
Corso
Feature Engineering per il Machine Learning in Python
4 h
39.2K
Una sfida comune nel machine learning è gestire le variabili categoriche (come colori, tipi di prodotto o località) perché gli algoritmi richiedono in genere input numerici. Una soluzione a questo problema è il one-hot encoding.
Il one-hot encoding è una tecnica per rappresentare dati categorici come vettori numerici, in cui ogni categoria unica è rappresentata da una colonna binaria con valore 1 a indicarne la presenza e 0 a indicarne l’assenza.
In questo articolo esploreremo il concetto di one-hot encoding, i suoi vantaggi e la sua implementazione pratica in Python usando librerie come Pandas e Scikit-learn.
Se cerchi un percorso curato sul machine learning, dai un’occhiata a questa track di quattro corsi su Fondamenti di Machine Learning con Python.
Il one-hot encoding è un metodo per convertire variabili categoriche in un formato utilizzabile dagli algoritmi di machine learning per migliorare la previsione. Comporta la creazione di nuove colonne binarie per ogni categoria unica di una feature. Ogni colonna rappresenta una categoria unica e un valore 1 o 0 indica la presenza o l’assenza di quella categoria.
Consideriamo un esempio per illustrare come funziona il one-hot encoding. Supponiamo di avere un dataset con una singola feature categorica, Color, che può assumere tre valori: Red, Green e Blue. Usando il one-hot encoding, possiamo trasformare questa feature come segue:
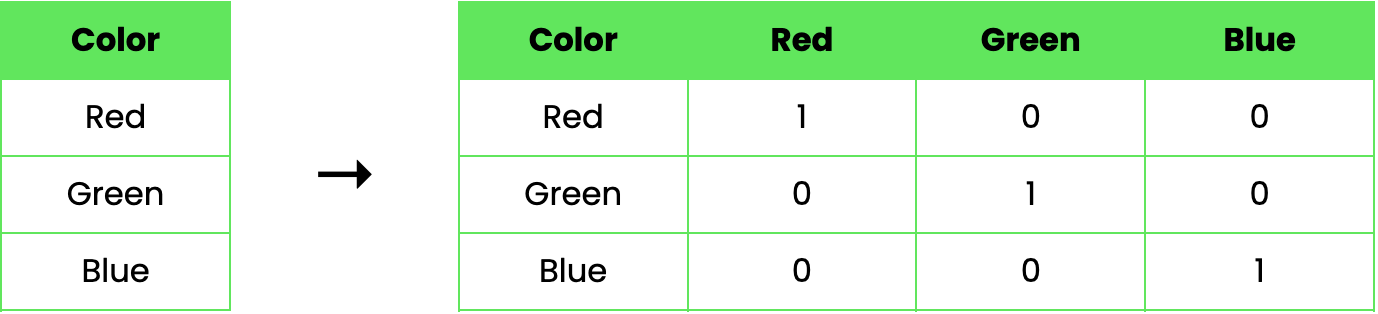
In questo esempio, la colonna originale "Color" è sostituita da tre nuove colonne binarie, ciascuna rappresentante uno dei colori. Un valore pari a 1 indica la presenza del colore in quella riga, mentre 0 ne indica l’assenza.
Il one-hot encoding è una tecnica essenziale nel preprocessing dei dati per diversi motivi. Trasforma i dati categorici in un formato che i modelli di machine learning possono comprendere e usare facilmente. Questa trasformazione consente di trattare ciascuna categoria in modo indipendente, senza implicare relazioni inesistenti tra di esse.
Inoltre, molte librerie di elaborazione dati e machine learning supportano il one-hot encoding. Si integra senza intoppi nel flusso di preprocessing, facilitando la preparazione dei dataset per vari algoritmi di machine learning.
La maggior parte degli algoritmi di machine learning richiede input numerici per eseguire i calcoli. I dati categorici devono quindi essere trasformati in un formato numerico per essere utilizzati in modo efficace. Il one-hot encoding offre un modo semplice per ottenere questa trasformazione, assicurando che le variabili categoriche possano essere integrate nei modelli.
Il label encoding è un altro metodo per convertire i dati categorici in valori numerici assegnando a ciascuna categoria un numero univoco. Tuttavia, questo approccio può creare problemi perché potrebbe suggerire un ordine o una graduatoria tra categorie che in realtà non esiste.
Per esempio, assegnare 1 a Red, 2 a Green e 3 a Blue potrebbe far pensare al modello che Green sia maggiore di Red e Blue sia maggiore di entrambi. Questo fraintendimento può influire negativamente sulle prestazioni del modello.
Il one-hot encoding risolve questo problema creando una colonna binaria separata per ciascuna categoria. In questo modo, il modello può vedere che ogni categoria è distinta e non correlata alle altre.
Il label encoding è utile quando i dati categorici hanno una relazione ordinale intrinseca, cioè quando le categorie hanno un ordine o una graduatoria significativa. In tali casi, i valori numerici assegnati dal label encoding possono rappresentare efficacemente quest’ordine, rendendolo una scelta adatta.
Considera un dataset con una feature che rappresenta i livelli di istruzione. Le categorie sono:
High SchoolBachelor's DegreeMaster's DegreePhDQueste categorie hanno un ordine chiaro, in cui PhD rappresenta un livello di istruzione più alto di Master's Degree, che a sua volta è superiore a Bachelor's Degree, e così via. In questo caso, il label encoding può catturare efficacemente la natura ordinale dei dati:
In questo esempio, i valori numerici riflettono la progressione dei livelli di istruzione, rendendo il label encoding una scelta adeguata. Il modello può interpretare correttamente questi valori, comprendendo che numeri più alti corrispondono a livelli di istruzione più elevati.
Ora che sappiamo cos’è il one-hot encoding e perché è importante, vediamo come implementarlo in Python.
Python offre librerie potenti come Pandas e Scikit-learn, che forniscono modi comodi ed efficienti per eseguire il one-hot encoding.
In questa sezione, vedremo passo per passo come applicare il one-hot encoding usando queste librerie. Inizieremo con la funzione get_dummies() di Pandas, rapida e semplice per compiti di encoding lineari. Poi esploreremo OneHotEncoder di Scikit-learn, che offre maggiore flessibilità e controllo, particolarmente utile per esigenze di encoding più complesse.
get_dummies()Pandas fornisce una funzione molto comoda, get_dummies(), per creare colonne one-hot encoded direttamente da un DataFrame.
Ecco come puoi usarla (spiegheremo tutto il codice passo passo qui sotto):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Per prima cosa importiamo la libreria Pandas. Poi creiamo un dizionario data con una singola chiave 'Color' e una lista di nomi di colori come valori. Quindi convertiamo questo dizionario in un DataFrame Pandas df. Il DataFrame si presenta così:
Color
0 Red
1 Green
2 Blue
3 RedUsiamo la funzione pd.get_dummies() per applicare il one-hot encoding al DataFrame df. Questa funzione rileva automaticamente le colonne categoriche e crea nuove colonne binarie per ciascuna categoria unica. L’argomento dtype=int garantisce che l’encoding sia effettuato con 1 e 0 invece dei Booleani di default. Il DataFrame risultante df_encoded è il seguente:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoder di Scikit-learnPer maggiore flessibilità e controllo sul processo di encoding, Scikit-learn offre la classe OneHotEncoder. Questa classe fornisce opzioni avanzate, come la gestione delle categorie sconosciute e il fitting dell’encoder sui dati di training.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Importiamo la classe OneHotEncoder da sklearn.preprocessing e importiamo anche numpy. Dopo questo, creiamo un’istanza di OneHotEncoder. Il parametro handle_unknown='ignore' indica all’encoder di ignorare le categorie sconosciute (categorie non viste durante il fitting) in fase di trasformazione. Creiamo quindi una lista di liste X, in cui ogni lista interna contiene un singolo colore. Questi sono i dati che useremo per fare il fit dell’encoder.
Fittiamo l’encoder sui dati di esempio X. In questo passaggio, l’encoder apprende le categorie uniche presenti nei dati. Usiamo quindi l’encoder fittato per trasformare nuovi dati. In questo caso, trasformiamo un singolo colore, 'Red'. Il metodo .transform() restituisce una matrice sparsa, che convertiamo in un array denso usando il metodo .toarray().
Il risultato [[1. 0. 0.]] indica che 'Red' è presente (1) mentre 'Green' e 'Blue' sono assenti (0).
Una sfida significativa del one-hot encoding è la “maledizione della dimensionalità”. Si verifica quando una feature categorica ha un numero elevato di valori unici, causando un’esplosione del numero di colonne. Questo può rendere il dataset sparso e costoso da elaborare dal punto di vista computazionale. Vediamo le tecniche che possiamo applicare per risolvere questo problema.
Il feature hashing, noto anche come hashing trick, può aiutare a ridurre la dimensionalità mappando le categorie in un numero fisso di colonne. Questo approccio mantiene l’efficienza controllando al contempo il numero di feature. Ecco un esempio di come farlo:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Importiamo le librerie necessarie, inclusi FeatureHasher da sklearn.feature_extraction e pandas. Creiamo quindi un DataFrame con una feature categorica 'Color'.
Inizializziamo FeatureHasher con il numero desiderato di feature in output (n_features=3) e specifichiamo il tipo di input come 'string'. Successivamente applichiamo il metodo transform alla colonna 'Color' e convertiamo la matrice sparsa risultante in un array denso, che viene poi convertito in un DataFrame. Infine, stampiamo il DataFrame contenente le feature hashate.
Dopo il one-hot encoding, si possono applicare tecniche come la Principal Component Analysis (PCA) per ridurre il numero di dimensioni preservando le informazioni essenziali del dataset.
La PCA può aiutare a comprimere i dati ad alta dimensionalità in uno spazio a dimensionalità inferiore, rendendoli più gestibili per gli algoritmi di machine learning.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)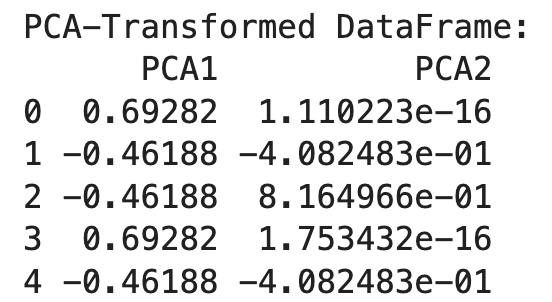
Usiamo OneHotEncoder per convertire la feature categorica in un formato one-hot encoded. Il risultato è un DataFrame con colonne binarie per ogni categoria.
Successivamente, inizializziamo la PCA con il numero desiderato di componenti (n_components=2) e la applichiamo ai dati one-hot encoded. Il risultato è un DataFrame trasformato con due componenti principali.
La PCA aiuta a ridurre la dimensionalità dei dati one-hot encoded, rendendoli più gestibili pur preservando le informazioni essenziali. Questo approccio è particolarmente utile quando si ha a che fare con dati ad alta dimensionalità derivanti dal one-hot encoding.
Sebbene il one-hot encoding sia uno strumento potente, un’implementazione scorretta può portare a problemi come multicollinearità o inefficienza nella gestione di nuovi dati. Vediamo alcune best practice e considerazioni.
Quando distribuisci modelli di machine learning, è comune trovare categorie nel test set che non erano presenti nel training set. OneHotEncoder di Scikit-learn può gestire le categorie sconosciute ignorandole o assegnandole a una colonna dedicata, garantendo che il modello possa comunque elaborare efficacemente i nuovi dati.
Questo esempio mostra come effettuare il fit dell’encoder sui dati di training e quindi trasformare sia i dati di training sia quelli di test, includendo la gestione delle categorie non presenti nel training set.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)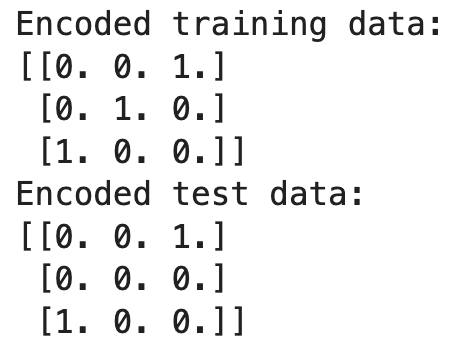
In questo esempio, l’encoder è fittato sui dati di training, apprendendo le categorie 'Red', 'Green' e 'Blue'. Durante la trasformazione dei dati di test, incontra 'Yellow', che non era stato visto in fase di training. Poiché abbiamo impostato handle_unknown='ignore', l’encoder produce una riga di zeri per 'Yellow', ignorando di fatto la categoria sconosciuta.
Gestendo le categorie sconosciute in questo modo, possiamo assicurarci che il modello elabori efficacemente i nuovi dati, anche se contengono categorie non viste in precedenza.
Dopo aver applicato il one-hot encoding, è fondamentale eliminare la colonna categorica originale dal dataset. Mantenere la colonna originale può portare a multicollinearità, dove informazioni ridondanti influenzano le prestazioni del modello. Assicurati che ogni categoria sia rappresentata una sola volta nel dataset per mantenerne l’integrità.
Ecco come puoi eliminare la colonna categorica originale dopo aver applicato il one-hot encoding, per evitare la multicollinearità e assicurarti che ogni categoria sia rappresentata una sola volta nel dataset.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
In questo esempio, partiamo da un DataFrame contenente una colonna categorica 'Color'. Usiamo pd.get_dummies() per applicare il one-hot encoding alla colonna 'Color', specificando columns=['Color'] per indicare quale colonna codificare. Questo elimina automaticamente la colonna 'Color' originale e la sostituisce con le colonne one-hot encoded. Il DataFrame risultante df_encoded contiene ora colonne binarie che rappresentano ciascuna categoria unica, assicurando che ogni categoria sia rappresentata una sola volta ed eliminando il rischio di multicollinearità.
Eliminare la colonna categorica originale ci permette di mantenere l’integrità del dataset e migliorare le prestazioni del modello di machine learning.
OneHotEncoder vs. get_dummies()La scelta tra get_dummies() di Pandas e OneHotEncoder di Scikit-learn dipende dalle tue esigenze. Per un encoding rapido e lineare, get_dummies() è comodo e facile da usare. Per scenari più complessi che richiedono maggiore controllo e flessibilità, come la gestione delle categorie sconosciute o il fitting dell’encoder su dati specifici, OneHotEncoder è la scelta migliore.
Il one-hot encoding è una tecnica potente ed essenziale per trasformare i dati categorici in un formato numerico adatto agli algoritmi di machine learning. Migliora accuratezza ed efficienza dei modelli evitando le insidie dell’ordinalità e facilitando l’uso dei dati categorici.
Implementare il one-hot encoding in Python è semplice con strumenti come get_dummies() di Pandas e OneHotEncoder di Scikit-learn. Ricorda di considerare la dimensionalità dei tuoi dati e di gestire efficacemente le categorie sconosciute.
Se vuoi approfondire l’argomento, dai un’occhiata a questo corso sul Preprocessing per il Machine Learning in Python.
Impara il machine learning con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

