
Cursus
AWS Cloud Practitioner (CLF-C02)
10 h
J'ai consacré de nombreuses heures à naviguer dans la console AWS, à lancer manuellement des instances EC2, à configurer des groupes de sécurité et, inévitablement, à commettre des erreurs qui nécessitaient des heures de débogage. Cela vous semble-t-il familier ? Vous créez une instance dans la mauvaise zone de disponibilité, vous omettez d'étiqueter une ressource ou vous passez un après-midi à recréer la configuration exacte que vous avez mise en place le mois dernier, car vous n'avez pas documenté les étapes.
Le provisionnement manuel des infrastructures n'est pas seulement fastidieux, il est également sujet aux erreurs, non évolutif et difficile à auditer. C'est là que Terraform change la donne. Imaginez que vous puissiez définir l'ensemble de votre infrastructure AWS dans des fichiers texte que vous pouvez contrôler, réviser et déployer automatiquement. Il n'est plus nécessaire de cliquer sur plusieurs écrans. Finies les discussions avec votre équipe sur le thème « mais cela fonctionnait sur mon ordinateur ».
Dans ce tutoriel, je vais vous expliquer comment automatiser l'infrastructure AWS à l'aide de Terraform, en me basant sur un exemple concret : le provisionnement d'une instance EC2 avec un agent SSM (Systems Manager) démarré automatiquement. À la fin, vous maîtriserez les principes fondamentaux de l'infrastructure en tant que code et disposerez d'un code fonctionnel que vous pourrez déployer immédiatement sur votre propre compte AWS.
Si vous débutez avec AWS, nous vous recommandons de suivre l'un de nos cours, tel que AWS Concepts, Introduction à AWS Boto en Pythonou Sécurité et gestion des coûts AWS.
Terraform est un outil open source d'infrastructure en tant que code (IaC) développé par HashiCorp qui permet de définir, de provisionner et de gérer des ressources cloud à l'aide du langage de configuration HashiCorp (HCL).
Au lieu de naviguer dans les consoles cloud ou de rédiger des scripts bash impératifs, vous définissez l'infrastructure souhaitée dans des fichiers de configuration, et Terraform se charge des détails pour la mettre en œuvre. Cette transition d'une infrastructure impérative à une infrastructure déclarative représente un changement fondamental dans notre conception des ressources cloud.
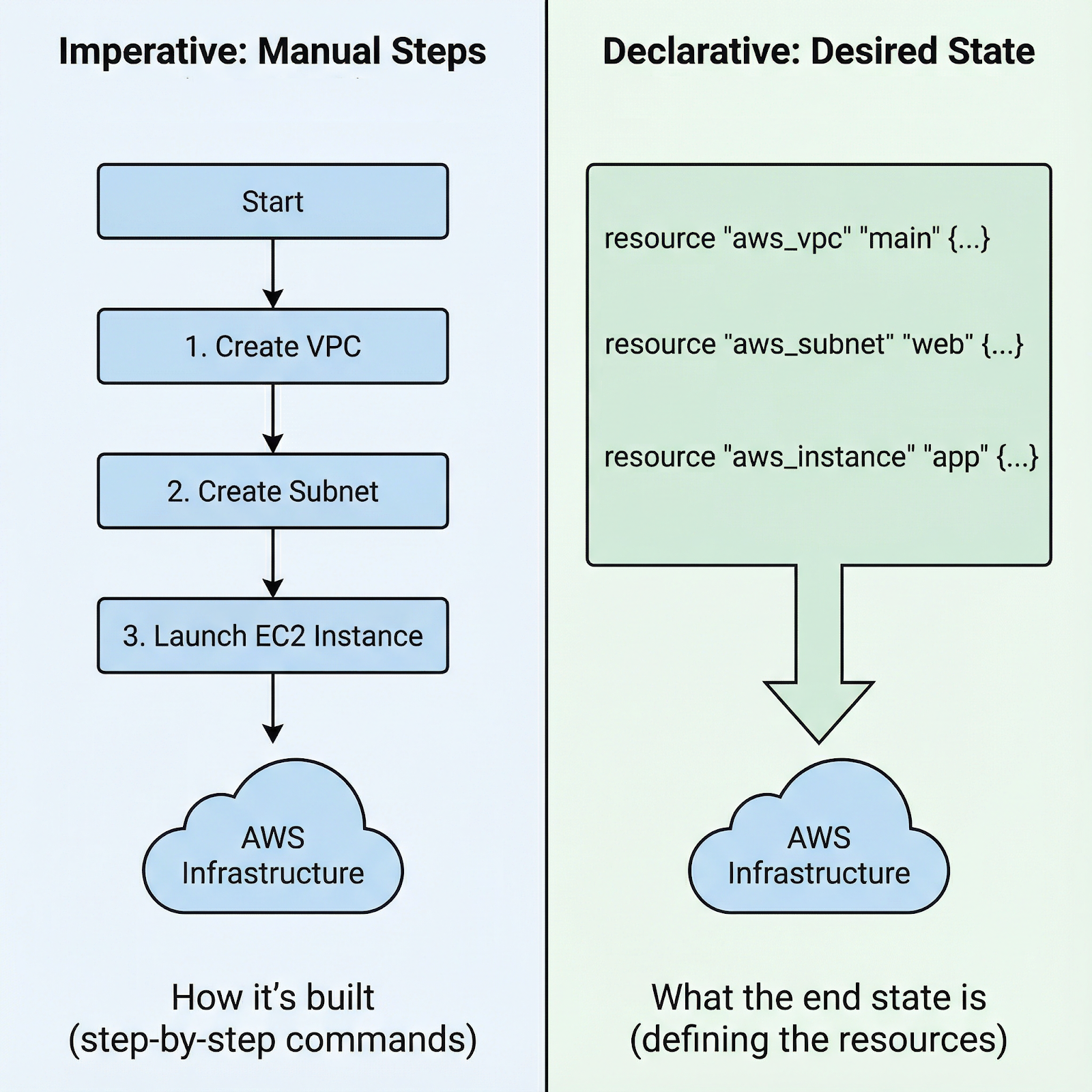
Approche impérative ou déclarative pour lancer une instance AWS EC2
Avec les approches impératives, vous rédigez des instructions étape par étape : « Commencez par créer ce groupe de sécurité, puis attendez qu'il soit opérationnel, lancez ensuite cette instance avec ce groupe de sécurité, attachez ce volume, puis créez ces balises. » Vous êtes responsable de la séquence exacte et des erreurs de manipulation à chaque étape.
Grâce à l'approche déclarative de Terraform, il vous suffit de définir l'état final : Je souhaite une instance EC2 présentant les caractéristiques suivantes, connectée à ce groupe de sécurité et dotée de ces balises. Terraform analyse les dépendances, détermine l'ordre correct et exécute le plan. Si un élément échoue, Terraform identifie précisément où le processus s'est arrêté.
Pourquoi choisir Terraform pour AWS en particulier ?
Avant de vous lancer dans la configuration pratique, il est important de comprendre trois concepts clés qui constituent les fondements de Terraform :
Maintenant que ces principes fondamentaux sont clairs, préparons votre environnement afin de commencer à construire l'infrastructure proprement dite.
Avant de rédiger tout code Terraform, il est nécessaire d'installer l'interface CLI et de configurer les informations d'identification AWS. Permettez-moi de vous expliquer les deux.
L'installation de Terraform varie selon le système d'exploitation :
Sous macOS, veuillez utiliser Homebrew : commencez par installer le tap HashiCorp à l'aide de la commande ` brew tap hashicorp/tap`, puis installez Terraform à l'aide de la commande ` brew install hashicorp/tap/terraform`.
Sous Windows, veuillez télécharger le fichier binaire depuis hashicorp.com et l'ajouter à votre PATH, ou utiliser Chocolatey : choco install terraform.
Sous Linux, veuillez télécharger le paquet approprié ou utiliser le gestionnaire de paquets de votre distribution.
Une fois l'installation terminée, veuillez vérifier qu'elle s'est déroulée correctement en exécutant le fichier terraform version.
La configuration des informations d'identification AWS nécessite un compte AWS, une clé d'accès et un secret provenant d'IAM. Veuillez ne jamais utiliser votre compte root. Veuillez plutôt créer un utilisateur IAM disposant d'un accès programmatique et des autorisations appropriées (AdministratorAccess). L'approche standard utilise le fichier d'informations d'identification AWS disponible à l'adresse ~/.aws/credentials:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEYVous pouvez également définir les variables d'environnement suivantes : AWS_ACCESS_KEY_ID et AWS_SECRET_ACCESS_KEY. Dans les environnements de production, il est recommandé d'utiliser des rôles IAM associés à des instances EC2 ou à des systèmes CI/CD plutôt que des informations d'identification à longue durée de vie.
Si vous envisagez d'utiliser un écosystème différent de celui d'Amazon ou si vous souhaitez simplement avoir une bonne vue d'ensemble de la comparaison entre les « trois grands », je vous recommande de lire cette comparaison des services AWS, Azure et GCP pour la science des données et l'IA.
Maintenant que les bases sont posées, nous allons créer quelque chose de concret : une instance EC2 qui installe automatiquement l'agent SSM au démarrage.
Les projets Terraform bénéficient d'une approche claire et structurée. Veuillez créer trois fichiers : main.tf pour les définitions de ressources, variables.tf pour les entrées et outputs.tf pour les valeurs dont vous aurez besoin après le déploiement. Cette séparation permet de garder votre code organisé et facile à maintenir.
aws-terraform
├── main.tf
├── output.tf
└── variables.tfVoici pourquoi cela est important : à mesure que les projets prennent de l'ampleur, il devient difficile de tout regrouper dans un seul fichier. Les variables vous permettent de réutiliser le même code dans différents environnements (développement, préproduction, production) en modifiant les entrées. Les sorties fournissent les valeurs dont vous avez besoin, telles que les identifiants d'instance ou les adresses IP, sans qu'il soit nécessaire d'effectuer une recherche manuelle dans la console AWS.
Nous allons maintenant créer l'infrastructure : une instance EC2 avec l'agent SSM préinstallé. Dans le fichier main.tf, veuillez ajouter la configuration suivante :
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
}
provider "aws" {
region = "eu-central-1"
}
data "aws_ami" "amazon_linux" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["amazon"]
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.amazon_linux.id
instance_type = "t2.micro"
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
user_data = <<-EOF
#!/bin/bash
cd /tmp
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
EOF
tags = {
Name = "TerraformWebServer"
}
}
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2-ssm-profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_iam_role" "ssm_role" {
name = "ec2-ssm-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "ssm_policy" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}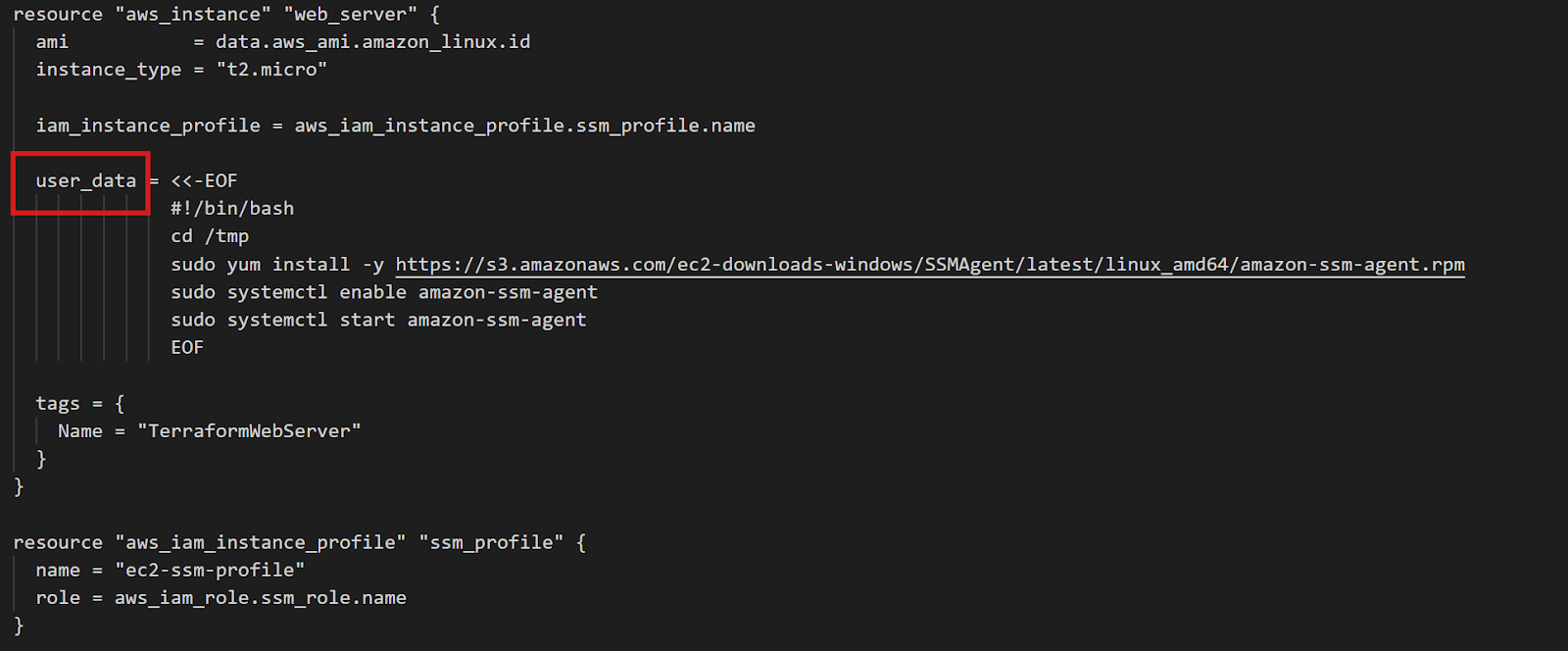
Configuration de l'instance EC2 Terraform
Le bloc d'data s interroge AWS pour obtenir la dernière image AMI Amazon Linux 2. Les filtres garantissent que vous obtenez le type d'image approprié, et owners = ["amazon"] assure que vous utilisez les AMI officielles d'Amazon. Cette approche est applicable à toutes les régions sans modification : Terraform identifie automatiquement l'AMI régionale appropriée.
L'élément essentiel est user_data: un script shell qui s'exécute lors du premier démarrage de l'instance. Ce script télécharge et installe l'agent SSM, puis le configure pour qu'il démarre automatiquement. Le rôle IAM fournit les autorisations dont SSM a besoin pour gérer l'instance.
Le même modèle s'applique à tous les agents. Souhaitez-vous utiliser CloudWatch pour les journaux et les métriques ? Veuillez modifier le script d'user_data ation afin d'installer l'agent CloudWatch à la place. Le principe reste identique : définissez ce que vous souhaitez installer, et Terraform s'assure que cela se produise sur chaque instance.
Pour le fichier output.tf, vous pouvez ajouter, par exemple, l'ID de l'instance. Ensuite, une fois que vous aurez exécuté toutes les commandes Terraform que je présenterai dans le chapitre suivant, la valeur s'affichera dans le terminal.
output "instance_id" {
description = "EC2 instance ID for SSM connection"
value = aws_instance.web_server.id
}Une fois votre configuration rédigée, le workflow Terraform comporte trois commandes. Tout d'abord, la commande suivante télécharge le plugin du fournisseur AWS et prépare votre répertoire :
terraform init
terraform init
Deuxièmement, terraform plan montre précisément ce que Terraform va créer, modifier ou supprimer. Cet aperçu vous permet de détecter les erreurs avant d'effectuer des modifications définitives :
terraform plan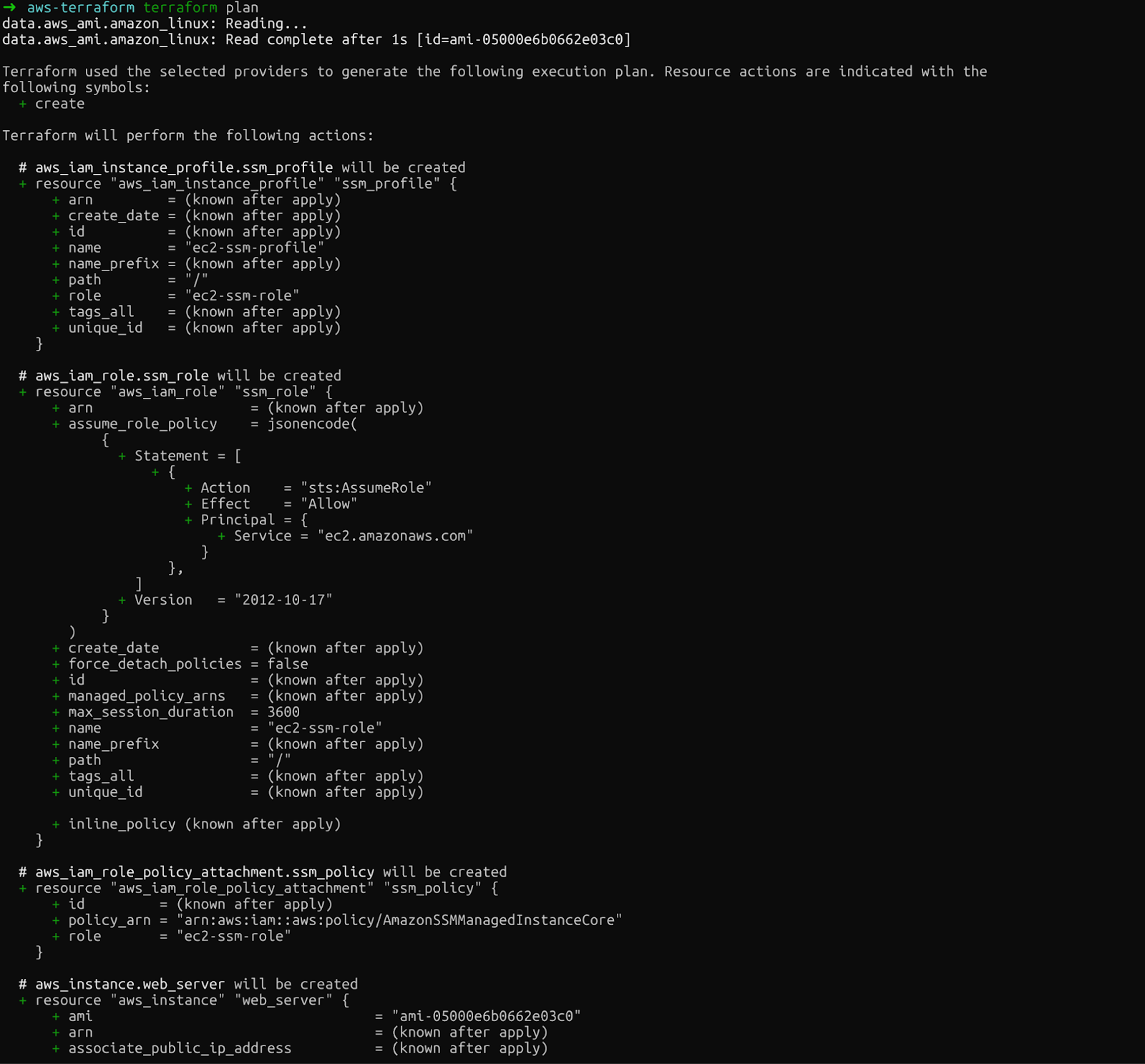
plan Terraform
Veuillez examiner attentivement le résultat. Vous verrez l'instance EC2, le rôle IAM, le profil d'instance et la politique d'attachement que Terraform créera.
Enfin, terraform apply applique les modifications. Terraform demande une confirmation avant de continuer. Veuillez saisir « oui » après avoir exécuté cette commande :
terraform apply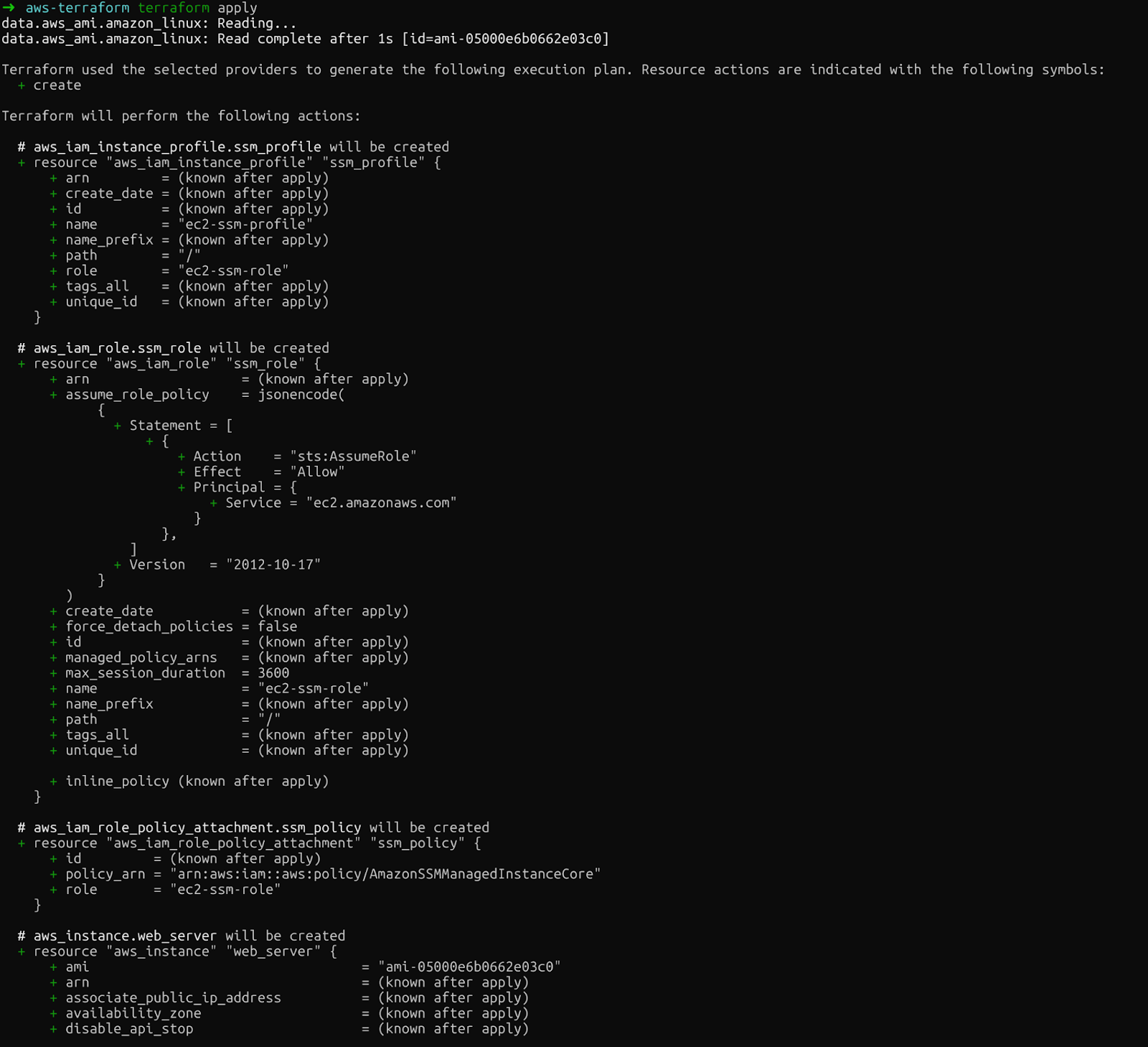
terraform apply
Si tout se déroule correctement, le message suivant s'affichera une fois les ressources créées.
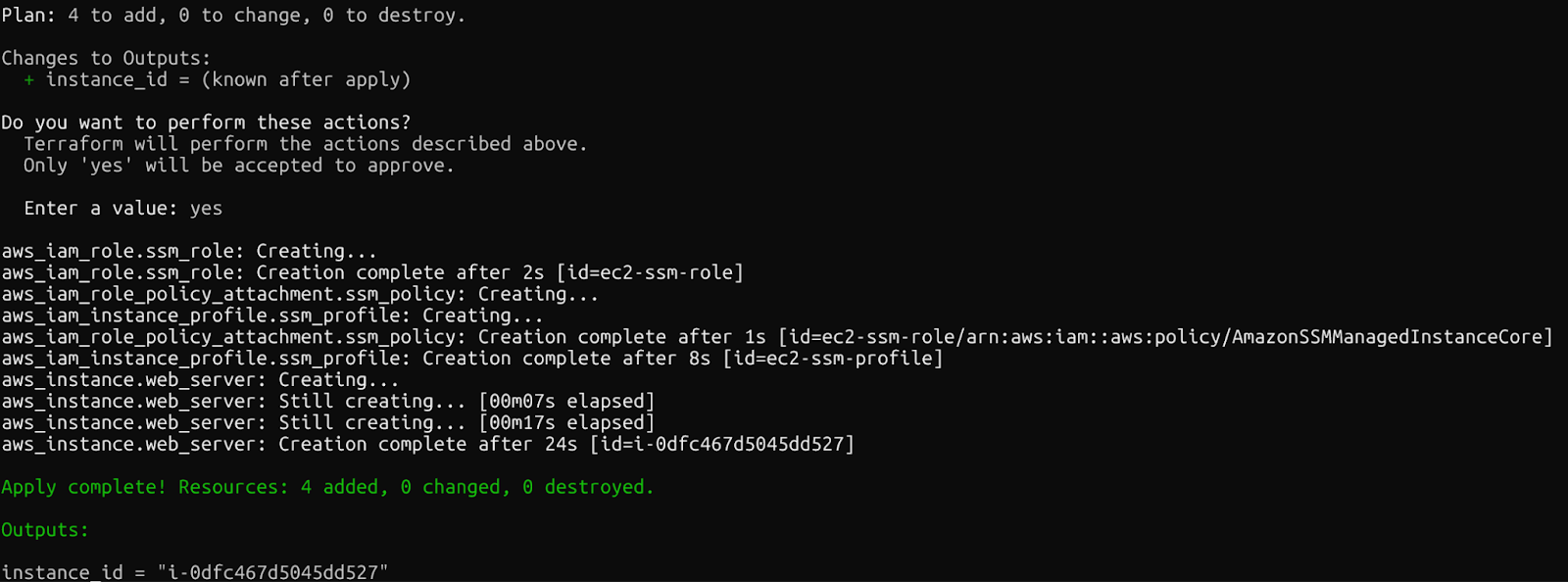
Confirmation : Ressources Terraform créées
En quelques minutes, vous disposerez d'une instance EC2 opérationnelle avec SSM configuré, accessible sans clés SSH. Veuillez vérifier la console AWS pour visualiser les ressources récemment créées.
Après avoir exécuté les commandes ci-dessus, vous constaterez qu'un nouveau fichier intitulé terraform.tfstate apparaît dans le répertoire. Le fichier d'état Terraform associe votre configuration aux ressources AWS réelles. Veuillez examiner ce document afin de comprendre son contenu.
Le fichier d'état contient toutes les informations relatives à votre infrastructure déployée : identifiants de ressources, adresses IP et dépendances. Terraform compare cet état à votre configuration et à l'état réel d'AWS afin de déterminer les actions à entreprendre. Si vous perdez le fichier d'état, Terraform perdra la trace de tout ce qu'il a créé.
Il est préconisé de ne pas conserver d'informations sensibles sur votre ordinateur portable. Si votre machine tombe en panne, l'état disparaît. Si plusieurs membres de l'équipe travaillent sur la même infrastructure, les conflits entre les états locaux peuvent entraîner des problèmes. La solution : le stockage à distance de l'état.
Pour approfondir vos connaissances sur S3 et EFS, veuillez consulter ce tutoriel sur le stockage AWS..
Le backend S3 de Terraform stocke l'état dans un emplacement centralisé et durable accessible à l'ensemble de votre équipe. Tout d'abord, veuillez créer un compartiment S3 :
aws s3api create-bucket \
--bucket datacamp-terraform-state \
--region eu-central-1 \
--create-bucket-configuration LocationConstraint=eu-central-1
aws s3api put-bucket-versioning \
--bucket datacamp-terraform-state \
--versioning-configuration Status=EnabledLa gestion des versions est essentielle : elle vous permet de récupérer des données après un incident en revenant à des versions antérieures.
Veuillez maintenant ajouter la configuration backend à votre code Terraform :
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
backend "s3" {
bucket = "datacamp-terraform-state"
key = "terraform.tfstate"
region = "eu-central-1"
use_lockfile = true
}
}Veuillez relancer terraform init pour migrer votre état local vers S3. Terraform demandera une confirmation avant de déplacer le fichier d'état.
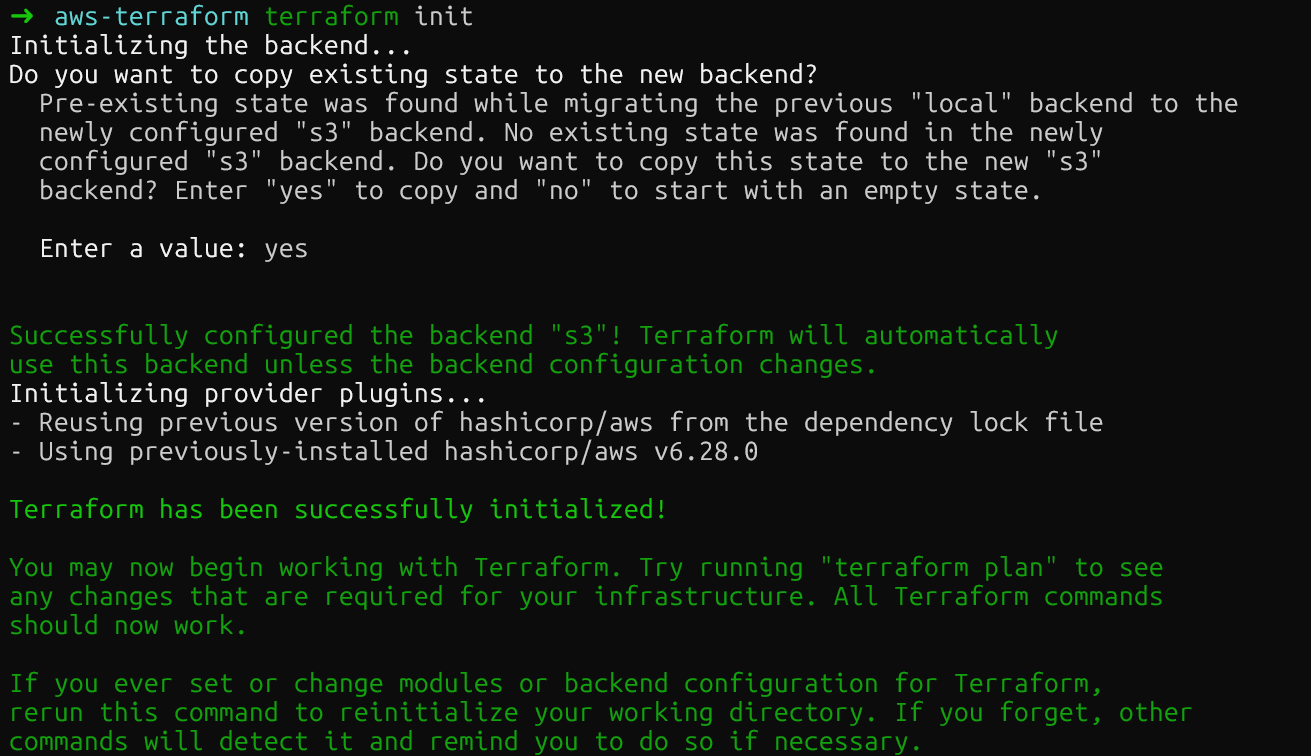
Backend distant Terraform S3
Après avoir exécuté la commande, le compartiment S3 devrait contenir le nouveau fichier d'état. Vous pouvez vérifier cela dans la console AWS.
Vous avez probablement remarqué que nous avons ajouté la commande suivante au fichier main.tf: use_lockfile = true. Ce paramètre active la nouvelle fonctionnalité de Terraform : le verrouillage natif de l'état S3. Auparavant, il était nécessaire de disposer d'une table DynamoDB distincte pour le verrouillage.
État de verrouillage Terraform
Cette simplification élimine un service AWS complet de votre configuration d'infrastructure tout en offrant la même protection contre les conditions de concurrence. Plusieurs ingénieurs peuvent travailler en toute sécurité sur l'infrastructure, sachant que seules les modifications apportées par une seule personne à la fois seront appliquées.
À mesure que votre infrastructure se développe, les valeurs codées en dur et le code copié-collé deviennent des défis de maintenance. Le système de variables et les modules de Terraform permettent de résoudre ce problème.
Auparavant, nous avons créé le fichier variables.tf. Vous pouvez désormais déplacer les valeurs, qui étaient auparavant codées en dur dans main.tf, vers ce nouveau fichier qui contiendra nos variables :
variable "aws_region" {
description = "AWS region for resources"
type = string
default = "eu-central-1"
}
variable "instance_type" {
description = "EC2 instance type"
type = string
default = "t2.micro"
}Veuillez maintenant référencer les variables dans vos ressources dans le fichier main.tf:
provider "aws" {
region = var.aws_region
}
resource "aws_instance" "web_server" {
instance_type = var.instance_type
# ... rest of configuration
tags = {
Environment = var.environment
}
}Veuillez noter que les compartiments AWS S3 sont uniques, il n'est donc pas possible d'utiliser des variables dans la région du paramètre backend de main.tf. Dans ce cas, il est nécessaire de conserver votre région codée en dur, par exemple “eu-central-1” au lieu de var.region_aws.
Maintenant que nos variables ont été définies, vous pouvez également définir différents environnements, tels que le développement ou la production, où les variables peuvent varier. Pour ce faire, il convient de créer de nouveaux fichiers avec l'extension .tfvars.
Par exemple, vous pouvez créer un fichier terraform-dev.tfvars pour le développement et un fichier terraform-prod.tfvars pour la production :
Développement :
aws_region = "eu-central-1"
instance_type = "t2.micro"Production :
aws_region = "eu-central-1"
instance_type = "t3.medium"Ensuite, vous pouvez procéder au déploiement dans les différents environnements en spécifiant le fichier approprié :
terraform apply -var-file="terraform-dev.tfvars”Les variables permettent de résoudre le problème des valeurs spécifiques à l'environnement, mais qu'en est-il de la duplication de modèles d'infrastructure complets ? C'est là que les modules deviennent indispensables.
Les modules regroupent les ressources en composants réutilisables. La meilleure façon d'utiliser les modules consiste à créer un dossier spécifique. Par exemple, vous pouvez créer une structure de répertoires comme celle-ci :
modules/
ec2-with-ssm/
main.tf
variables.tf
outputs.tfVous pouvez déplacer le fichier variables.tf précédemment créé (ou en créer un nouveau) vers le dossier du module. La modification principale se trouve dans le fichier main.tf. Celui du module doit contenir nos ressources. Par conséquent, tous les éléments, de l'AMI jusqu'à la fin du fichier, doivent être déplacés à cet emplacement :
data "aws_ami" "amazon_linux" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["amazon"]
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.amazon_linux.id
instance_type = var.instance_type
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
user_data = <<-EOF
#!/bin/bash
cd /tmp
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
EOF
tags = {
Name = "TerraformWebServer"
}
}
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2-ssm-profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_iam_role" "ssm_role" {
name = "ec2-ssm-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "ssm_policy" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}Pour remplacer cette modification, veuillez conserver le reste du fichier, mais ajoutez un paramètre de module qui fait référence au module spécifique.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
backend "s3" {
bucket = "datacamp-terraform-state"
key = "terraform.tfstate"
region = "eu-central-1"
use_lockfile = true
}
}
provider "aws" {
region = var.aws_region
}
module "web_server" {
source = "./modules/ec2-with-ssm"
instance_type = var.instance_type
}À présent, si vous exécutez les commandes init, plan et apply avec ces paramètres, vous déployerez les mêmes ressources qu'auparavant. La différence réside dans le fait que les modules vous permettent de déployer une infrastructure avec des configurations similaires qui peuvent être réutilisées. Ils sont essentiels pour étendre Terraform au-delà des projets simples.
Passons maintenant à un autre sujet important : la sécurité.
Le code d'infrastructure doit respecter les mêmes normes de sécurité que le code d'application. Il est donc essentiel de protéger vos déploiements Terraform.
Veuillez ne jamais enregistrer de secrets dans Git. Jamais. Veuillez utiliser AWS Secrets Manager pour les valeurs sensibles. Vous pouvez utiliser la ressource suivante dans Terraform pour y parvenir :
resource "aws_secretsmanager_secret" "example" {
name = "example"
}Pour les secrets spécifiques à l'environnement, il est possible d'utiliser des variables d'environnement avec le préfixe TF_VAR_.
Par exemple, vous pourriez utiliser variable "aws_access_key" {} dans le fichier variables.tf et l'exporter dans le terminal avec export TF_VAR_aws_access_key=. Terraform charge automatiquement ces valeurs en tant que variables sans les exposer dans le code.
Un autre sujet important en matière de configuration est la dérive. Cela se produit lorsque quelqu'un modifie l'infrastructure via la console AWS ou l'interface CLI, en contournant Terraform. Veuillez exécuter régulièrement terraform plan afin de détecter toute dérive. Le résultat du plan indique les ressources existantes qui ne correspondent pas à votre configuration.
Lorsque des écarts apparaissent, vous avez deux options : mettre à jour votre code Terraform pour qu'il corresponde à la réalité, ou exécuter l'terraform apply e pour forcer l'infrastructure à revenir à l'état souhaité. Le choix approprié dépend du caractère intentionnel ou non de la modification manuelle.
Enfin, il est également important de supprimer toutes les ressources dont nous n'avons plus besoin, afin d'éviter des coûts inutiles. Vous pouvez nettoyer les ressources à l'aide de la commande suivante :
terraform destroyVeuillez examiner attentivement le plan de destruction. Terraform supprimera toutes les ressources qu'il a créées. Pour la production, envisagez d'utiliser terraform destroy -target afin de supprimer des ressources spécifiques plutôt que l'ensemble des ressources.
Vous avez appris le workflow principal de Terraform : définir l'infrastructure dans le code, prévisualiser les modifications avec ` plan`, les appliquer avec ` apply` et tout suivre avec la gestion de l'état. Nous avons abordé le déploiement EC2 avec l'installation automatique d'agents, transféré l'état vers S3 avec verrouillage natif, mis à l'échelle avec des variables et des modules, et sécurisé l'infrastructure avec la gestion des secrets.
Traitez le code d'infrastructure avec la même rigueur que le code d'application. Veuillez utiliser le contrôle de version, exiger des revues de code pour les modifications et effectuer des tests dans des environnements hors production dans un premier temps. Les pipelines CI/CD peuvent automatiser l'terraform apply, rendant les mises à jour de l'infrastructure aussi fluides que les déploiements d'applications.
Votre prochaine étape : explorez GitHub Actions ou GitLab CI pour exécuter automatiquement Terraform lorsque vous effectuez un push de code. Cette approche « Infrastructure as Code », associée à l'automatisation, transforme la manière dont les équipes gèrent les ressources cloud, en remplaçant le travail manuel sur console par une infrastructure fiable, reproductible et contrôlée par version.
Je vous recommande de vous appuyer sur ces connaissances et de vous inscrire à la formation AWS Cloud Practitioner (CLF-C02) , qui vous propose un cursus complet pour obtenir la certification CLF-C02 d'Amazon.
Cours AWS
Cursus
Cours
Cours