
Kursus
Rekayasa Fitur untuk Machine Learning di Python
4 Hr
39.2K
Salah satu tantangan umum dalam machine learning adalah menangani variabel kategorikal (seperti warna, jenis produk, atau lokasi) karena algoritme umumnya memerlukan masukan numerik. Salah satu solusi untuk masalah ini adalah one-hot encoding.
One-hot encoding adalah teknik untuk merepresentasikan data kategorikal sebagai vektor numerik, di mana setiap kategori unik direpresentasikan oleh kolom biner dengan nilai 1 menandakan kehadirannya dan 0 menandakan ketidakhadirannya.
Dalam artikel ini, kita akan membahas konsep one-hot encoding, manfaatnya, dan implementasi praktisnya di Python menggunakan pustaka seperti Pandas dan Scikit-learn.
Jika Anda mencari kurikulum terkurasi tentang machine learning, lihat jalur empat kursus ini tentang Fundamental Machine Learning dengan Python.
One-hot encoding adalah metode mengonversi variabel kategorikal ke format yang dapat diberikan kepada algoritme machine learning untuk meningkatkan prediksi. Ini melibatkan pembuatan kolom biner baru untuk setiap kategori unik dalam sebuah fitur. Setiap kolom merepresentasikan satu kategori unik, dan nilai 1 atau 0 menunjukkan ada atau tidaknya kategori tersebut.
Mari pertimbangkan sebuah contoh untuk menggambarkan cara kerja one-hot encoding. Misalkan kita memiliki dataset dengan satu fitur kategorikal, Color, yang dapat bernilai Red, Green, dan Blue. Dengan one-hot encoding, kita dapat mentransformasikan fitur ini sebagai berikut:
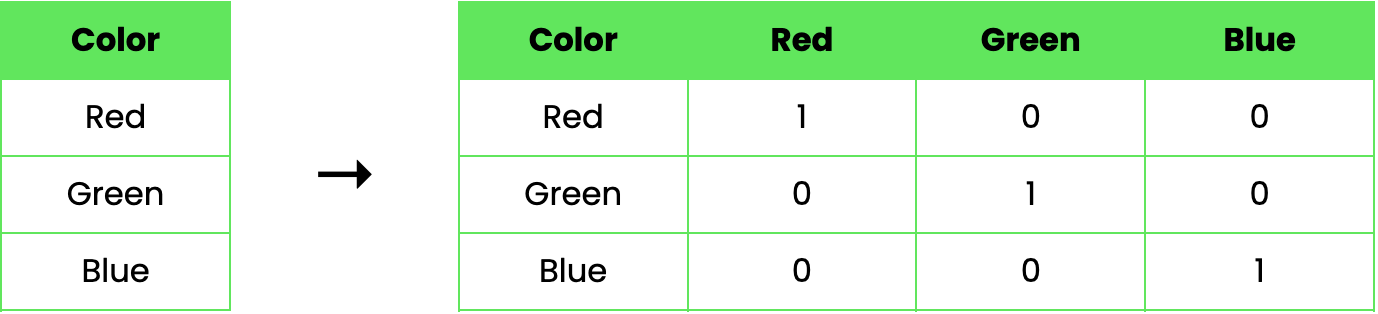
Pada contoh ini, kolom "Color" asli digantikan oleh tiga kolom biner baru, masing-masing merepresentasikan salah satu warna. Nilai 1 menandakan warna tersebut hadir pada baris itu, sementara 0 menandakan ketiadaannya.
One-hot encoding adalah teknik penting dalam prapemrosesan data karena beberapa alasan. Teknik ini mengubah data kategorikal menjadi format yang mudah dipahami dan digunakan oleh model machine learning. Transformasi ini memungkinkan setiap kategori diperlakukan secara independen tanpa menyiratkan adanya hubungan palsu di antara mereka.
Selain itu, banyak pustaka pemrosesan data dan machine learning mendukung one-hot encoding. Teknik ini menyatu mulus dalam alur kerja prapemrosesan data, sehingga memudahkan menyiapkan dataset untuk berbagai algoritme machine learning.
Sebagian besar algoritme machine learning membutuhkan masukan numerik untuk melakukan perhitungan. Data kategorikal perlu diubah menjadi format numerik agar dapat digunakan secara efektif oleh algoritme ini. One-hot encoding menyediakan cara yang lugas untuk mencapai transformasi ini, memastikan variabel kategorikal dapat diintegrasikan ke dalam model machine learning.
Label encoding adalah metode lain untuk mengonversi data kategorikal menjadi nilai numerik dengan memberikan setiap kategori sebuah angka unik. Namun, pendekatan ini dapat menimbulkan masalah karena dapat menyiratkan urutan atau pemeringkatan di antara kategori yang sebenarnya tidak ada.
Sebagai contoh, memberikan 1 untuk Red, 2 untuk Green, dan 3 untuk Blue dapat membuat model mengira bahwa Green lebih besar dari Red dan Blue lebih besar dari keduanya. Kesalahpahaman ini dapat berdampak negatif pada kinerja model.
One-hot encoding menyelesaikan masalah ini dengan membuat kolom biner terpisah untuk setiap kategori. Dengan cara ini, model dapat melihat bahwa setiap kategori itu berbeda dan tidak berkaitan satu sama lain.
Label encoding berguna ketika data kategorikal memiliki hubungan ordinal yang melekat, artinya kategori memiliki urutan atau peringkat yang bermakna. Dalam kasus seperti itu, nilai numerik yang diberikan oleh label encoding dapat secara efektif merepresentasikan urutan ini, sehingga menjadi pilihan yang sesuai.
Pertimbangkan sebuah dataset dengan fitur yang merepresentasikan tingkat pendidikan. Kategorinya adalah:
High SchoolBachelor's DegreeMaster's DegreePhDKategori-kategori ini memiliki urutan yang jelas, di mana PhD mewakili tingkat pendidikan yang lebih tinggi daripada Master's Degree, yang pada gilirannya lebih tinggi daripada Bachelor's Degree, dan seterusnya. Dalam kasus ini, label encoding dapat secara efektif menangkap sifat ordinal dari data:
Pada contoh ini, nilai numerik mencerminkan progres tingkat pendidikan, sehingga label encoding menjadi pilihan yang sesuai. Model dapat menafsirkan nilai-nilai ini dengan benar, memahami bahwa angka yang lebih tinggi berkaitan dengan tingkat pendidikan yang lebih tinggi.
Sekarang setelah kita memahami apa itu one-hot encoding dan mengapa itu penting, mari kita bahas cara menerapkannya di Python.
Python menyediakan pustaka yang kuat seperti Pandas dan Scikit-learn, yang menawarkan cara praktis dan efisien untuk melakukan one-hot encoding.
Pada bagian ini, kita akan menelusuri langkah demi langkah penerapan one-hot encoding menggunakan pustaka tersebut. Kita mulai dengan fungsi get_dummies() milik Pandas, yang cepat dan mudah untuk tugas encoding yang sederhana. Lalu, kita jelajahi OneHotEncoder dari Scikit-learn, yang menawarkan lebih banyak fleksibilitas dan kontrol, sangat berguna untuk kebutuhan encoding yang lebih kompleks.
get_dummies()Pandas menyediakan fungsi yang sangat praktis, get_dummies(), untuk membuat kolom one-hot encoding langsung dari DataFrame.
Berikut cara menggunakannya (kami akan menjelaskan semua kodenya langkah demi langkah di bawah):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Pertama, kita mengimpor pustaka Pandas. Lalu, kita membuat kamus data dengan satu kunci 'Color' dan daftar nama warna sebagai nilainya. Selanjutnya, kita mengonversi kamus ini menjadi Pandas DataFrame df. DataFrame-nya terlihat seperti ini:
Color
0 Red
1 Green
2 Blue
3 RedKita menggunakan fungsi pd.get_dummies() untuk menerapkan one-hot encoding pada DataFrame df. Fungsi ini secara otomatis mendeteksi kolom kategorikal dan membuat kolom biner baru untuk setiap kategori unik. Argumen dtype=int memastikan encoding dilakukan dengan 1 dan 0 alih-alih nilai Boolean bawaan. DataFrame hasilnya, df_encoded, terlihat seperti ini:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoder dari Scikit-learnUntuk fleksibilitas dan kontrol lebih atas proses encoding, Scikit-learn menyediakan kelas OneHotEncoder. Kelas ini menawarkan opsi lanjutan, seperti menangani kategori yang tidak dikenal dan melakukan fitting encoder pada data pelatihan.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Kita mengimpor kelas OneHotEncoder dari sklearn.preprocessing, dan juga mengimpor numpy. Setelah itu, kita membuat instance OneHotEncoder. Parameter handle_unknown='ignore' memberi tahu encoder untuk mengabaikan kategori yang tidak dikenal (kategori yang tidak terlihat saat proses fitting) ketika melakukan transformasi. Lalu kita membuat daftar berisi daftar X, di mana setiap daftar dalam berisi satu warna. Inilah data yang akan kita gunakan untuk melakukan fitting encoder.
Kita melakukan fitting encoder pada data contoh X. Pada langkah ini, encoder mempelajari kategori unik dalam data. Kita menggunakan encoder yang sudah di-fit untuk mentransformasi data baru. Dalam kasus ini, kita mentransformasi satu warna, 'Red'. Metode .transform() mengembalikan matriks jarang (sparse matrix), yang kemudian kita ubah menjadi array padat (dense) menggunakan metode .toarray().
Hasil [[1. 0. 0.]] menunjukkan bahwa 'Red' hadir (1) dan 'Green' serta 'Blue' tidak hadir (0).
Salah satu tantangan besar dengan one-hot encoding adalah "kutukan dimensi". Ini terjadi ketika suatu fitur kategorikal memiliki banyak nilai unik, sehingga jumlah kolom menjadi meledak. Hal ini dapat membuat dataset menjadi jarang (sparse) dan mahal secara komputasi untuk diproses. Mari kita lihat teknik yang dapat diterapkan untuk mengatasinya.
Feature hashing, juga dikenal sebagai hashing trick, dapat membantu mengurangi dimensi dengan melakukan hashing kategori ke sejumlah kolom tetap. Pendekatan ini menjaga efisiensi sambil mengendalikan jumlah fitur. Berikut contoh cara melakukannya:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Kita mengimpor pustaka yang diperlukan, termasuk FeatureHasher dari sklearn.feature_extraction dan pandas. Lalu kita membuat DataFrame dengan fitur kategorikal 'Color'.
Kita menginisialisasi FeatureHasher dengan jumlah fitur keluaran yang diinginkan (n_features=3) dan menentukan tipe masukan sebagai 'string'. Setelah itu, kita menerapkan metode transform pada kolom 'Color' dan mengonversi matriks jarang yang dihasilkan menjadi array padat, yang kemudian diubah menjadi DataFrame. Terakhir, kita mencetak DataFrame yang berisi fitur hasil hashing.
Setelah one-hot encoding, teknik seperti Principal Component Analysis (PCA) dapat diterapkan untuk mengurangi jumlah dimensi sekaligus mempertahankan informasi penting dalam dataset.
PCA dapat membantu memampatkan data berdimensi tinggi ke ruang berdimensi lebih rendah, sehingga lebih mudah dikelola oleh algoritme machine learning.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)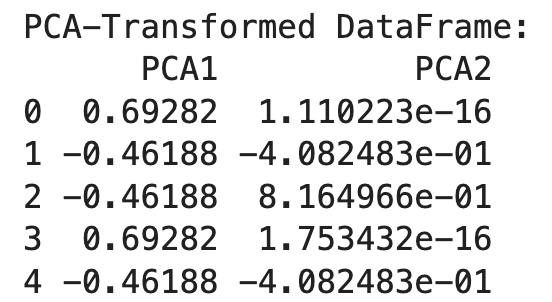
Kita menggunakan OneHotEncoder untuk mengonversi fitur kategorikal ke format one-hot encoding. Hasilnya adalah DataFrame dengan kolom biner untuk setiap kategori.
Setelah itu, kita menginisialisasi PCA dengan jumlah komponen yang diinginkan (n_components=2) dan menerapkannya pada data yang telah di-one-hot encoding. Hasilnya adalah DataFrame yang ditransformasikan dengan dua komponen utama.
PCA membantu mengurangi dimensi data hasil one-hot encoding, sehingga lebih mudah dikelola sekaligus mempertahankan informasi penting. Pendekatan ini sangat berguna ketika berhadapan dengan data berdimensi tinggi dari one-hot encoding.
Walaupun one-hot encoding adalah alat yang kuat, implementasi yang tidak tepat dapat menyebabkan masalah seperti multikolinearitas atau ketidakefisienan dalam menangani data baru. Mari kita bahas beberapa praktik terbaik dan pertimbangannya.
Saat menerapkan model machine learning, umum dijumpai kategori pada set uji yang tidak ada pada set latih. OneHotEncoder milik Scikit-learn dapat menangani kategori yang tidak dikenal dengan mengabaikannya atau menetapkannya ke kolom khusus, sehingga model tetap dapat memproses data baru secara efektif.
Contoh ini menunjukkan cara melakukan fit encoder pada data pelatihan lalu mentransformasi data pelatihan dan data uji, termasuk menangani kategori yang tidak ada pada data pelatihan.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)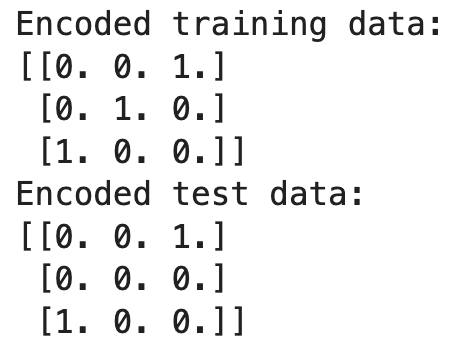
Pada contoh ini, encoder di-fit pada data pelatihan, mempelajari kategori 'Red', 'Green', dan 'Blue'. Saat mentransformasi data uji, encoder menemukan 'Yellow' yang tidak terlihat selama pelatihan. Karena kita menetapkan handle_unknown='ignore', encoder menghasilkan satu baris nol untuk 'Yellow', secara efektif mengabaikan kategori yang tidak dikenal.
Dengan menangani kategori yang tidak dikenal seperti ini, kita dapat memastikan model Anda dapat memproses data baru secara efektif, meskipun berisi kategori yang belum pernah terlihat sebelumnya.
Setelah menerapkan one-hot encoding, penting untuk menghapus kolom kategorikal asli dari dataset. Menyimpan kolom asli dapat menyebabkan multikolinearitas, di mana informasi redundan memengaruhi kinerja model. Pastikan setiap kategori hanya direpresentasikan satu kali dalam dataset untuk menjaga integritasnya.
Berikut cara menghapus kolom kategorikal asli setelah menerapkan one-hot encoding untuk menghindari multikolinearitas dan memastikan setiap kategori hanya direpresentasikan satu kali dalam dataset.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
Pada contoh ini, kita mulai dengan DataFrame yang memiliki kolom kategorikal 'Color'. Kita menggunakan pd.get_dummies() untuk menerapkan one-hot encoding pada kolom 'Color', dengan menentukan columns=['Color'] untuk menunjukkan kolom mana yang akan di-encode. Ini secara otomatis menghapus kolom 'Color' asli dan menggantinya dengan kolom hasil one-hot encoding. DataFrame hasil, df_encoded, kini berisi kolom biner yang merepresentasikan setiap kategori unik, memastikan setiap kategori hanya muncul sekali dan menghilangkan risiko multikolinearitas.
Menghapus kolom kategorikal asli membantu menjaga integritas dataset dan meningkatkan kinerja model machine learning.
OneHotEncoder vs. get_dummies()Memilih antara get_dummies() milik Pandas dan OneHotEncoder milik Scikit-learn bergantung pada kebutuhan Anda. Untuk encoding yang cepat dan sederhana, get_dummies() nyaman dan mudah digunakan. Untuk skenario yang lebih kompleks yang memerlukan kontrol dan fleksibilitas lebih besar, seperti menangani kategori yang tidak dikenal atau melakukan fitting encoder pada data tertentu, OneHotEncoder adalah pilihan yang lebih baik.
One-hot encoding adalah teknik yang kuat dan esensial untuk mentransformasikan data kategorikal ke format numerik yang sesuai bagi algoritme machine learning. Teknik ini meningkatkan akurasi dan efisiensi model machine learning dengan menghindari jebakan ordinalitas dan memudahkan penggunaan data kategorikal.
Menerapkan one-hot encoding di Python sangatlah mudah dengan alat seperti get_dummies() dari Pandas dan OneHotEncoder dari Scikit-learn. Ingat untuk mempertimbangkan dimensi data Anda dan menangani kategori yang tidak dikenal secara efektif.
Jika Anda ingin mempelajari lebih lanjut tentang topik ini, lihat kursus tentang Prapemrosesan untuk Machine Learning di Python.
Pelajari machine learning dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
