
programa
Científico de datos asociado en Python
90 h
A lo largo de los años, he aprendido que incluso el más mínimo cambio en el código puede tener consecuencias inesperadas. Lo que en un principio puede parecer un pequeño cambio puede romper silenciosamente algo que funcionaba perfectamente.
Por eso son importantes las pruebas de regresión. Se trata, en esencia, de una salvaguarda que garantiza que el progreso no se produzca a expensas de la estabilidad.
En mi experiencia con proyectos basados en datos, en los que los modelos, las API y los procesos evolucionan constantemente, las pruebas de regresión han sido esenciales para mantener resultados coherentes y fiables.
Sin él, incluso pequeños ajustes como modificar una función de transformación o actualizar un paquete pueden provocar un comportamiento inesperado que es difícil de rastrear.
Si eres nuevo en Python o deseas refrescar tus conocimientos básicos de programación antes de profundizar en las pruebas, echaun vistazo a nuestroprograma de programación en Python.
En resumen, las pruebas de regresión consisten en volver a probar las funcionalidades existentes tras realizar cambios en el código para confirmar que nada ha «regresado» a un estado defectuoso.
Aunque la palabra «regresión» pueda parecer matemática, en el ámbito de las pruebas, en realidad significa «un paso atrás».
Cada vez que modificas el código (ya sea para corregir un error o añadir una función), existe la posibilidad de que el nuevo cambio afecte al funcionamiento de componentes que antes funcionaban correctamente, por lo que es necesario realizar pruebas de regresión.
Las pruebas de regresión responden a la siguiente pregunta crucial:
Tras este cambio, ¿todo lo que funcionaba antes sigue funcionando ahora?
A diferencia de las pruebas unitarias, que validan componentes aislados, o las pruebas de integración, que comprueban cómo funcionan los módulos juntos, las pruebas de regresión adoptan una perspectiva más amplia y a largo plazo.
Garantiza que tu software se mantenga estable y coherente versión tras versión, incluso a medida que evoluciona.
Ejemplos de pruebas de regresión. Imagen creada por el autor con Napkin AI.
Por ejemplo:
En entornos de desarrollo continuo (especialmente Agile y DevOps), las pruebas de regresión actúan como una red de seguridad que te permite iterar rápidamente sin sacrificar la estabilidad.
Te brinda la confianza necesaria para realizar implementaciones frecuentes, flujos de trabajo automatizados y prácticas de integración continua.
Las pruebas de regresión son una de las formas más fiables de garantizar que la calidad de tu software se mantenga constante a medida que tu sistema evoluciona. Te ayuda a detectar y prevenir estos efectos dominó de forma temprana, lo que a su vez preserva la estabilidad y la confianza de los usuarios.
El nuevo código a menudo trae consigo efectos secundarios no deseados. Una simple refactorización o actualización de dependencias podría afectar la funcionalidad de módulos distantes.
Las pruebas de regresión te ayudan a identificar estos problemas antes de que afecten a la producción o a los usuarios. Las suites de regresión automatizadas pueden ejecutarse después de cada envío de código, lo que puede poner de relieve los conflictos entre la lógica nueva y la antigua. Esta retroalimentación temprana te ahorra tiempo, reduce los gastos generales de depuración y mantiene la confianza en el desarrollo.
En equipos ágiles o DevOps que se mueven rápidamente, la regresión automatizada actúa como una barrera de protección que permite a los programadores innovar sin temor a romper las funciones establecidas.
|
Beneficio |
Descripción |
Ejemplo |
|
Detección precoz |
Identifica errores poco después de nuevas confirmaciones. |
Una nueva ruta API interrumpe una solicitud de cliente existente. |
|
Depuración más rápida |
Identifica con exactitud dónde falla la nueva lógica. |
Los informes de CI relacionan las pruebas fallidas con módulos específicos. |
|
Confianza de los programadores |
Fomenta las liberaciones frecuentes y seguras. |
Los equipos realizan implementaciones de forma continua sin comprobaciones manuales. |
Uno de los problemas más frustrantes en el mantenimiento de software es ver cómo reaparece un antiguo error.
Las pruebas de regresión actúan como salvaguardias permanentes (es decir, una vez que se corrige un error, la prueba correspondiente garantiza que permanezca corregido y no vuelva a aparecer).
Con el tiempo, esto crea una red de seguridad basada en el historial de errores de tu propio proyecto.
Incorporar esta práctica en tu flujo de trabajo significa que tu conjunto de pruebas valida no solo las nuevas funcionalidades, sino también todas las correcciones que se han implementado anteriormente.
|
Antes de las pruebas de regresión |
Después de las pruebas de regresión |
|
Los antiguos errores reaparecen de forma impredecible. |
Los problemas solucionados permanecen verificados de forma permanente. |
|
Las correcciones de errores dependen de la memoria o la documentación. |
Las pruebas confirman automáticamente las correcciones anteriores. |
|
Los equipos de control de calidad repiten las comprobaciones manuales. |
Los guardias automatizados evitan que se repita |
La fiabilidad no es negociable, especialmente desde la perspectiva del usuario. Las funciones que funcionan un día y al siguiente fallan socavan la confianza y la satisfacción de los usuarios.
Las pruebas de regresión garantizan una experiencia coherente en todas las actualizaciones, lo que refuerza la confianza en tu producto.
En las aplicaciones basadas en datos, esta fiabilidad significa mantener resultados coherentes y comportamientos predecibles, incluso a medida que evolucionan los modelos, las fuentes de datos y las API.
|
Área de aplicación |
¿Qué protegen las pruebas de regresión? |
|
Paneles de control |
Garantiza que las visualizaciones se representen correctamente después de las actualizaciones del backend o del esquema de datos. |
|
API de modelos |
Verifica que las predicciones del modelo sigan siendo estables y reproducibles. |
|
Canales de datos |
Confirma que las exportaciones de datos conservan la coherencia del esquema y el formato. |
Las pruebas de regresión también son una parte fundamental de la gestión de riesgos. Sin él, pueden aparecer errores inesperados en las últimas fases del ciclo de lanzamiento, lo que podría provocar interrupciones del servicio o costosas reversiones.
Verificar la estabilidad con cada iteración puede ayudar a tu equipo a lanzar el producto con confianza, sabiendo que los cambios no han comprometido la funcionalidad.
|
Con pruebas de regresión |
Sin pruebas de regresión |
|
Lanzamientos predecibles y de bajo riesgo |
Errores y retrocesos frecuentes de última hora. |
|
Canales CI/CD fiables |
Implementaciones vacilantes, cuellos de botella en el control de calidad manual |
|
Garantía de calidad continua |
Extinción de incendios tras el despliegue |
Las pruebas de regresión no son válidas para todos los casos. El enfoque adecuado depende de factores como el tamaño del código base, la frecuencia de los cambios y el impacto en el negocio.
Cada uno de estos métodos equilibra de manera diferente la velocidad, la cobertura y el costo de los recursos.
La forma más sencilla de realizar pruebas de regresión consiste en ejecutar todas las pruebas existentes después de un cambio.
Aunque garantiza que no se pase nada por alto, se vuelve cada vez más poco práctico a medida que los sistemas crecen.
Por lo tanto, este enfoque se utiliza a menudo al principio del ciclo de vida de un proyecto o cuando se valida una refactorización importante.
La regresión selectiva se centra únicamente en las áreas directamente afectadas por los cambios recientes.
Utiliza el análisis de impacto para determinar las dependencias y limitar el alcance de las pruebas.
Por ejemplo, si cambia un módulo de transformación de datos, es posible que no sea necesario volver a ejecutar las pruebas relacionadas con la autenticación o la representación de la interfaz de usuario.
Este enfoque equilibra la precisión con la velocidad y se basa en un buen seguimiento de las dependencias.
En sistemas grandes, el tiempo y los recursos rara vez permiten una cobertura completa de la regresión.
Las pruebas de regresión priorizadas clasifican los casos de prueba por importancia y nivel de riesgo, lo que garantiza que las rutas críticas (como los pagos o la autenticación) se verifiquen en primer lugar.
Las pruebas de menor prioridad pueden ejecutarse más tarde o de forma asíncrona.
La siguiente tabla resumelos niveles de prioridad habituales, con ejemplos de las áreas cubiertas y el enfoque de las pruebas correspondiente.
|
Nivel de prioridad |
Área de ejemplo |
Enfoque de las pruebas |
|
Alto |
Procesamiento de pagos, autenticación |
Nunca debe fallar y siempre se debe probar primero. |
|
Medio |
Imágenes del panel de control, notificaciones por correo electrónico |
Debe funcionar de manera consistente. |
|
Bajo |
Ajustes de diseño, información sobre herramientas |
Cosmético y menos crítico durante ciclos rápidos. |
Las pruebas de regresión manuales se vuelven rápidamente insostenibles a medida que los proyectos crecen.
Por otro lado, la automatización convierte las pruebas de regresión, que antes eran un paso lento, en una forma de trabajar más rápido y con mayor confianza.
Las suites automatizadas se ejecutan en cada compilación o solicitud de extracción, proporcionan comentarios instantáneos y se integran con herramientas de CI como Jenkins, GitHub Actions o GitLab CI/CD.
Permiten una verificación continua en todos los entornos, lo cual es una capacidad esencial para los equipos ágiles y DevOps que buscan «avanzar rápidamente sin causar daños».
|
Ventajas de la automatización |
Impacto en el desarrollo |
|
Retroalimentación continua |
Identificación más rápida de cambios importantes |
|
Ejecución coherente |
Elimina el error humano en pruebas repetitivas. |
|
Escalabilidad |
Las pruebas se ejecutan simultáneamente en todos los entornos. |
|
Listo para la integración |
Se integra directamente en los flujos de trabajo de CI/CD. |
La siguiente tabla ofrece unavisión general rápidade las principales técnicas de pruebas de regresión mencionadas anteriormente.
|
Tipo |
Descripción |
Pros |
Contras |
Ideal para |
|
Volver a probar todo |
Ejecuta todos los casos de prueba después de cada cambio. |
Cobertura completa y validación exhaustiva |
Muy laborioso y costoso. |
Sistemas pequeños y pruebas de referencia |
|
Regresión selectiva |
Las pruebas solo afectaron a los componentes basados en cambios de código. |
Respuesta eficaz y más rápida |
Requiere un mapeo preciso de las dependencias. |
Sistemas modulares y lanzamientos frecuentes |
|
Regresión priorizada |
Ejecuta pruebas clasificadas según su impacto en el negocio. |
Se centra primero en las funciones críticas. |
Puedes omitir áreas menos críticas pero relevantes. |
Ciclos de pruebas limitados en el tiempo |
|
Regresión automatizada |
Se ejecuta automáticamente a través de CI/CD después de las confirmaciones de código. |
Rápido, escalable, repetible |
Requiere configuración y mantenimiento. |
Proyectos grandes o en rápida evolución |
Crear un conjunto de pruebas de regresión es una inversión continua en la calidad del software.
Con el tiempo, se convierte en uno de los activos más valiosos de tu proceso de desarrollo.
La imagen siguiente muestra los pasos necesarios para crear y mantener un conjunto de pruebas de regresión.
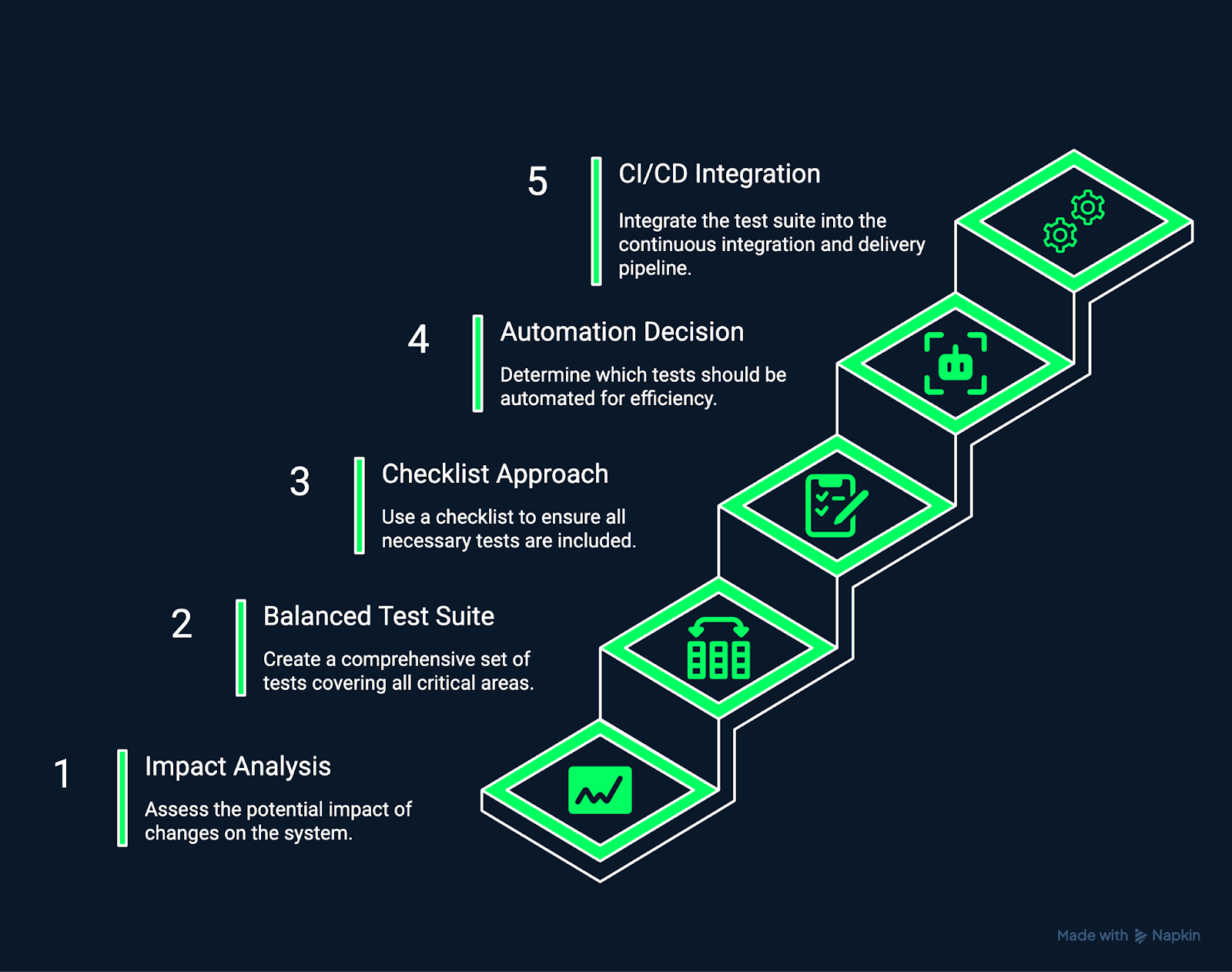
Creación y mantenimiento de un conjunto de pruebas de regresión. Imagen del autor utilizando Napkin AI.
Empieza por comprender qué partes del sistema se ven afectadas por un cambio.
Es recomendable utilizar herramientas como analizadores de cobertura de código o gráficos de dependencia para determinar qué pruebas deben volver a ejecutarse.
Da prioridad a los módulos que interactúan con código modificado, comparten estructuras de datos comunes o han fallado anteriormente tras actualizaciones similares.
Desarrolla un conjunto de pruebas que cubra exhaustivamente los flujos de trabajo críticos de la empresa, los procesos de datos esenciales y los recorridos habituales de los usuarios.
Asegúrate de que cada prueba tenga un propósito y un alcance específicos, y trata de evitar la redundancia o el solapamiento.
Las pruebas modulares y reutilizables facilitan el mantenimiento a medida que tu sistema evoluciona.
Una lista de verificación estructurada ayuda a garantizar la coherencia y la integridad tanto en las pruebas de regresión manuales como en las automatizadas.
Reduce la supervisión, estandariza la ejecución y promueve procesos de garantía de calidad repetibles.
|
Paso |
Objetivo |
|
Definir las condiciones previas |
Establecer el estado del sistema e introducir datos |
|
Ejecutar caso de prueba |
Realizar la prueba en condiciones controladas. |
|
Verificar los resultados |
Valida tanto el resultado esperado como los efectos secundarios. |
|
Resultados récord |
Documentos aprobados, rechazados y cualquier anomalía. |
Este método proporciona estructura,transparencia y responsabilidad, lo que resulta especialmente útil a la hora de incorporar nuevos ingenieros de control de calidad.
No todas las pruebas deben automatizarse.
Automatiza pruebas estables, repetibles y de alta frecuencia, incluidas aquellas que validan flujos de trabajo críticos para la misión o áreas que se actualizan con frecuencia.
Mantén un manual de pruebas exploratorias y de usabilidad, ya que el juicio humano aporta valor añadido.
|
Automatizar cuando: |
Conserva el manual cuando: |
|
Los escenarios son repetitivos y estables. |
Los escenarios requieren interpretación humana. |
|
Los datos de prueba son predecibles. |
Se está evaluando la experiencia del usuario o el comportamiento de la interfaz de usuario. |
|
Las pruebas se ejecutan con frecuencia a través de CI/CD. |
Se realizan pruebas puntuales o exploratorias. |
La integración de las pruebas de regresión en los procesos de CI/CD garantiza que cada cambio se verifique automáticamente.
Configura las compilaciones para que fallen si las pruebas de regresión detectan nuevos problemas, genera informes para su clasificación inmediata y aplica la filosofía de «probar pronto y probar a menudo».
Este enfoque evita que se acumulen las regresiones y permite crear una verdadera cultura de calidad continua.
|
Ventajas de la integración de CI/CD |
Resultado |
|
Verificación automatizada después de cada confirmación |
Detección temprana de regresiones |
|
Alertas de fallos de compilación |
Clasificación rápida del código problemático |
|
Bucle de retroalimentación continua |
Calidad constante en iteraciones rápidas |
Una gama de herramientas modernas permite realizar pruebas de regresión eficientes y escalables.
La herramienta adecuada depende de la pila tecnológica de tu proyecto, los objetivos de automatización y el nivel de madurez del equipo.
A continuación, se muestran varias opciones ampliamente adoptadas que simplifican y aceleran los flujos de trabajo de regresión.
Katalon Studio es una plataforma integral de automatización de pruebas que admite pruebas web, API, móviles y de escritorio.
Cuenta con una interfaz gráfica fácil de usar y sólidas capacidades de scripting. Por lo tanto, esto lo utilizan los equipos que pasan de las pruebas de regresión manuales a las automatizadas.
Katalon ofrece pruebas integradas basadas en palabras clave y datos, reconocimiento inteligente de objetos y paneles de informes detallados.
Una de sus mayores ventajas es la accesibilidad: los evaluadores sin amplios conocimientos de programación pueden diseñar casos de prueba complejos de forma visual, mientras que los usuarios avanzados pueden personalizar el comportamiento utilizando Groovy o JavaScript.
La plataforma se integra perfectamente con sistemas CI/CD como Jenkins y GitLab, lo que permite ejecutar pruebas de regresión automatizadas en cada compilación.
Cypress es un marco de pruebas integral, rápido y fácil de usar para programadores, diseñado específicamente para aplicaciones web modernas. A diferencia de las herramientas tradicionales basadas en Selenium, Cypress se ejecuta directamente dentro del navegador, lo que te permite observar, controlar y depurar el comportamiento web en tiempo real.
Esta arquitectura ofrece información instantánea, recarga en tiempo real y una ejecución de pruebas altamente fiable sin la inestabilidad que a veces afecta a la automatización de los navegadores.
Es ideal para equipos que ya utilizan marcos como React, Angular o Vue, ya que su sintaxis basada en JavaScript se adapta de forma natural a los flujos de trabajo de desarrollo front-end.
Cypress también ofrece potentes herramientas de depuración, espera automática y registros de pruebas detallados con capturas de pantalla y vídeos, perfectos para diagnosticar rápidamente las regresiones.
Testsigma ofrece una moderna plataforma de automatización de pruebas basada en la nube que utiliza el procesamiento del lenguaje natural (NLP) para escribir casos de prueba en inglés sencillo.
Este enfoque reduce drásticamente la barrera de entrada, lo que permite a los miembros del equipo sin conocimientos técnicos, como los analistas de control de calidad o los propietarios de productos, contribuir directamente al conjunto de pruebas de regresión.
Admite pruebas web, móviles, API y de escritorio en un entorno unificado, lo que ayuda a los equipos ágiles a lograr una amplia cobertura sin una gran sobrecarga de codificación.
Testsigma también se adapta fácilmente a diferentes navegadores, sistemas operativos y dispositivos, lo que resulta especialmente valioso para los equipos que gestionan múltiples objetivos de implementación.
Se integra perfectamente con las herramientas DevOps y los procesos CI/CD más populares, lo que permite la ejecución en tiempo real, las pruebas paralelas y el mantenimiento de pruebas asistido por IA.
Además de estas plataformas líderes, existen otras herramientas especializadas que pueden complementar los flujos de trabajo de las pruebas de regresión.
Selenium sigue siendo una opción fundamental de código abierto para la automatización de navegadores, especialmente para equipos que se sienten cómodos gestionando marcos de trabajo y scripts personalizados. Playwright, desarrollado por Microsoft, ofrece capacidades similares con una ejecución más rápida y una compatibilidad más amplia entre navegadores.
Para las pruebas móviles, herramientas como Appium amplían la automatización a las plataformas iOS y Android mediante una API unificada.
Estas herramientas forman un ecosistema robusto para las pruebas de regresión. Cada uno de ellos es compatible con la integración con canalizaciones CI/CD, sistemas de control de versiones e infraestructura en la nube.
Las pruebas de regresión son importantes, pero tienen sus dificultades.
A medida que los sistemas evolucionan y las suites de pruebas crecen, mantener la velocidad, la fiabilidad y la precisión se vuelve cada vez más complejo.
Comprender los retos comunes y cómo abordarlos ayuda a los equipos a mantener prácticas de regresión eficientes y de gran impacto a lo largo del tiempo.
La imagen siguiente muestra algunos de los retos más comunes en las pruebas de regresión.
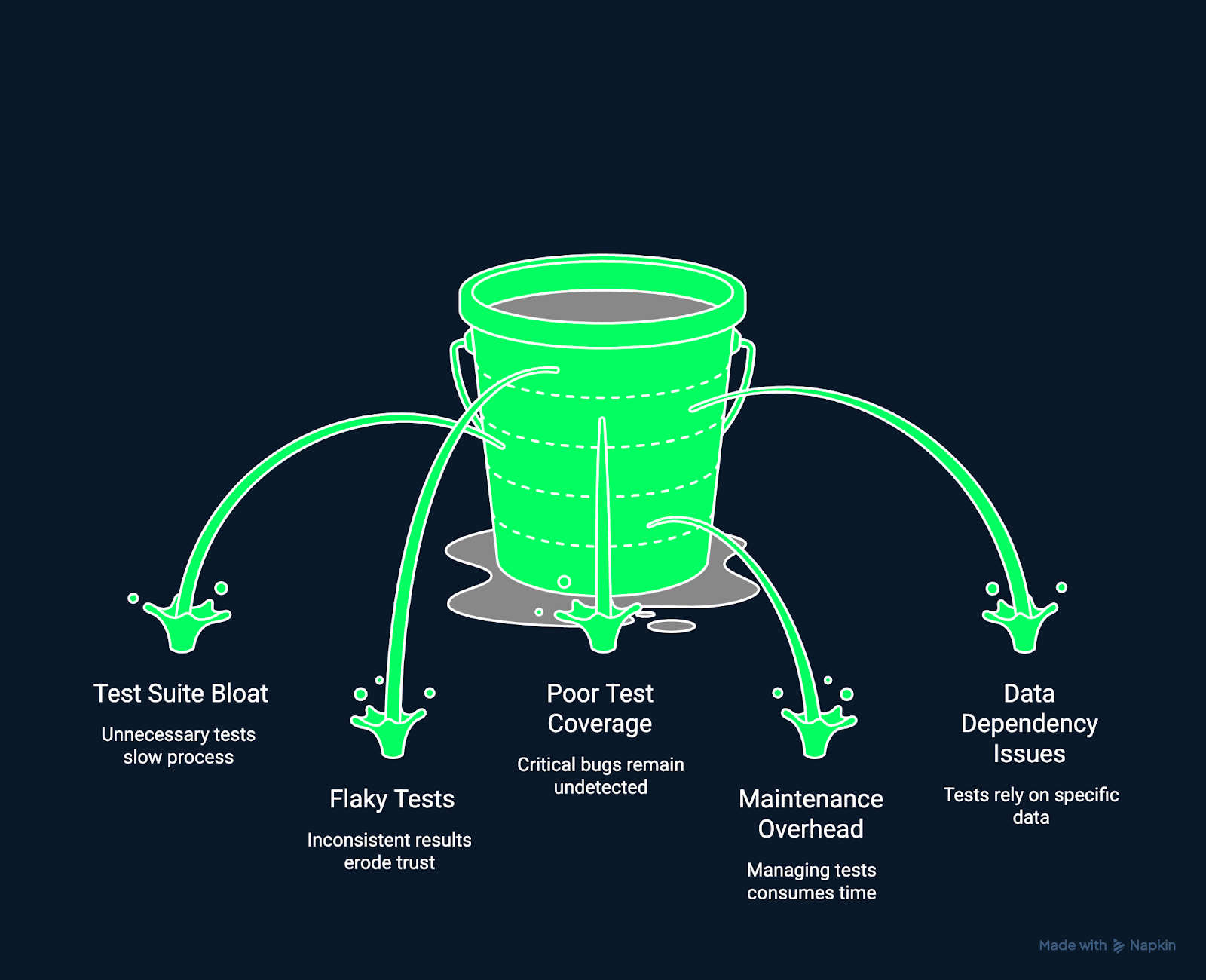
Retos en las pruebas de regresión. Imagen del autor utilizando Napkin AI.
A medida que los proyectos evolucionan, los casos de prueba pueden acumularse más rápido de lo que se revisan. Esto da lugar a suites infladas que tardan más en ejecutarse y contienen pruebas redundantes u obsoletas. Los conjuntos de pruebas demasiado grandes ralentizan los bucles de retroalimentación y reducen la eficiencia de las pruebas.
La solución consiste en auditar y refactorizar periódicamente tu conjunto de pruebas. Eliminar pruebas obsoletas o duplicadas, consolidar escenarios que se solapan y archivar casos históricos que ya no son aplicables.
Las pruebas que fallan aleatoriamente pueden frustrar a los programadores. Las pruebas inestables, aquellas que pasan o fallan de forma inconsistente, pueden deberse a operaciones asíncronas o entornos inestables. Reducen la confianza en tu sistema de pruebas y ocultan las regresiones reales.
La solución consiste en estabilizar los entornos de prueba, utilizar datos simulados en lugar de llamadas reales y añadir esperas explícitas o sincronización cuando sea necesario. Programa y reserva las pruebas defectuosas hasta que se solucionen para mantener la confianza en los resultados de la automatización.
Incluso con pruebas exhaustivas, las rutas críticas pueden quedar sin probar debido a la presión del tiempo o a la falta de claridad en cuanto a la responsabilidad. Una cobertura insuficiente permite que las regresiones pasen desapercibidas.
La solución consiste en utilizar herramientas de cobertura de código y análisis de pruebas para identificar las áreas no probadas. Céntrate primero en cubrir los módulos de alto riesgo y gran impacto, y asegúrate de que las nuevas funciones incluyan pruebas de regresión desde el principio.
Las pruebas de regresión automatizadas pueden volverse frágiles y fallar incluso tras pequeñas actualizaciones de la interfaz de usuario o la API. Los elevados costes de mantenimiento desalientan la realización de pruebas continuas y ralentizan la entrega.
La solución consiste en diseñar pruebas modulares y reutilizables, y utilizar localizadores de elementos robustos o contratos API. Implementa capas de abstracción entre las pruebas y la lógica de la aplicación para minimizar las reescrituras después de las actualizaciones.
Las pruebas que dependen de fuentes de datos en tiempo real o mutables pueden producir resultados inconsistentes, lo que dificulta distinguir entre fallos reales y ruido ambiental.
La solución consiste en utilizar datos de prueba controlados o servicios simulados para garantizar resultados predecibles y reproducibles. Versión y documenta tus datos de prueba para garantizar la coherencia entre entornos.
|
Reto |
Descripción |
Estrategia de mitigación |
|
Sobrecarga del conjunto de pruebas |
Los casos de prueba se acumulan con el tiempo, lo que ralentiza la ejecución. |
Refactorizar y eliminar pruebas redundantes con regularidad. |
|
Pruebas poco fiables |
Las pruebas fallan de forma intermitente debido a inconsistencias de sincronización, dependencias o entorno. |
Refactorizar y eliminar pruebas redundantes con regularidad. |
|
Cobertura de pruebas insuficiente |
Algunas rutas críticas no se prueban debido a descuidos o falta de tiempo. |
Utiliza herramientas de cobertura de código para identificar lagunas. |
|
Gastos generales de mantenimiento |
Las pruebas automatizadas fallan tras cambios menores en la interfaz de usuario o la API. |
Utiliza diseños de pruebas modulares y selectores robustos. |
|
Problemas de dependencia de datos |
Las pruebas se basan en fuentes de datos cambiantes o en tiempo real. |
Utiliza accesorios, simulaciones o conjuntos de datos sintéticos. |
Si deseas reforzar tus conocimientos sobre validación estadística y pruebas analíticas, prueba nuestro curso Pruebas de hipótesis en Python.
Las pruebas de regresión sólidas consisten en ejecutar pruebas y crear un marco sostenible para garantizar una calidad continua.
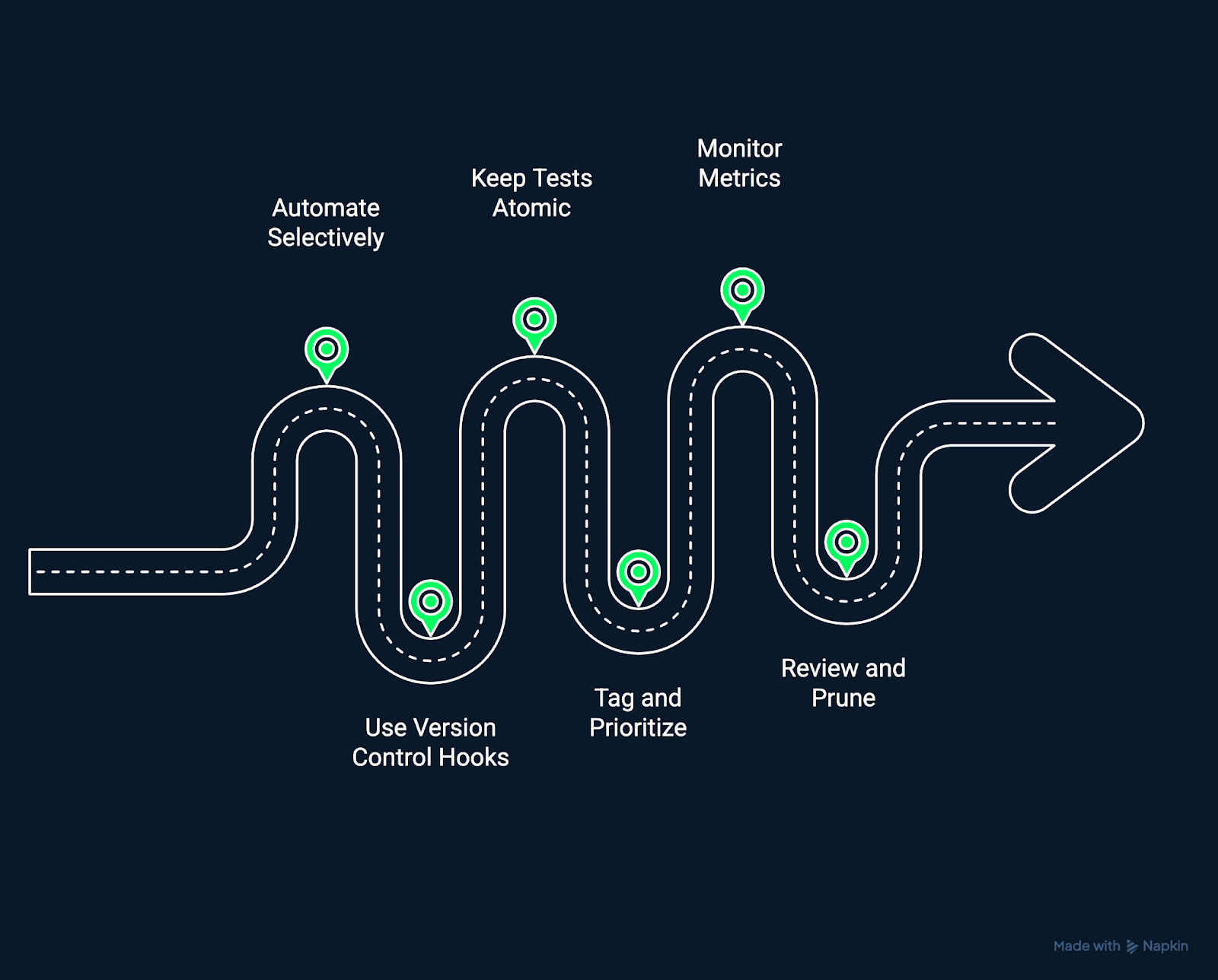
Mejores prácticas para realizar pruebas de regresión eficaces. Imagen del autor utilizando Napkin AI.
La automatización amplía la capacidad de prueba, pero no todas las pruebas deben automatizarse. Comienza por automatizar pruebas estables y de alto valor que validen los flujos de trabajo principales. Evita automatizar áreas volátiles hasta que su funcionalidad se estabilice para reducir los gastos generales de mantenimiento.
Integra las pruebas de regresión directamente en tu sistema de control de versiones. Activa ejecuciones de pruebas automatizadas en solicitudes de extracción o fusiones para detectar regresiones antes de que los cambios se fusionen en las ramas principales. Esto crea un enfoque proactivo y preventivo de las pruebas.
Cada prueba debe validar un comportamiento de forma aislada. Las pruebas atómicas facilitan el diagnóstico de los fallos y reducen los problemas en cadena cuando falla un componente. Las pruebas independientes también pueden ejecutarse en paralelo, lo que acelera los bucles de retroalimentación de CI/CD.
Etiqueta las pruebas en función de su importancia, como «humo», «regresión» o «rendimiento». Ejecuta pruebas de alto impacto en cada confirmación, mientras que las suites más amplias pueden ejecutarse cada noche o antes del lanzamiento. La priorización garantiza que las pruebas se ajusten a las limitaciones de tiempo y al riesgo empresarial.
Cuantifica el rendimiento de tus pruebas a lo largo del tiempo. Programa métricas como las tasas de fallo, la duración de la ejecución y las tendencias de cobertura para identificar cuellos de botella y oportunidades de mejora. La medición continua mantiene tus pruebas de regresión ágiles y responsables.
Los conjuntos de pruebas de regresión son sistemas vivos. Con el tiempo, elimina las pruebas obsoletas, actualiza las expectativas y ajusta las prioridades. Un conjunto de pruebas sencillo y relevante proporciona información más rápida y precisa con menos ruido.
|
Práctica |
Objetivo |
Ejemplo o resultado |
|
Automatiza pronto, pero de forma selectiva. |
Centrar los esfuerzos en pruebas estables y de alto valor. |
Reducir los gastos generales de mantenimiento |
|
Utilizar ganchos de control de versiones |
Detecta regresiones antes de fusionar código. |
Ejecuta pruebas automáticamente en las solicitudes de extracción. |
|
Mantén las pruebas atómicas e independientes. |
Simplifica la depuración y habilita las ejecuciones paralelas. |
Cada prueba valida un comportamiento específico. |
|
Utilizar etiquetado de prueba y priorización |
Asignar los recursos de prueba de manera eficiente. |
Pruebas críticas ejecutadas en cada confirmación |
|
Supervisar las métricas de prueba |
Programa el estado y la eficiencia de la suite. |
Identificar áreas lentas o inestables |
|
Revisa y poda con regularidad. |
Mantén la suite rápida y relevante. |
Eliminar los casos obsoletos o redundantes. |
Estas prácticas combinadas constituyen la base de unacultura de pruebas de regresión saludable, que prioriza la velocidad, la fiabilidad y la facilidad de mantenimiento a largo plazo.
Para mejorar tu capacidad de escribir código fácil de mantener y probar , echa un vistazo a nuestro curso Principios de ingeniería de software en Python.
Recuerda que, a medida que los sistemas de software evolucionan y se vuelven más complejos, las pruebas de regresión se convierten en una garantía esencial para mantener la estabilidad y la confianza de los usuarios. Cada cambio en el código, por pequeño que sea, introduce un riesgo potencial. Una sólida estrategia de pruebas de regresión puede ayudarte a ofrecer actualizaciones con confianza y a avanzar rápidamente sin dañar el software en el que confían tus usuarios.
Para seguir ampliando tus conocimientos sobre pruebas de software, explora nuestro curso Introducción a las pruebas en Python. Si deseas integrar estrategias de pruebas sólidas en los procesos de implementación modernos, echa un vistazo a nuestro curso CI/CD para machine learning.
Aprende con DataCamp
programa
programa
Curso
Tutorial
Natassha Selvaraj
Tutorial
Eladio Montero Porras
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
Tutorial
Abid Ali Awan
