noise.
The solution is to use controlled test data or mock services to ensure predictable, reproducible outcomes. Version and document your test data for consistency across environments.
|
Challenge |
Description |
Mitigation strategy |
|
Test suite bloat |
Test cases accumulate over time, slowing down execution |
Regularly refactor and remove redundant tests |
|
Flaky tests |
Tests fail intermittently due to timing, dependencies, or environment inconsistencies |
Regularly refactor and remove redundant tests |
|
Poor test coverage |
Some critical paths aren’t tested due to oversight or lack of time |
Use code coverage tools to identify gaps |
|
Maintenance overhead |
Automated tests break after minor UI or API changes |
Use modular test design and robust selectors |
|
Data dependency issues |
Tests rely on changing or live data sources |
Use fixtures, mocks, or synthetic datasets |
If you would like to strengthen your understanding of statistical validation and analytical testing, try our Hypothesis Testing in Python course.
Strong regression testing is about running tests as well as building a sustainable framework for continuous quality.
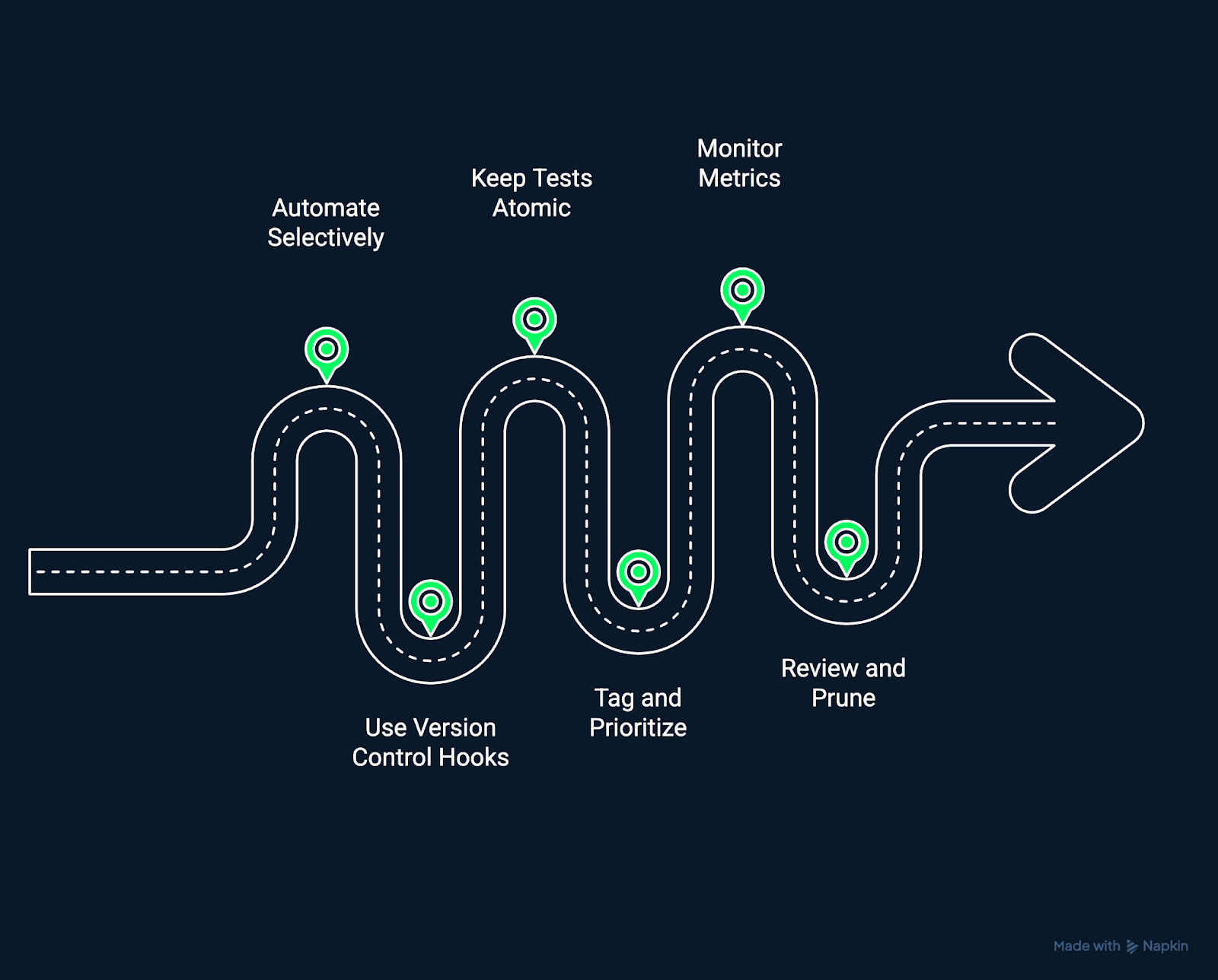
Best practices for effective regression testing. Image by Author Using Napkin AI.
Automation amplifies testing power, but not all tests need to be automated. Start by automating stable, high-value tests that validate core workflows. Avoid automating volatile areas until their functionality stabilizes to reduce maintenance overhead.
Integrate regression testing directly into your version control system. Trigger automated test runs on pull requests or merges to detect regressions before changes are merged into main branches. This creates a proactive, preventive testing approach.
Each test should validate one behavior in isolation. Atomic tests make failures easier to diagnose and reduce cascading issues when one component fails. Independent tests can also run in parallel, speeding up CI/CD feedback loops.
Tag tests based on criticality, such as ‘smoke’, regression’, or ‘performance’. Run high-impact tests on every commit, while broader suites can run nightly or before release. Prioritization ensures that testing aligns with time constraints and business risk.
Quantify your testing performance over time. Track metrics such as failure rates, execution duration, and coverage trends to identify bottlenecks and improvement opportunities. Continuous measurement keeps your regression testing agile and accountable.
Regression test suites are living systems. Over time, remove obsolete tests, update expectations, and adjust priorities. A lean, relevant test suite delivers faster, more accurate insights with less noise.
|
Practice |
Purpose |
Example or outcome |
|
Automate early, but selectively |
Focus effort on stable, high-value tests |
Reduce maintenance overhead |
|
Use version control hooks |
Detect regressions before merging code |
Run tests automatically on pull requests |
|
Keep tests atomic and independent |
Simplify debugging and enable parallel runs |
Each test validates one specific behavior |
|
Use test tagging and prioritization |
Allocate testing resources efficiently |
Critical tests run on every commit |
|
Monitor test metrics |
Track health and efficiency of the suite |
Identify slow or flaky areas |
|
Regularly review and prune |
Keep the suite fast and relevant |
Remove obsolete or redundant cases |
These practices combined form the foundation of a healthy regression testing culture, one that prioritizes speed, reliability, and long-term maintainability.
To strengthen your ability to write maintainable, testable code, check out our Software Engineering Principles in Python course.
Remember that as software systems evolve and grow in complexity, regression testing becomes an essential safeguard for maintaining stability and user trust. Every code change, no matter how small, introduces potential risk. A strong regression testing strategy can help you deliver updates confidently and move fast without breaking the software your users rely on.
To continue building your expertise in software testing, explore our Introduction to Testing in Python course. If you are looking to integrate robust testing strategies into modern deployment pipelines, have a look at our CI/CD for Machine Learning course.
Learn with DataCamp
Track
Track
Course
blog
Don Kaluarachchi
15 min
Tutorial
Austin Chia
Tutorial
Zoumana Keita
Tutorial
Mark Pedigo
Tutorial
Josef Waples
Tutorial
Josef Waples
