
Cours
Concepts des grands modèles de langage (LLM)
2 h
99.8K
Les transformateurs ont d'abord été développés pour résoudre le problème de la transduction de séquences, ou traduction automatique neuronale, ce qui signifie qu'ils sont destinés à résoudre toute tâche qui transforme une séquence d'entrée en une séquence de sortie. C'est pourquoi on les appelle "Transformers".
Mais commençons par le début.
Un modèle de transformateur est un réseau neuronal qui apprend le contexte des données séquentielles et génère de nouvelles données à partir de celui-ci.
Pour faire simple :
Un transformateur est un type de modèle d'intelligence artificielle qui apprend à comprendre et à générer des textes de type humain en analysant des modèles dans de grandes quantités de données textuelles.
Les transformateurs constituent un modèle NLP de pointe et sont considérés comme l'évolution de l'architecture codeur-décodeur. Cependant, alors que l'architecture codeur-décodeur repose principalement sur des réseaux neuronaux récurrents (RNN) pour extraire des informations séquentielles, les transformateurs sont totalement dépourvus de cette récurrence.
Alors, comment font-ils ?
Ils sont spécifiquement conçus pour comprendre le contexte et le sens en analysant la relation entre différents éléments, et ils s'appuient presque entièrement sur une technique mathématique appelée attention pour ce faire.

Image de l'auteur.
Issus d'un article de recherche publié en 2017 par Google, les modèles de transformateurs constituent l'un des développements les plus récents et les plus influents dans le domaine de l'apprentissage automatique. Le premier modèle de transformateur a été expliqué dans l'article influent "Attention is All You Need.
Ce concept pionnier n'était pas seulement une avancée théorique, il a également trouvé une application pratique, notamment dans le package Tensor2Tensor de TensorFlow. En outre, le groupe NLP de Harvard a contribué à ce domaine en plein essor en proposant un guide annoté de l'article, complété par une implémentation PyTorch. Vous pouvez en apprendre davantage sur la façon de mettre en œuvre un transformateur à partir de zéro dans notre tutoriel séparé.
Leur introduction a suscité un essor considérable dans ce domaine, souvent appelé "Transformer AI". Ce modèle révolutionnaire a jeté les bases des percées ultérieures dans le domaine des grands modèles de langage, y compris l'ORET. En 2018, ces développements étaient déjà considérés comme un moment décisif pour la PNL.
En 2020, les chercheurs de l'OpenAI ont annoncé le GPT-3. En quelques semaines, la polyvalence du GPT-3 a été rapidement démontrée lorsque des personnes l'ont utilisé pour créer des poèmes, des programmes, des chansons, des sites web et bien d'autres choses encore, captivant l'imagination des utilisateurs du monde entier.
Dans un document datant de 2021, des universitaires de Stanford ont judicieusement appelé ces innovations " modèles de fondation", soulignant leur rôle fondamental dans la refonte de l'IA. Leurs travaux mettent en évidence la manière dont les modèles de transformateurs ont non seulement révolutionné le domaine, mais aussi repoussé les frontières de ce qui est réalisable en matière d'intelligence artificielle, annonçant ainsi une nouvelle ère de possibilités.
"Nous sommes à une époque où des méthodes simples comme les réseaux neuronaux nous offrent une explosion de nouvelles capacités", a déclaréAshish Vaswani, entrepreneur et ancien chercheur principal chez Google.
Au moment de l'introduction du modèle Transformer, les RNN étaient l'approche privilégiée pour traiter les données séquentielles, qui se caractérisent par un ordre spécifique dans leur entrée.
Les RNN fonctionnent de la même manière qu'un réseau neuronal feed-forward, mais traitent l'entrée de manière séquentielle, un élément à la fois.
Les transformateurs ont été inspirés par l'architecture codeur-décodeur que l'on trouve dans les RNN. Cependant, au lieu d'utiliser la récurrence, le modèle Transformer est entièrement basé sur le mécanisme d'attention.
Outre l'amélioration des performances des RNN, les transformateurs ont fourni une nouvelle architecture pour résoudre de nombreuses autres tâches, telles que le résumé de texte, le sous-titrage d'images et la reconnaissance vocale.
Quels sont donc les principaux problèmes des RNN ? Ils sont inefficaces pour les tâches de la PNL pour deux raisons principales :
Le passage des réseaux neuronaux récurrents (RNN) tels que LSTM à Transformers dans le domaine du NLP est motivé par ces deux problèmes principaux et par la capacité de Transformers à les évaluer tous deux en tirant parti des améliorations du mécanisme d'attention :
Les transformateurs sont donc devenus une amélioration naturelle des RNN.
Voyons maintenant comment fonctionnent les transformateurs.
Conçus à l'origine pour la transduction de séquences ou la traduction automatique neuronale, les transformateurs excellent dans la conversion de séquences d'entrée en séquences de sortie. Il s'agit du premier modèle de transduction reposant entièrement sur l'auto-attention pour calculer les représentations de son entrée et de sa sortie sans utiliser de RNN alignés sur la séquence ou de convolution. La principale caractéristique de l'architecture Transformers est qu'elle conserve le modèle codeur-décodeur.
Si nous commençons à considérer un transformateur pour la traduction linguistique comme une simple boîte noire, il prendrait une phrase dans une langue, l'anglais par exemple, en entrée et produirait sa traduction en anglais.

Image de l'auteur.
Si nous plongeons un peu, nous constatons que cette boîte noire est composée de deux parties principales :
Image de l'auteur. Structure globale du codeur-décodeur.
Cependant, le codeur et le décodeur sont en fait une pile avec plusieurs couches (même nombre pour chacune). Tous les encodeurs présentent la même structure, et l'entrée entre dans chacun d'entre eux et est transmise au suivant. Tous les décodeurs présentent également la même structure et reçoivent l'entrée du dernier codeur et du décodeur précédent.
L'architecture originale comprenait 6 encodeurs et 6 décodeurs, mais nous pouvons reproduire autant de couches que nous le souhaitons. Supposons donc qu'il y ait N couches de chaque.
Image de l'auteur. Structure globale du codeur-décodeur. Plusieurs couches.
Maintenant que nous avons une idée générale de l'architecture globale du transformateur, concentrons-nous sur les encodeurs et les décodeurs afin de mieux comprendre leur fonctionnement :
Le codeur est un élément fondamental de l'architecture du transformateur. La fonction première de l'encodeur est de transformer les mots d'entrée en représentations contextualisées. Contrairement aux modèles précédents qui traitaient les mots indépendamment les uns des autres, le codeur Transformer capture le contexte de chaque mot par rapport à l'ensemble de la séquence.
Sa structure se compose comme suit :
Image de l'auteur. Structure globale des codeurs.
Décomposons donc son flux de travail en ses étapes les plus élémentaires :
L'intégration n'a lieu que dans l'encodeur le plus bas. Le codeur commence par convertir les jetons d'entrée - mots ou sous-mots - en vecteurs à l'aide de couches d'intégration. Ces encastrements capturent la signification sémantique des tokens et les convertissent en vecteurs numériques.
Tous les codeurs reçoivent une liste de vecteurs, chacun d'une taille de 512 (taille fixe). Dans le codeur du bas, il s'agirait des enchâssements de mots, mais dans les autres codeurs, il s'agirait de la sortie du codeur qui se trouve directement en dessous.
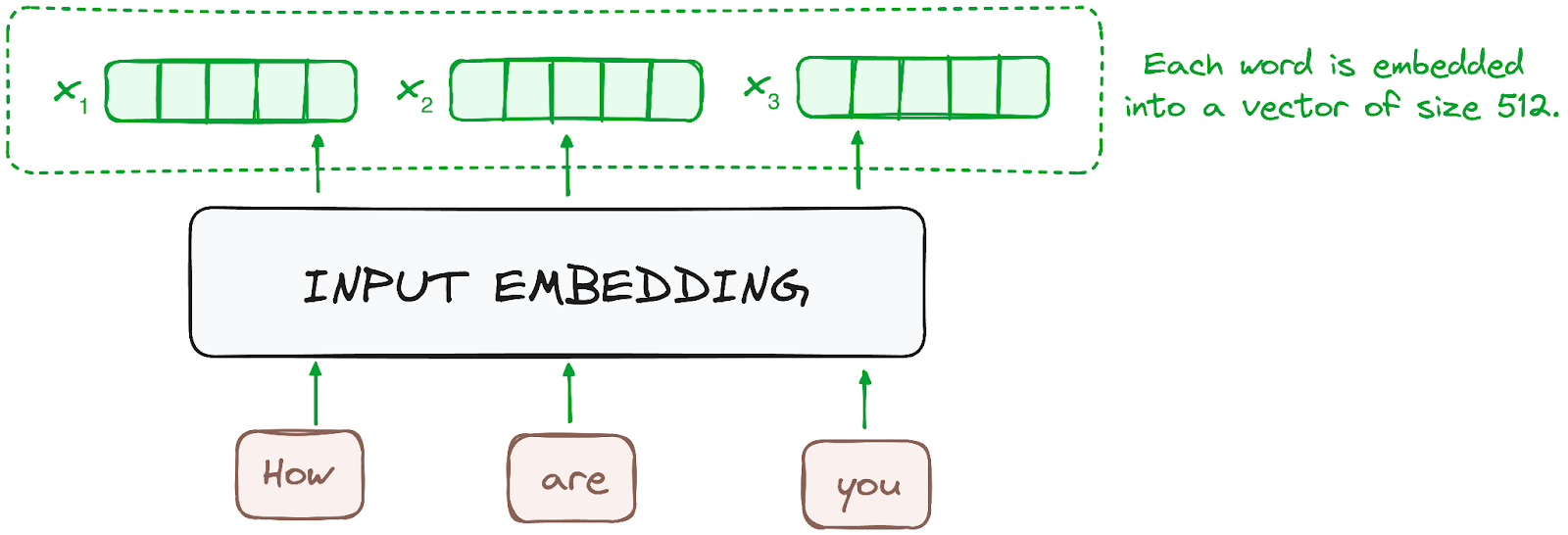
Image de l'auteur. Flux de travail de l'encodeur. Intégration des données.
Comme les transformateurs ne disposent pas d'un mécanisme de récurrence comme les RNN, ils utilisent des encodages positionnels ajoutés aux encodages d'entrée pour fournir des informations sur la position de chaque token dans la séquence. Cela leur permet de comprendre la position de chaque mot dans la phrase.
Pour ce faire, les chercheurs ont proposé d'utiliser une combinaison de diverses fonctions sinus et cosinus pour créer des vecteurs de position, ce qui permet d'utiliser ce codeur de position pour des phrases de n'importe quelle longueur.
Dans cette approche, chaque dimension est représentée par des fréquences et des décalages uniques de l'onde, les valeurs allant de -1 à 1, représentant effectivement chaque position.
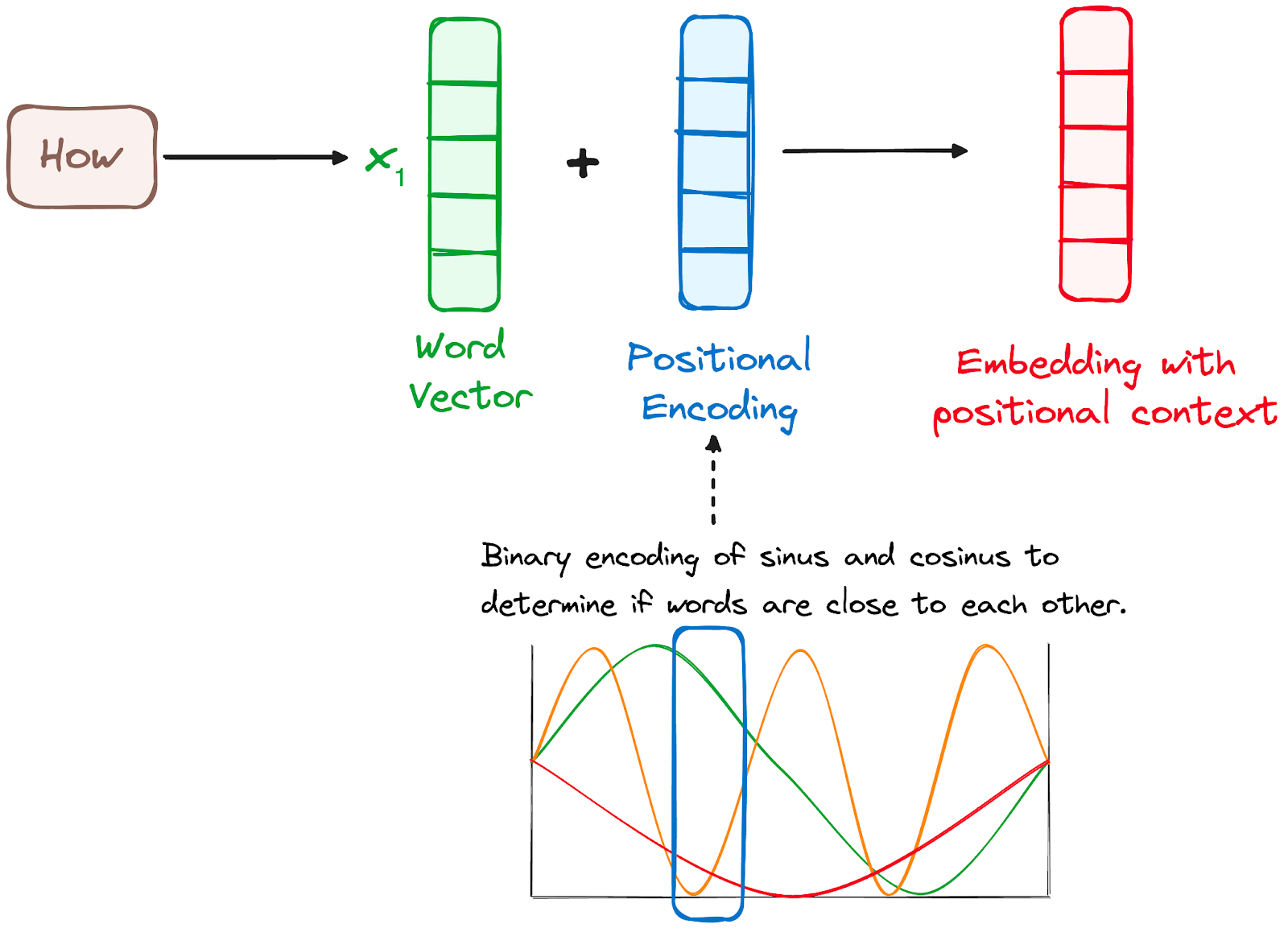
Image de l'auteur. Flux de travail de l'encodeur. Codage positionnel.
Le codeur Transformer est constitué d'une pile de couches identiques (6 dans le modèle Transformer original).
La couche d'encodage sert à transformer toutes les séquences d'entrée en une représentation continue et abstraite qui encapsule les informations apprises de l'ensemble de la séquence. Cette couche comprend deux sous-modules :
En outre, il incorpore les connexions résiduelles autour de chaque sous-couche, qui sont ensuite suivies d'une normalisation de la couche.
Image de l'auteur. Flux de travail de l'encodeur. Pile de couches de l'encodeur
Dans l'encodeur, l'attention à plusieurs têtes utilise un mécanisme d'attention spécialisé connu sous le nom d'auto-attention. Cette approche permet aux modèles de relier chaque mot de l'entrée à d'autres mots. Par exemple, dans un exemple donné, le modèle peut apprendre à relier le mot "sont" à "vous".
Ce mécanisme permet au codeur de se concentrer sur différentes parties de la séquence d'entrée lorsqu'il traite chaque jeton. Il calcule des scores d'attention basés sur :
Ce premier module d'auto-attention permet au modèle de capturer les informations contextuelles de l'ensemble de la séquence. Au lieu d'exécuter une seule fonction d'attention, les requêtes, les clés et les valeurs sont projetées linéairement h fois. Sur chacune de ces versions projetées des requêtes, des clés et des valeurs, le mécanisme d'attention est exécuté en parallèle, produisant des valeurs de sortie h-dimensionnelles.
L'architecture détaillée est la suivante :
Une fois que les vecteurs de requête, de clé et de valeur sont passés par une couche linéaire, une multiplication matricielle du produit point est effectuée entre les requêtes et les clés, ce qui aboutit à la création d'une matrice de score.
La matrice de score établit le degré d'importance que chaque mot doit accorder aux autres mots. Par conséquent, chaque mot se voit attribuer un score par rapport aux autres mots au cours du même pas de temps. Un score plus élevé indique une plus grande concentration.
Ce processus permet d'associer les requêtes aux clés correspondantes.
Image de l'auteur. Flux de travail de l'encodeur. Mécanisme d'attention - Multiplication des matrices.
Les scores sont ensuite réduits en les divisant par la racine carrée de la dimension des vecteurs de requête et de clé. Cette étape est mise en œuvre pour garantir des gradients plus stables, car la multiplication des valeurs peut entraîner des effets trop importants.
Image de l'auteur. Flux de travail de l'encodeur. Réduire les scores d'attention.
Ensuite, une fonction softmax est appliquée aux scores ajustés pour obtenir les poids d'attention. Il en résulte des valeurs de probabilité comprises entre 0 et 1. La fonction softmax met l'accent sur les scores les plus élevés tout en diminuant les scores les plus faibles, améliorant ainsi la capacité du modèle à déterminer efficacement les mots qui devraient faire l'objet d'une plus grande attention.
Image de l'auteur. Flux de travail de l'encodeur. Les scores ajustés de Softmax.
L'étape suivante du mécanisme d'attention consiste à multiplier les poids dérivés de la fonction softmax par le vecteur de valeurs, ce qui permet d'obtenir un vecteur de sortie.
Dans ce processus, seuls les mots qui présentent des scores softmax élevés sont conservés. Enfin, ce vecteur de sortie est introduit dans une couche linéaire pour un traitement ultérieur.
Image de l'auteur. Flux de travail de l'encodeur. Combinaison des résultats de Softmax avec le vecteur de valeurs.
Nous obtenons enfin la sortie du mécanisme d'attention !
Vous vous demandez peut-être pourquoi on parle d'attention à plusieurs têtes ?
Rappelez-vous qu'avant que tout le processus ne commence, nous décomposons nos requêtes, nos clés et nos valeurs cinq fois. Ce processus, connu sous le nom d'attention à soi, se déroule séparément dans chacune de ces petites étapes ou "têtes". Chaque tête opère sa magie de manière indépendante, en produisant un vecteur de sortie.
Cet ensemble passe par une dernière couche linéaire, un peu comme un filtre qui affine leur performance collective. La beauté de la chose réside dans la diversité de l'apprentissage pour chaque tête, qui enrichit le modèle de codage d'une compréhension robuste et multiforme.
Chaque sous-couche d'une couche de codage est suivie d'une étape de normalisation. En outre, la sortie de chaque sous-couche est ajoutée à son entrée (connexion résiduelle) afin d'atténuer le problème du gradient qui s'évanouit, ce qui permet d'obtenir des modèles plus profonds. Ce processus sera également répété pour le réseau neuronal Feed-Forward.
Image de l'auteur. Flux de travail de l'encodeur. Normalisation et connexion résiduelle après l'attention à plusieurs têtes.
Le parcours de la sortie résiduelle normalisée se poursuit à travers un réseau d'anticipation ponctuel, une phase cruciale pour un raffinement supplémentaire.
Imaginez ce réseau comme un duo de couches linéaires, avec une activation ReLU nichée entre les deux, jouant le rôle de pont. Une fois traitée, la sortie emprunte un chemin familier : elle revient en boucle et fusionne avec l'entrée du réseau à progression ponctuelle.
Ces retrouvailles sont suivies d'un nouveau cycle de normalisation, qui permet de s'assurer que tout est bien ajusté et synchronisé pour les étapes suivantes.
Image de l'auteur. Flux de travail de l'encodeur. Sous-couche du réseau neuronal Feed-Forward.
La sortie de la dernière couche de codage est un ensemble de vecteurs, chacun représentant la séquence d'entrée avec une compréhension contextuelle riche. Cette sortie est ensuite utilisée comme entrée pour le décodeur dans un modèle de transformateur.
Ce codage minutieux ouvre la voie au décodeur, en le guidant pour qu'il prête attention aux bons mots de l'entrée au moment du décodage.
Imaginez que vous construisiez une tour, où vous pouvez empiler N couches d'encodeurs. Chaque couche de cette pile a la possibilité d'explorer et d'apprendre différentes facettes de l'attention, un peu comme des couches de connaissances. Cela permet non seulement de diversifier les connaissances, mais aussi d'accroître considérablement les capacités de prévision du réseau de transformateurs.
Le rôle du décodeur est centré sur l'élaboration de séquences de texte. À l'image du codeur, le décodeur est équipé d'un ensemble similaire de sous-couches. Il comporte deux couches d'attention à têtes multiples, une couche d'anticipation ponctuelle et incorpore à la fois des connexions résiduelles et une normalisation des couches après chaque sous-couche.
Image de l'auteur. Structure globale des codeurs.
Ces composants fonctionnent de la même manière que les couches du codeur, mais avec une particularité : chaque couche d'attention à plusieurs têtes dans le décodeur a sa propre mission.
Le processus final du décodeur comprend une couche linéaire, qui sert de classificateur, complétée par une fonction softmax pour calculer les probabilités des différents mots.
Le décodeur Transformer possède une structure spécialement conçue pour générer cette sortie en décodant l'information codée étape par étape.
Il est important de noter que le décodeur fonctionne de manière autorégressive, en démarrant son processus avec un jeton de départ. Il utilise astucieusement une liste de sorties précédemment générées comme entrées, en tandem avec les sorties de l'encodeur qui sont riches en informations sur l'attention à partir de l'entrée initiale.
Cette danse séquentielle du décodage se poursuit jusqu'à ce que le décodeur atteigne un moment charnière : la génération d'un jeton qui signale la fin de sa création de sortie.
Sur la ligne de départ du décodeur, le processus reflète celui du codeur. Ici, l'entrée passe d'abord par une couche d'intégration
Après l'intégration, comme pour le décodeur, l'entrée passe par la couche d'encodage positionnel. Cette séquence a pour but de produire des enchâssements positionnels.
Ces enregistrements positionnels sont ensuite acheminés vers la première couche d'attention multi-têtes du décodeur, où les scores d'attention spécifiques à l'entrée du décodeur sont méticuleusement calculés.
Le décodeur se compose d'une pile de couches identiques (6 dans le modèle original du transformateur). Chaque couche comporte trois sous-composants principaux :
Ce mécanisme est similaire au mécanisme d'auto-attention de l'encodeur, mais avec une différence cruciale : il empêche les positions d'être attentives aux positions suivantes, ce qui signifie que chaque mot de la séquence n'est pas influencé par les tokens à venir.
Par exemple, lorsque les scores d'attention pour le mot "sont" sont calculés, il est important que "sont" ne jette pas un coup d'œil sur "vous", qui est un mot suivant dans la séquence.
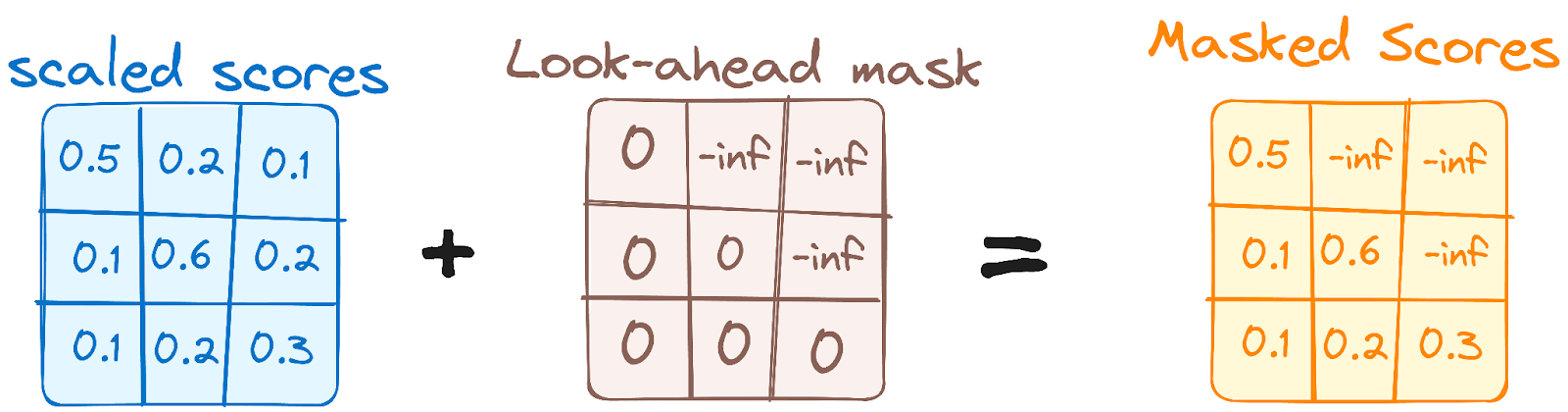
Image de l'auteur. Flux de travail du décodeur. Premier masque d'attention à plusieurs têtes.
Ce masquage garantit que les prédictions pour une position particulière ne peuvent dépendre que des résultats connus pour les positions précédentes.
Dans la deuxième couche d'attention à plusieurs têtes du décodeur, nous observons une interaction unique entre les composants du codeur et du décodeur. Ici, les sorties de l'encodeur jouent à la fois le rôle de requêtes et de clés, tandis que les sorties de la première couche d'attention à plusieurs têtes du décodeur servent de valeurs.
Cette configuration aligne efficacement l'entrée du codeur sur celle du décodeur, permettant au décodeur d'identifier et de mettre l'accent sur les parties les plus pertinentes de l'entrée du codeur.
Les résultats de cette deuxième couche d'attention multiple sont ensuite affinés par une couche d'anticipation ponctuelle, ce qui permet d'améliorer encore le traitement.
Image de l'auteur. Flux de travail du décodeur. Encodeur-Décodeur Attention.
Dans cette sous-couche, les requêtes proviennent de la couche décodeur précédente, et les clés et les valeurs proviennent de la sortie du codeur. Cela permet à chaque position du décodeur de s'occuper de toutes les positions de la séquence d'entrée, en intégrant efficacement les informations du codeur à celles du décodeur.
Comme pour le codeur, chaque couche du décodeur comprend un réseau d'anticipation entièrement connecté, appliqué à chaque position séparément et de manière identique.
Le parcours des données à travers le modèle de transformation se termine par leur passage à travers une dernière couche linéaire, qui fonctionne comme un classificateur.
La taille de ce classificateur correspond au nombre total de classes impliquées (nombre de mots contenus dans le vocabulaire). Par exemple, dans un scénario comportant 1 000 classes distinctes représentant 1 000 mots différents, le résultat du classificateur sera un tableau de 1 000 éléments.
Cette sortie est ensuite introduite dans une couche softmax, qui la transforme en une série de scores de probabilité, chacun se situant entre 0 et 1. Le plus élevé de ces scores de probabilité est la clé, son index correspondant pointe directement vers le mot que le modèle prédit comme étant le suivant dans la séquence.
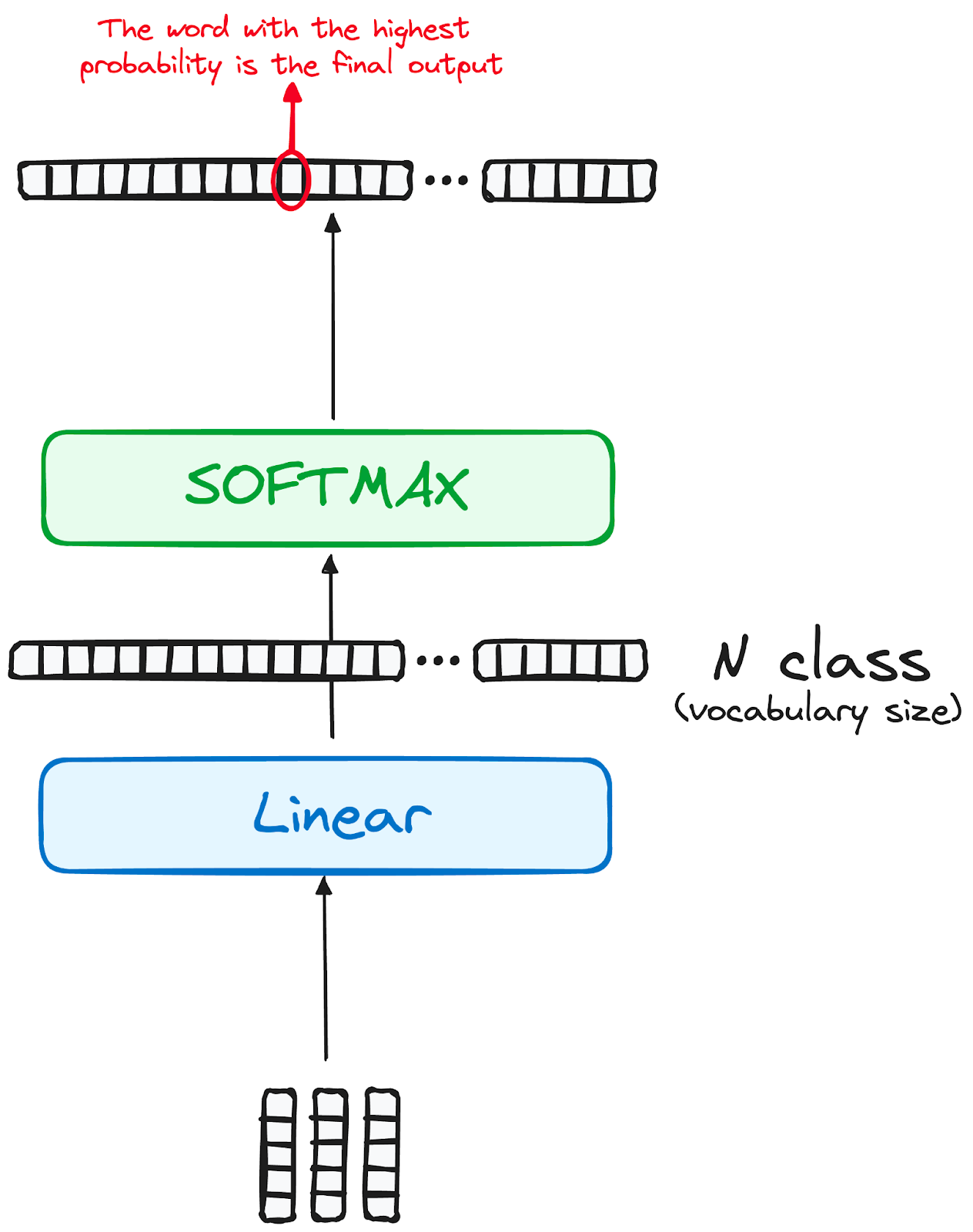
Image de l'auteur. Flux de travail du décodeur. Sortie finale du transformateur.
Chaque sous-couche (auto-attention masquée, attention codeur-décodeur, réseau feed-forward) est suivie d'une étape de normalisation, et chacune comprend également une connexion résiduelle autour d'elle.
La sortie de la dernière couche est transformée en une séquence prédite, généralement par le biais d'une couche linéaire suivie d'un softmax pour générer des probabilités sur le vocabulaire.
Le décodeur, dans son flux opérationnel, incorpore la sortie fraîchement générée dans sa liste croissante d'entrées, puis poursuit le processus de décodage. Ce cycle se répète jusqu'à ce que le modèle prédise un jeton spécifique, signalant ainsi l'achèvement.
Le jeton prédit avec la probabilité la plus élevée est assigné à la classe finale, souvent représentée par le jeton de fin.
Rappelez-vous que le décodeur n'est pas limité à une seule couche. Il peut être structuré en N couches, chacune s'appuyant sur les données reçues du codeur et des couches précédentes. Cette architecture en couches permet au modèle de diversifier ses objectifs et d'extraire des modèles d'attention variés à travers ses têtes d'attention.
Une telle approche multicouche peut améliorer de manière significative la capacité de prévision du modèle, dans la mesure où il développe une compréhension plus nuancée des différentes combinaisons d'attention.
Et l'architecture finale ressemble à quelque chose comme ceci (tiré de l'article original)
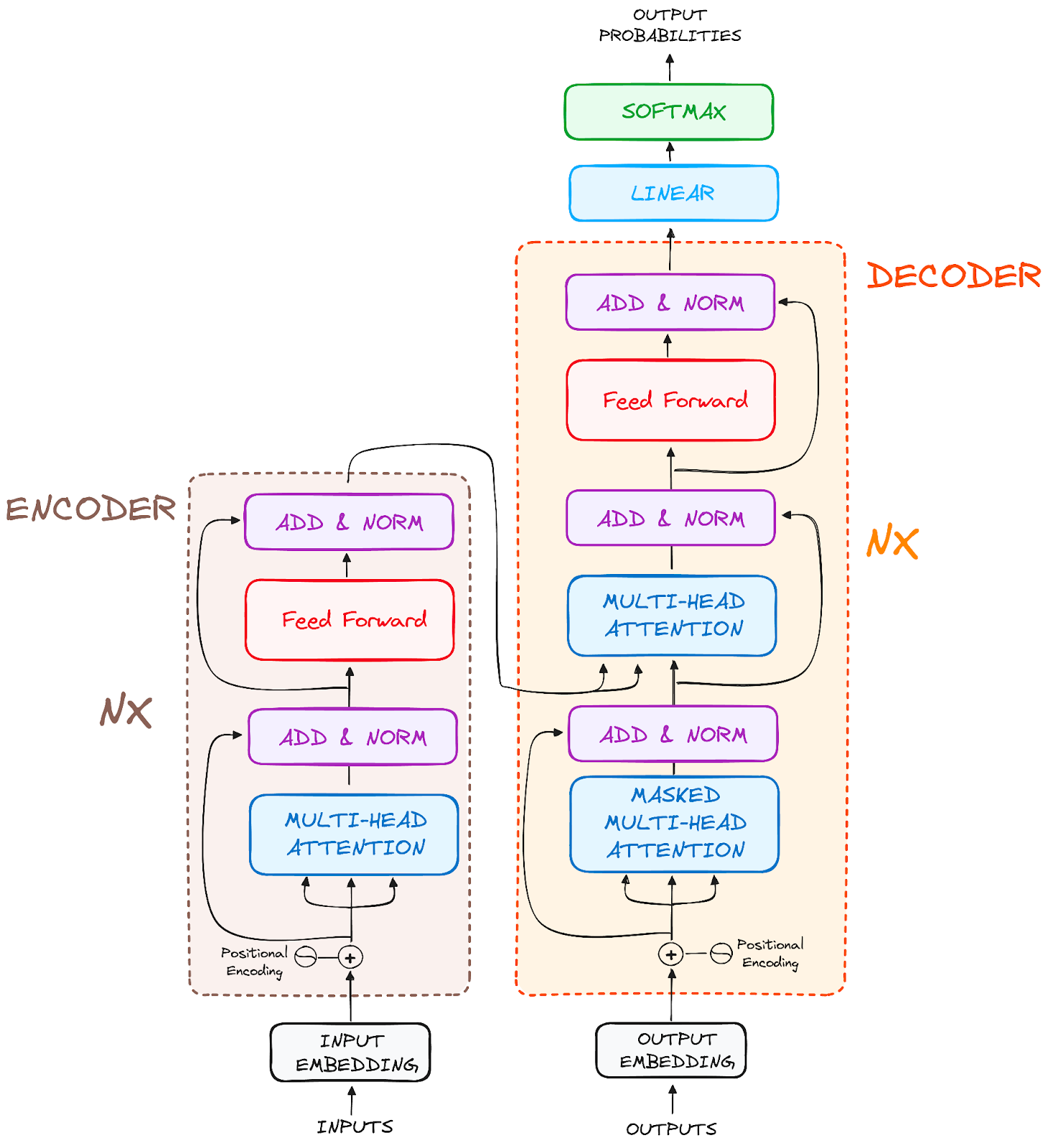
Image de l'auteur. Structure originale de Transformers.
Pour mieux comprendre cette architecture, je vous recommande d'essayer d'appliquer un Transformer à partir de zéro en suivant ce tutoriel pour construire un Transformer avec PyTorch.
La version 2018 de BERT de Google, un cadre de traitement du langage naturel open-source, a révolutionné le NLP grâce à son entraînement bidirectionnel unique, qui permet au modèle d'avoir des prédictions plus éclairées par le contexte sur ce que devrait être le mot suivant.
En comprenant le contexte de tous les côtés d'un mot, BERT a surpassé les modèles précédents dans des tâches telles que la réponse à des questions et la compréhension d'un langage ambigu. Son noyau utilise des transformateurs, connectant chaque élément de sortie et d'entrée de manière dynamique.
BERT, pré-entraîné sur Wikipédia, a excellé dans diverses tâches NLP, ce qui a incité Google à l'intégrer dans son moteur de recherche pour des requêtes plus naturelles. Cette innovation a déclenché une course au développement de modèles linguistiques avancés et a fait progresser de manière significative la capacité du domaine à gérer la compréhension de langues complexes.
Pour en savoir plus sur le BERT, vous pouvez consulter notre article qui présente le modèle BERT.
LaMDA (Language Model for Dialogue Applications) est un modèle basé sur Transformer développé par Google, conçu spécifiquement pour les tâches conversationnelles, et lancé lors de la keynote Google I/O de 2021. Ils sont conçus pour générer des réponses plus naturelles et plus pertinentes sur le plan contextuel, améliorant ainsi les interactions avec les utilisateurs dans diverses applications.
La conception de LaMDA lui permet de comprendre et de répondre à un large éventail de sujets et d'intentions de l'utilisateur, ce qui la rend idéale pour les applications dans les chatbots, les assistants virtuels et d'autres systèmes d'IA interactifs où une conversation dynamique est essentielle.
L'accent mis sur la compréhension et la réponse aux conversations fait du LaMDA une avancée significative dans le domaine du traitement du langage naturel et de la communication pilotée par l'IA.
Si vous souhaitez mieux comprendre les modèles LaMDA, vous pouvez consulter l'article sur LaMDA.
GPT et ChatGPT, développés par OpenAI, sont des modèles génératifs avancés connus pour leur capacité à produire des textes cohérents et contextuellement pertinents. Le GPT-1 a été son premier modèle lancé en juin 2018 et le GPT-3, l'un des modèles les plus impactants, a été lancé deux ans plus tard, en 2020.
Ces modèles sont capables d'effectuer un large éventail de tâches, notamment la création de contenu, la conversation, la traduction, etc. L'architecture de GPT lui permet de générer des textes très proches de l'écriture humaine, ce qui le rend utile dans des applications telles que la rédaction créative, l'assistance à la clientèle et même l'aide au codage. ChatGPT, une variante optimisée pour les contextes conversationnels, excelle dans la génération de dialogues de type humain, améliorant ainsi son application dans les chatbots et les assistants virtuels.
Le paysage des modèles de fondations, en particulier des modèles de transformateurs, s'élargit rapidement. Une étude a identifié plus de 50 modèles de transformateurs importants, tandis que le groupe de Stanford en a évalué 30, reconnaissant ainsi la croissance rapide du secteur. NLP Cloud, une startup innovante faisant partie du programme Inception de NVIDIA, utilise commercialement environ 25 grands modèles de langage pour divers secteurs tels que les compagnies aériennes et les pharmacies.
La tendance est de plus en plus à l'ouverture de ces modèles, avec des plateformes comme Hugging Face's model hub qui ouvrent la voie. En outre, de nombreux modèles basés sur Transformer ont été développés, chacun étant spécialisé dans des tâches NLP différentes, ce qui démontre la polyvalence et l'efficacité du modèle dans diverses applications.
Vous pouvez en savoir plus sur tous les modèles de fondation existants dans un article séparé qui explique ce qu'ils sont et quels sont les plus utilisés.
L'analyse comparative et l'évaluation des performances des modèles de transformateurs dans le cadre du PNA impliquent une approche systématique pour évaluer leur efficacité et leur efficience.
Selon la nature de la tâche, il existe différents moyens et ressources pour y parvenir :
Pour les tâches de traduction automatique, vous pouvez tirer parti d'ensembles de données standard tels que WMT (Workshop on Machine Translation), où les systèmes de traduction automatique sont confrontés à une tapisserie de paires de langues, chacune offrant ses propres défis.
Des mesures telles que BLEU, METEOR, TER et chrF servent d'outils de navigation, nous guidant vers la précision et la fluidité.
En outre, les tests effectués dans divers domaines tels que l'actualité, la littérature et les textes techniques garantissent l'adaptabilité et la polyvalence d'un système de traduction automatique, ce qui en fait un véritable polyglotte dans le monde numérique.
Pour évaluer les modèles d'AQ, nous utilisons des collections spéciales de questions et de réponses, comme SQuAD (Stanford Question Answering Dataset), Natural Questions ou TriviaQA.
Chacun d'entre eux est comme un jeu différent avec ses propres règles. Par exemple, SQuAD permet de trouver des réponses dans un texte donné, tandis que d'autres s'apparentent davantage à un jeu de quiz avec des questions provenant de n'importe où.
Pour évaluer les performances de ces programmes, nous utilisons des scores tels que Precision, Recall, F1, et parfois même des scores de correspondance exacte.
Dans le cadre de l'inférence du langage naturel (NLI), nous utilisons des ensembles de données spécifiques tels que SNLI (Stanford Natural Language Inference), MultiNLI et ANLI.
Il s'agit en quelque sorte de grandes bibliothèques de variations linguistiques et de cas délicats, qui nous permettent de voir dans quelle mesure nos ordinateurs comprennent les différents types de phrases. Nous vérifions principalement la précision des ordinateurs pour comprendre si les déclarations sont cohérentes, contradictoires ou sans rapport entre elles.
Il est également important d'examiner la manière dont l'ordinateur interprète les éléments linguistiques délicats, par exemple lorsqu'un mot fait référence à un élément mentionné précédemment, ou lorsqu'il comprend les termes "pas", "tous" et "certains".
Dans le monde des réseaux neuronaux, deux structures importantes sont généralement comparées à des transformateurs. Chacun d'entre eux offre des avantages et des défis distincts, adaptés à des types spécifiques de traitement de données. Les RNN, qui sont déjà apparus à plusieurs reprises dans l'article, et les couches convulsives.
Les couches récurrentes, pierre angulaire des réseaux neuronaux récurrents (RNN), excellent dans le traitement des données séquentielles. La force de cette architecture réside dans sa capacité à effectuer des opérations séquentielles, cruciales pour des tâches telles que le traitement du langage ou l'analyse de séries temporelles. Dans une couche récurrente, la sortie d'une étape précédente est réinjectée dans le réseau en tant qu'entrée pour l'étape suivante. Ce mécanisme en boucle permet au réseau de se souvenir des informations précédentes, ce qui est essentiel pour comprendre le contexte d'une séquence.
Cependant, comme nous l'avons déjà évoqué, ce traitement séquentiel a deux implications principales :
Les modèles de transformateurs diffèrent considérablement des architectures utilisant des couches récurrentes, car ils ne sont pas récurrents. Comme nous l'avons vu précédemment, la couche d'attention du Transformer évalue les deux problèmes, ce qui en fait l'évolution naturelle des RNN pour les applications NLP.
D'autre part, les couches convolutives, qui constituent les éléments de base des réseaux neuronaux convolutifs (CNN), sont réputées pour leur efficacité dans le traitement des données spatiales telles que les images.
Ces couches utilisent des noyaux (filtres) qui parcourent les données d'entrée pour en extraire les caractéristiques. La largeur de ces noyaux peut être ajustée, ce qui permet au réseau de se concentrer sur de petites ou de grandes caractéristiques, en fonction de la tâche à accomplir.
Si les couches convolutives sont exceptionnellement efficaces pour capturer les hiérarchies et les modèles spatiaux dans les données, elles sont confrontées à des problèmes de dépendances à long terme. Ils ne prennent pas en compte les informations séquentielles, ce qui les rend moins adaptés aux tâches qui nécessitent de comprendre l'ordre ou le contexte d'une séquence.
C'est pourquoi les CNN et les Transformers sont adaptés à différents types de données et de tâches. Les CNN dominent dans le domaine de la vision par ordinateur en raison de leur efficacité dans le traitement des informations spatiales, tandis que les Transformers sont le choix idéal pour les tâches séquentielles complexes, en particulier dans le domaine du langage parlé et écrit, en raison de leur capacité à comprendre les dépendances à long terme.
En conclusion, les transformateurs constituent une avancée monumentale dans le domaine de l'intelligence artificielle et de la PNL.
En gérant efficacement les données séquentielles grâce à leur mécanisme unique d'auto-attention, ces modèles ont surpassé les RNN traditionnels. Leur capacité à traiter plus efficacement de longues séquences et à paralléliser le traitement des données accélère considérablement la formation.
Des modèles pionniers tels que BERT de Google et la série GPT d'OpenAI illustrent l'impact des transformateurs sur l'amélioration des moteurs de recherche et la génération de textes à caractère humain.
Ils sont donc devenus indispensables à l'apprentissage automatique moderne, repoussant les limites de l'IA et ouvrant de nouvelles voies aux avancées technologiques.
Si vous souhaitez vous plonger dans les Transformers et leur utilisation, notre article sur les Transformers et le Hugging Face est un parfait point de départ ! Vous pouvez également apprendre à construire un Transformer avec PyTorch grâce à notre guide approfondi.
En savoir plus sur les transformateurs et les LLM !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
blog
Kurtis Pykes
9 min
blog
Zoumana Keita
15 min
Tutoriel
Samuel Shaibu
Tutoriel

