
Cursus
Inference for Linear Regression in R
4 Hr
16K
Lineaire regressiemodellen worden veel gebruikt in statistiek en machine learning om numerieke waarden te voorspellen op basis van inputkenmerken, en ook om de relatie tussen variabelen te begrijpen. Maar het feit dat je een lijn door je data kunt trekken, betekent nog niet dat je dat ook moet doen. We moeten ook de kwaliteit van de fit beoordelen om te bepalen of het model geschikt is voor de data of dat het verfijnd moet worden.
Er zijn verschillende manieren om een model te toetsen, waaronder het evalueren via een train/test-werkwijze en het bekijken van modelstatistieken zoals aangepaste r-kwadraat. In dit artikel richt ik me op het maken en interpreteren van een specifieke diagnostische plot, de Q-Q-plot, en laat ik je enkele methoden zien om deze Q-Q-plot te maken in de programmeertaal R. Wil je regressietechnieken echt onder de knie krijgen, volg dan Introduction to Regression in R of Intermediate Regression in R of, voor Python, Introduction to Regression in Python of Intermediate Regression in Python, afhankelijk van je niveau.
Een Q-Q- (Quantile-Quantile) plot wordt gebruikt om te zien of een dataset een bepaalde theoretische verdeling volgt. Dat gebeurt door de kwantielen van de geobserveerde data te vergelijken met de kwantielen van die andere verdeling. Ik zei ‘theoretische verdeling’ om precies te zijn, maar vaak denken we bij een Q-Q-plot specifiek aan de normale, of Gaussische, verdeling, en hebben we het over een normale Q-Q-plot. Q-Q-plots kunnen echter ook worden gebruikt om data te vergelijken met andere verdelingen, zoals exponentieel, uniform, chi-kwadraat, t-verdeling, Poissonverdeling, of andere, afhankelijk van de context.
Het is handig om dit met een voorbeeld te bekijken. Hier heb ik 10 getallen gemaakt. Om een normale Q-Q-plot te construeren, zet ik eerst de getallen op volgorde. Vervolgens bereken ik de kans met deze vergelijking: q = (i– 0.5)/n. Daarna kan ik de percent-point function (PPF) van de standaardnormale verdeling (de functie qnorm()) gebruiken om de bijbehorende waarde voor de rang te vinden. (Je kent misschien de cumulatieve verdelingsfunctie (CDF), die de kans tot en met een waarde x geeft. De PPF is eigenlijk het omgekeerde: die geeft ons de x-waarde voor een gegeven kans.)
Tot slot, om de grafiek te maken, plotten we de kwantielen van onze geobserveerde waarden tegen de theoretische kwantielen (vandaar de twee Q’s in Q-Q-plot). De lijn wordt geconstrueerd door de helling en het snijpunt te berekenen met behulp van het eerste en derde kwartiel van zowel de geobserveerde als de theoretische verdeling.
library(dplyr)
library(ggplot2)
# Create a data frame
data <- data.frame(
numbers = c(
-2.28261064680868, -0.91977039576432, -2.08595211862542,
1.29734993896137, -0.200143957176023, -0.693254525721567,
-3.90536265272207, 4.16373814964331, 2.3499592867344,
0.299856042823977
)
)
# Prepare Q-Q plot data
qq_data <- data %>%
arrange(numbers) %>% # Step 1: Arrange the numbers in ascending order
mutate(
rank = seq(1, n()), # Step 2: Rank each number from 1 to n
prob = (rank - 0.5) / n(), # Step 3: Calculate empirical cumulative probability
theoretical_quantile = qnorm(prob) # Step 4: Calculate theoretical quantiles
)
# Calculate slope and intercept for the Q-Q line
q1_obs <- quantile(qq_data$numbers, probs = 0.25)
q3_obs <- quantile(qq_data$numbers, probs = 0.75)
q1_theo <- qnorm(0.25)
q3_theo <- qnorm(0.75)
slope <- (q3_obs - q1_obs) / (q3_theo - q1_theo)
intercept <- q1_obs - slope * q1_theo
# Create the Q-Q plot
(qq_plot <- ggplot(data = qq_data, aes(x = theoretical_quantile, y = numbers)) +
geom_point(fill = '#01ef63', color = '#203147', shape = 21, size = 2) + # Points with a border
labs(title = "Q-Q Plot") +
geom_abline(slope = slope, intercept = intercept, color = '#203147', linetype = "dashed"))| Numbers | Rank | Probability (prob) | Theoretical Quantile (qnorm(Probability)) |
|---|---|---|---|
| -3.905363 | 1 | 0.05 | -1.644854 |
| -2.282611 | 2 | 0.15 | -1.036433 |
| -2.085952 | 3 | 0.25 | -0.674490 |
| -0.919770 | 4 | 0.35 | -0.385321 |
| -0.693255 | 5 | 0.45 | -0.125661 |
| -0.200144 | 6 | 0.55 | 0.125661 |
| 0.299856 | 7 | 0.65 | 0.385321 |
| 1.297350 | 8 | 0.75 | 0.674490 |
| 2.349959 | 9 | 0.85 | 1.036433 |
| 4.163738 | 10 | 0.95 | 1.644854 |

Illustratieve Q-Q-plot. Afbeelding door de auteur
Een Q-Q-plot is een fijne, visuele manier om aannames over verdelingen te controleren. Er zijn ook andere manieren om te testen of data een normale verdeling volgt, zoals de Shapiro-Wilk-toets, maar niets is naar mijn mening zo visueel en maakt het verhaal zo duidelijk als de Q-Q-plot.
Het kennen van de verdeling is op meerdere manieren belangrijk. Zo willen we waarschijnlijk de beste maten voor centrum en spreiding kiezen. En bij het maken van een lineaire regressie willen we weten of onze afhankelijke variabele in het bijzonder een normale verdeling volgt, en we willen ook zien of de residuen van ons model normaal verdeeld zijn, zodat we meer vertrouwen hebben in onze schattingen. Kortom, ik denk dat Q-Q-plots om twee algemene redenen nuttig zijn: het vergelijken van onze data met steekproefverdelingen en het testen op normaliteit.
Laten we nu kijken hoe je een Q-Q-plot in R maakt. In deze sectie behandel ik drie verschillende methoden: base R, het pakket car en tidyverse-methoden. Je zult zien dat ik de voorkeur geef aan tidyverse-methoden omdat je daarmee de grafiek flexibeler en mooier kunt maken, en omdat ze beter uitbreidbaar zijn met andere pakketten.
Voor elke methode maak ik een Q-Q-plot van de residuen van een eenvoudige lineaire regressie, een van de meest voorkomende toepassingen — zo niet de meest voorkomende — van de Q-Q-plot. Je kunt echter ook een Q-Q-plot maken om de verdeling van variabelen te controleren voordat je überhaupt een lineaire regressie opstelt. Alles wat je nodig hebt is de verdeling van één variabele en een theoretische verdeling om mee te vergelijken.
Als je wilt meekijken, kun je de Kaggle-dataset downloaden die ik gebruik: Car Prices Jordan 2023.
Laten we eerst een Q-Q-plot maken in base R, dus zonder extra pakketten te installeren en alleen met ingebouwde functies.
# Importing data (in this example, saved on the desktop)
car_prices_jordan <- read.csv('~/Desktop/car_prices_jordan.csv')
# Create a linear model
car_linear_model <- lm(Price ~ sqrt(Price), data = filtered_car_prices)
# Extract the residuals
residuals <- resid(car_linear_model)
# Q-Q plot of residuals
qqnorm(residuals, main = "Q-Q Plot of Residuals from Linear Regression")
qqline(residuals, col = "red")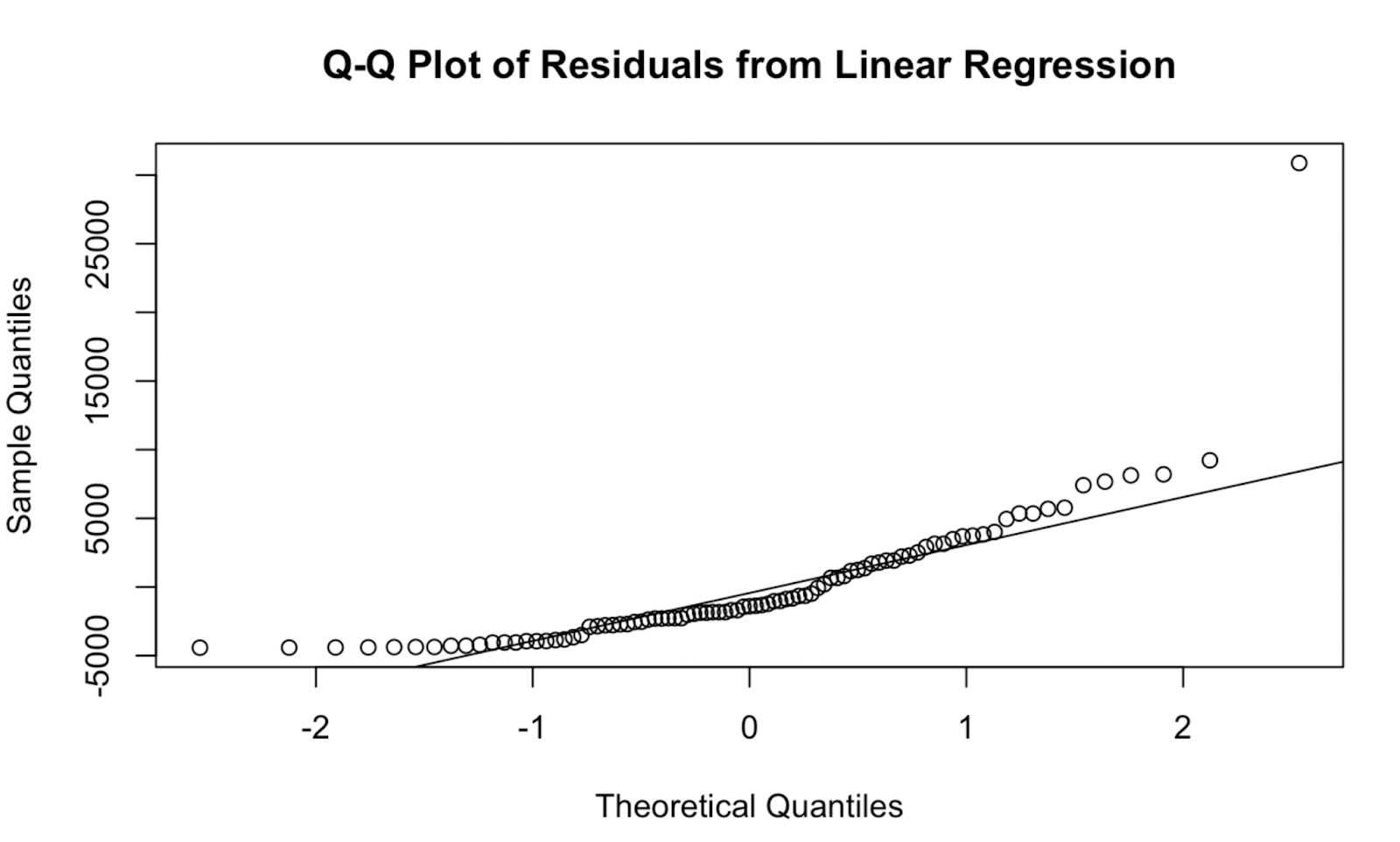 Q-Q-plot gemaakt in base R. Afbeelding door de auteur
Q-Q-plot gemaakt in base R. Afbeelding door de auteur
Laten we nu een Q-Q-plot maken met het pakket car. Naar mijn mening verschilt de kwaliteit van de visualisatie niet heel veel, maar deze Q-Q-plot heeft als voordeel dat hij een betrouwbaarheidsenvelop toont, die het gebied afbakent waarbinnen onze datapunten naar verwachting liggen als de modelaanname van normaliteit waar is.
# Install and load the 'car' package
# install.packages("car") # Uncomment this line if the 'car' package is not installed
library(car)
# Q-Q plot of residuals using the 'car' package
car::qqPlot(car_linear_model, main = "Q-Q Plot of Residuals from Linear Regression")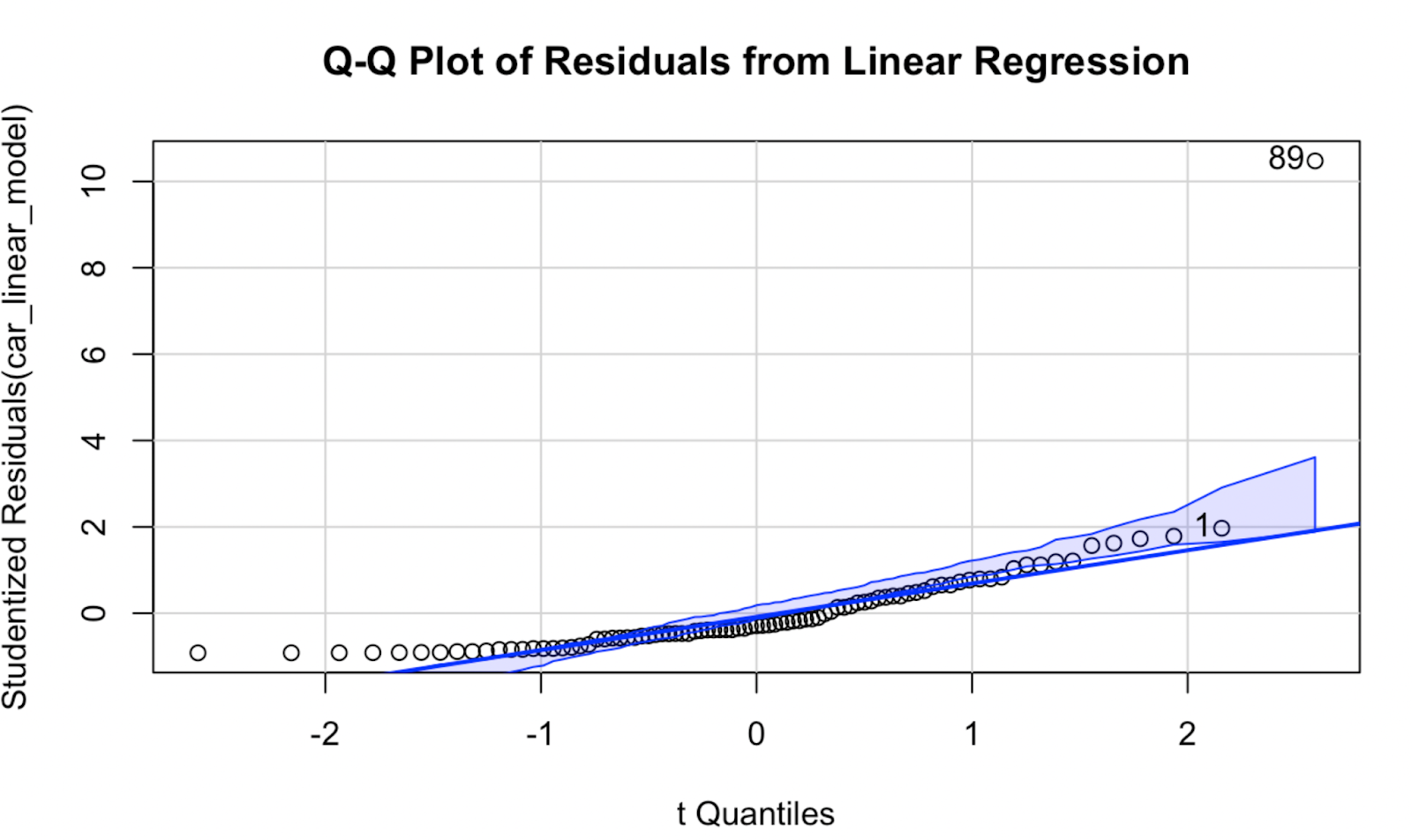 Q-Q-plot gemaakt met het car-pakket in R. Afbeelding door de auteur
Q-Q-plot gemaakt met het car-pakket in R. Afbeelding door de auteur
Nu kijken we hoe je een Q-Q-plot maakt met tidyverse-methoden voor meer flexibiliteit en een fraaiere opmaak. Dit keer zet ik de Q-Q-plot als paneel naast mijn oorspronkelijke scatterplot.
# Load necessary libraries
library(tidyverse)
library(metBrewer)
# Clean and convert Power and Price columns to numeric
car_prices_jordan$Power <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Power))
car_prices_jordan$Price <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Price))
# Calculate slope and intercept for linear regression line
slope <- (cor(car_prices_jordan$Power, car_prices_jordan$Price) *
(sd(car_prices_jordan$Price)) /
sd(car_prices_jordan$Power))
intercept <- (mean(car_prices_jordan$Price) - slope * mean(car_prices_jordan$Power))
# Create scatter plot with regression line
car_prices_graph <- ggplot(car_prices_jordan, aes(x = Power, y = Price)) +
geom_point() +
ggtitle("Car Prices in Jordan") +
geom_abline(slope = slope, intercept = intercept, color = '#376795', size = 1)
# Fit a linear model
car_linear_model <- lm(Price ~ Power, data = car_prices_jordan)
# Generate Q-Q plot for residuals
qq_plot <- ggplot(data = data.frame(resid = residuals(car_linear_model)), aes(sample = resid)) +
stat_qq() +
stat_qq_line(linetype = 'dashed', color = '#ef8a47', size = 1) +
labs(
title = "Car Prices in Jordan",
subtitle = "Residual QQ Plot"
)
# Combine scatter plot and Q-Q plot using patchwork
library(patchwork)
car_prices_graph + qq_plot
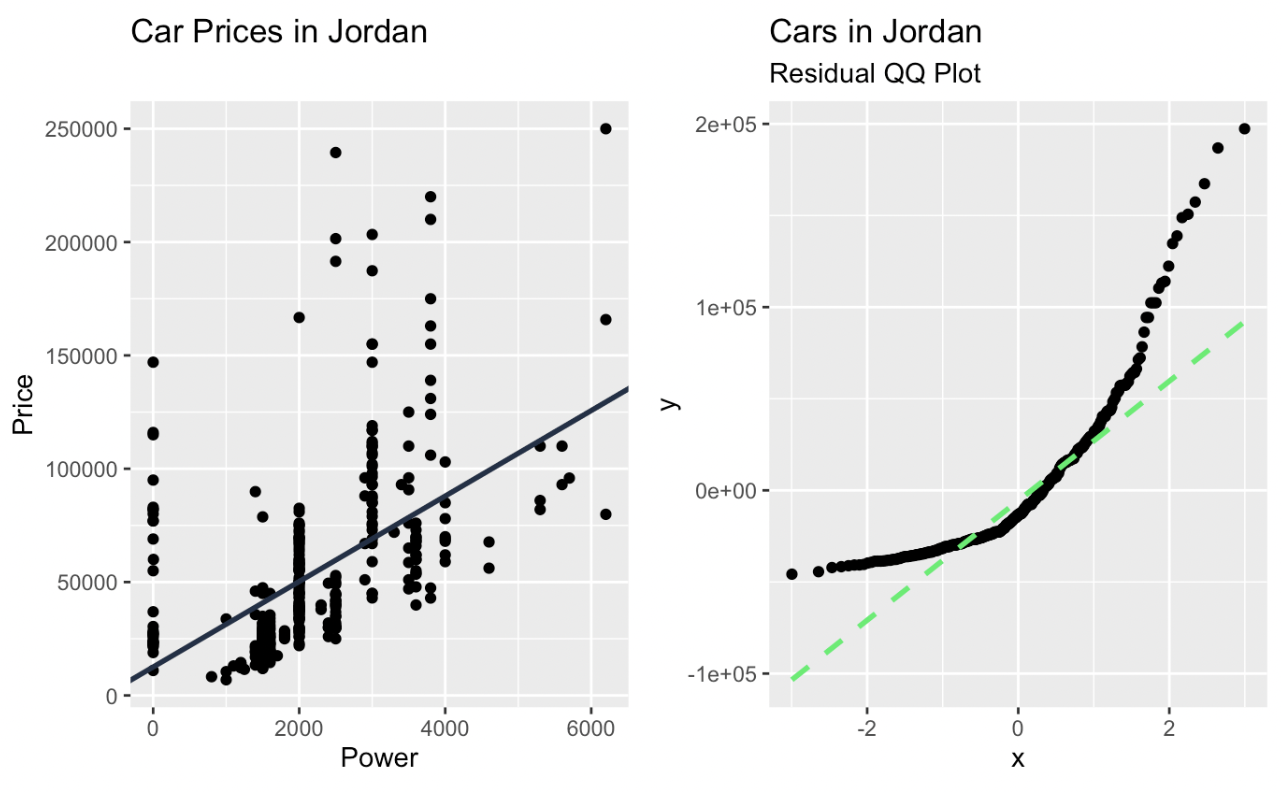
Lineaire regressie en een Q-Q-plot van de residuen gemaakt in ggplot2. Afbeelding door de auteur
Bij een Q-Q-plot worden de kwantielen van de geobserveerde data uitgezet tegen de theoretische kwantielen. Als de data de theoretische verdeling nauw volgt, liggen de punten op de Q-Q-plot op een diagonale lijn. Afwijkingen van deze lijn duiden op afwijkingen van de verwachte verdeling. Punten die boven of onder de lijn vallen, suggereren scheefheid of uitschieters, en patronen zoals krommen of s-vormige afwijkingen wijzen op systematische verschillen, zoals zwaardere of lichtere staarten.
We letten op ongeveer drie dingen.
Laten we voor elk een voorbeeld laten zien:
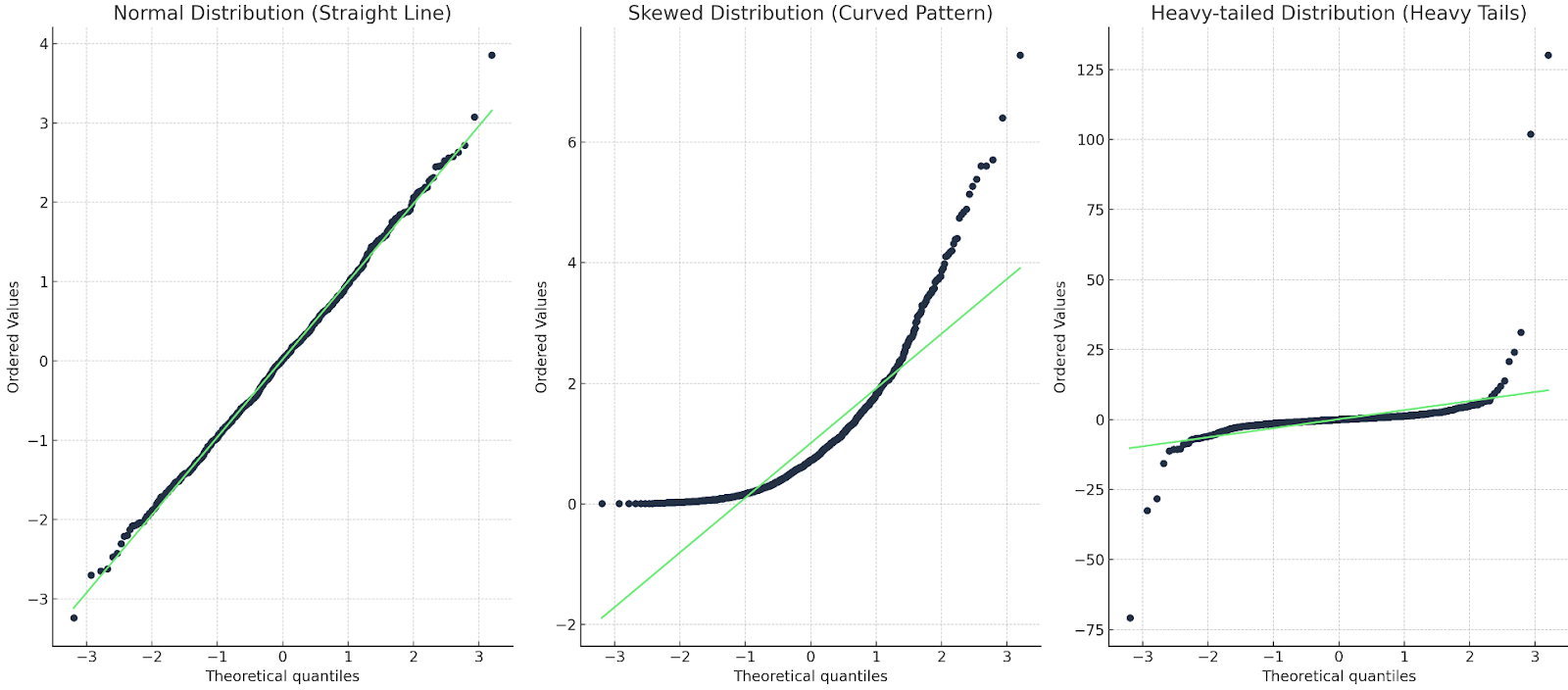
Drie Q-Q-plots: één met een rechte lijn; één met een kromme; één met een zware staart. Afbeelding door de auteur
In het eerste geval komt de Q-Q-lijn overeen met de datapunten, dus de verdeling is inderdaad normaal. In het tweede geval zien we een gebogen patroon, dus de data is ofwel niet normaal ofwel scheef. In het laatste geval zien we een soort ‘s’-vorm, dus de verdeling heeft zware staarten of meer extreme waarden.
Er zijn verschillende aannames bij lineaire modellen, waaronder lineariteit (dat de relatie tussen variabelen lineair is), onafhankelijkheid van fouten (dat de fouten niet met elkaar gecorreleerd zijn), homoscedasticiteit (dat de residuen een constante variantie hebben), en normaliteit van residuen (dat de residuen een normale verdeling volgen). De Q-Q-plot helpt in het bijzonder bij die vierde aanname, de normaliteit van residuen.
Zo beïnvloeden verschillende patronen de interpretatie en betrouwbaarheid van ons model:
Als je bekend bent met diagnostische plots voor lineaire modellen, weet je dat er nogal wat opties zijn om de modelfit te beoordelen. Om precies te begrijpen wat de Q-Q-plot laat zien, kijken we naar een paar andere diagnostics. Dat helpt ons beter te begrijpen wat de Q-Q-plot doet en welke andere plots hem kunnen aanvullen.
Ik laat je snel zien hoe je elke plot maakt met tidyverse-methoden. Het doel hier is niet om het lineaire model van onze dataset “Cars in Jordan” te interpreteren voor elke diagnostische plot op deze lijst. Ik wil de andere diagnostische plots laten zien zodat je ze kunt herkennen, de code kunt gebruiken als die handig is en — in lijn met dit artikel — zodat je de Q-Q-plot beter kunt plaatsen tussen de andere diagnostische plots. Zo begrijp je beter wat de Q-Q-plot wel en niet laat zien, hoe hij helpt en wat hij mist.
fitted_values_vs_residuals <- ggplot(data = car_linear_model, aes(x = .fitted, y = .resid)) +
geom_point(color = '#203147') +
geom_hline(yintercept = 0, linetype = "dashed", color = '#01ef63', size = 1) +
xlab("fitted values") +
ylab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Fitted Values vs Residuals")
histogram_of_residuals <- ggplot(data = car_linear_model, aes(x = .resid)) +
geom_histogram(color = '#01ef63') +
xlab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Histogram of Residuals")
scale_location <- ggplot(car_linear_model, aes(.fitted, sqrt(abs(.stdresid)))) +
geom_point(color = '#203147', na.rm=TRUE) +
stat_smooth(method="loess", na.rm = TRUE, color = '#01ef63', size = 1, se = FALSE) +
xlab("Fitted Value") +
ylab(expression(sqrt("|Standardized residuals|"))) +
labs(title = "Cars in Jordan") +
labs(subtitle = "Scale-Location")
leverage_vs_standardized_residuals <- ggplot(data = car_linear_model, aes(.hat, .stdresid)) +
geom_point(aes(size = .cooksd), color = '#203147') +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage") +
ylab("Standardized Residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Residuals vs Leverage") +
scale_size_continuous("Cook's Distance", range=c(1,5)) +
theme(legend.title = element_blank()) +
theme(legend.position= "none")
observation_number_vs_cooks_distance <- ggplot(car_linear_model, aes(seq_along(.cooksd), .cooksd)) +
geom_bar(stat="identity", position="identity", color = '#01ef63', size = 1) +
xlab("Obs. Number") +
ylab("Cook's distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's distance")
leverage_vs_cooks_distance <- ggplot(car_linear_model, aes(.hat, .cooksd))+geom_point(na.rm=TRUE) +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage hii")+
ylab("Cook's Distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's dist vs Leverage hii/(1-hii)") +
geom_abline(slope=seq(0,3,0.5), color = "gray", linetype = "dotdash")
library(patchwork)
fitted_values_vs_residuals + histogram_of_residuals
library(patchwork)
scale_location + leverage_vs_standardized_residuals
library(patchwork)
observation_number_vs_cooks_distance + leverage_vs_cooks_distance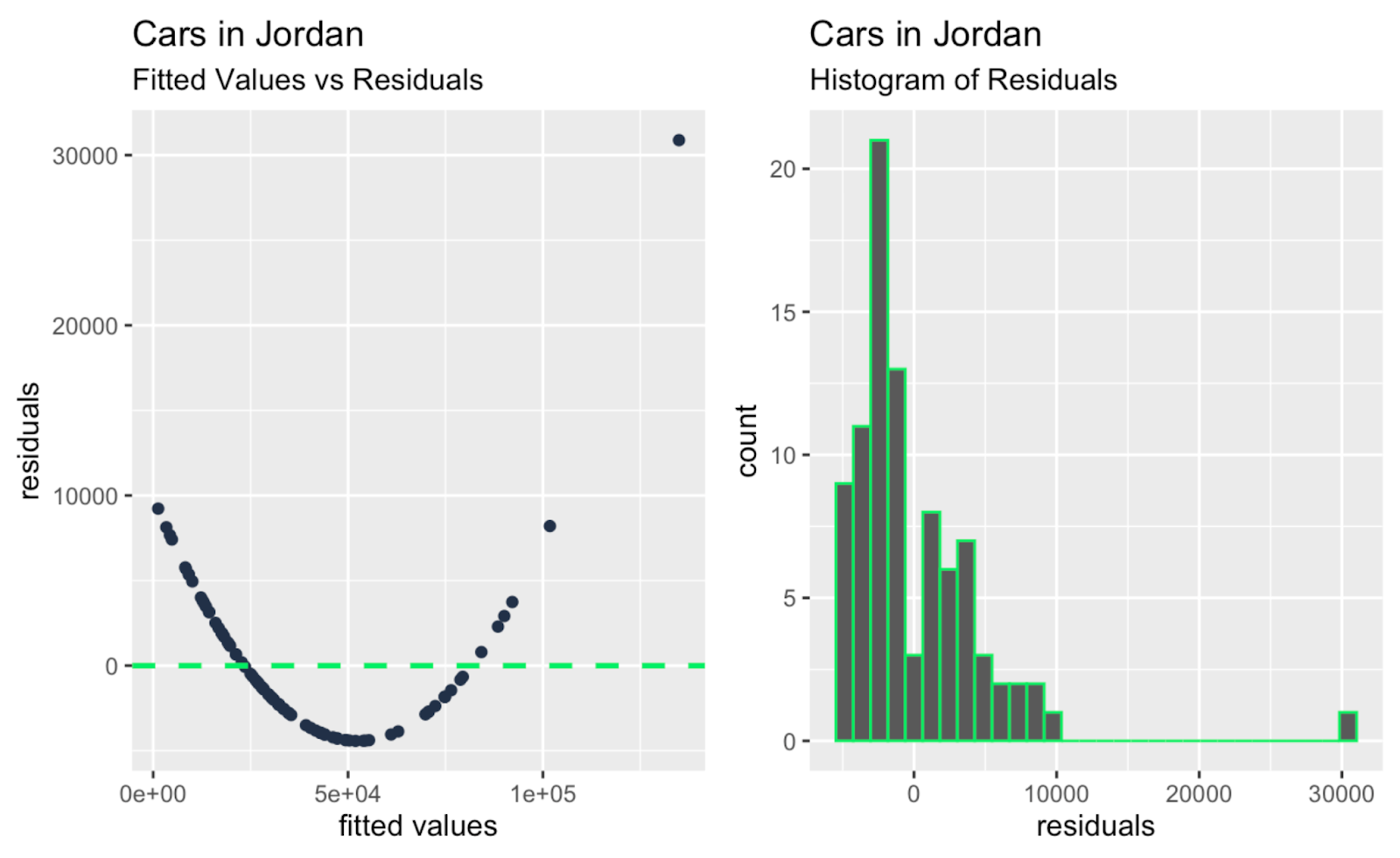
Gefitte waarden versus residuen; histogram van residuen. Afbeelding door de auteur
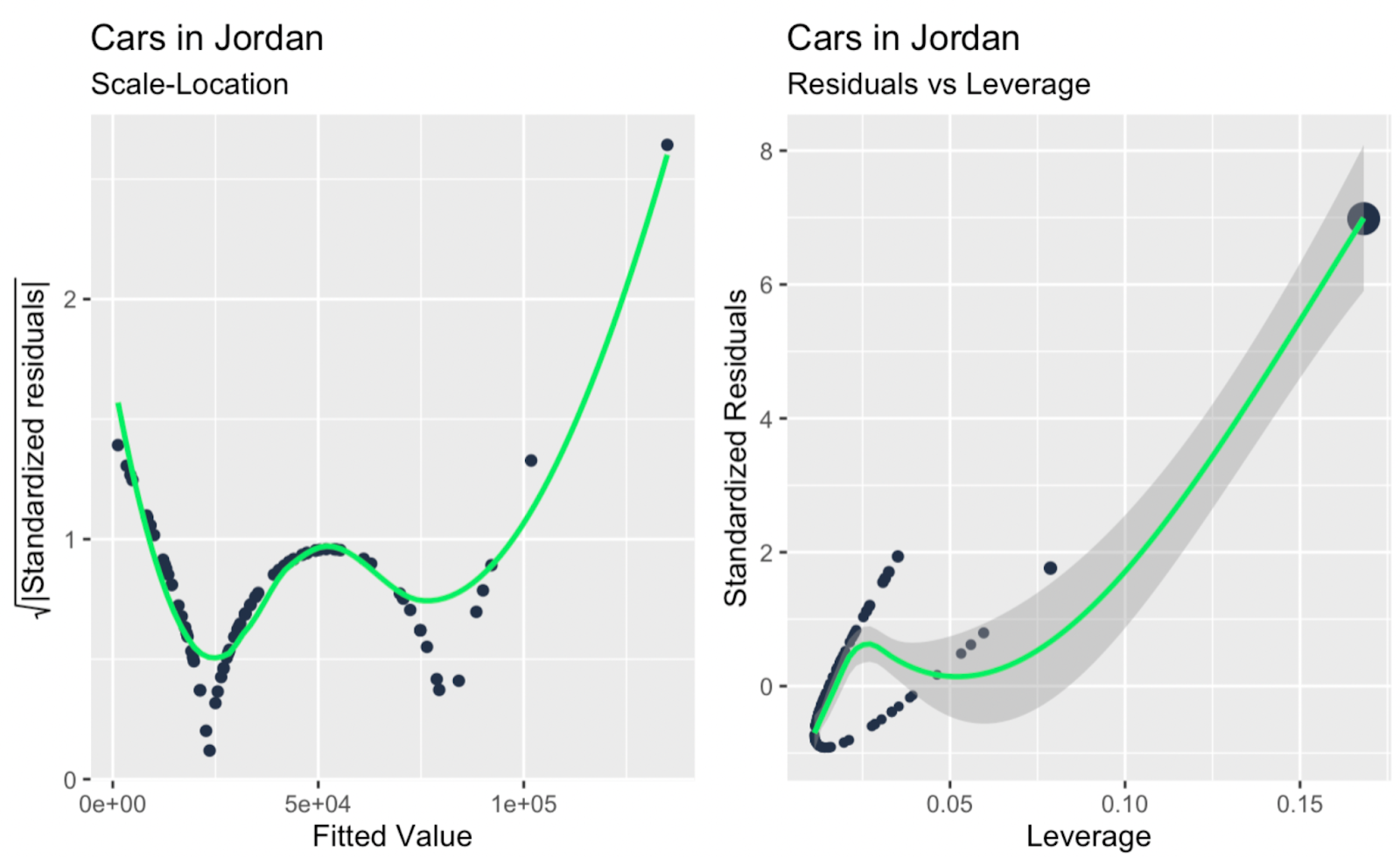
Scale-location-plot; leverage versus gestandaardiseerde residuen. Afbeelding door de auteur
Observatienummer versus Cook's distance; Cook's distance versus leverage. Afbeelding door de auteur
Misschien is de belangrijkste conclusie, als je snel naar alle extra diagnostische plots hierboven kijkt, dat er één of twee grote uitschieters zijn die een grote invloed hebben op de helling van de regressielijn, en dat deze uitschieters niet zo duidelijk zijn wanneer je alleen naar de Q-Q-plot kijkt. De Q-Q-plot in ons voorbeeld vervult dus zijn functie — het testen van de normaliteit van residuen — en onthult ook een beperking, namelijk dat hij geen onafhankelijkheid, homoscedasticiteit of uitschieters adresseert.
Ter verdere referentie voeg ik hier een tabel op hoofdlijnen toe waarin staat welke aanname van het lineaire model met elke diagnostische plot wordt getest, en ik suggereer ook hoe andere diagnostische plots samen met de Q-Q-plot kunnen werken. Houd er rekening mee dat, afhankelijk van de data, verschillende soorten patronen zichtbaar kunnen worden met verschillende diagnostische plots, en dat bepaalde zaken juist in combinatie naar voren komen. Zo kan een Q-Q-plot de normaliteit bevestigen, terwijl een scale-location-plot heteroscedasticiteit kan blootleggen, en zie je normaliteit en heteroscedasticiteit pas door beide plots te gebruiken.
| Type diagnostische plot | Helpt bij | Hoe het samenwerkt met de Q-Q-plot |
|---|---|---|
| Q-Q-plot | Normaliteit van residuen | |
| Histogram van residuen | Normaliteit van residuen | Geeft snel visueel een algemeen beeld van symmetrie en spreiding. |
| Gefitte waarden versus residuen | Lineariteit, onafhankelijkheid van fouten | Laat patronen en niet-lineariteit zien, als aanvulling op de normaliteitscheck van de Q-Q-plot. |
| Scale-location-plot | Homoscedasticiteit | Benadrukt de consistentie van de spreiding van residuen, als aanvulling op Q-Q-plots voor normaliteitschecks. |
| Leverage versus residuen-plot | Onafhankelijkheid van fouten | Richt zich op punten met hoge leverage, waar Q-Q-plots niet op ingaan. |
| Observatienummer versus Cook’s distance | Invloedrijke punten identificeren | Vult Q-Q-plots aan door uitschieters met grote invloed te lokaliseren. |
| Leverage versus Cook’s distance-plot | Punten met hoge leverage identificeren | Benadrukt invloedrijke observaties, terwijl Q-Q-plots de normaliteit valideren. |
Ik hoop dat je een nieuwe waardering hebt gekregen voor Q-Q-plots als handig hulpmiddel om normaliteit te beoordelen en dat je beter begrijpt hoe ze vaak worden gebruikt om de normaliteit van residuen in een lineaire regressie te toetsen. Ik hoop ook dat je in het algemeen meer waardering hebt gekregen voor het belang van diagnostiek bij lineaire modellen.
Blijf leren over lineaire regressie met onze Multiple Linear Regression in R: Tutorial With Examples, die complexere modellen met meerdere voorspellers behandelt, inclusief het concept multicollineariteit in regressie. Ik raad sterk aan je in te schrijven voor onze volledige en uitgebreide carrièreroute, Machine Learning Scientist in Python, om alles te leren over de modelbouw-werkstroom, inclusief zowel supervised als unsupervised learning.
Leren met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
