
Corso
Inferenza per la regressione lineare in R
4 h
16K
I modelli di regressione lineare sono ampiamente usati in statistica e machine learning per prevedere valori numerici a partire da variabili in input e per comprendere la relazione tra variabili. Tuttavia, il fatto che tu possa tracciare una retta attraverso i tuoi dati non significa che dovresti farlo. Dobbiamo anche diagnosticare la qualità del fit per capire se il modello è adatto ai dati o se va perfezionato.
Ci sono diversi modi per testare un modello, tra cui valutare il modello usando un flusso train/test e osservare statistiche del modello come l’R-quadrato corretto. In questo articolo, mi concentrerò su come creare e interpretare un grafico diagnostico specifico chiamato Q-Q plot e ti mostrerò alcuni metodi per creare questo Q-Q plot nel linguaggio R. Per continuare davvero a padroneggiare le tecniche di regressione, segui Introduction to Regression in R o Intermediate Regression in R oppure, per Python, segui Introduction to Regression in Python o Intermediate Regression in Python, a seconda del tuo livello di confidenza.
Un Q-Q (Quantile-Quantile) plot serve per verificare se un dataset segue una particolare distribuzione teorica. Funziona confrontando i quantili dei dati osservati con i quantili di un’altra distribuzione. Ho detto “distribuzione teorica” per essere preciso, ma spesso quando creiamo un Q-Q plot pensiamo in particolare alla distribuzione normale, o gaussiana, e la indichiamo come normal Q-Q plot. Tuttavia, i Q-Q plot possono essere usati anche per confrontare i dati con altre distribuzioni, come esponenziale, uniforme, chi-quadrato, t-distribution, distribuzione di Poisson o altre, a seconda del contesto.
È utile capirlo con un esempio. Qui ho creato 10 numeri. Per costruire un normal Q-Q plot, prima metto i numeri in ordine. Poi calcolo la probabilità con questa equazione: q = (i – 0,5)/n. Quindi, posso usare la percent-point function (PPF) della distribuzione normale standard (la funzione qnorm()) per trovare il valore corrispondente al rango. (Forse ti è più familiare la cumulative distribution function (CDF), che ci dice la probabilità fino a un valore x. Ebbene, la PPF è l’opposto: ci fornisce il valore di x per una data probabilità.)
Infine, per creare il grafico, riportiamo i quantili dei nostri valori osservati contro i quantili teorici (da qui le due Q nel Q-Q plot). La linea è costruita calcolando pendenza e intercetta usando il primo e terzo quartile sia della distribuzione osservata sia di quella teorica.
library(dplyr)
library(ggplot2)
# Create a data frame
data <- data.frame(
numbers = c(
-2.28261064680868, -0.91977039576432, -2.08595211862542,
1.29734993896137, -0.200143957176023, -0.693254525721567,
-3.90536265272207, 4.16373814964331, 2.3499592867344,
0.299856042823977
)
)
# Prepare Q-Q plot data
qq_data <- data %>%
arrange(numbers) %>% # Step 1: Arrange the numbers in ascending order
mutate(
rank = seq(1, n()), # Step 2: Rank each number from 1 to n
prob = (rank - 0.5) / n(), # Step 3: Calculate empirical cumulative probability
theoretical_quantile = qnorm(prob) # Step 4: Calculate theoretical quantiles
)
# Calculate slope and intercept for the Q-Q line
q1_obs <- quantile(qq_data$numbers, probs = 0.25)
q3_obs <- quantile(qq_data$numbers, probs = 0.75)
q1_theo <- qnorm(0.25)
q3_theo <- qnorm(0.75)
slope <- (q3_obs - q1_obs) / (q3_theo - q1_theo)
intercept <- q1_obs - slope * q1_theo
# Create the Q-Q plot
(qq_plot <- ggplot(data = qq_data, aes(x = theoretical_quantile, y = numbers)) +
geom_point(fill = '#01ef63', color = '#203147', shape = 21, size = 2) + # Points with a border
labs(title = "Q-Q Plot") +
geom_abline(slope = slope, intercept = intercept, color = '#203147', linetype = "dashed"))| Numeri | Rango | Probabilità (prob) | Quantile teorico (qnorm(Probabilità)) |
|---|---|---|---|
| -3.905363 | 1 | 0.05 | -1.644854 |
| -2.282611 | 2 | 0.15 | -1.036433 |
| -2.085952 | 3 | 0.25 | -0.674490 |
| -0.919770 | 4 | 0.35 | -0.385321 |
| -0.693255 | 5 | 0.45 | -0.125661 |
| -0.200144 | 6 | 0.55 | 0.125661 |
| 0.299856 | 7 | 0.65 | 0.385321 |
| 1.297350 | 8 | 0.75 | 0.674490 |
| 2.349959 | 9 | 0.85 | 1.036433 |
| 4.163738 | 10 | 0.95 | 1.644854 |

Q-Q plot illustrativo. Immagine dell’autore
Un Q-Q plot è un modo visivo efficace per verificare assunzioni sulla distribuzione. Esistono altri metodi per testare se i dati seguono una distribuzione normale, come ad esempio il test di Shapiro-Wilk, ma nulla, a mio avviso, è altrettanto visivo e rende la storia così evidente come il Q-Q plot.
Conoscere la distribuzione è importante per vari motivi. Per cominciare, probabilmente vorremo sapere quali sono le migliori misure di centro e dispersione. Inoltre, quando creiamo una regressione lineare, vogliamo sapere se la nostra variabile dipendente, in particolare, segue una distribuzione normale, e vogliamo anche verificare se i residui del nostro modello sono normalmente distribuiti per avere maggiore fiducia nelle stime. In sostanza, penso che i Q-Q plot siano utili per due ragioni generali: confrontare i nostri dati con distribuzioni campione e testare la normalità.
Vediamo ora come creare un Q-Q plot in R. In questa sezione passerò attraverso tre metodi diversi: base R, il pacchetto car e i metodi tidyverse. Vedrai che preferisco i metodi tidyverse perché offrono più flessibilità per migliorare l’aspetto del grafico e maggiore estensibilità con altri pacchetti.
Per ciascun metodo, creerò un Q-Q plot sui residui di una regressione lineare semplice, uno degli usi più comuni – se non il più comune – del Q-Q plot. Tuttavia, potresti anche creare un Q-Q plot per verificare la distribuzione delle variabili prima di costruire la regressione lineare. Tutto ciò che ti serve è la distribuzione di una variabile e una distribuzione teorica con cui confrontarla.
Se vuoi seguire passo passo, puoi scaricare il dataset di Kaggle che sto usando: Car Prices Jordan 2023.
Per prima cosa creiamo un Q-Q plot in base R, cioè senza installare pacchetti extra ma usando solo le funzioni integrate.
# Importing data (in this example, saved on the desktop)
car_prices_jordan <- read.csv('~/Desktop/car_prices_jordan.csv')
# Create a linear model
car_linear_model <- lm(Price ~ sqrt(Price), data = filtered_car_prices)
# Extract the residuals
residuals <- resid(car_linear_model)
# Q-Q plot of residuals
qqnorm(residuals, main = "Q-Q Plot of Residuals from Linear Regression")
qqline(residuals, col = "red")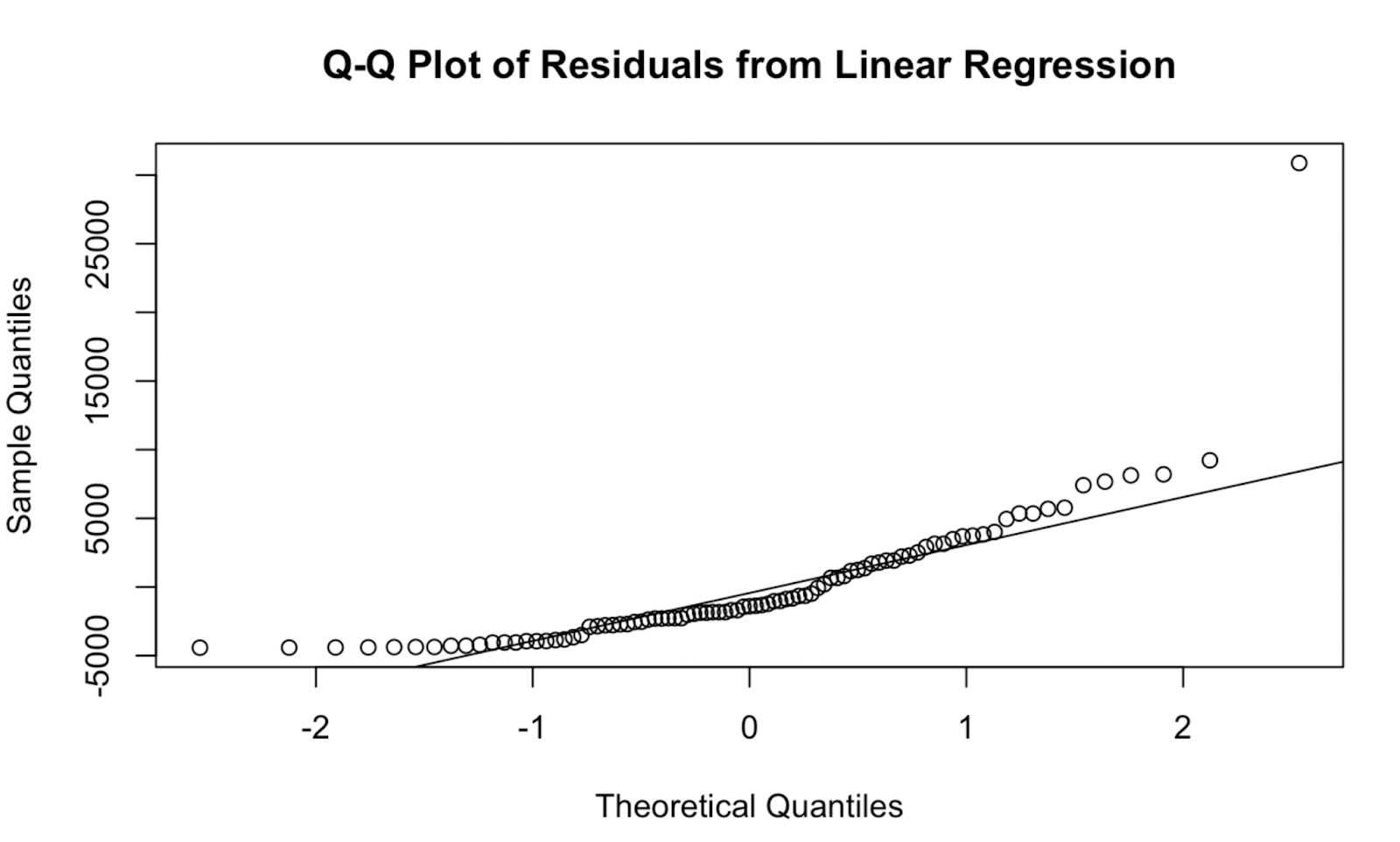 Q-Q plot creato in base R. Immagine dell’autore
Q-Q plot creato in base R. Immagine dell’autore
Ora proviamo a creare un Q-Q plot usando il pacchetto car. A mio parere, la qualità della visualizzazione non è molto diversa, ma questo Q-Q plot ha il vantaggio di mostrare un “confidence envelope”, che definisce l’area entro la quale ci si aspetta che cadano i punti se l’assunzione di normalità del modello fosse vera.
# Install and load the 'car' package
# install.packages("car") # Uncomment this line if the 'car' package is not installed
library(car)
# Q-Q plot of residuals using the 'car' package
car::qqPlot(car_linear_model, main = "Q-Q Plot of Residuals from Linear Regression")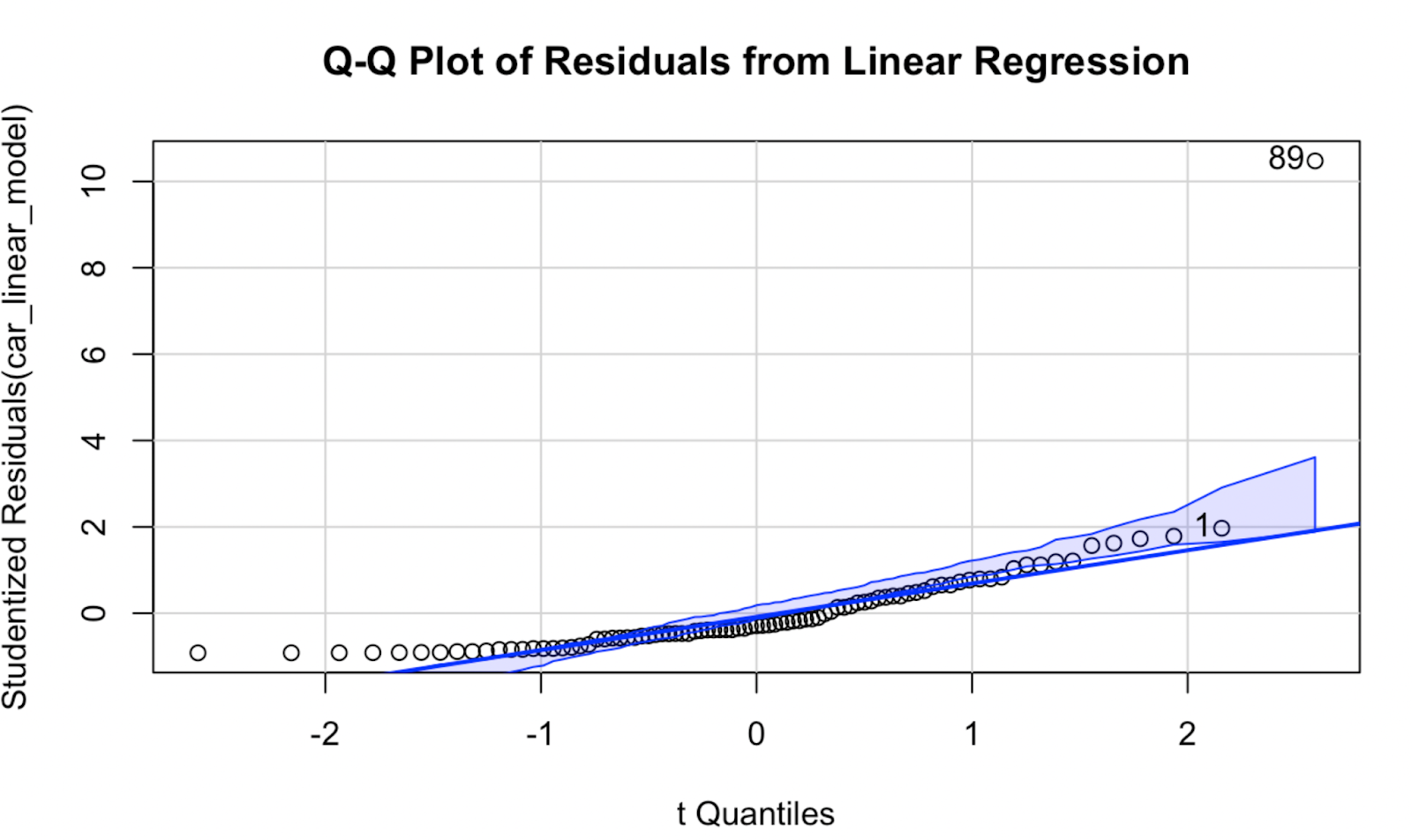 Q-Q plot creato con il pacchetto car in R. Immagine dell’autore
Q-Q plot creato con il pacchetto car in R. Immagine dell’autore
Vediamo ora come creare un Q-Q plot con i metodi tidyverse per avere più flessibilità e un aspetto migliore. Questa volta inserirò il Q-Q plot come pannello accanto al mio scatterplot originale.
# Load necessary libraries
library(tidyverse)
library(metBrewer)
# Clean and convert Power and Price columns to numeric
car_prices_jordan$Power <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Power))
car_prices_jordan$Price <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Price))
# Calculate slope and intercept for linear regression line
slope <- (cor(car_prices_jordan$Power, car_prices_jordan$Price) *
(sd(car_prices_jordan$Price)) /
sd(car_prices_jordan$Power))
intercept <- (mean(car_prices_jordan$Price) - slope * mean(car_prices_jordan$Power))
# Create scatter plot with regression line
car_prices_graph <- ggplot(car_prices_jordan, aes(x = Power, y = Price)) +
geom_point() +
ggtitle("Car Prices in Jordan") +
geom_abline(slope = slope, intercept = intercept, color = '#376795', size = 1)
# Fit a linear model
car_linear_model <- lm(Price ~ Power, data = car_prices_jordan)
# Generate Q-Q plot for residuals
qq_plot <- ggplot(data = data.frame(resid = residuals(car_linear_model)), aes(sample = resid)) +
stat_qq() +
stat_qq_line(linetype = 'dashed', color = '#ef8a47', size = 1) +
labs(
title = "Car Prices in Jordan",
subtitle = "Residual QQ Plot"
)
# Combine scatter plot and Q-Q plot using patchwork
library(patchwork)
car_prices_graph + qq_plot
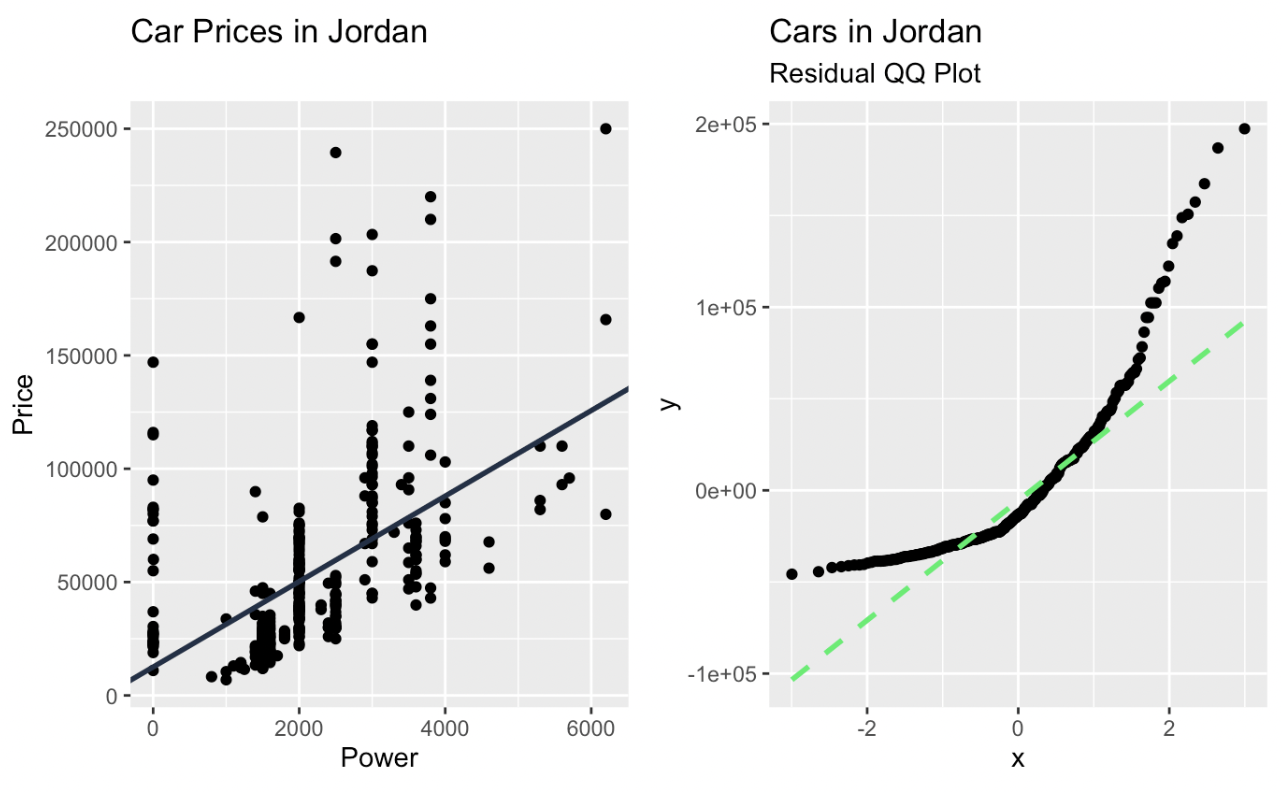
Regressione lineare e Q-Q plot dei residui creati con ggplot2. Immagine dell’autore
Con un Q-Q plot, i quantili dei dati osservati sono riportati contro i quantili teorici. Se i dati seguono da vicino la distribuzione teorica, i punti nel Q-Q plot si dispongono lungo una linea diagonale. Le deviazioni da questa linea indicano scostamenti dalla distribuzione attesa. Punti sopra o sotto la linea suggeriscono asimmetria o outlier, e pattern come curve o deviazioni a forma di S indicano differenze sistematiche, come code più pesanti o più leggere.
In generale, guardiamo circa tre aspetti.
Vediamolo con un esempio per ciascun caso:
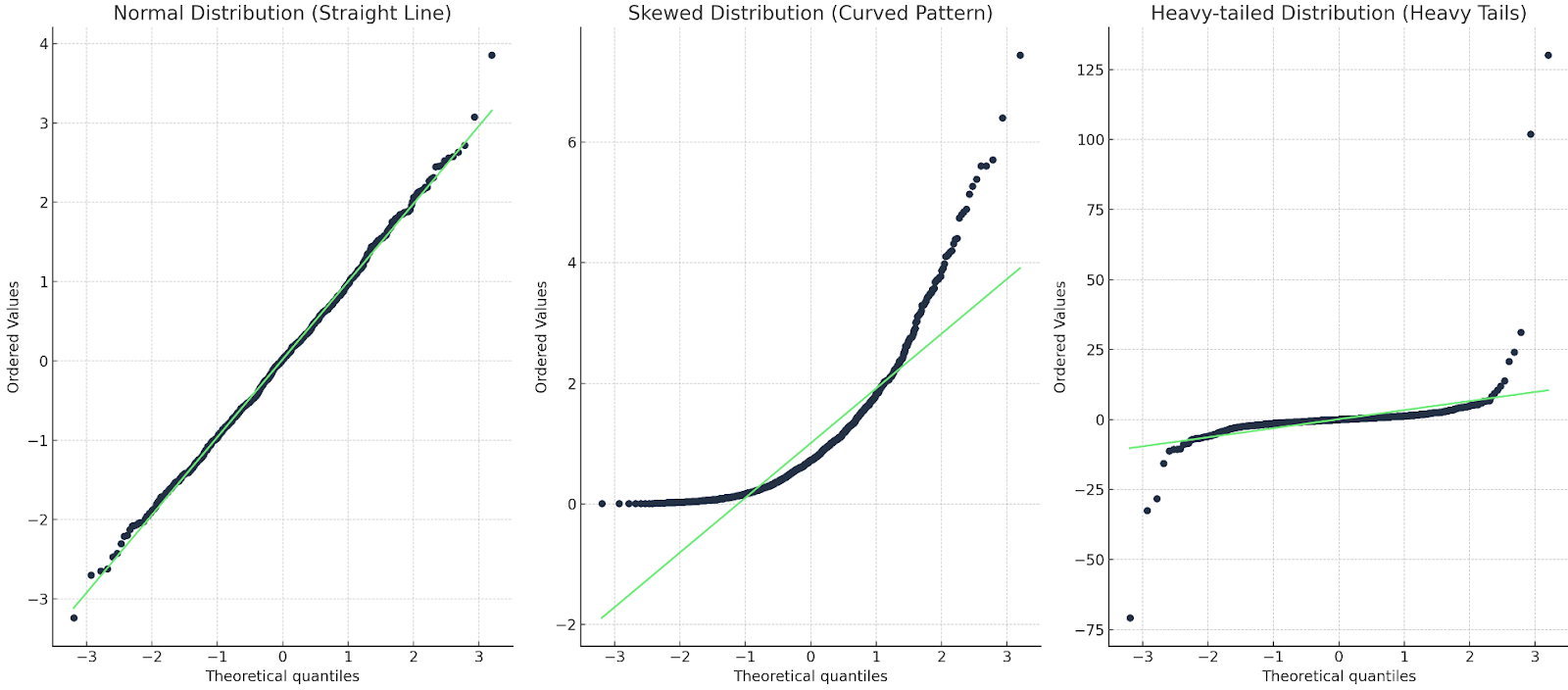
Tre Q-Q plot: uno con linea retta; uno con curva; uno con coda pesante. Immagine dell’autore
Nel primo caso, la linea del Q-Q coincide con i punti, quindi la distribuzione è effettivamente normale. Nel secondo caso, vediamo un pattern curvilineo: i dati non sono normali o sono asimmetrici. Nell’ultimo caso, osserviamo una sorta di forma a “s”, quindi la distribuzione ha code pesanti o valori più estremi.
Le assunzioni di un modello lineare sono diverse, tra cui linearità (la relazione tra variabili è lineare), indipendenza degli errori (gli errori non sono correlati tra loro), omocedasticità (che i residui abbiano varianza costante) e normalità dei residui (che i residui seguano una distribuzione normale). Il Q-Q plot aiuta in particolare con la quarta assunzione, la normalità dei residui.
Ecco come diversi pattern influenzano l’interpretazione e l’affidabilità del nostro modello:
Se conosci i grafici diagnostici per modelli lineari, saprai che ci sono diverse opzioni per valutare il fit del modello. Per capire esattamente cosa mostra il Q-Q plot, diamo un’occhiata ad alcuni altri diagnostici. Questo ci aiuterà a comprendere meglio cosa fa il Q-Q plot e quali altri grafici possono completarlo.
Ti mostrerò rapidamente come creare ciascun grafico usando i metodi tidyverse. Lo scopo qui non è interpretare il modello lineare del nostro dataset “Cars in Jordan” per ogni diagnostico di questa lista. Piuttosto, voglio mostrarti gli altri grafici diagnostici così da riconoscerli, usare il codice se ti è utile e, in linea con l’obiettivo di questo articolo, collocare meglio il Q-Q plot tra gli altri grafici diagnostici. In questo modo capirai meglio cosa il Q-Q plot mostra e non mostra, come è utile e cosa gli manca.
fitted_values_vs_residuals <- ggplot(data = car_linear_model, aes(x = .fitted, y = .resid)) +
geom_point(color = '#203147') +
geom_hline(yintercept = 0, linetype = "dashed", color = '#01ef63', size = 1) +
xlab("fitted values") +
ylab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Fitted Values vs Residuals")
histogram_of_residuals <- ggplot(data = car_linear_model, aes(x = .resid)) +
geom_histogram(color = '#01ef63') +
xlab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Histogram of Residuals")
scale_location <- ggplot(car_linear_model, aes(.fitted, sqrt(abs(.stdresid)))) +
geom_point(color = '#203147', na.rm=TRUE) +
stat_smooth(method="loess", na.rm = TRUE, color = '#01ef63', size = 1, se = FALSE) +
xlab("Fitted Value") +
ylab(expression(sqrt("|Standardized residuals|"))) +
labs(title = "Cars in Jordan") +
labs(subtitle = "Scale-Location")
leverage_vs_standardized_residuals <- ggplot(data = car_linear_model, aes(.hat, .stdresid)) +
geom_point(aes(size = .cooksd), color = '#203147') +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage") +
ylab("Standardized Residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Residuals vs Leverage") +
scale_size_continuous("Cook's Distance", range=c(1,5)) +
theme(legend.title = element_blank()) +
theme(legend.position= "none")
observation_number_vs_cooks_distance <- ggplot(car_linear_model, aes(seq_along(.cooksd), .cooksd)) +
geom_bar(stat="identity", position="identity", color = '#01ef63', size = 1) +
xlab("Obs. Number") +
ylab("Cook's distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's distance")
leverage_vs_cooks_distance <- ggplot(car_linear_model, aes(.hat, .cooksd))+geom_point(na.rm=TRUE) +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage hii")+
ylab("Cook's Distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's dist vs Leverage hii/(1-hii)") +
geom_abline(slope=seq(0,3,0.5), color = "gray", linetype = "dotdash")
library(patchwork)
fitted_values_vs_residuals + histogram_of_residuals
library(patchwork)
scale_location + leverage_vs_standardized_residuals
library(patchwork)
observation_number_vs_cooks_distance + leverage_vs_cooks_distance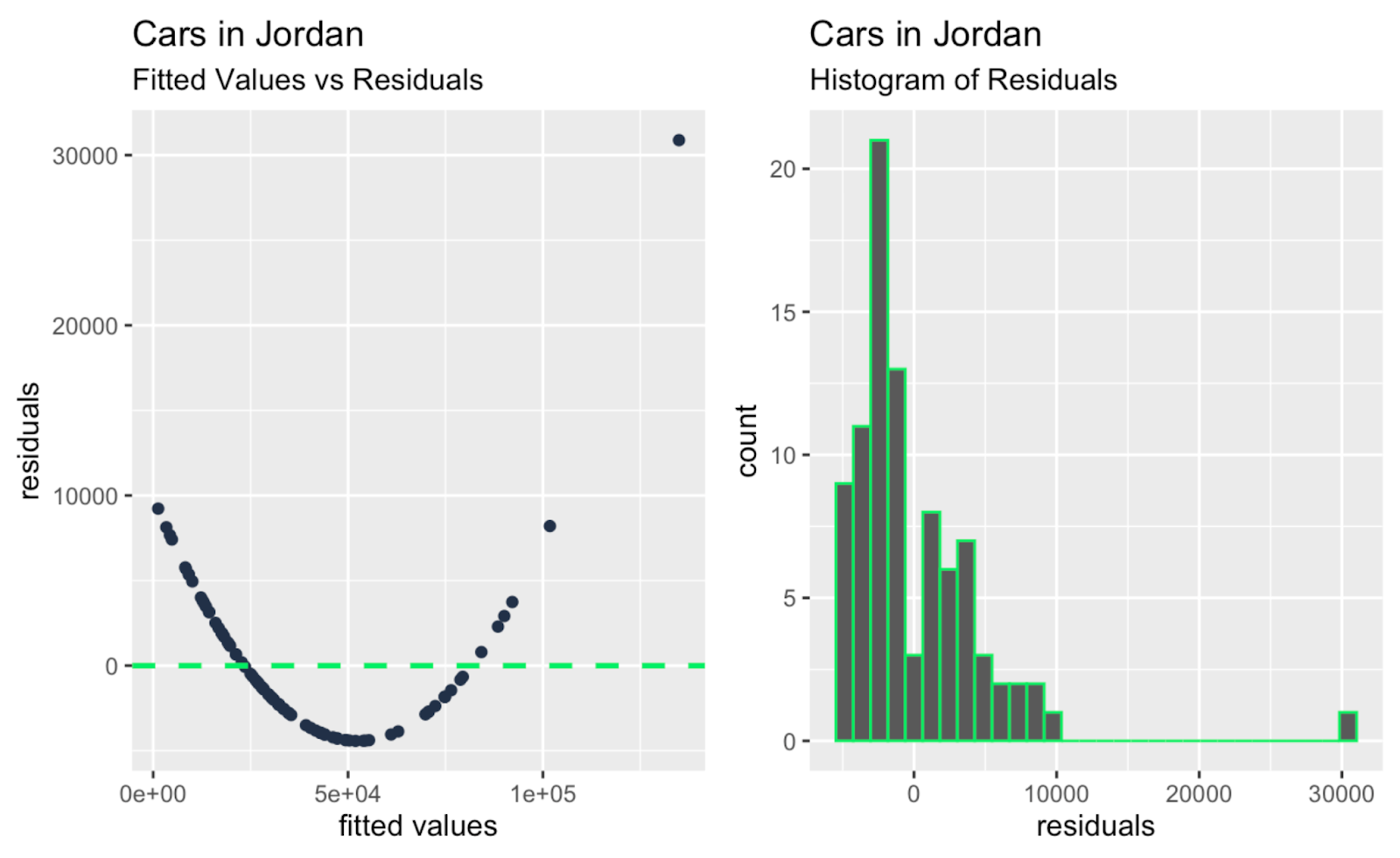
Valori adattati contro residui; istogramma dei residui. Immagine dell’autore
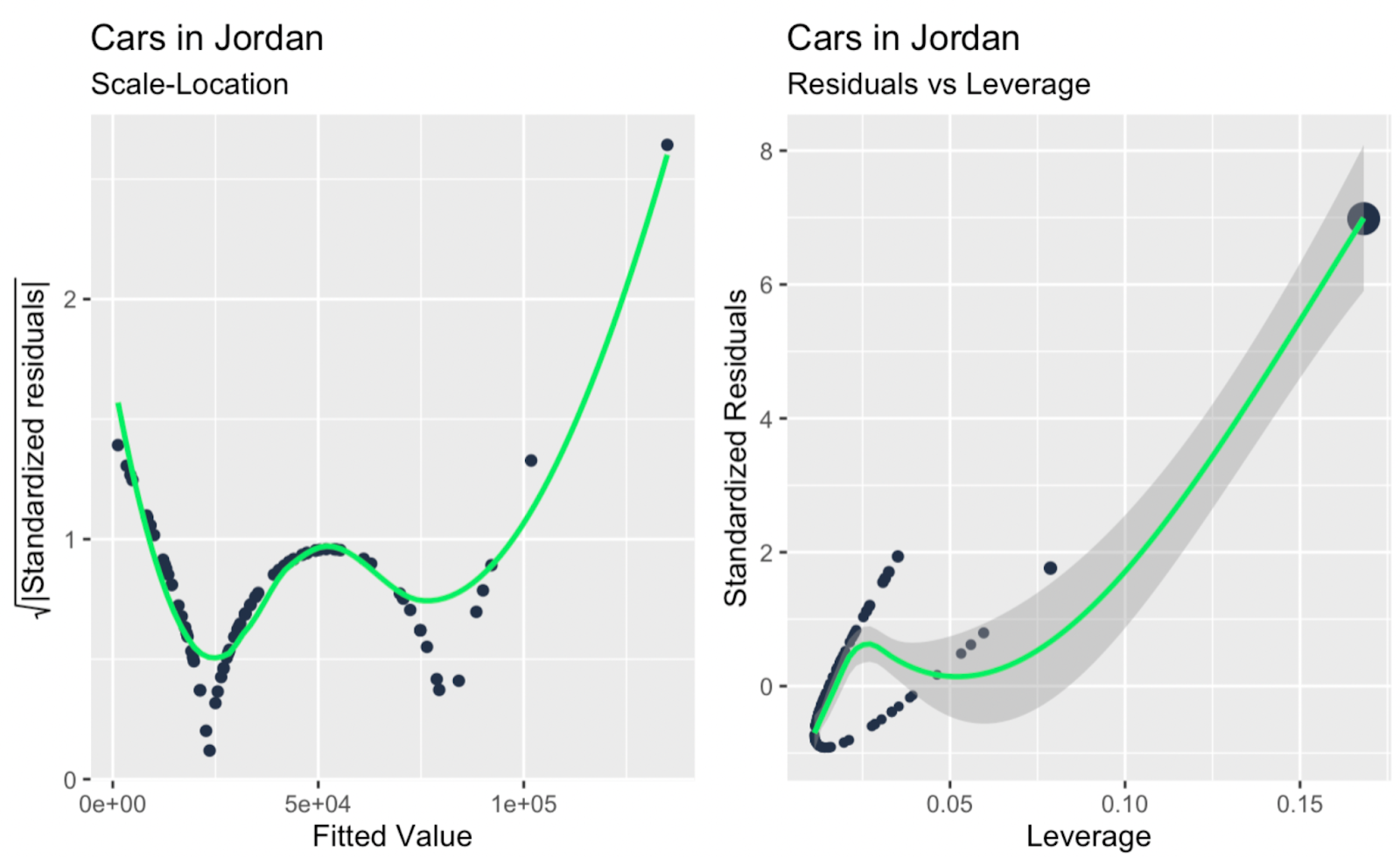
Scale-location plot; leverage contro residui standardizzati. Immagine dell’autore
Numero di osservazione contro distanza di Cook; distanza di Cook contro leverage. Immagine dell’autore
Forse la cosa principale che emerge, dando un’occhiata a tutti i grafici diagnostici aggiuntivi sopra, è che ci sono uno o due outlier di grandi dimensioni che hanno un forte impatto sulla pendenza della retta di regressione, e questi outlier non sono così evidenti guardando solo il Q-Q plot. Quindi il Q-Q plot nel nostro esempio svolge la sua funzione – testare la normalità dei residui – e allo stesso tempo rivela un limite, ovvero che non affronta indipendenza, omocedasticità o outlier.
Per ulteriore riferimento, includo qui una tabella ad alto livello che mostra quale assunzione del modello lineare viene testata con ciascun grafico diagnostico e suggerisco anche come altri grafici possano lavorare in tandem con il Q-Q plot. Tieni presente che, a seconda dei dati, diversi tipi di pattern possono emergere con grafici diagnostici differenti, e certe cose possono emergere in combinazione. Ad esempio, un Q-Q plot può confermare la normalità, mentre uno scale-location plot può individuare eterocedasticità, e potresti vedere normalità ed eterocedasticità solo usando entrambi i grafici.
| Tipo di grafico diagnostico | Aiuta con | Come lavora con il Q-Q plot |
|---|---|---|
| Q-Q plot | Normalità dei residui | |
| Istogramma dei residui | Normalità dei residui | Fornisce un colpo d’occhio e una percezione generale di simmetria e dispersione. |
| Valori adattati contro residui | Linearità, indipendenza degli errori | Rivela pattern e non linearità, complementando il controllo di normalità del Q-Q plot. |
| Scale-Location plot | Omocedasticità | Evidenzia la coerenza della dispersione dei residui, completando i Q-Q plot per i controlli di normalità. |
| Grafico leverage contro residui | Indipendenza degli errori | Si concentra sui punti ad alto leverage, che i Q-Q plot non affrontano. |
| Numero di osservazione contro distanza di Cook | Identificazione dei punti influenti | Completa i Q-Q plot individuando outlier ad alta influenza. |
| Grafico leverage contro distanza di Cook | Identificazione di punti ad alto leverage | Evidenzia osservazioni influenti, mentre i Q-Q plot validano la normalità. |
Spero che tu abbia una nuova considerazione per i Q-Q plot come strumento utile per valutare la normalità e una migliore comprensione del loro uso comune nell’assessment della normalità dei residui in una regressione lineare. Spero anche che tu apprezzi di più l’idea e l’importanza dei diagnostici dei modelli lineari in generale.
Continua a imparare sulla regressione lineare con il nostro Multiple Linear Regression in R: Tutorial With Examples, che copre modelli più complessi con più predittori, incluse le idee di multicollinearità nella regressione. Ti suggerisco vivamente di iscriverti al nostro percorso di carriera completo e approfondito, Machine Learning Scientist in Python, per imparare tutto sul workflow di costruzione dei modelli, sia di apprendimento supervisionato che non supervisionato.
Impara con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

