
Kursus
Inferensi untuk Regresi Linear di R
4 Hr
16K
Model regresi linear banyak digunakan dalam statistik dan pembelajaran mesin untuk memprediksi nilai numerik berdasarkan fitur masukan, sekaligus memahami hubungan antarvariabel. Namun, hanya karena Anda bisa menarik sebuah garis melalui data Anda bukan berarti Anda harus melakukannya. Kita juga harus mendiagnosis kualitas kecocokan untuk menentukan apakah model sesuai untuk datanya atau perlu disesuaikan.
Ada beberapa cara untuk menguji model, termasuk mengevaluasi model menggunakan alur kerja train/test dan melihat statistik model seperti adjusted r-squared. Dalam artikel ini, saya akan berfokus pada cara membuat dan menafsirkan sebuah plot diagnostik khusus yang disebut plot Q-Q, dan saya akan menunjukkan beberapa metode untuk membuat plot Q-Q ini dalam bahasa pemrograman R. Untuk terus menguasai teknik regresi, ikuti Introduction to Regression in R atau Intermediate Regression in R atau, untuk Python, ikuti Introduction to Regression in Python atau Intermediate Regression in Python, sesuai tingkat kenyamanan Anda.
Plot Q-Q (Quantile-Quantile) digunakan untuk melihat apakah suatu dataset mengikuti distribusi teoretis tertentu. Caranya adalah dengan membandingkan kuantil data yang diamati dengan kuantil dari distribusi lain tersebut. Saya mengatakan ‘distribusi teoretis’ agar tepat, tetapi sering kali saat kita membuat plot Q-Q, kita sebenarnya memikirkan distribusi normal, atau Gaussian secara khusus, dan menyebutnya sebagai plot Q-Q normal. Namun, plot Q-Q juga dapat digunakan untuk membandingkan data dengan distribusi lain, seperti eksponensial, uniform, chi-kuadrat, t-distribution, distribusi Poisson, atau lainnya, tergantung konteks.
Akan lebih mudah dipahami dengan contoh. Di sini, saya membuat 10 angka. Untuk membangun plot Q-Q normal, pertama saya mengurutkan angkanya. Lalu, saya menghitung probabilitas dengan persamaan: q = (i– 0.5)/n. Selanjutnya, saya dapat menggunakan percent-point function (PPF) dari distribusi normal baku (fungsi qnorm()) untuk mencari nilai yang sesuai bagi peringkat tersebut. (Anda mungkin lebih akrab dengan cumulative distribution function (CDF), yang memberi tahu kita probabilitas hingga nilai x tertentu. Nah, PPF adalah kebalikannya: Ia memberi kita nilai x untuk probabilitas yang diberikan.)
Terakhir, untuk membuat grafiknya, kita plot kuantil dari nilai yang diamati terhadap kuantil teoretis (itulah dua huruf Q pada plot Q-Q). Garisnya dibentuk dengan menghitung kemiringan (slope) dan intersep menggunakan kuartil pertama dan ketiga dari distribusi yang diamati dan yang teoretis.
library(dplyr)
library(ggplot2)
# Create a data frame
data <- data.frame(
numbers = c(
-2.28261064680868, -0.91977039576432, -2.08595211862542,
1.29734993896137, -0.200143957176023, -0.693254525721567,
-3.90536265272207, 4.16373814964331, 2.3499592867344,
0.299856042823977
)
)
# Prepare Q-Q plot data
qq_data <- data %>%
arrange(numbers) %>% # Step 1: Arrange the numbers in ascending order
mutate(
rank = seq(1, n()), # Step 2: Rank each number from 1 to n
prob = (rank - 0.5) / n(), # Step 3: Calculate empirical cumulative probability
theoretical_quantile = qnorm(prob) # Step 4: Calculate theoretical quantiles
)
# Calculate slope and intercept for the Q-Q line
q1_obs <- quantile(qq_data$numbers, probs = 0.25)
q3_obs <- quantile(qq_data$numbers, probs = 0.75)
q1_theo <- qnorm(0.25)
q3_theo <- qnorm(0.75)
slope <- (q3_obs - q1_obs) / (q3_theo - q1_theo)
intercept <- q1_obs - slope * q1_theo
# Create the Q-Q plot
(qq_plot <- ggplot(data = qq_data, aes(x = theoretical_quantile, y = numbers)) +
geom_point(fill = '#01ef63', color = '#203147', shape = 21, size = 2) + # Points with a border
labs(title = "Q-Q Plot") +
geom_abline(slope = slope, intercept = intercept, color = '#203147', linetype = "dashed"))| Angka | Peringkat | Probabilitas (prob) | Kuantil Teoretis (qnorm(Probabilitas)) |
|---|---|---|---|
| -3.905363 | 1 | 0.05 | -1.644854 |
| -2.282611 | 2 | 0.15 | -1.036433 |
| -2.085952 | 3 | 0.25 | -0.674490 |
| -0.919770 | 4 | 0.35 | -0.385321 |
| -0.693255 | 5 | 0.45 | -0.125661 |
| -0.200144 | 6 | 0.55 | 0.125661 |
| 0.299856 | 7 | 0.65 | 0.385321 |
| 1.297350 | 8 | 0.75 | 0.674490 |
| 2.349959 | 9 | 0.85 | 1.036433 |
| 4.163738 | 10 | 0.95 | 1.644854 |

Plot Q-Q ilustratif. Gambar oleh Penulis
Plot Q-Q adalah cara visual yang baik untuk memeriksa asumsi distribusi. Ada cara lain untuk menguji apakah data mengikuti distribusi normal, seperti uji Shapiro-Wilk, misalnya, tetapi menurut saya tidak ada yang sevisual dan membuat ceritanya begitu jelas seperti plot Q-Q.
Mengetahui distribusi sesuatu penting dalam beberapa hal. Misalnya, kita mungkin ingin mengetahui ukuran pemusatan dan penyebaran yang terbaik. Selain itu, saat membuat regresi linear, kita ingin mengetahui apakah variabel dependen kita, khususnya, mengikuti distribusi normal, dan kita juga ingin melihat apakah residual dari model kita berdistribusi normal sehingga kita memiliki keyakinan yang lebih baik pada estimasi kita. Jadi secara garis besar, saya rasa plot Q-Q berguna untuk dua alasan umum: membandingkan data kita dengan distribusi contoh dan menguji kenormalan.
Sekarang mari lihat cara membuat plot Q-Q di R. Pada bagian ini, saya akan membahas tiga metode berbeda: base R, paket car, dan metode tidyverse. Anda akan melihat bahwa saya lebih menyukai metode tidyverse karena memberi fleksibilitas lebih untuk mempercantik grafik dan memiliki ekstensibilitas yang lebih baik dengan paket lain.
Untuk setiap metode, saya akan membuat plot Q-Q pada residual dari regresi linear sederhana, yang merupakan salah satu penggunaan paling umum—jika bukan yang paling umum—dari plot Q-Q. Namun, Anda juga dapat membuat plot Q-Q untuk memeriksa distribusi variabel sebelum membuat regresi linear. Yang Anda butuhkan hanyalah distribusi satu variabel dan distribusi teoretis untuk dibandingkan.
Jika Anda ingin mengikuti, Anda bisa mengunduh dataset Kaggle yang saya gunakan: Car Prices Jordan 2023.
Pertama mari membuat plot Q-Q di base R, artinya kita tidak akan memasang paket tambahan apa pun dan hanya menggunakan fungsi bawaan.
# Importing data (in this example, saved on the desktop)
car_prices_jordan <- read.csv('~/Desktop/car_prices_jordan.csv')
# Create a linear model
car_linear_model <- lm(Price ~ sqrt(Price), data = filtered_car_prices)
# Extract the residuals
residuals <- resid(car_linear_model)
# Q-Q plot of residuals
qqnorm(residuals, main = "Q-Q Plot of Residuals from Linear Regression")
qqline(residuals, col = "red")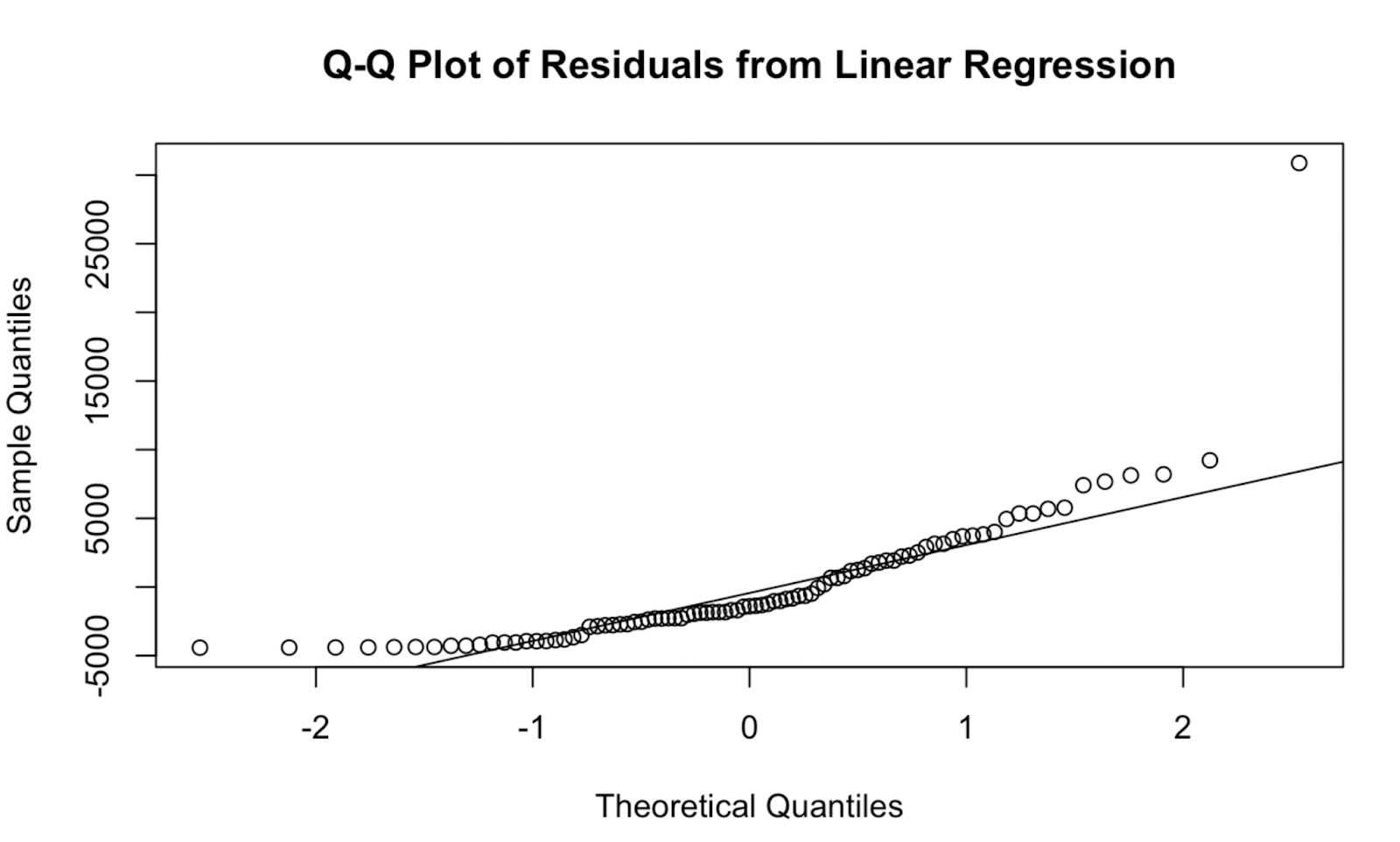 Plot Q-Q dibuat di base R. Gambar oleh Penulis
Plot Q-Q dibuat di base R. Gambar oleh Penulis
Sekarang, mari coba membuat plot Q-Q menggunakan paket car. Menurut saya, kualitas visualisasinya tidak terlalu berbeda, tetapi plot Q-Q ini memiliki keunggulan berupa amplop kepercayaan, yang mendefinisikan area tempat titik data diharapkan berada jika asumsi kenormalan model benar.
# Install and load the 'car' package
# install.packages("car") # Uncomment this line if the 'car' package is not installed
library(car)
# Q-Q plot of residuals using the 'car' package
car::qqPlot(car_linear_model, main = "Q-Q Plot of Residuals from Linear Regression")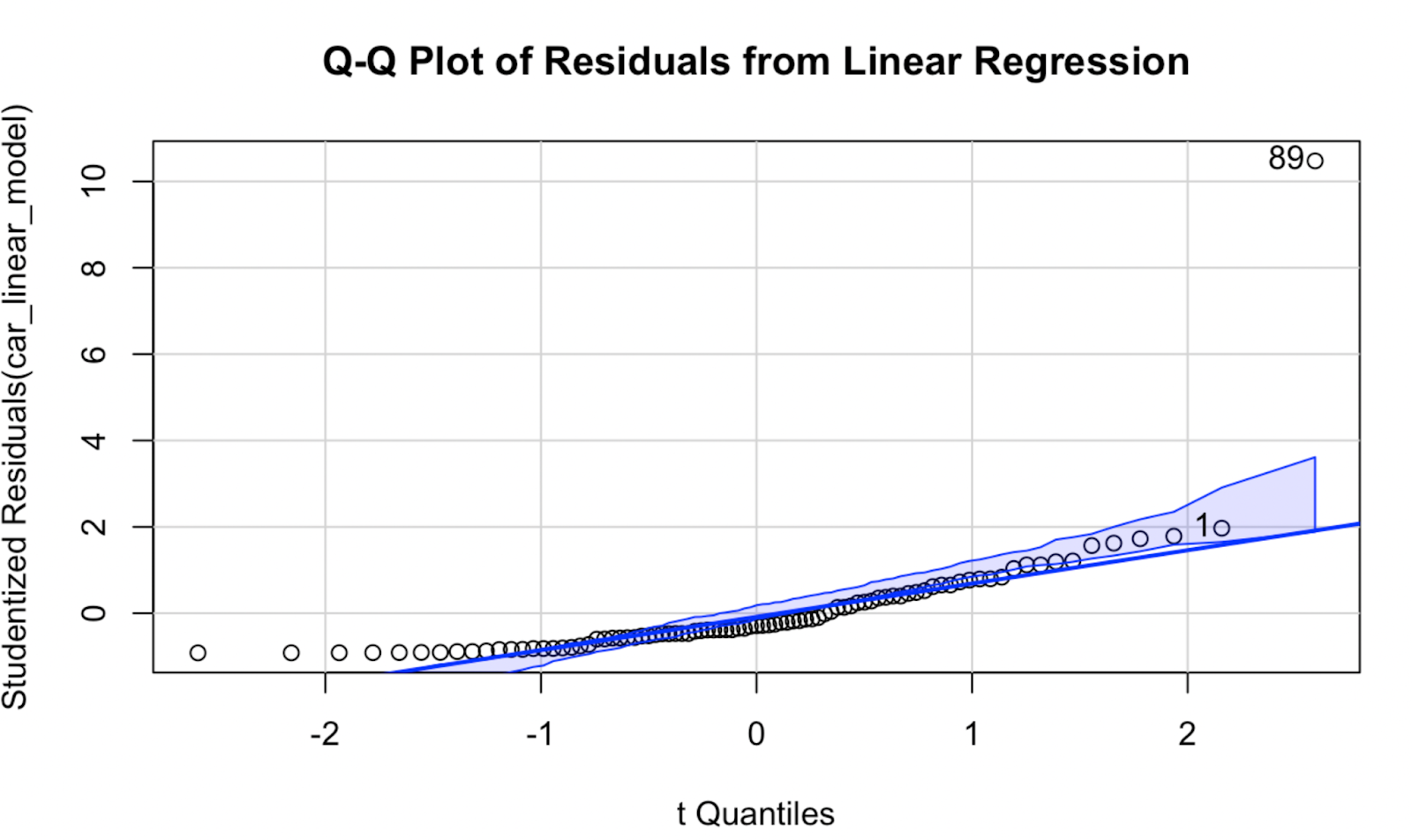 Plot Q-Q dibuat menggunakan paket car di R. Gambar oleh Penulis
Plot Q-Q dibuat menggunakan paket car di R. Gambar oleh Penulis
Sekarang mari lihat cara membuat plot Q-Q menggunakan metode tidyverse untuk fleksibilitas lebih dan tampilan yang lebih baik. Kali ini, saya akan menempatkan plot Q-Q sebagai panel di samping scatterplot asli saya.
# Load necessary libraries
library(tidyverse)
library(metBrewer)
# Clean and convert Power and Price columns to numeric
car_prices_jordan$Power <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Power))
car_prices_jordan$Price <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Price))
# Calculate slope and intercept for linear regression line
slope <- (cor(car_prices_jordan$Power, car_prices_jordan$Price) *
(sd(car_prices_jordan$Price)) /
sd(car_prices_jordan$Power))
intercept <- (mean(car_prices_jordan$Price) - slope * mean(car_prices_jordan$Power))
# Create scatter plot with regression line
car_prices_graph <- ggplot(car_prices_jordan, aes(x = Power, y = Price)) +
geom_point() +
ggtitle("Car Prices in Jordan") +
geom_abline(slope = slope, intercept = intercept, color = '#376795', size = 1)
# Fit a linear model
car_linear_model <- lm(Price ~ Power, data = car_prices_jordan)
# Generate Q-Q plot for residuals
qq_plot <- ggplot(data = data.frame(resid = residuals(car_linear_model)), aes(sample = resid)) +
stat_qq() +
stat_qq_line(linetype = 'dashed', color = '#ef8a47', size = 1) +
labs(
title = "Car Prices in Jordan",
subtitle = "Residual QQ Plot"
)
# Combine scatter plot and Q-Q plot using patchwork
library(patchwork)
car_prices_graph + qq_plot
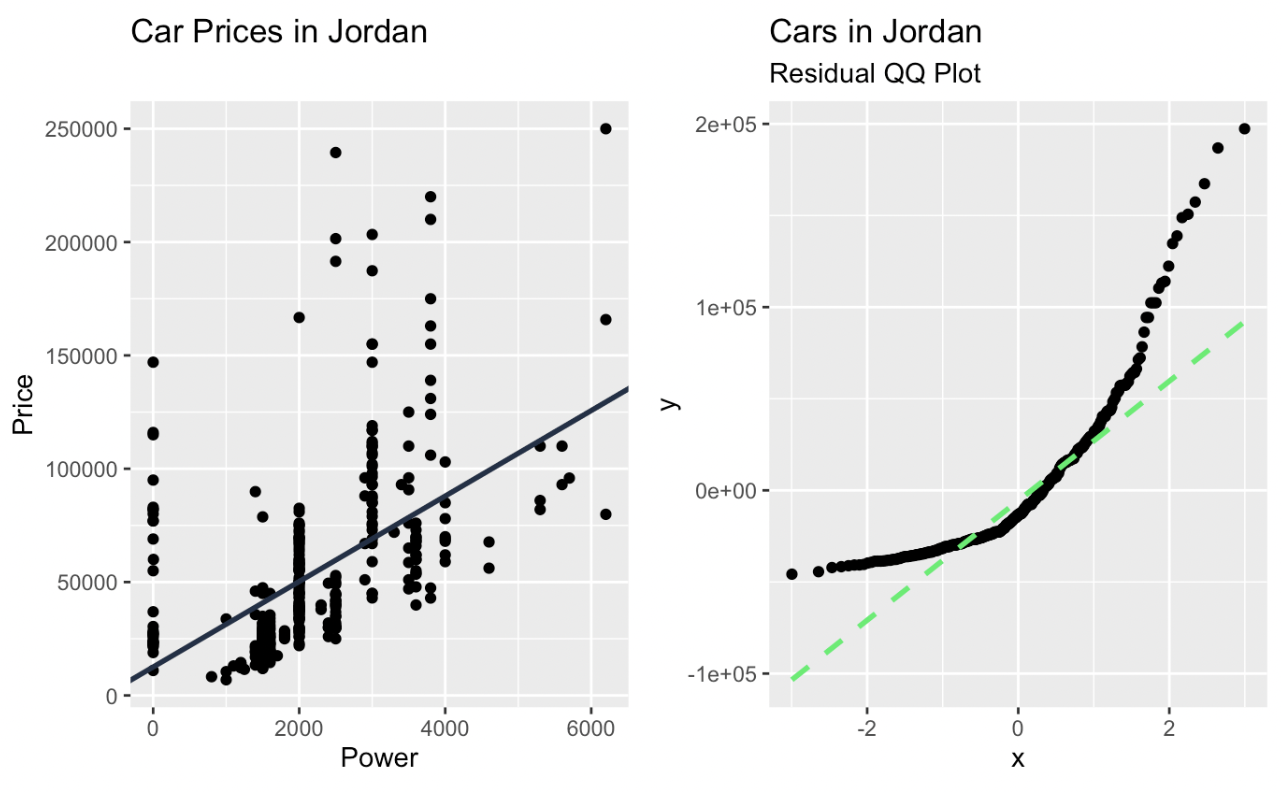
Regresi linear dan plot Q-Q residual yang dibuat di ggplot2. Gambar oleh Penulis
Dengan plot Q-Q, kuantil data yang diamati diplot terhadap kuantil teoretis. Jika data mengikuti distribusi teoretis dengan baik, titik-titik pada plot Q-Q akan bergerak pada garis diagonal. Penyimpangan dari garis ini menunjukkan penyimpangan dari distribusi yang diharapkan. Titik yang berada di atas atau di bawah garis menunjukkan skewness atau outlier, dan pola seperti kurva atau deviasi berbentuk S mengindikasikan perbedaan sistematis, seperti ekor yang lebih berat atau lebih ringan.
Ada sekitar tiga hal yang kita cari.
Mari tunjukkan dengan contoh untuk masing-masing:
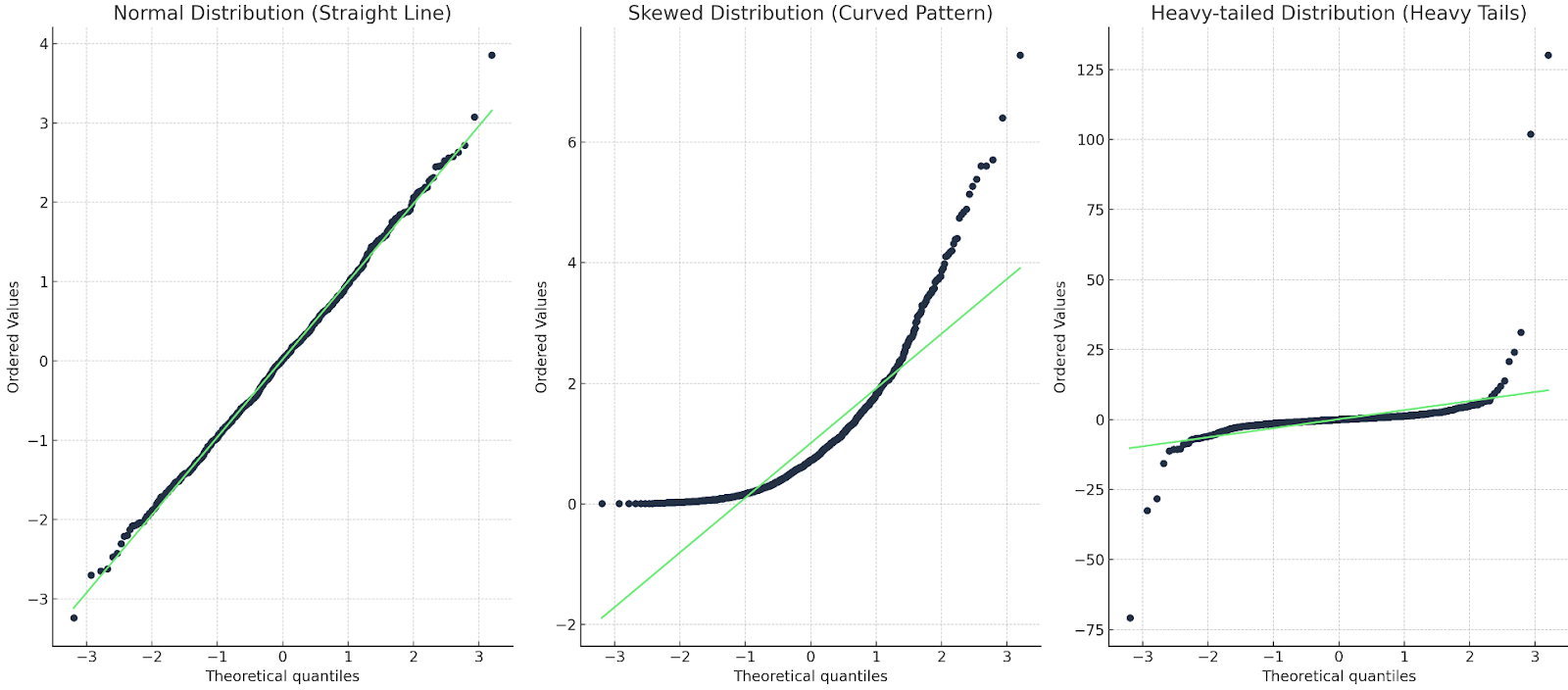
Tiga plot Q-Q: satu dengan garis lurus; satu dengan kurva; satu dengan ekor berat. Gambar oleh Penulis
Pada kasus pertama, garis Q-Q cocok dengan titik data, sehingga distribusinya memang normal. Pada kasus kedua, kita melihat pola melengkung, sehingga datanya tidak normal atau miring. Pada kasus terakhir, kita melihat semacam bentuk ‘s’, sehingga distribusinya memiliki ekor berat atau nilai yang lebih ekstrem.
Ada beberapa asumsi model linear, termasuk linearitas (bahwa hubungan antarvariabel bersifat linear), kemandirian galat (bahwa galat tidak berkorelasi satu sama lain), homoskedastisitas (bahwa residual memiliki varians konstan), dan kenormalan residual (bahwa residual mengikuti distribusi normal). Plot Q-Q khususnya membantu asumsi keempat, yaitu kenormalan residual.
Begini bagaimana pola yang berbeda memengaruhi interpretasi dan keandalan model kita:
Jika Anda familier dengan plot diagnostik model linear, Anda mungkin juga tahu ada cukup banyak opsi untuk menilai kecocokan model. Agar benar-benar memahami apa yang ditampilkan plot Q-Q, mari lihat beberapa diagnostik lain. Ini akan membantu kita lebih memahami apa yang dilakukan plot Q-Q dan plot lain apa yang dapat melengkapinya.
Saya akan tunjukkan secara singkat cara membuat setiap plot menggunakan metode tidyverse. Tujuannya di sini bukan untuk menafsirkan model linear dari dataset “Cars in Jordan” kita untuk setiap diagnostik model linear dalam daftar ini. Sebaliknya, saya ingin menunjukkan plot diagnostik lain agar Anda dapat mengenalinya, menggunakan kodenya jika bermanfaat, dan—sesuai tujuan artikel ini—agar Anda bisa menempatkan plot Q-Q di antara plot diagnostik lainnya. Dengan begitu, Anda akan lebih memahami apa yang ditunjukkan dan tidak ditunjukkan oleh plot Q-Q, bagaimana plot ini membantu, dan apa yang luput darinya.
fitted_values_vs_residuals <- ggplot(data = car_linear_model, aes(x = .fitted, y = .resid)) +
geom_point(color = '#203147') +
geom_hline(yintercept = 0, linetype = "dashed", color = '#01ef63', size = 1) +
xlab("fitted values") +
ylab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Fitted Values vs Residuals")
histogram_of_residuals <- ggplot(data = car_linear_model, aes(x = .resid)) +
geom_histogram(color = '#01ef63') +
xlab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Histogram of Residuals")
scale_location <- ggplot(car_linear_model, aes(.fitted, sqrt(abs(.stdresid)))) +
geom_point(color = '#203147', na.rm=TRUE) +
stat_smooth(method="loess", na.rm = TRUE, color = '#01ef63', size = 1, se = FALSE) +
xlab("Fitted Value") +
ylab(expression(sqrt("|Standardized residuals|"))) +
labs(title = "Cars in Jordan") +
labs(subtitle = "Scale-Location")
leverage_vs_standardized_residuals <- ggplot(data = car_linear_model, aes(.hat, .stdresid)) +
geom_point(aes(size = .cooksd), color = '#203147') +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage") +
ylab("Standardized Residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Residuals vs Leverage") +
scale_size_continuous("Cook's Distance", range=c(1,5)) +
theme(legend.title = element_blank()) +
theme(legend.position= "none")
observation_number_vs_cooks_distance <- ggplot(car_linear_model, aes(seq_along(.cooksd), .cooksd)) +
geom_bar(stat="identity", position="identity", color = '#01ef63', size = 1) +
xlab("Obs. Number") +
ylab("Cook's distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's distance")
leverage_vs_cooks_distance <- ggplot(car_linear_model, aes(.hat, .cooksd))+geom_point(na.rm=TRUE) +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage hii")+
ylab("Cook's Distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's dist vs Leverage hii/(1-hii)") +
geom_abline(slope=seq(0,3,0.5), color = "gray", linetype = "dotdash")
library(patchwork)
fitted_values_vs_residuals + histogram_of_residuals
library(patchwork)
scale_location + leverage_vs_standardized_residuals
library(patchwork)
observation_number_vs_cooks_distance + leverage_vs_cooks_distance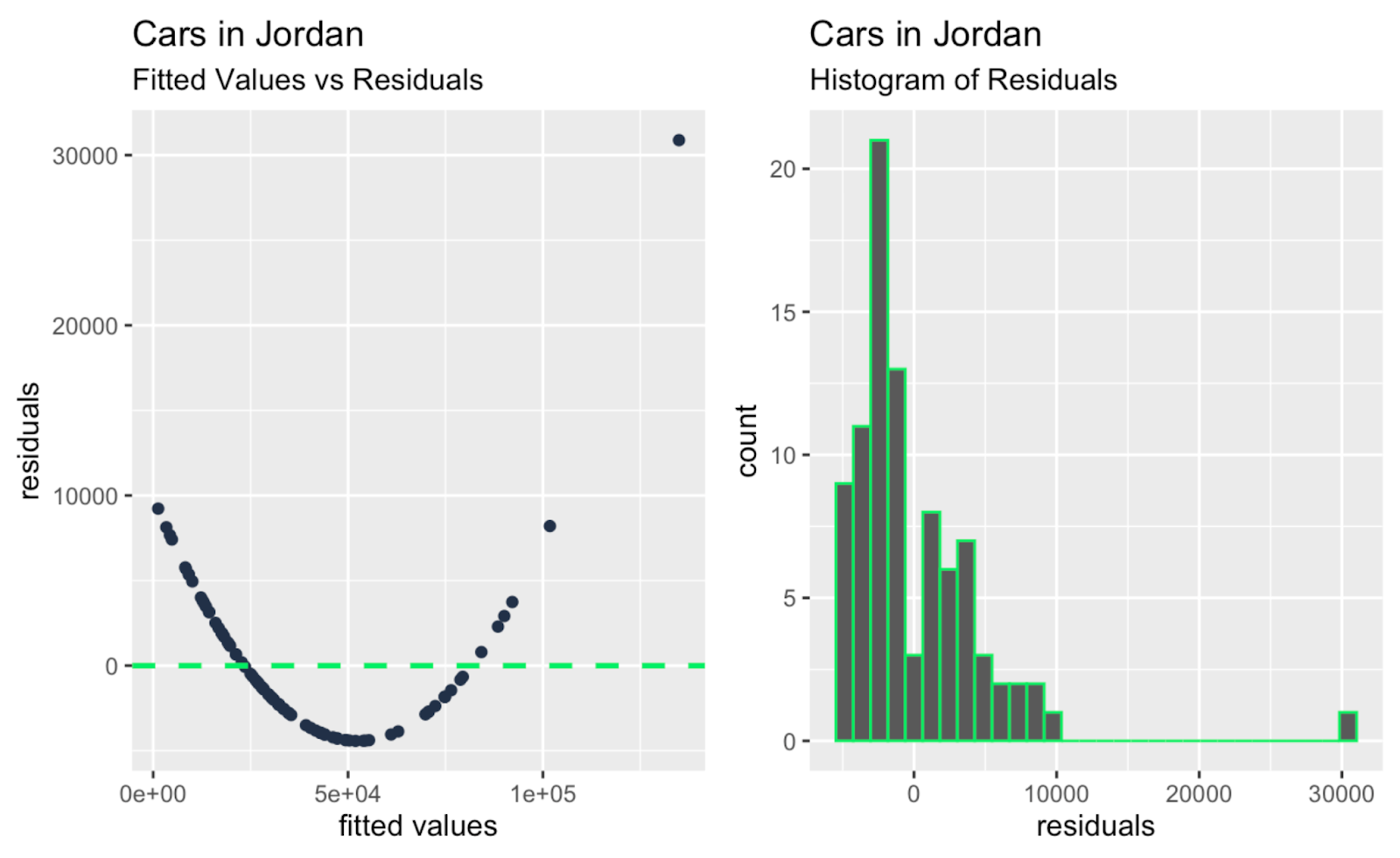
Nilai terpasang versus residual; histogram residual. Gambar oleh Penulis
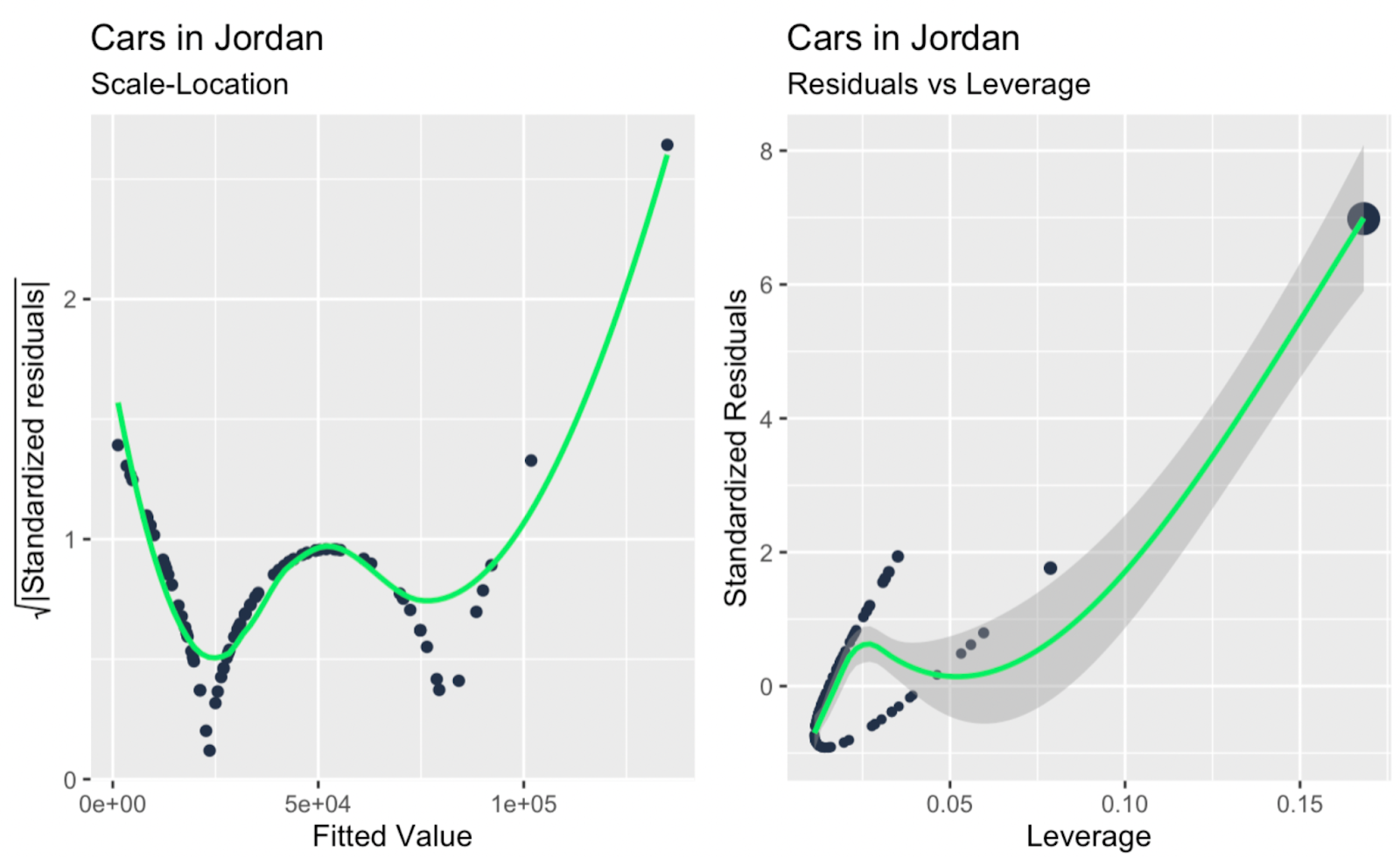
Plot skala-lokasi; leverage versus residual ternormalisasi. Gambar oleh Penulis
Nomor observasi versus jarak Cook; jarak Cook versus leverage. Gambar oleh Penulis
Mungkin hal utama yang bisa disimpulkan, sekilas melihat semua plot diagnostik tambahan di atas, adalah adanya satu atau dua outlier besar yang berdampak besar pada kemiringan garis regresi, dan outlier ini tidak begitu jelas saat hanya melihat plot Q-Q. Jadi plot Q-Q pada contoh kita menjalankan fungsinya—menguji kenormalan residual—dan juga mengungkap keterbatasan, yakni tidak membahas kemandirian, homoskedastisitas, atau outlier.
Untuk referensi tambahan, saya sertakan tabel tingkat tinggi yang menunjukkan asumsi model linear mana yang diuji dengan setiap plot diagnostik, dan saya juga menyarankan bagaimana plot diagnostik lain dapat bekerja berdampingan dengan plot Q-Q. Perlu diingat bahwa, tergantung pada data, berbagai jenis pola dapat terungkap dengan plot diagnostik yang berbeda, dan hal-hal tertentu mungkin terlihat jika digunakan bersama. Misalnya, plot Q-Q dapat mengonfirmasi kenormalan, sementara plot skala-lokasi dapat mengidentifikasi heteroskedastisitas, dan Anda mungkin hanya melihat kenormalan dan heteroskedastisitas jika menggunakan keduanya.
| Jenis Plot Diagnostik | Membantu Dengan | Cara Kerjanya dengan Plot Q-Q |
|---|---|---|
| Plot Q-Q | Kenormalan residual | |
| Histogram Residual | Kenormalan residual | Menyediakan visual cepat dan gambaran umum simetri serta penyebaran. |
| Nilai Terpasang versus Residual | Linearitas, kemandirian galat | Mengungkap pola dan non-linearitas, melengkapi pemeriksaan kenormalan pada plot Q-Q. |
| Plot Skala-Lokasi | Homoskedastisitas | Menyoroti konsistensi sebaran residual, melengkapi plot Q-Q untuk pemeriksaan kenormalan. |
| Plot Leverage versus Residual | Kemandirian galat | Berfokus pada titik ber-leverage tinggi, yang tidak dibahas oleh plot Q-Q. |
| Nomor Observasi versus Jarak Cook | Mengidentifikasi titik berpengaruh | Melengkapi plot Q-Q dengan mencari outlier yang berpengaruh tinggi. |
| Plot Leverage versus Jarak Cook | Mengidentifikasi titik ber-leverage tinggi | Menyoroti observasi berpengaruh, sementara plot Q-Q memvalidasi kenormalan. |
Saya harap Anda memiliki apresiasi baru terhadap plot Q-Q sebagai alat yang berguna untuk menilai kenormalan dan memiliki pemahaman yang lebih baik tentang penggunaannya yang umum dalam menilai kenormalan residual pada regresi linear. Saya juga berharap Anda memiliki apresiasi baru terhadap gagasan dan pentingnya diagnostik model linear secara umum.
Terus pelajari regresi linear dengan Multiple Linear Regression in R: Tutorial With Examples yang membahas model lebih kompleks dengan banyak prediktor, termasuk gagasan multikolinearitas dalam regresi. Saya sangat menyarankan mendaftar ke jalur karier lengkap dan komprehensif kami, Machine Learning Scientist in Python, untuk mempelajari seluruh alur kerja pembuatan model, termasuk pembelajaran terawasi dan tak terawasi.
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
