Apprentissage automatique pour les données de séries temporelles en Python
44.5K learners
Les techniques de classification sont un élément essentiel des applications d'apprentissage automatique et d'exploration de données. Environ 70 % des problèmes liés à la science des données sont des problèmes de classification. Il existe de nombreux problèmes de classification, mais la régression logistique est courante et constitue une méthode de régression utile pour résoudre le problème de la classification binaire. Une autre catégorie de classification est la classification multinomiale, qui traite les problèmes liés à la présence de plusieurs classes dans la variable cible. Par exemple, l'ensemble de données IRIS est un exemple très célèbre de classification multi-classes. D'autres exemples sont la classification des catégories d'articles/blogs/documents.
La régression logistique peut être utilisée pour divers problèmes de classification, tels que la détection de spam. Parmi d'autres exemples, citons : la prédiction du diabète, la question de savoir si un client donné achètera un produit particulier ; la question de savoir si un client se désabonnera ou non, si l'utilisateur cliquera ou non sur un lien publicitaire donné, et bien d'autres exemples encore.
La régression logistique est l'un des algorithmes d'apprentissage automatique les plus simples et les plus couramment utilisés pour la classification en deux classes. Il est facile à mettre en œuvre et peut être utilisé comme base de référence pour tout problème de classification binaire. Ses concepts fondamentaux sont également constructifs dans l'apprentissage profond. La régression logistique décrit et estime la relation entre une variable binaire dépendante et des variables indépendantes.
Pour exécuter facilement vous-même tous les exemples de code de ce tutoriel, vous pouvez créer gratuitement un classeur DataLab dans lequel Python est préinstallé et qui contient tous les exemples de code. Pour plus de pratique sur la régression logistique, consultez les exercices de notre cours Modélisation du risque de crédit en R, qui contient de nombreux exemples du monde réel.
La régression logistique est une méthode statistique permettant de prédire des classes binaires. Le résultat ou la variable cible est de nature dichotomique. Dichotomique signifie qu'il n'y a que deux classes possibles. Par exemple, elle peut être utilisée pour les problèmes de détection du cancer. Il calcule la probabilité qu'un événement se produise.
Il s'agit d'un cas particulier de régression linéaire où la variable cible est de nature catégorielle. Il utilise le logarithme des chances comme variable dépendante. La régression logistique prédit la probabilité d'occurrence d'un événement binaire à l'aide d'une fonction logit.
Équation de régression linéaire :
![]()
Où y est une variable dépendante et x1, x2 ... et Xn sont des variables explicatives.
Sigmoïde Fonction :
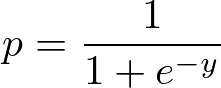
Appliquez la fonction Sigmoïde à la régression linéaire :
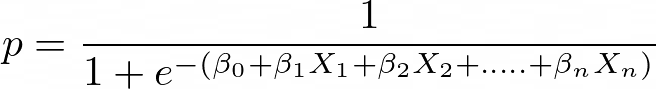
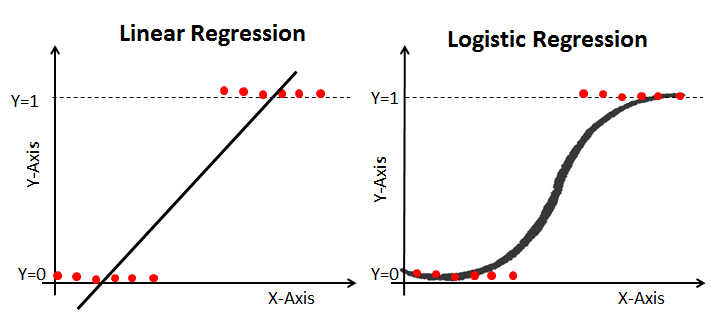
Propriétés de la régression logistique :
La régression linéaire vous donne un résultat continu, alors que la régression logistique vous donne un résultat constant. Le prix de l'immobilier et le cours des actions sont des exemples de résultats continus. Parmi les exemples de résultats discrets, citons la prédiction de l'existence ou non d'un cancer chez un patient et la prédiction de l'attrition d'un client. La régression logistique est estimée à l'aide de l'approche d'estimation du maximum de vraisemblance (MLE), tandis que la régression linéaire est généralement estimée à l'aide des moindres carrés ordinaires (MCO), qui peuvent également être considérés comme un cas spécial de MLE lorsque les erreurs du modèle sont normalement distribuées.
La MLE est une méthode de maximisation de la "vraisemblance", tandis que les MCO sont une méthode d'approximation par minimisation de la distance. La maximisation de la fonction de vraisemblance permet de déterminer les paramètres les plus susceptibles de produire les données observées. D'un point de vue statistique, la MLE définit la moyenne et la variance comme des paramètres dans la détermination des valeurs paramétriques spécifiques pour un modèle donné. Cet ensemble de paramètres peut être utilisé pour prédire les données nécessaires à une distribution normale.
Les estimations des moindres carrés ordinaires sont calculées en ajustant une ligne de régression sur des points de données donnés qui présente la somme minimale des écarts quadratiques (erreur des moindres carrés). Les deux sont utilisés pour estimer les paramètres d'un modèle de régression linéaire. La MLE suppose une fonction de masse de probabilité conjointe, tandis que les MCO ne nécessitent aucune hypothèse stochastique pour minimiser la distance.
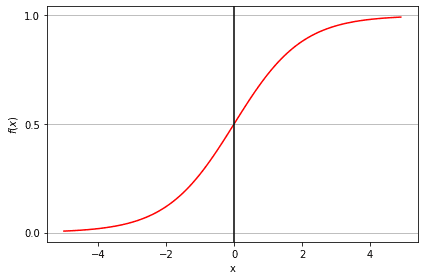
La fonction sigmoïde, également appelée fonction logistique, donne une courbe en forme de "S" qui peut prendre n'importe quel nombre réel et le convertir en une valeur comprise entre 0 et 1. Si la courbe va jusqu'à l'infini positif, y prédit deviendra 1, et si la courbe va jusqu'à l'infini négatif, y prédit deviendra 0. Si la sortie de la fonction sigmoïde est supérieure à 0,5, nous pouvons classer le résultat comme 1 ou OUI, et si elle est inférieure à 0,5, nous pouvons le classer comme 0 ou NON. Par exemple, si le résultat est 0,75, nous pouvons dire en termes de probabilité qu'il y a 75 % de chances qu'un patient soit atteint d'un cancer.

Types de régression logistique :
Construisons le modèle de prédiction du diabète à l'aide d'un classificateur de régression logistique.
Commençons par charger le jeu de données Pima Indian Diabetes requis à l'aide de la fonction read CSV de pandas. Vous pouvez télécharger les données à partir du lien suivant : https://www.kaggle.com/uciml/pima-indians-diabetes-database ou sélectionner un ensemble de données à partir de DataCamp : https://www.datacamp.com/datalab/datasets. Le jeu de données prêt à l'emploi vous offre la possibilité d'entraîner le modèle sur DataLab, le carnet Jupyter gratuit de DataCamp sur le cloud.
Nous allons simplifier les colonnes en fournissant col_names à la fonction pandas read_csv().
#import pandas
import pandas as pd
col_names = ['pregnant', 'glucose', 'bp', 'skin', 'insulin', 'bmi', 'pedigree', 'age', 'label']
# load dataset
pima = pd.read_csv("pima-indians-diabetes.csv", header=None, names=col_names)pima.head()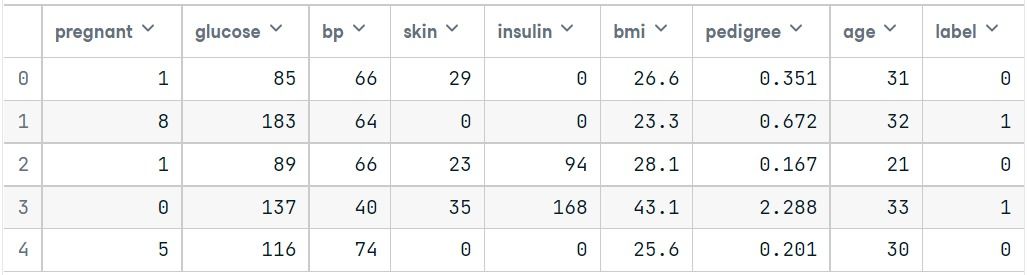
Ici, vous devez diviser les colonnes données en deux types de variables : la variable dépendante (ou variable cible) et la variable indépendante (ou variable caractéristique).
#split dataset in features and target variable
feature_cols = ['pregnant', 'insulin', 'bmi', 'age','glucose','bp','pedigree']
X = pima[feature_cols] # Features
y = pima.label # Target variablePour comprendre les performances d'un modèle, la division de l'ensemble de données en un ensemble d'apprentissage et un ensemble de test est une bonne stratégie.
Divisons l'ensemble de données en utilisant la fonction train_test_split(). Vous devez passer 3 paramètres : features, target, et test_set size. En outre, vous pouvez utiliser random_state pour sélectionner des enregistrements de manière aléatoire.
# split X and y into training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=16)Ici, l'ensemble de données est divisé en deux parties dans un rapport de 75:25. Cela signifie que 75 % des données seront utilisées pour l'apprentissage du modèle et 25 % pour le test du modèle.
Tout d'abord, importez le module LogisticRegression et créez un objet classificateur de régression logistique en utilisant la fonction LogisticRegression() avec random_state pour la reproductibilité.
Ensuite, ajustez votre modèle sur l'ensemble de formation à l'aide de fit() et effectuez la prédiction sur l'ensemble de test à l'aide de predict().
# import the class
from sklearn.linear_model import LogisticRegression
# instantiate the model (using the default parameters)
logreg = LogisticRegression(random_state=16)
# fit the model with data
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)Une matrice de confusion est un tableau utilisé pour évaluer les performances d'un modèle de classification. Vous pouvez également visualiser les performances d'un algorithme. La partie fondamentale d'une matrice de confusion est le nombre de prédictions correctes et incorrectes additionnées par classe.
# import the metrics class
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
cnf_matrixarray([[115, 8],
[ 30, 39]])Ici, vous pouvez voir la matrice de confusion sous la forme d'un tableau. La dimension de cette matrice est de 2*2 car ce modèle est une classification binaire. Vous avez deux classes 0 et 1. Les valeurs diagonales représentent des prédictions exactes, tandis que les éléments non diagonaux représentent des prédictions inexactes. Dans le résultat, 115 et 39 sont des prédictions réelles, et 30 et 8 sont des prédictions incorrectes.
Visualisons les résultats du modèle sous la forme d'une matrice de confusion à l'aide de matplotlib et de seaborn.
Ici, vous allez visualiser la matrice de confusion à l'aide d'une carte thermique.
# import required modules
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
class_names=[0,1] # name of classes
fig, ax = plt.subplots()
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names)
plt.yticks(tick_marks, class_names)
# create heatmap
sns.heatmap(pd.DataFrame(cnf_matrix), annot=True, cmap="YlGnBu" ,fmt='g')
ax.xaxis.set_label_position("top")
plt.tight_layout()
plt.title('Confusion matrix', y=1.1)
plt.ylabel('Actual label')
plt.xlabel('Predicted label')
Text(0.5,257.44,'Predicted label');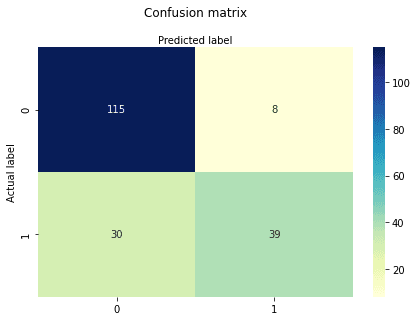
Évaluons le modèle à l'aide de classification_report pour l'exactitude, la précision et le rappel.
from sklearn.metrics import classification_report
target_names = ['without diabetes', 'with diabetes']
print(classification_report(y_test, y_pred, target_names=target_names)) precision recall f1-score support
without diabetes 0.79 0.93 0.86 123
with diabetes 0.83 0.57 0.67 69
accuracy 0.80 192
macro avg 0.81 0.75 0.77 192
weighted avg 0.81 0.80 0.79 192Vous avez obtenu un taux de classification de 80 %, ce qui est considéré comme une bonne précision.
Précision: La précision concerne la précision, c'est-à-dire le degré d'exactitude de votre modèle. En d'autres termes, vous pouvez dire, lorsqu'un modèle fait une prédiction, à quelle fréquence il est correct. Dans votre cas de prédiction, lorsque votre modèle de régression logistique prédit que les patients vont souffrir de diabète, ces patients sont atteints dans 73 % des cas.
Rappel: Si l'ensemble de test contient des patients atteints de diabète et que votre modèle de régression logistique peut l'identifier dans 57 % des cas.
La courbe ROC (Receiver Operating Characteristic) est une représentation graphique du taux de vrais positifs par rapport au taux de faux positifs. Il montre le compromis entre la sensibilité et la spécificité.
y_pred_proba = logreg.predict_proba(X_test)[::,1]
fpr, tpr, _ = metrics.roc_curve(y_test, y_pred_proba)
auc = metrics.roc_auc_score(y_test, y_pred_proba)
plt.plot(fpr,tpr,label="data 1, auc="+str(auc))
plt.legend(loc=4)
plt.show()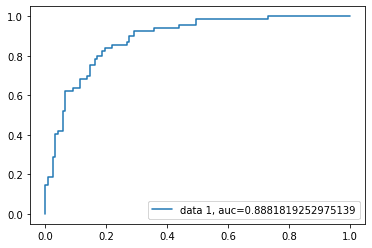
Le score AUC pour ce cas est de 0,88. Le score AUC de 1 représente un classificateur parfait, et celui de 0,5 un classificateur sans valeur.
Le code source est disponible sur DataLab : Comprendre la régression logistique en Python.
En raison de son efficacité et de sa simplicité, il ne nécessite pas une grande puissance de calcul, est facile à mettre en œuvre et à interpréter, et est largement utilisé par les analystes de données et les scientifiques. En outre, il n'est pas nécessaire de modifier les caractéristiques. La régression logistique fournit un score de probabilité pour les observations.
La régression logistique n'est pas en mesure de traiter un grand nombre de caractéristiques/variables catégorielles. Il est vulnérable à l'ajustement excessif. En outre, il ne peut pas résoudre les problèmes non linéaires, c'est pourquoi il nécessite une transformation des caractéristiques non linéaires. La régression logistique ne donne pas de bons résultats avec des variables indépendantes qui ne sont pas corrélées à la variable cible et qui sont très similaires ou corrélées entre elles.
Dans ce tutoriel, vous avez abordé de nombreux détails sur la régression logistique. Vous avez appris ce qu'est la régression logistique, comment construire les modèles correspondants, comment visualiser les résultats et quelques informations théoriques de base. Vous avez également abordé des concepts de base tels que la fonction sigmoïde, le maximum de vraisemblance, la matrice de confusion, la courbe ROC.
Nous espérons que vous pouvez maintenant utiliser la technique de régression logistique pour analyser vos propres ensembles de données. Merci d'avoir lu ce tutoriel !
Si vous souhaitez en savoir plus sur la régression logistique, suivez le cours Machine Learning with scikit-learn de DataCamp. Vous pouvez également commencer votre parcours pour devenir ingénieur en apprentissage automatique en vous inscrivant au cursus Machine Learning Scientist with Python.
Cours de régression Python
Cours
Cours
Tutoriel
Laiba Siddiqui
Tutoriel
Abid Ali Awan
Tutoriel
Sejal Jaiswal
Tutoriel
Allan Ouko
Tutoriel
Mark Pedigo
Tutoriel
Aditya Sharma

