
Cursus
Feature engineering voor Machine Learning in Python
4 Hr
39.2K
Een veelvoorkomende uitdaging in machine learning is het omgaan met categorische variabelen (zoals kleuren, producttypes of locaties), omdat algoritmes doorgaans numerieke input vereisen. Een oplossing voor dit probleem is one-hot-encoding.
One-hot-encoding is een techniek om categorische data te representeren als numerieke vectoren, waarbij elke unieke categorie wordt weergegeven door een binaire kolom met een waarde 1 voor aanwezigheid en 0 voor afwezigheid.
In dit artikel bespreken we het concept van one-hot-encoding, de voordelen en de praktische implementatie in Python met bibliotheken zoals Pandas en Scikit-learn.
Zoek je een samengesteld curriculum over machine learning? Bekijk dan dit vierdelige traject over Machine Learning Fundamentals With Python.
One-hot-encoding zet categorische variabelen om naar een formaat dat kan worden gebruikt door machine-learningalgoritmes om voorspellingen te verbeteren. Het houdt in dat er nieuwe binaire kolommen worden gemaakt voor elke unieke categorie in een feature. Elke kolom vertegenwoordigt één unieke categorie en een waarde 1 of 0 geeft respectievelijk aanwezigheid of afwezigheid aan.
Laten we een voorbeeld bekijken om te illustreren hoe one-hot-encoding werkt. Stel, we hebben een dataset met één categorische feature, Color, die drie waarden kan aannemen: Red, Green en Blue. Met one-hot-encoding kunnen we deze feature als volgt transformeren:
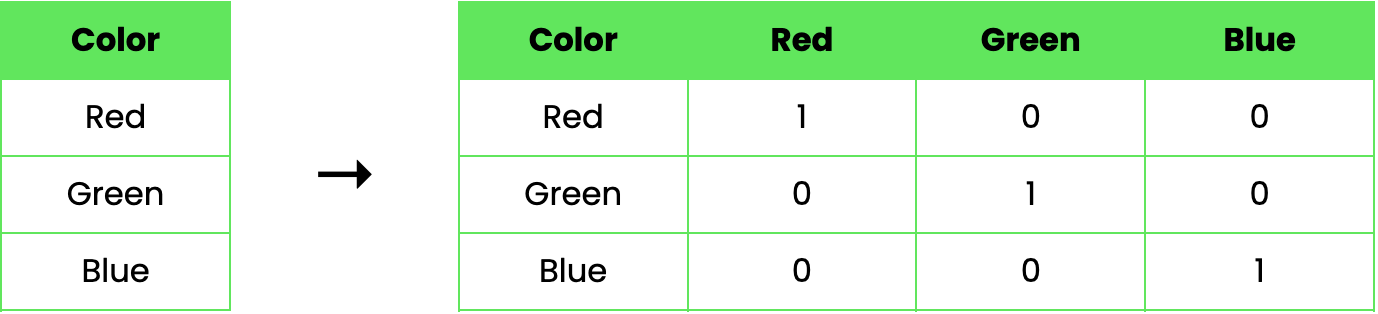
In dit voorbeeld wordt de oorspronkelijke kolom "Color" vervangen door drie nieuwe binaire kolommen, elk voor een van de kleuren. Een waarde van 1 geeft aan dat de kleur in die rij aanwezig is, terwijl 0 afwezigheid aangeeft.
One-hot-encoding is een essentiële techniek in data-preprocessing om meerdere redenen. Het zet categorische data om naar een formaat dat machine-learningmodellen eenvoudig kunnen begrijpen en gebruiken. Hierdoor kan elke categorie onafhankelijk worden behandeld, zonder valse relaties te impliceren.
Bovendien ondersteunen veel data- en machine-learningbibliotheken one-hot-encoding. Het past soepel in de preprocessing-workflow, waardoor het makkelijker wordt om datasets voor te bereiden voor uiteenlopende algoritmes.
De meeste machine-learningalgoritmes hebben numerieke input nodig om berekeningen uit te voeren. Categorische data moet daarom worden omgezet naar een numeriek formaat om effectief gebruikt te kunnen worden. One-hot-encoding biedt een eenvoudige manier om dit te bereiken, zodat categorische variabelen geïntegreerd kunnen worden in modellen.
Label-encoding is een andere methode om categorische data om te zetten naar numerieke waarden door elke categorie een uniek getal toe te wijzen. Deze aanpak kan echter problemen veroorzaken, omdat hiermee een volgorde of rangorde tussen categorieën gesuggereerd kan worden die in werkelijkheid niet bestaat.
Als je bijvoorbeeld 1 toewijst aan Red, 2 aan Green en 3 aan Blue, zou het model kunnen denken dat Green groter is dan Red en Blue groter is dan beide. Dit misverstand kan de modelprestaties negatief beïnvloeden.
One-hot-encoding lost dit op door voor elke categorie een aparte binaire kolom te maken. Zo ziet het model dat elke categorie op zichzelf staat en niet gerelateerd is aan de andere.
Label-encoding is nuttig wanneer de categorische data een inherente ordinale relatie heeft, dus wanneer de categorieën een betekenisvolle volgorde of rangorde hebben. In zulke gevallen kunnen de numerieke waarden van label-encoding deze volgorde effectief weergeven en is het een geschikte keuze.
Neem een dataset met een feature die opleidingsniveaus weergeeft. De categorieën zijn:
High SchoolBachelor's DegreeMaster's DegreePhDDeze categorieën hebben een duidelijke volgorde, waarbij PhD een hoger opleidingsniveau vertegenwoordigt dan Master's Degree, dat op zijn beurt hoger is dan Bachelor's Degree, enzovoort. In dit geval kan label-encoding de ordinale aard van de data effectief vastleggen:
In dit voorbeeld weerspiegelen de numerieke waarden de vooruitgang in opleidingsniveaus, waardoor label-encoding een geschikte keuze is. Het model kan deze waarden correct interpreteren en begrijpen dat hogere getallen overeenkomen met hogere niveaus.
Nu we weten wat one-hot-encoding is en waarom het belangrijk is, gaan we in op de implementatie in Python.
Python biedt krachtige bibliotheken zoals Pandas en Scikit-learn, die handige en efficiënte manieren bieden om one-hot-encoding uit te voeren.
In deze sectie lopen we stap voor stap door het toepassen van one-hot-encoding met deze bibliotheken. We beginnen met de functie get_dummies() van Pandas, die snel en eenvoudig is voor rechttoe-rechtaan taken. Daarna verkennen we Scikit-learns OneHotEncoder, die meer flexibiliteit en controle biedt, vooral handig voor complexere behoeften.
get_dummies() gebruikenPandas biedt een erg handige functie, get_dummies(), om direct vanuit een DataFrame one-hot-gecodeerde kolommen te maken.
Zo gebruik je het (we leggen de code stap voor stap hieronder uit):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Eerst importeren we de Pandas-bibliotheek. Vervolgens maken we een dictionary data met één sleutel 'Color' en een lijst met kleurnamen als waarden. We zetten deze dictionary om naar een Pandas DataFrame df. Het DataFrame ziet er zo uit:
Color
0 Red
1 Green
2 Blue
3 RedWe gebruiken de functie pd.get_dummies() om one-hot-encoding toe te passen op het DataFrame df. Deze functie detecteert automatisch de categorische kolom(men) en maakt nieuwe binaire kolommen voor elke unieke categorie. Het argument dtype=int zorgt ervoor dat de codering gebeurt met 1 en 0 in plaats van de standaard booleans. Het resulterende DataFrame df_encoded ziet er zo uit:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoder gebruikenVoor meer flexibiliteit en controle over het coderingsproces biedt Scikit-learn de klasse OneHotEncoder. Deze klasse heeft geavanceerde opties, zoals het afhandelen van onbekende categorieën en het fitten van de encoder op trainingsdata.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]We importeren de klasse OneHotEncoder uit sklearn.preprocessing, en ook numpy. Daarna maken we een instantie van OneHotEncoder. De parameter handle_unknown='ignore' geeft aan dat de encoder onbekende categorieën (categorieën die niet zijn gezien tijdens het fitten) negeert tijdens de transformatie. Vervolgens maken we een lijst van lijsten X, waarbij elke binnenste lijst één kleur bevat. Dit is de data waarmee we de encoder fitten.
We fitten de encoder op de voorbeelddata X. In deze stap leert de encoder de unieke categorieën in de data. Daarna gebruiken we de gefitte encoder om nieuwe data te transformeren. In dit geval transformeren we één kleur, 'Red'. De methode .transform() geeft een sparse matrix terug, die we omzetten naar een dense array met .toarray().
Het resultaat [[1. 0. 0.]] geeft aan dat 'Red' aanwezig is (1) en 'Green' en 'Blue' afwezig zijn (0).
Een belangrijke uitdaging bij one-hot-encoding is de "vloek van dimensionaliteit". Dit treedt op wanneer een categorische feature veel unieke waarden heeft, wat leidt tot een explosie in het aantal kolommen. De dataset kan dan zeer schaars worden en rekenkundig kostbaar om te verwerken. Laten we de technieken bekijken die we kunnen toepassen om dit op te lossen.
Feature hashing, ook wel de hashing trick genoemd, kan helpen de dimensionaliteit te beperken door categorieën te hashen naar een vast aantal kolommen. Deze aanpak houdt het efficiënt en beheerst het aantal features. Hier is een voorbeeld hoe je dit doet:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
We importeren de benodigde bibliotheken, waaronder FeatureHasher uit sklearn.feature_extraction en pandas. Vervolgens maken we een DataFrame met een categorische feature 'Color'.
We initialiseren FeatureHasher met het gewenste aantal outputfeatures (n_features=3) en geven het inputtype op als 'string'. Daarna passen we de transform-methode toe op de kolom 'Color' en zetten de resulterende sparse matrix om naar een dense array, die we vervolgens omzetten naar een DataFrame. Tot slot printen we het DataFrame met de gehashte features.
Na one-hot-encoding kunnen technieken zoals Principal Component Analysis (PCA) worden toegepast om het aantal dimensies te verkleinen, terwijl de essentiële informatie in de dataset behouden blijft.
PCA kan helpen om hoog-dimensionale data te comprimeren naar een lager-dimensionale ruimte, waardoor het beheersbaarder wordt voor algoritmes.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)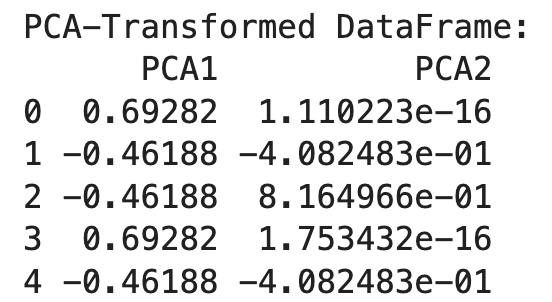
We gebruiken OneHotEncoder om de categorische feature om te zetten naar een one-hot-gecodeerd formaat. Het resultaat is een DataFrame met binaire kolommen voor elke categorie.
Daarna initialiseren we PCA met het gewenste aantal componenten (n_components=2) en passen dit toe op de one-hot-gecodeerde data. Het resultaat is een getransformeerd DataFrame met twee hoofdcomponenten.
PCA helpt de dimensionaliteit van de one-hot-gecodeerde data te verminderen, waardoor deze beter hanteerbaar wordt terwijl de essentiële informatie behouden blijft. Dit is vooral nuttig bij hoog-dimensionale data door one-hot-encoding.
Hoewel one-hot-encoding krachtig is, kan onjuiste implementatie leiden tot problemen zoals multicollineariteit of inefficiënt omgaan met nieuwe data. Laten we enkele best practices en aandachtspunten bespreken.
Bij het deployen van modellen kom je vaak categorieën in de testset tegen die niet in de trainingsset voorkwamen. Scikit-learns OneHotEncoder kan onbekende categorieën negeren of toewijzen aan een speciale kolom, zodat het model nieuwe data toch effectief kan verwerken.
Dit voorbeeld laat zien hoe je de encoder fit op de trainingsdata en vervolgens zowel de trainings- als testdata transformeert, inclusief het afhandelen van categorieën die niet in de training voorkwamen.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)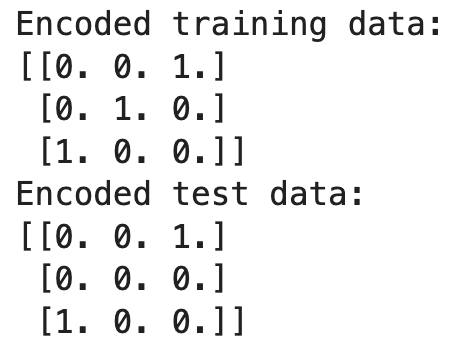
In dit voorbeeld wordt de encoder gefit op de trainingsdata en leert deze de categorieën 'Red', 'Green' en 'Blue'. Bij het transformeren van de testdata komt 'Yellow' voor, dat tijdens de training niet is gezien. Omdat we handle_unknown='ignore' hebben ingesteld, produceert de encoder voor 'Yellow' een rij met nullen en negeert zo de onbekende categorie.
Door op deze manier met onbekende categorieën om te gaan, zorg je ervoor dat je model nieuwe data effectief kan verwerken, zelfs als die eerder onzichtbare categorieën bevat.
Na het toepassen van one-hot-encoding is het cruciaal om de oorspronkelijke categorische kolom uit de dataset te verwijderen. Als je de originele kolom behoudt, kan dat leiden tot multicollineariteit, waarbij overtollige informatie de modelprestaties schaadt. Zorg ervoor dat elke categorie slechts één keer in de dataset wordt weergegeven om de integriteit te bewaren.
Zo kun je de oorspronkelijke categorische kolom verwijderen na one-hot-encoding om multicollineariteit te voorkomen en te zorgen dat elke categorie slechts één keer wordt weergegeven.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
In dit voorbeeld beginnen we met een DataFrame met een categorische kolom 'Color'. We gebruiken pd.get_dummies() om one-hot-encoding toe te passen op de kolom 'Color', waarbij we columns=['Color'] specificeren om aan te geven welke kolom moet worden gecodeerd. Dit verwijdert automatisch de oorspronkelijke kolom 'Color' en vervangt deze door de one-hot-gecodeerde kolommen. Het resulterende DataFrame df_encoded bevat nu binaire kolommen voor elke unieke categorie, zodat elke categorie slechts één keer wordt weergegeven en het risico op multicollineariteit wordt weggenomen.
Door de oorspronkelijke categorische kolom te verwijderen, behouden we de integriteit van de dataset en verbeteren we de prestaties van het model.
OneHotEncoder vs. get_dummies()De keuze tussen de get_dummies() van Pandas en de OneHotEncoder van Scikit-learn hangt af van je behoeften. Voor snelle en eenvoudige codering is get_dummies() handig en makkelijk. Voor complexere scenario’s die meer controle en flexibiliteit vereisen, zoals het omgaan met onbekende categorieën of het fitten op specifieke data, is OneHotEncoder de betere keuze.
One-hot-encoding is een krachtige en essentiële techniek om categorische data om te zetten naar een numeriek formaat dat geschikt is voor machine-learningalgoritmes. Het verhoogt de nauwkeurigheid en efficiëntie van modellen door ordinaliteitsvalkuilen te vermijden en het gebruik van categorische data te faciliteren.
One-hot-encoding implementeren in Python is eenvoudig met tools als de get_dummies() van Pandas en de OneHotEncoder van Scikit-learn. Denk eraan rekening te houden met de dimensionaliteit van je data en onbekende categorieën goed af te handelen.
Wil je hier meer over leren? Bekijk dan deze cursus over Preprocessing voor Machine Learning in Python.
Leer machine learning met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
