
Programa
Profissional de nuvem da AWS (CLF-C02)
10 h
Passei um monte de tempo clicando no Console da AWS, abrindo instâncias EC2 manualmente, configurando grupos de segurança e, claro, cometendo erros que levam horas para serem corrigidos. Parece familiar? Você cria uma instância na zona de disponibilidade errada, esquece de marcar um recurso ou passa uma tarde recriando a configuração exata que você montou no mês passado porque não documentou as etapas.
O provisionamento manual de infraestrutura não é só chato, mas também pode dar errado, não é escalável e é impossível de auditar. É aí que o Terraform muda tudo. Imagine definir toda a sua infraestrutura AWS em arquivos de texto que você pode controlar por versão, revisar e implantar automaticamente. Chega de clicar em várias telas. Chega de conversas do tipo “mas funcionou na minha máquina” com sua equipe.
Neste tutorial, vou mostrar como automatizar a infraestrutura da AWS usando o Terraform, com foco em um exemplo real: provisionar uma instância EC2 com um agente SSM (Systems Manager) inicializado automaticamente. No final, você vai entender os fundamentos da Infraestrutura como Código e vai ter um código funcional que pode implementar imediatamente na sua própria conta AWS.
Se você é novo na AWS, considere fazer um dos nossos cursos, como o AWS Concepts, Introdução ao AWS Boto em Pythonou Segurança e gerenciamento de custos da AWS.
O Terraform é uma ferramenta de código aberto de Infraestrutura como Código (IaC) criada pela HashiCorp que permite definir, provisionar e gerenciar recursos em nuvem usando a Linguagem de Configuração HashiCorp (HCL).
Em vez de ficar clicando em consoles na nuvem ou escrevendo scripts bash imperativos, você declara a infraestrutura que deseja nos arquivos de configuração, e o Terraform cuida dos detalhes para que isso aconteça. Essa mudança de infraestrutura imperativa para declarativa representa uma mudança fundamental na forma como pensamos sobre os recursos da nuvem.
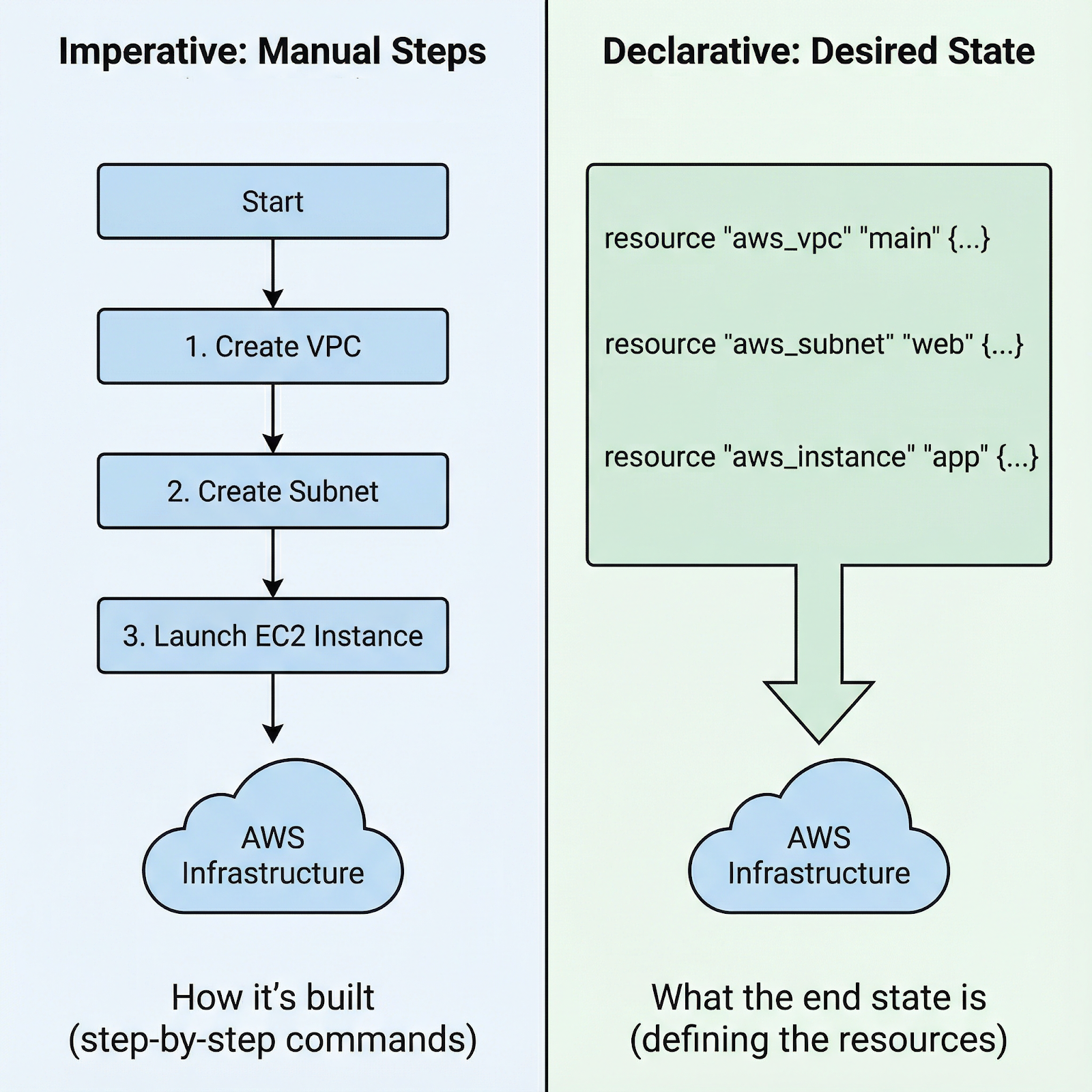
Abordagem imperativa vs. declarativa para lançar uma instância AWS EC2
Com abordagens imperativas, você escreve instruções passo a passo: “primeiro crie esse grupo de segurança, depois espere ele existir, depois inicie essa instância com esse grupo de segurança, depois conecte esse volume, depois crie essas tags”. Você é responsável pela sequência exata e pelos erros de manuseio em cada etapa.
Com a abordagem declarativa do Terraform, você só precisa definir o estado final: Quero uma instância EC2 com essas especificações, conectada a esse grupo de segurança, com essas tags. O Terraform analisa as dependências, determina a ordem certa e coloca o plano em ação. Se algo der errado, o Terraform sabe exatamente onde parou.
Por que escolher o Terraform especificamente para a AWS?
Antes de mergulhar na configuração prática, você precisa entender três conceitos-chave que formam a base do Terraform:
Com esses fundamentos claros, vamos preparar seu ambiente para começar a construir a infraestrutura real.
Antes de escrever qualquer código Terraform, você precisa ter a CLI instalada e as credenciais da AWS configuradas. Deixa eu te explicar os dois.
A instalação do Terraform varia de acordo com o sistema operacional:
No macOS, use o Homebrew: primeiro instale o HashiCorp tap com brew tap hashicorp/tap e, em seguida, instale o Terraform com brew install hashicorp/tap/terraform.
No Windows, baixa o binário em hashicorp.com e adiciona-o ao teu PATH, ou usa o Chocolatey: choco install terraform.
No Linux, baixa o pacote certo ou usa o gerenciador de pacotes da tua distribuição.
Depois de instalar, dá uma olhada se tá tudo certo rodando o terraform version.
Pra configurar as credenciais da AWS, você precisa de uma conta AWS, uma chave de acesso e um segredo do IAM. Nunca use sua conta root. Em vez disso, crie um usuário IAM com acesso programático e permissões apropriadas (AdministratorAccess). A abordagem padrão usa o arquivo de credenciais da AWS em ~/.aws/credentials:
[default]
aws_access_key_id = YOUR_ACCESS_KEY
aws_secret_access_key = YOUR_SECRET_KEYOu então, defina as variáveis de ambiente: ` AWS_ACCESS_KEY_ID ` e ` AWS_SECRET_ACCESS_KEY`. Para ambientes de produção, use funções IAM associadas a instâncias EC2 ou sistemas CI/CD em vez de credenciais de longa duração.
Se você está pensando em usar um ecossistema diferente do da Amazon ou simplesmente quer ter uma boa visão geral de como os “três grandes” se comparam, recomendo a leitura desta comparação de serviços da AWS, Azure e GCP para ciência de dados e IA.
Com a base pronta, vamos criar algo real: uma instância EC2 que instala automaticamente o agente SSM na inicialização.
Os projetos Terraform se beneficiam de uma abordagem clara e estruturada. Crie três arquivos: main.tf para definições de recursos, variables.tf para entradas e outputs.tf para valores que você vai precisar depois da implantação. Essa separação mantém seu código organizado e fácil de manter.
aws-terraform
├── main.tf
├── output.tf
└── variables.tfEis por que isso é importante: conforme os projetos crescem, misturar tudo em um único arquivo fica difícil de manter. As variáveis permitem que você reutilize o mesmo código em diferentes ambientes (desenvolvimento, teste, produção) alterando as entradas. As saídas fornecem os valores de que você precisa, como IDs de instância ou endereços IP, sem precisar procurar manualmente no Console da AWS.
Agora vamos criar a infraestrutura: uma instância EC2 com o agente SSM pré-instalado. No arquivo main.tf, adicione a seguinte configuração:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
}
provider "aws" {
region = "eu-central-1"
}
data "aws_ami" "amazon_linux" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["amazon"]
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.amazon_linux.id
instance_type = "t2.micro"
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
user_data = <<-EOF
#!/bin/bash
cd /tmp
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
EOF
tags = {
Name = "TerraformWebServer"
}
}
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2-ssm-profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_iam_role" "ssm_role" {
name = "ec2-ssm-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "ssm_policy" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}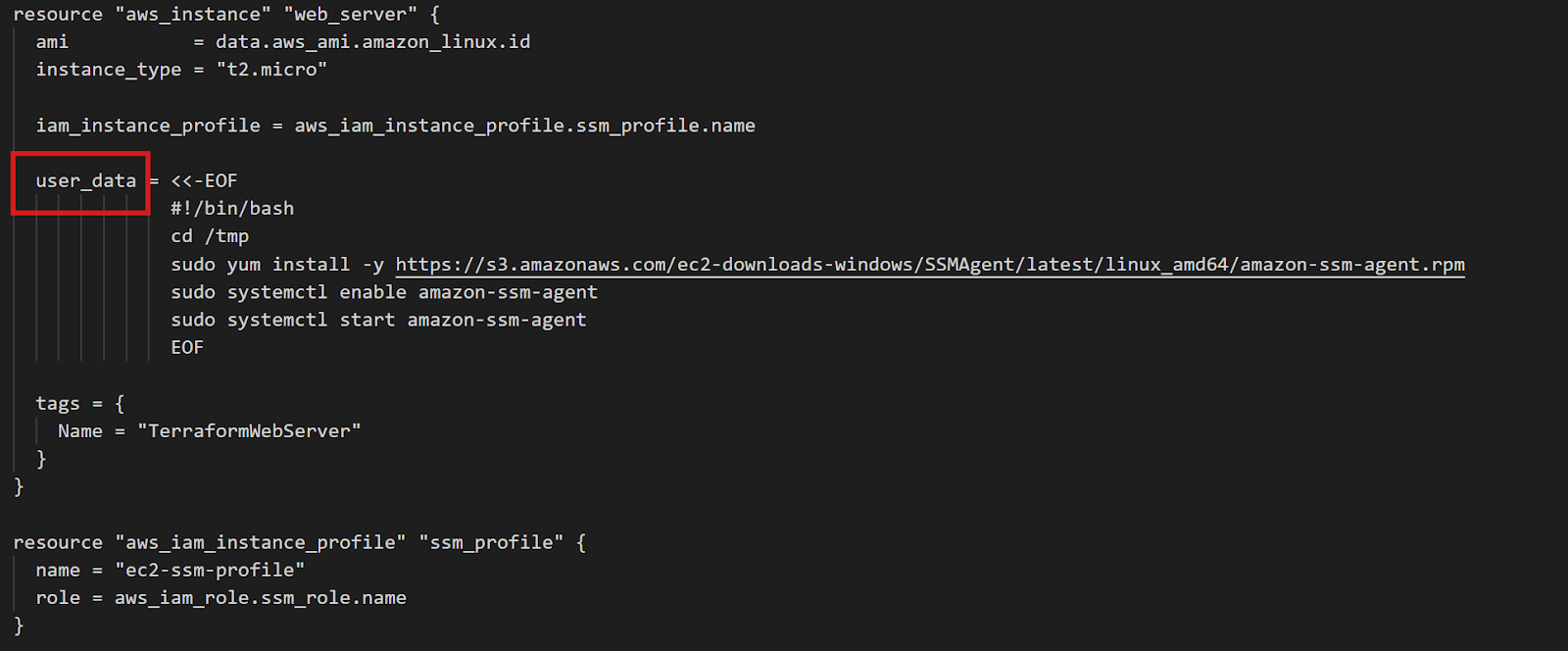
Configuração da instância EC2 do Terraform
O bloco ` data ` consulta a AWS para obter a AMI mais recente do Amazon Linux 2. Os filtros garantem que você obtenha o tipo de imagem correto, e owners = ["amazon"] garante que você esteja usando AMIs oficiais da Amazon. Essa abordagem funciona em todas as regiões sem precisar mexer em nada — o Terraform encontra automaticamente a AMI regional certa.
A parte importante é o user_data: um script shell que rola quando a instância é inicializada pela primeira vez. Esse script baixa e instala o agente SSM e, em seguida, permite que ele seja iniciado automaticamente. A função IAM fornece as permissões necessárias para o SSM gerenciar a instância.
O mesmo padrão funciona para qualquer agente. Quer o CloudWatch para logs e métricas? É só mexer no script user_data pra instalar o agente CloudWatch. O princípio continua o mesmo: defina o que você quer instalar, e o Terraform garante que isso aconteça em todas as instâncias.
Para o arquivo output.tf, você pode adicionar, por exemplo, o ID da instância. Então, depois de executar todos os comandos do Terraform que vou abordar no próximo capítulo, o valor aparecerá no terminal.
output "instance_id" {
description = "EC2 instance ID for SSM connection"
value = aws_instance.web_server.id
}Com sua configuração escrita, o fluxo de trabalho do Terraform tem três comandos. Primeiro, o comando a seguir baixa o plug-in do provedor AWS e prepara seu diretório:
terraform init
terraform init
Segundo, o comando ` terraform plan ` mostra exatamente o que o Terraform vai criar, modificar ou destruir. Essa pré-visualização permite que você detecte erros antes de fazer alterações reais:
terraform plan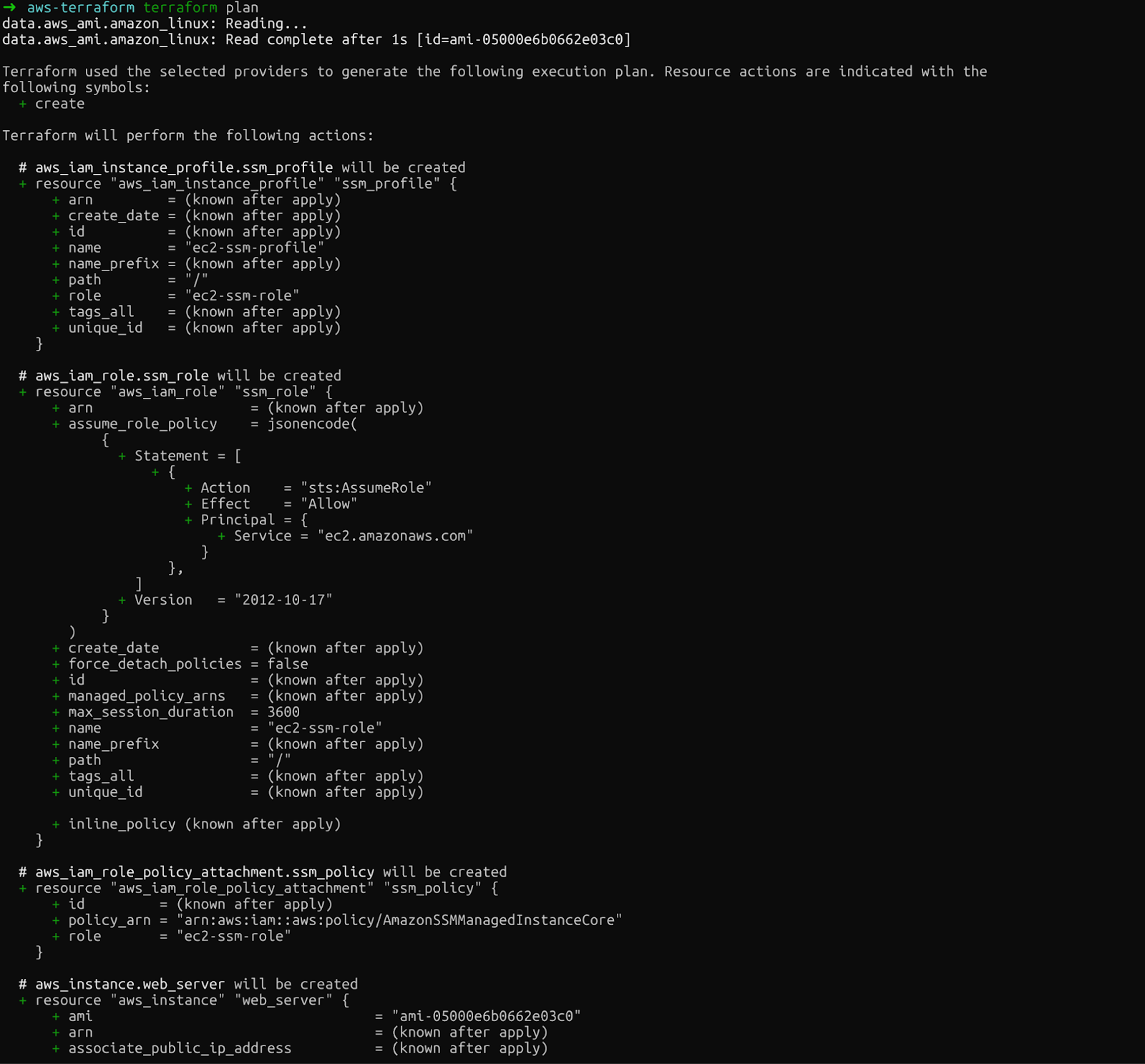
plano terraform
Dá uma olhada com cuidado no resultado. Você vai ver a instância EC2, a função IAM, o perfil da instância e a anexação da política que o Terraform vai criar.
Por fim, o comando ` terraform apply ` faz as alterações. O Terraform pede uma confirmação antes de continuar. Digite sim depois de executar este comando:
terraform apply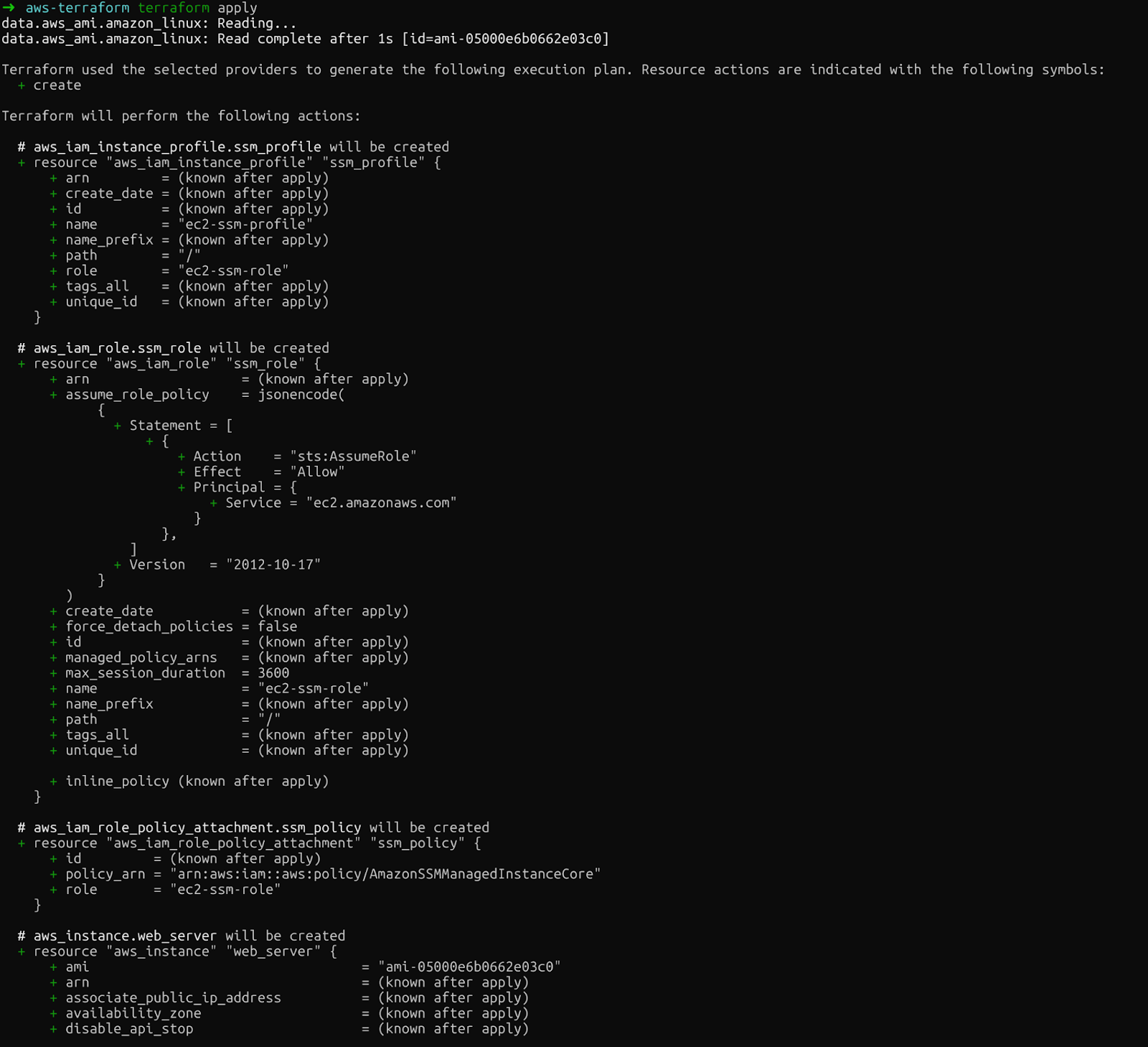
aplicar terraform
Se tudo der certo, você vai ver a seguinte mensagem assim que os recursos forem criados.
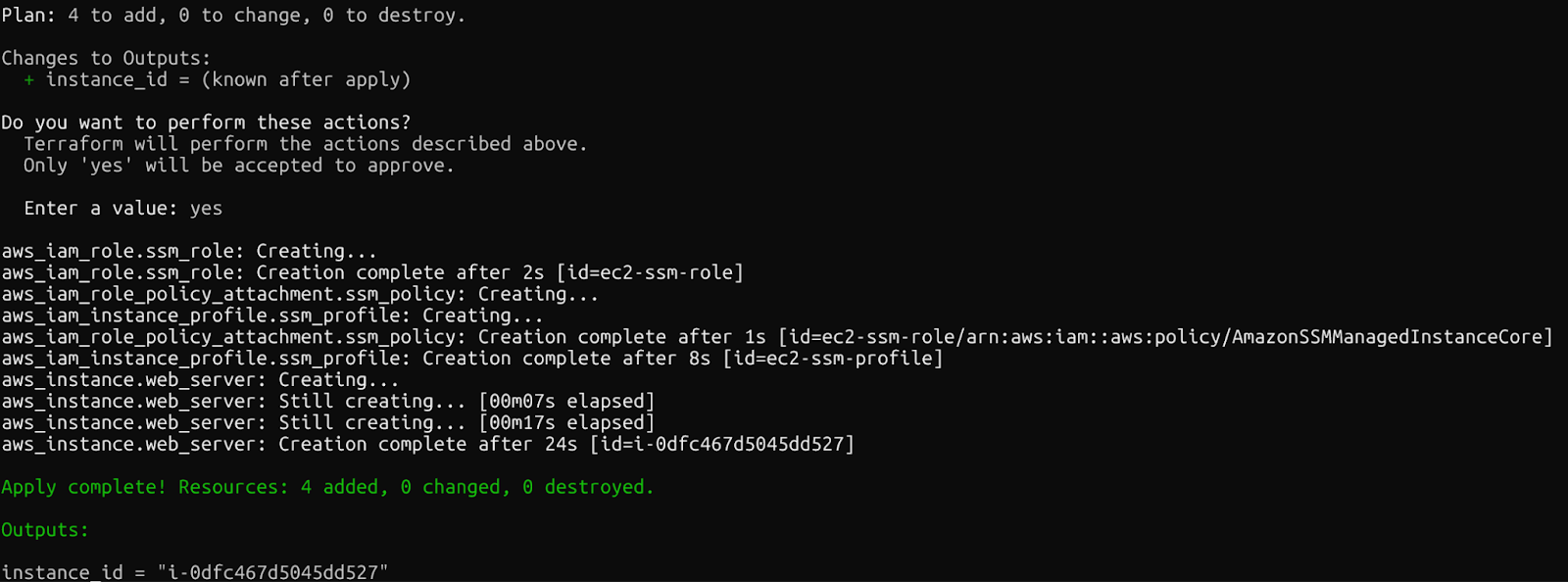
Confirmação: Recursos Terraform criados
Em poucos minutos, você vai ter uma instância EC2 funcionando com o SSM configurado, acessível sem chaves SSH. Não esqueça de dar uma olhada no Console da AWS pra ver os recursos que foram criados recentemente.
Depois de rodar os comandos acima, você vai ver um novo arquivo no diretório chamado terraform.tfstate. O arquivo de estado do Terraform mapeia sua configuração para recursos reais da AWS. Vamos dar uma olhada nesse arquivo pra entender o que tem nele.
O arquivo de estado tem todos os detalhes sobre a sua infraestrutura implantada: IDs de recursos, endereços IP e dependências. O Terraform compara esse estado com a sua configuração e o estado real da AWS para decidir quais ações tomar. Se você perder o arquivo de estado, o Terraform vai perder o controle de tudo que criou.
Manter o estado no seu laptop é perigoso. Se o seu computador travar, o estado desaparece. Se vários membros da equipe estiverem trabalhando na mesma infraestrutura, os conflitos de estados locais podem causar problemas. A solução: armazenamento remoto de estado.
Para saber mais sobre o S3 e o EFS, dá uma olhada neste Tutorial de armazenamento da AWS.
O backend S3 do Terraform guarda o estado num lugar centralizado e durável, acessível para toda a sua equipe. Primeiro, crie um bucket S3:
aws s3api create-bucket \
--bucket datacamp-terraform-state \
--region eu-central-1 \
--create-bucket-configuration LocationConstraint=eu-central-1
aws s3api put-bucket-versioning \
--bucket datacamp-terraform-state \
--versioning-configuration Status=EnabledO controle de versões é super importante: ele permite que você se recupere de acidentes voltando para versões anteriores.
Agora, adicione a configuração do backend ao seu código Terraform:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
backend "s3" {
bucket = "datacamp-terraform-state"
key = "terraform.tfstate"
region = "eu-central-1"
use_lockfile = true
}
}Execute terraform init de novo para migrar seu estado local para o S3. O Terraform vai pedir pra você confirmar antes de mover o arquivo de estado.
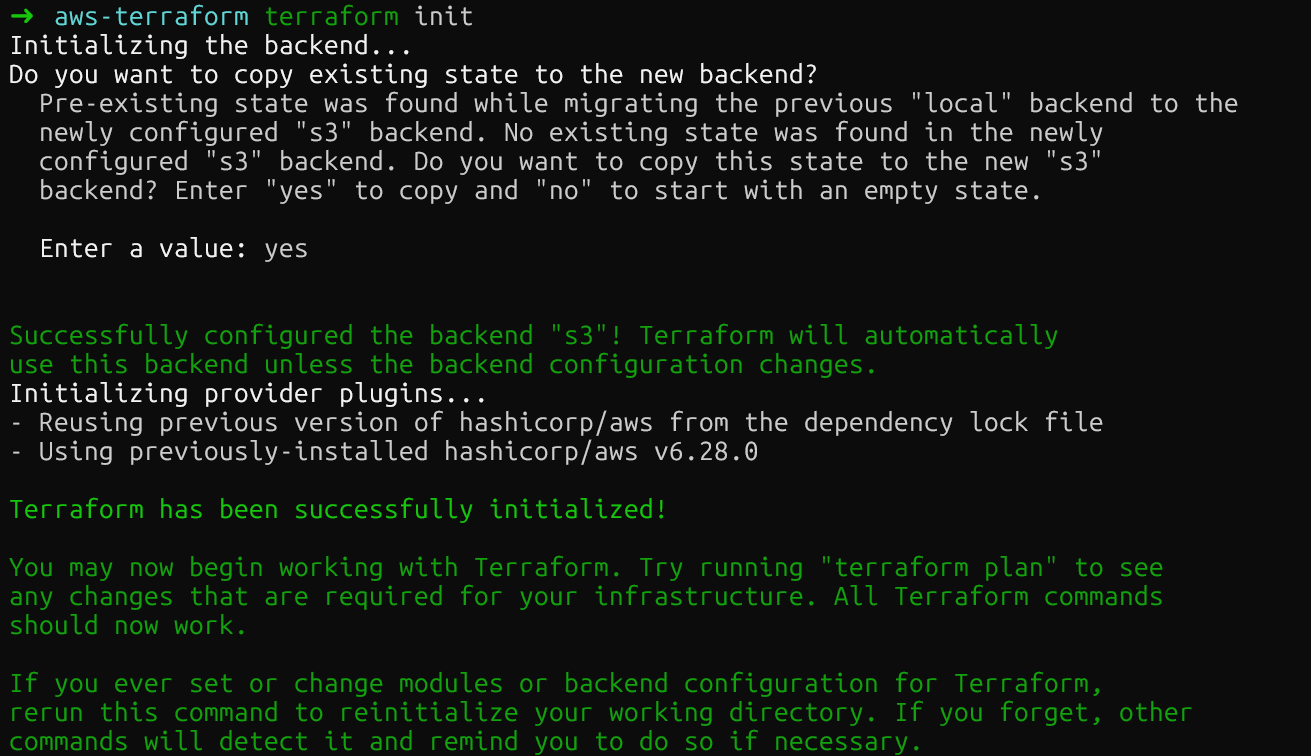
Backend remoto Terraform S3
Depois de executar o comando, o bucket S3 vai ter o novo arquivo de estado. Você pode conferir isso no console da AWS.
Você provavelmente já viu que a gente adicionou o seguinte comando ao arquivo main.tf: use_lockfile = true . Essa configuração ativa o recurso mais recente do Terraform: bloqueio de estado S3 nativo. Antes, você precisava de uma tabela DynamoDB separada para o bloqueio.
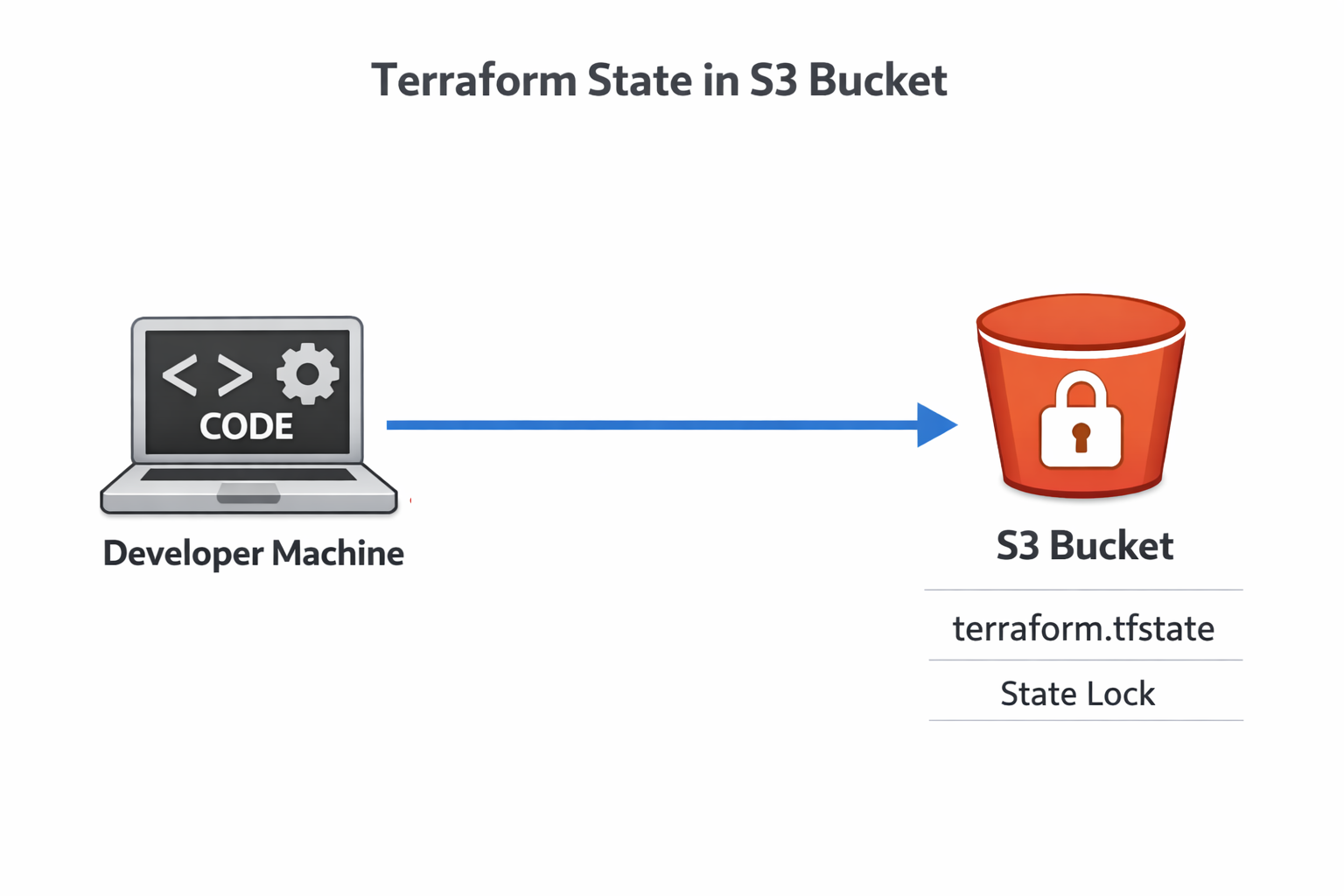
Estado de bloqueio do Terraform
Essa simplificação tira um serviço AWS inteiro da sua configuração de infraestrutura, mas ainda dá a mesma proteção contra condições de corrida. Vários engenheiros podem trabalhar na infraestrutura com segurança, sabendo que só as alterações de uma pessoa serão aplicadas de cada vez.
À medida que sua infraestrutura cresce, valores codificados e código copiado e colado se tornam um pesadelo para a manutenção. O sistema de variáveis e os módulos do Terraform resolvem isso.
Antes, a gente criou o arquivo variables.tf. Agora você pode mover os valores, que antes estavam codificados em main.tf, para esse novo arquivo que vai ter nossas variáveis:
variable "aws_region" {
description = "AWS region for resources"
type = string
default = "eu-central-1"
}
variable "instance_type" {
description = "EC2 instance type"
type = string
default = "t2.micro"
}Agora, faça referência às variáveis nos seus recursos no arquivo main.tf:
provider "aws" {
region = var.aws_region
}
resource "aws_instance" "web_server" {
instance_type = var.instance_type
# ... rest of configuration
tags = {
Environment = var.environment
}
}Lembre-se de que os buckets do AWS S3 são únicos, então você não pode usar variáveis na região no parâmetro backend de main.tf. Aqui, você precisa manter sua região codificada como “eu-central-1” em vez de var.region_aws.
Agora que nossas variáveis foram definidas, você também pode definir diferentes ambientes, como desenvolvimento ou produção, onde as variáveis podem ser diferentes. Isso é feito criando novos arquivos com a extensão .tfvars.
Por exemplo, você pode criar um terraform-dev.tfvars para desenvolvimento e um terraform-prod.tfvars para produção:
Desenvolvimento:
aws_region = "eu-central-1"
instance_type = "t2.micro"Produção:
aws_region = "eu-central-1"
instance_type = "t3.medium"Depois, você pode implantar nos diferentes ambientes especificando o arquivo apropriado:
terraform apply -var-file="terraform-dev.tfvars”As variáveis resolvem o problema dos valores específicos do ambiente, mas e quanto à duplicação de padrões inteiros de infraestrutura? É aí que os módulos se tornam essenciais.
Os módulos juntam recursos em componentes que podem ser usados de novo. A melhor maneira de usar os módulos é criando uma pasta específica. Por exemplo, você pode criar uma estrutura de diretórios assim:
modules/
ec2-with-ssm/
main.tf
variables.tf
outputs.tfVocê pode mover o arquivo variables.tf criado anteriormente (ou criar um novo) para a pasta do módulo. A principal alteração ocorre no arquivo main.tf. O que está no módulo deve conter nossos recursos. Então, tudo, desde o AMI até o final do arquivo, deve ser movido para lá:
data "aws_ami" "amazon_linux" {
most_recent = true
filter {
name = "name"
values = ["amzn2-ami-hvm-*-x86_64-gp2"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["amazon"]
}
resource "aws_instance" "web_server" {
ami = data.aws_ami.amazon_linux.id
instance_type = var.instance_type
iam_instance_profile = aws_iam_instance_profile.ssm_profile.name
user_data = <<-EOF
#!/bin/bash
cd /tmp
sudo yum install -y https://s3.amazonaws.com/ec2-downloads-windows/SSMAgent/latest/linux_amd64/amazon-ssm-agent.rpm
sudo systemctl enable amazon-ssm-agent
sudo systemctl start amazon-ssm-agent
EOF
tags = {
Name = "TerraformWebServer"
}
}
resource "aws_iam_instance_profile" "ssm_profile" {
name = "ec2-ssm-profile"
role = aws_iam_role.ssm_role.name
}
resource "aws_iam_role" "ssm_role" {
name = "ec2-ssm-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}]
})
}
resource "aws_iam_role_policy_attachment" "ssm_policy" {
role = aws_iam_role.ssm_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore"
}Para substituir essa alteração, você mantém o resto do arquivo, mas adiciona um parâmetro de módulo que se refere ao módulo específico.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 6.0"
}
}
backend "s3" {
bucket = "datacamp-terraform-state"
key = "terraform.tfstate"
region = "eu-central-1"
use_lockfile = true
}
}
provider "aws" {
region = var.aws_region
}
module "web_server" {
source = "./modules/ec2-with-ssm"
instance_type = var.instance_type
}Agora, se você rodar os comandos init, plan e apply com essas configurações, vai acabar implantando os mesmos recursos de antes. A diferença é que os módulos permitem que você inicie uma infraestrutura com configurações parecidas que podem ser reutilizadas. Eles são essenciais para expandir o Terraform além de projetos simples.
Agora vamos passar para outro assunto importante: segurança.
O código da infraestrutura precisa ter o mesmo rigor de segurança que o código da aplicação. Então, é super importante proteger suas implantações do Terraform.
Nunca coloque segredos no Git. Sempre. Use o AWS Secrets Manager para valores confidenciais. Você pode usar o seguinte recurso no Terraform para fazer isso:
resource "aws_secretsmanager_secret" "example" {
name = "example"
}Para segredos específicos do ambiente, você pode usar variáveis de ambiente com o prefixo TF_VAR_.
Por exemplo, você pode usar variable "aws_access_key" {} no arquivo variables.tf e exportá-lo no terminal com export TF_VAR_aws_access_key=. O Terraform carrega automaticamente esses valores como variáveis, sem mostrá-los no código.
Outro assunto importante sobre configuração é o desvio. Isso rola quando alguém mexe na infraestrutura pelo Console ou CLI da AWS, sem passar pelo Terraform. Execute regularmente o comando ` terraform plan ` para detectar desvios. A saída do plano mostra os recursos que existem, mas não combinam com a sua configuração.
Quando rola um desvio, você tem duas opções: atualizar seu código Terraform pra ficar igual à realidade ou rodar um terraform apply pra forçar a infraestrutura a voltar pro estado desejado. A escolha certa depende se a mudança manual foi de propósito.
Por fim, também é importante remover todos os recursos assim que soubermos que não precisamos mais deles, para evitar custos desnecessários. Você pode limpar os recursos com o seguinte comando:
terraform destroyDá uma olhada no plano de destruição com cuidado. O Terraform vai apagar todos os recursos que criou. Para produção, pense em usar terraform destroy -target para tirar recursos específicos em vez de tudo.
Você aprendeu o fluxo de trabalho principal do Terraform: definir a infraestrutura em código, visualizar as alterações com o comando ` plan`, aplicá-las com o comando ` apply` e acompanhar tudo com o gerenciamento de estado. Falamos sobre a implantação do EC2 com instalação automática de agentes, transferimos o estado para o S3 com bloqueio nativo, escalamos com variáveis e módulos e protegemos a infraestrutura com gerenciamento de segredos.
Trate o código da infraestrutura com o mesmo cuidado que o código do aplicativo. Use controle de versão, peça revisões de código para alterações e teste primeiro em ambientes que não sejam de produção. Os pipelines de CI/CD podem automatizar o terraform apply, tornando as atualizações de infraestrutura tão fáceis quanto as implantações de aplicativos.
Seu próximo passo: dá uma olhada no GitHub Actions ou no GitLab CI pra rodar o Terraform automaticamente quando você enviar o código. Essa abordagem de Infraestrutura como Código, junto com a automação, muda a forma como as equipes cuidam dos recursos na nuvem, trocando o trabalho manual no console por uma infraestrutura confiável, repetível e com controle de versão.
Minha dica é aproveitar esse conhecimento e se inscrever no curso AWS Cloud Practitioner (CLF-C02) , que oferece um programa completo que ensina tudo o que você precisa saber para obter a certificação CLF-C02 da Amazon.
Cursos AWS
Programa
Curso
Curso
blog
Srujana Maddula
13 min
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita
Tutorial
Tim Lu
Tutorial
Bex Tuychiev
Tutorial
Zoumana Keita