
Courses
Feature Engineering cho Machine Learning bằng Python
4 giờ
39.2K
Một thách thức phổ biến trong học máy là xử lý các biến phân loại (chẳng hạn như màu sắc, loại sản phẩm hoặc địa điểm) vì các thuật toán thường yêu cầu đầu vào dạng số. Một cách giải quyết là one-hot encoding.
One-hot encoding là một kỹ thuật biểu diễn dữ liệu phân loại dưới dạng các véc-tơ số, trong đó mỗi hạng mục duy nhất được biểu diễn bằng một cột nhị phân với giá trị 1 cho biết có xuất hiện và 0 cho biết không xuất hiện.
Trong bài viết này, chúng ta sẽ tìm hiểu khái niệm one-hot encoding, lợi ích của nó và cách triển khai thực tế trong Python bằng các thư viện như Pandas và Scikit-learn.
Nếu bạn đang tìm kiếm một lộ trình học máy được tuyển chọn, hãy xem lộ trình gồm bốn khóa học về Các nền tảng Học máy với Python.
One-hot encoding là phương pháp chuyển đổi các biến phân loại sang định dạng có thể đưa vào các thuật toán học máy để cải thiện khả năng dự đoán. Nó bao gồm việc tạo các cột nhị phân mới cho mỗi hạng mục duy nhất trong một đặc trưng. Mỗi cột biểu diễn một hạng mục, và giá trị 1 hoặc 0 cho biết có hay không có hạng mục đó.
Hãy xem một ví dụ để minh họa cách one-hot encoding hoạt động. Giả sử chúng ta có một tập dữ liệu với một đặc trưng phân loại duy nhất, Color, có thể nhận ba giá trị: Red, Green và Blue. Sử dụng one-hot encoding, chúng ta có thể biến đổi đặc trưng này như sau:
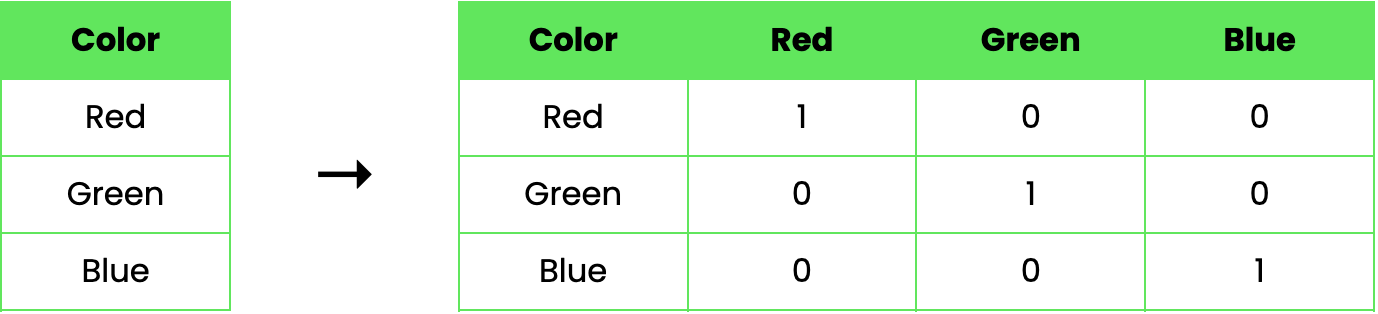
Trong ví dụ này, cột "Color" gốc được thay thế bằng ba cột nhị phân mới, mỗi cột đại diện cho một màu. Giá trị 1 cho biết màu đó xuất hiện ở hàng tương ứng, còn 0 cho biết không xuất hiện.
One-hot encoding là một kỹ thuật thiết yếu trong tiền xử lý dữ liệu vì nhiều lý do. Nó chuyển đổi dữ liệu phân loại sang định dạng mà các mô hình học máy có thể dễ dàng hiểu và sử dụng. Việc chuyển đổi này cho phép xử lý từng hạng mục một cách độc lập mà không hàm ý bất kỳ mối quan hệ sai lệch nào giữa chúng.
Ngoài ra, nhiều thư viện xử lý dữ liệu và học máy hỗ trợ one-hot encoding. Nó tích hợp mượt mà vào quy trình tiền xử lý dữ liệu, giúp bạn dễ dàng chuẩn bị tập dữ liệu cho nhiều thuật toán học máy khác nhau.
Hầu hết các thuật toán học máy yêu cầu đầu vào dạng số để thực hiện tính toán. Dữ liệu phân loại cần được chuyển đổi sang dạng số để các thuật toán này sử dụng hiệu quả. One-hot encoding cung cấp một cách đơn giản để thực hiện chuyển đổi này, đảm bảo các biến phân loại có thể tích hợp vào mô hình học máy.
Label encoding là một phương pháp khác để chuyển dữ liệu phân loại thành giá trị số bằng cách gán cho mỗi hạng mục một số duy nhất. Tuy nhiên, cách tiếp cận này có thể gây vấn đề vì nó có thể ngụ ý một trật tự hoặc thứ hạng giữa các hạng mục vốn không tồn tại.
Ví dụ, gán 1 cho Red, 2 cho Green và 3 cho Blue có thể khiến mô hình nghĩ rằng Green lớn hơn Red và Blue lớn hơn cả hai. Sự hiểu nhầm này có thể ảnh hưởng tiêu cực đến hiệu năng của mô hình.
One-hot encoding giải quyết vấn đề này bằng cách tạo một cột nhị phân riêng cho từng hạng mục. Nhờ đó, mô hình có thể thấy rằng mỗi hạng mục là riêng biệt và không liên quan đến các hạng mục khác.
Label encoding hữu ích khi dữ liệu phân loại có mối quan hệ thứ bậc nội tại, tức là các hạng mục có một trật tự hoặc thứ hạng có ý nghĩa. Trong những trường hợp như vậy, các giá trị số do label encoding gán có thể biểu diễn hiệu quả trật tự đó, khiến nó trở thành lựa chọn phù hợp.
Hãy xét một tập dữ liệu với một đặc trưng biểu diễn trình độ học vấn. Các hạng mục gồm:
High SchoolBachelor's DegreeMaster's DegreePhDCác hạng mục này có một trật tự rõ ràng, trong đó PhD thể hiện trình độ cao hơn Master's Degree, vốn lại cao hơn Bachelor's Degree, v.v. Trong trường hợp này, label encoding có thể nắm bắt hiệu quả tính thứ bậc của dữ liệu:
Trong ví dụ này, các giá trị số phản ánh sự tiến triển về trình độ học vấn, khiến label encoding trở thành lựa chọn phù hợp. Mô hình có thể diễn giải đúng các giá trị này, hiểu rằng số cao hơn tương ứng với trình độ học vấn cao hơn.
Giờ chúng ta đã hiểu one-hot encoding là gì và vì sao quan trọng, hãy đi sâu vào cách triển khai nó trong Python.
Python cung cấp các thư viện mạnh mẽ như Pandas và Scikit-learn, cho phép thực hiện one-hot encoding một cách tiện lợi và hiệu quả.
Trong phần này, chúng ta sẽ đi qua từng bước áp dụng one-hot encoding bằng các thư viện này. Bắt đầu với hàm get_dummies() của Pandas, nhanh gọn cho các tác vụ mã hóa đơn giản. Sau đó, chúng ta sẽ khám phá OneHotEncoder của Scikit-learn, cung cấp nhiều linh hoạt và kiểm soát hơn, đặc biệt hữu ích cho các nhu cầu mã hóa phức tạp.
get_dummies()Pandas cung cấp một hàm rất tiện lợi, get_dummies(), để tạo các cột one-hot encoded trực tiếp từ DataFrame.
Cách sử dụng như sau (chúng tôi sẽ giải thích từng bước mã bên dưới):
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, dtype=int)
# Displaying the encoded DataFrame
print(df_encoded)
Đầu tiên, chúng ta nhập thư viện Pandas. Sau đó, tạo một từ điển data với khóa 'Color' và danh sách tên màu làm giá trị. Tiếp theo, chuyển từ điển này thành một Pandas DataFrame df. DataFrame trông như sau:
Color
0 Red
1 Green
2 Blue
3 RedChúng ta dùng hàm pd.get_dummies() để áp dụng one-hot encoding cho DataFrame df. Hàm này tự động nhận diện các cột phân loại và tạo các cột nhị phân mới cho mỗi hạng mục duy nhất. Tham số dtype=int đảm bảo mã hóa bằng 1 và 0 thay vì kiểu Boolean mặc định. DataFrame kết quả df_encoded trông như sau:
Color_Blue Color_Green Color_Red
0 0 0 1
1 0 1 0
2 1 0 0
3 0 0 1OneHotEncoder của Scikit-learnĐể linh hoạt và kiểm soát tốt hơn quá trình mã hóa, Scikit-learn cung cấp lớp OneHotEncoder. Lớp này có các tùy chọn nâng cao, như xử lý hạng mục không biết và fit bộ mã hóa vào dữ liệu huấn luyện.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Creating the encoder
enc = OneHotEncoder(handle_unknown='ignore')
# Sample data
X = [['Red'], ['Green'], ['Blue']]
# Fitting the encoder to the data
enc.fit(X)
# Transforming new data
result = enc.transform([['Red']]).toarray()
# Displaying the encoded result
print(result)[[1. 0. 0.]]Chúng ta nhập lớp OneHotEncoder từ sklearn.preprocessing và nhập cả numpy. Sau đó, tạo một thể hiện OneHotEncoder. Tham số handle_unknown='ignore' yêu cầu bộ mã hóa bỏ qua các hạng mục không biết (không xuất hiện trong quá trình fit) khi biến đổi. Tiếp tục tạo danh sách các danh sách X, trong đó mỗi danh sách con chứa một màu. Đây là dữ liệu chúng ta dùng để fit bộ mã hóa.
Chúng ta fit bộ mã hóa vào dữ liệu mẫu X. Ở bước này, bộ mã hóa học các hạng mục duy nhất trong dữ liệu. Sau đó, dùng bộ mã hóa đã fit để biến đổi dữ liệu mới. Trong ví dụ, chúng ta biến đổi một màu, 'Red'. Phương thức .transform() trả về một ma trận thưa, được chuyển sang mảng đặc bằng phương thức .toarray().
Kết quả [[1. 0. 0.]] cho thấy 'Red' xuất hiện (1) còn 'Green' và 'Blue' không xuất hiện (0).
Một thách thức lớn với one-hot encoding là "lời nguyền chiều dữ liệu". Điều này xảy ra khi một đặc trưng phân loại có số lượng giá trị duy nhất lớn, dẫn đến bùng nổ số lượng cột. Tập dữ liệu có thể trở nên thưa và tốn kém về tính toán. Hãy xem các kỹ thuật có thể áp dụng để giải quyết.
Feature hashing, còn gọi là hashing trick, giúp giảm chiều bằng cách băm các hạng mục vào một số cột cố định. Cách tiếp cận này duy trì hiệu quả đồng thời kiểm soát số lượng đặc trưng. Dưới đây là ví dụ cách thực hiện:
from sklearn.feature_extraction import FeatureHasher
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Initialize FeatureHasher
hasher = FeatureHasher(n_features=3, input_type='string')
# Apply feature hashing
hashed_features = hasher.transform(df['Color'])
hashed_df = pd.DataFrame(hashed_features.toarray(), columns=['Feature1', 'Feature2', 'Feature3'])
# Display the hashed features DataFrame
print("Hashed Features DataFrame:")
print(hashed_df)
Chúng ta nhập các thư viện cần thiết, bao gồm FeatureHasher từ sklearn.feature_extraction và pandas. Sau đó tạo một DataFrame với đặc trưng phân loại 'Color'.
Khởi tạo FeatureHasher với số đặc trưng đầu ra mong muốn (n_features=3) và chỉ định kiểu đầu vào là 'string'. Tiếp theo, áp dụng phương thức transform cho cột 'Color' và chuyển ma trận thưa kết quả thành mảng đặc, sau đó chuyển thành DataFrame. Cuối cùng, in DataFrame chứa các đặc trưng đã băm.
Sau one-hot encoding, có thể áp dụng các kỹ thuật như Phân tích Thành phần Chính (PCA) để giảm số chiều trong khi vẫn giữ lại thông tin cốt lõi của tập dữ liệu.
PCA có thể giúp nén dữ liệu có số chiều cao vào không gian chiều thấp hơn, giúp các thuật toán học máy xử lý dễ dàng hơn.
from sklearn.preprocessing import OneHotEncoder
from sklearn.decomposition import PCA
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red', 'Yellow']}
df = pd.DataFrame(data)
# Applying one-hot encoding
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(df[['Color']])
# Creating a DataFrame with one-hot encoded columns
# Check if get_feature_names_out is available
if hasattr(encoder, 'get_feature_names_out'):
feature_names = encoder.get_feature_names_out(['Color'])
else:
feature_names = [f'Color_{cat}' for cat in encoder.categories_[0]]
df_encoded = pd.DataFrame(one_hot_encoded, columns=feature_names)
# Initialize PCA
pca = PCA(n_components=2) # Adjust the number of components based on your needs
# Apply PCA
pca_transformed = pca.fit_transform(df_encoded)
# Creating a DataFrame with PCA components
df_pca = pd.DataFrame(pca_transformed, columns=['PCA1', 'PCA2'])
# Display the PCA-transformed DataFrame
print("PCA-Transformed DataFrame:")
print(df_pca)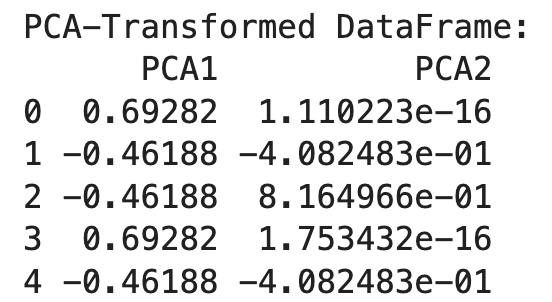
Chúng ta dùng OneHotEncoder để chuyển đặc trưng phân loại sang dạng one-hot. Kết quả là một DataFrame với các cột nhị phân cho từng hạng mục.
Sau đó, khởi tạo PCA với số thành phần mong muốn (n_components=2) và áp dụng cho dữ liệu đã one-hot. Kết quả là một DataFrame biến đổi với hai thành phần chính.
PCA giúp giảm chiều dữ liệu sau one-hot encoding, khiến dữ liệu dễ xử lý hơn trong khi vẫn giữ thông tin thiết yếu. Cách tiếp cận này đặc biệt hữu ích khi xử lý dữ liệu có số chiều cao do one-hot encoding.
Mặc dù one-hot encoding là công cụ mạnh mẽ, triển khai không đúng có thể dẫn đến các vấn đề như đa cộng tuyến hoặc kém hiệu quả khi xử lý dữ liệu mới. Hãy cùng tìm hiểu một số thực hành tốt và lưu ý.
Khi triển khai mô hình học máy, việc gặp các hạng mục trong tập kiểm thử không xuất hiện trong tập huấn luyện là điều thường gặp. OneHotEncoder của Scikit-learn có thể xử lý các hạng mục không biết bằng cách bỏ qua chúng hoặc gán vào một cột riêng, đảm bảo mô hình vẫn xử lý hiệu quả dữ liệu mới.
Ví dụ dưới đây minh họa cách fit bộ mã hóa trên dữ liệu huấn luyện rồi biến đổi cả dữ liệu huấn luyện và kiểm thử, bao gồm xử lý các hạng mục không có trong tập huấn luyện.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# Training data
X_train = [['Red'], ['Green'], ['Blue']]
# Creating the encoder with handle_unknown='ignore'
enc = OneHotEncoder(handle_unknown='ignore')
# Fitting the encoder to the training data
enc.fit(X_train)
# Transforming the training data
X_train_encoded = enc.transform(X_train).toarray()
print("Encoded training data:")
print(X_train_encoded)
# Test data with an unknown category 'Yellow'
X_test = [['Red'], ['Yellow'], ['Blue']]
# Transforming the test data
X_test_encoded = enc.transform(X_test).toarray()
print("Encoded test data:")
print(X_test_encoded)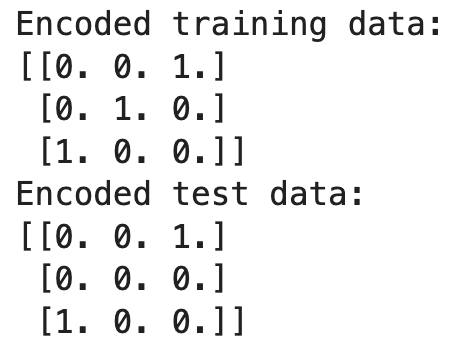
Trong ví dụ này, bộ mã hóa được fit trên dữ liệu huấn luyện, học các hạng mục 'Red', 'Green' và 'Blue'. Khi biến đổi dữ liệu kiểm thử, nó gặp 'Yellow', hạng mục không xuất hiện trong quá trình huấn luyện. Vì chúng ta đặt handle_unknown='ignore', bộ mã hóa tạo một hàng toàn số 0 cho 'Yellow', tức là bỏ qua hạng mục không biết.
Bằng cách xử lý hạng mục không biết theo cách này, chúng ta có thể đảm bảo mô hình xử lý hiệu quả dữ liệu mới, ngay cả khi chứa các hạng mục chưa từng thấy trước đó.
Sau khi áp dụng one-hot encoding, điều quan trọng là loại bỏ cột phân loại gốc khỏi tập dữ liệu. Giữ lại cột gốc có thể dẫn đến đa cộng tuyến, khi thông tin dư thừa ảnh hưởng đến hiệu năng mô hình. Hãy đảm bảo mỗi hạng mục chỉ được biểu diễn một lần trong tập dữ liệu để duy trì tính toàn vẹn.
Dưới đây là cách bạn có thể loại bỏ cột phân loại gốc sau khi áp dụng one-hot encoding để tránh đa cộng tuyến và đảm bảo mỗi hạng mục chỉ xuất hiện một lần trong tập dữ liệu.
import pandas as pd
# Sample data
data = {'Color': ['Red', 'Green', 'Blue', 'Red']}
df = pd.DataFrame(data)
# Applying one-hot encoding
df_encoded = pd.get_dummies(df, columns=['Color'])
# Displaying the encoded DataFrame
print("Encoded DataFrame:")
print(df_encoded)
Trong ví dụ này, chúng ta bắt đầu với một DataFrame chứa cột phân loại 'Color'. Chúng ta dùng pd.get_dummies() để áp dụng one-hot encoding cho cột 'Color', chỉ định columns=['Color'] để nêu rõ cột cần mã hóa. Cách này tự động loại bỏ cột 'Color' gốc và thay bằng các cột one-hot. DataFrame kết quả df_encoded giờ chứa các cột nhị phân biểu diễn mỗi hạng mục duy nhất, đảm bảo mỗi hạng mục chỉ xuất hiện một lần và loại bỏ nguy cơ đa cộng tuyến.
Loại bỏ cột phân loại gốc giúp duy trì tính toàn vẹn của tập dữ liệu và cải thiện hiệu năng mô hình học máy.
OneHotEncoder so với get_dummies()Việc lựa chọn giữa get_dummies() của Pandas và OneHotEncoder của Scikit-learn phụ thuộc vào nhu cầu của bạn. Với mã hóa nhanh và đơn giản, get_dummies() thuận tiện và dễ dùng. Với các kịch bản phức tạp đòi hỏi kiểm soát và linh hoạt hơn, như xử lý hạng mục không biết hoặc fit bộ mã hóa cho dữ liệu cụ thể, OneHotEncoder là lựa chọn tốt hơn.
One-hot encoding là một kỹ thuật mạnh mẽ và thiết yếu để chuyển đổi dữ liệu phân loại sang định dạng số phù hợp với các thuật toán học máy. Nó giúp nâng cao độ chính xác và hiệu quả của mô hình bằng cách tránh những hệ quả của tính thứ bậc giả và tạo điều kiện sử dụng dữ liệu phân loại.
Triển khai one-hot encoding trong Python rất đơn giản với các công cụ như get_dummies() của Pandas và OneHotEncoder của Scikit-learn. Hãy nhớ cân nhắc số chiều dữ liệu và xử lý hiệu quả các hạng mục không biết.
Nếu bạn muốn tìm hiểu thêm về chủ đề này, hãy xem khóa học về Tiền xử lý cho Học máy bằng Python.
Học học máy với những khóa học này!
Courses
Courses
Courses