
Kurs
Inference for Linear Regression in R
4 sa
15.9K
Doğrusal regresyon modelleri, girdilere dayalı sayısal değerleri tahmin etmek ve değişkenler arasındaki ilişkiyi anlamak için istatistik ve makine öğrenmesinde yaygın olarak kullanılır. Ancak verilerinizin içinden bir doğru geçirebiliyor olmanız, bunu yapmanız gerektiği anlamına gelmez. Modelin veriye uygun olup olmadığını ya da iyileştirilmesi gerekip gerekmediğini belirlemek için uyum kalitesini de teşhis etmemiz gerekir.
Bir modeli test etmek için, eğitim/test iş akışıyla modeli değerlendirmek ve düzeltilmiş R-kare gibi istatistiklere bakmak dâhil birkaç farklı yol vardır. Bu yazıda, Q-Q grafiği adı verilen belirli bir teşhis grafiğinin nasıl oluşturulacağını ve yorumlanacağını ele alacağım ve bu Q-Q grafiğini R programlama dilinde oluşturmanın birkaç farklı yöntemini göstereceğim. Regresyon tekniklerinde ustalaşmaya devam etmek için, seviyenize bağlı olarak R ile Regresyona Giriş veya R ile Orta Düzey Regresyon eğitimlerini ya da Python için Python ile Regresyona Giriş veya Python ile Orta Düzey Regresyon eğitimlerini almanızı öneririm.
Q-Q (Quantile-Quantile) grafiği, bir veri kümesinin belirli bir teorik dağılımı izleyip izlemediğini görmek için kullanılır. Gözlemlenen verilerin kantillerini bu diğer dağılımın kantilleriyle karşılaştırarak çalışır. Tam olmak gerekirse ‘teorik dağılım’ dedim; ancak sıklıkla bir Q-Q grafiği oluşturduğumuzda özellikle normal ya da Gauss dağılımını düşünür ve buna normal Q-Q grafiği deriz. Bununla birlikte, Q-Q grafikleri bağlama bağlı olarak üstel, uniform, ki-kare, t-dağılımı, Poisson dağılımı ve diğerlerine karşı da kullanılabilir.
Bir örnekle göstermek faydalı olacaktır. Burada 10 sayı oluşturdum. Normal bir Q-Q grafiği oluşturmak için önce sayıları sıraya koyuyorum. Ardından şu denklemle olasılığı hesaplıyorum: q = (i– 0.5)/n. Sonra, standart normal dağılımın yüzde-nokta fonksiyonunu (PPF) yani qnorm() fonksiyonunu kullanarak derece için karşılık gelen değeri buluyorum. (Muhtemelen x değerine kadar olan olasılığı veren kümülatif dağılım fonksiyonuna (CDF) daha aşinasınızdır. PPF ise bunun tersi gibidir: Verilen bir olasılık için x değerini verir.)
Son olarak grafiği oluşturmak için, gözlemlenen değerlerimizin kantillerini teorik kantillere karşı çizeriz (Q-Q grafiğindeki iki Q buradan gelir). Çizgi, gözlemlenen ve teorik dağılımların birinci ve üçüncü çeyrekleri kullanılarak eğim ve kesişimin hesaplanmasıyla oluşturulur.
library(dplyr)
library(ggplot2)
# Create a data frame
data <- data.frame(
numbers = c(
-2.28261064680868, -0.91977039576432, -2.08595211862542,
1.29734993896137, -0.200143957176023, -0.693254525721567,
-3.90536265272207, 4.16373814964331, 2.3499592867344,
0.299856042823977
)
)
# Prepare Q-Q plot data
qq_data <- data %>%
arrange(numbers) %>% # Step 1: Arrange the numbers in ascending order
mutate(
rank = seq(1, n()), # Step 2: Rank each number from 1 to n
prob = (rank - 0.5) / n(), # Step 3: Calculate empirical cumulative probability
theoretical_quantile = qnorm(prob) # Step 4: Calculate theoretical quantiles
)
# Calculate slope and intercept for the Q-Q line
q1_obs <- quantile(qq_data$numbers, probs = 0.25)
q3_obs <- quantile(qq_data$numbers, probs = 0.75)
q1_theo <- qnorm(0.25)
q3_theo <- qnorm(0.75)
slope <- (q3_obs - q1_obs) / (q3_theo - q1_theo)
intercept <- q1_obs - slope * q1_theo
# Create the Q-Q plot
(qq_plot <- ggplot(data = qq_data, aes(x = theoretical_quantile, y = numbers)) +
geom_point(fill = '#01ef63', color = '#203147', shape = 21, size = 2) + # Points with a border
labs(title = "Q-Q Plot") +
geom_abline(slope = slope, intercept = intercept, color = '#203147', linetype = "dashed"))| Sayılar | Derece | Olasılık (prob) | Teorik Kantıl (qnorm(Olasılık)) |
|---|---|---|---|
| -3.905363 | 1 | 0.05 | -1.644854 |
| -2.282611 | 2 | 0.15 | -1.036433 |
| -2.085952 | 3 | 0.25 | -0.674490 |
| -0.919770 | 4 | 0.35 | -0.385321 |
| -0.693255 | 5 | 0.45 | -0.125661 |
| -0.200144 | 6 | 0.55 | 0.125661 |
| 0.299856 | 7 | 0.65 | 0.385321 |
| 1.297350 | 8 | 0.75 | 0.674490 |
| 2.349959 | 9 | 0.85 | 1.036433 |
| 4.163738 | 10 | 0.95 | 1.644854 |

Örnekleyici Q-Q grafiği. Görsel: Yazar
Q-Q grafiği, dağılımsal varsayımları kontrol etmek için güzel bir görsel yoldur. Verilerin normal dağılımı izleyip izlemediğini test etmenin başka yolları da vardır; örneğin Shapiro-Wilk testi. Ancak bana göre hiçbir şey Q-Q grafiği kadar görsel ve hikâyeyi bu kadar açık kılmaz.
Bir şeyin dağılımını bilmek birkaç açıdan önemlidir. Öncelikle, merkez ve yayılım için en uygun ölçüleri bilmek isteyeceğiz. Ayrıca, doğrusal bir regresyon oluştururken özellikle bağımlı değişkenimizin normal dağılımı izleyip izlemediğini ve tahminlerimize daha fazla güvenebilmek için modelimizden elde edilen artıkların normal dağılılıp dağılmadığını görmek isteriz. Özetle, Q-Q grafikleri verilerimizi örnek dağılımlarla karşılaştırmak ve normalliği test etmek üzere iki genel nedenle kullanışlıdır.
Şimdi R'de Q-Q grafiğinin nasıl oluşturulacağına bakalım. Bu bölümde üç farklı yöntemden geçeceğim: temel R, car paketi ve tidyverse yöntemleri. Sanırım tidyverse yöntemlerini tercih ettiğimi göreceksiniz; çünkü grafiği daha güzel göstermek için daha fazla esneklik sağlar ve diğer paketlerle daha genişletilebilirlik sunar.
Her yöntem için, Q-Q grafiğini basit bir doğrusal regresyonun artıklarına uygulayacağım; bu, Q-Q grafiğinin en yaygın kullanım alanlarından biridir—hatta belki de en yaygın olanıdır. Ancak, baştan doğrusal regresyon oluşturmadan önce değişkenlerin dağılımını kontrol etmek için de bir Q-Q grafiği oluşturabilirsiniz. Tek ihtiyacınız olan, bir değişkenin dağılımı ve onu karşılaştıracağınız bir teorik dağılımdır.
Takip etmek isterseniz, kullandığım Kaggle veri setini indirebilirsiniz: Car Prices Jordan 2023.
Önce temel R ile bir Q-Q grafiği oluşturalım; yani hiçbir ek paket kurmayacağız, yalnızca yerleşik işlevleri kullanacağız.
# Importing data (in this example, saved on the desktop)
car_prices_jordan <- read.csv('~/Desktop/car_prices_jordan.csv')
# Create a linear model
car_linear_model <- lm(Price ~ sqrt(Price), data = filtered_car_prices)
# Extract the residuals
residuals <- resid(car_linear_model)
# Q-Q plot of residuals
qqnorm(residuals, main = "Q-Q Plot of Residuals from Linear Regression")
qqline(residuals, col = "red")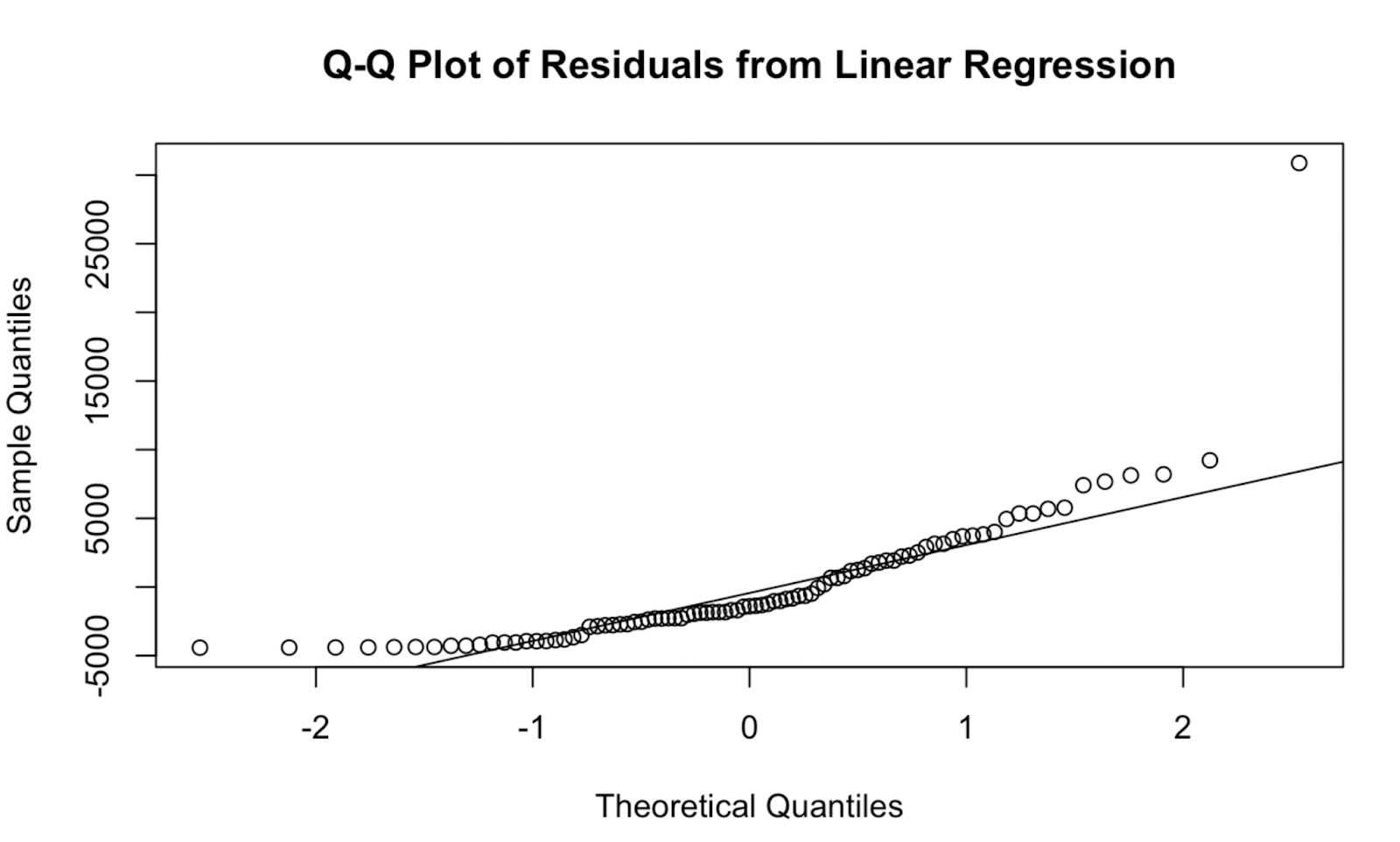 Temel R'de oluşturulmuş Q-Q grafiği. Görsel: Yazar
Temel R'de oluşturulmuş Q-Q grafiği. Görsel: Yazar
Şimdi de car paketini kullanarak bir Q-Q grafiği oluşturalım. Bana göre görselleştirmenin kalitesi çok farklı değil; ancak bu Q-Q grafiğinin bir avantajı, modelin normallik varsayımı geçerliyse veri noktalarının düşmesinin beklendiği alanı tanımlayan bir güven zarfı göstermesidir.
# Install and load the 'car' package
# install.packages("car") # Uncomment this line if the 'car' package is not installed
library(car)
# Q-Q plot of residuals using the 'car' package
car::qqPlot(car_linear_model, main = "Q-Q Plot of Residuals from Linear Regression")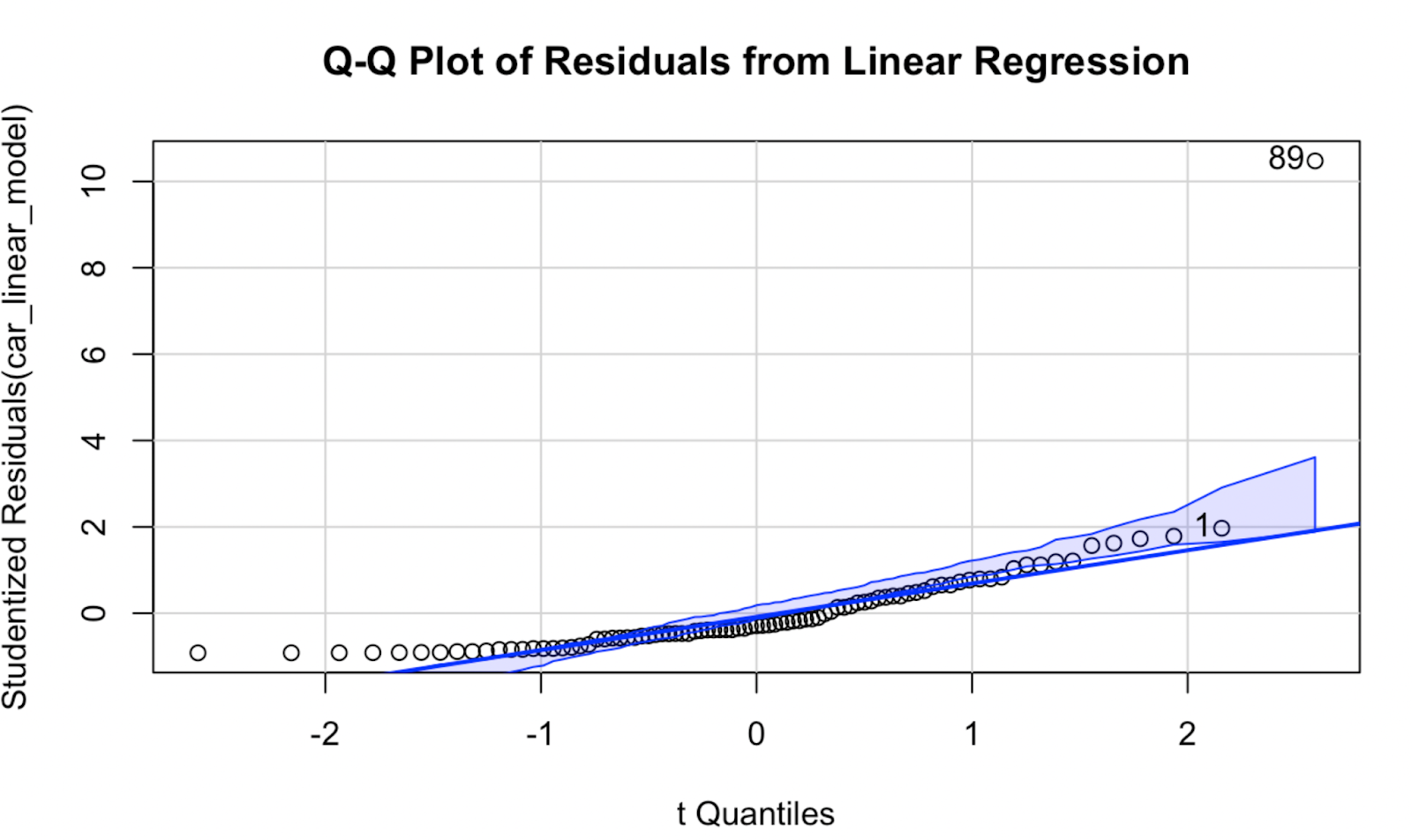 R'de car paketi kullanılarak oluşturulan Q-Q grafiği. Görsel: Yazar
R'de car paketi kullanılarak oluşturulan Q-Q grafiği. Görsel: Yazar
Şimdi daha fazla esneklik ve daha iyi bir görünüm için tidyverse yöntemleriyle Q-Q grafiğinin nasıl oluşturulacağına bakalım. Bu sefer, Q-Q grafiğini orijinal saçılım grafiğimin yan paneli olarak yerleştireceğim.
# Load necessary libraries
library(tidyverse)
library(metBrewer)
# Clean and convert Power and Price columns to numeric
car_prices_jordan$Power <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Power))
car_prices_jordan$Price <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Price))
# Calculate slope and intercept for linear regression line
slope <- (cor(car_prices_jordan$Power, car_prices_jordan$Price) *
(sd(car_prices_jordan$Price)) /
sd(car_prices_jordan$Power))
intercept <- (mean(car_prices_jordan$Price) - slope * mean(car_prices_jordan$Power))
# Create scatter plot with regression line
car_prices_graph <- ggplot(car_prices_jordan, aes(x = Power, y = Price)) +
geom_point() +
ggtitle("Car Prices in Jordan") +
geom_abline(slope = slope, intercept = intercept, color = '#376795', size = 1)
# Fit a linear model
car_linear_model <- lm(Price ~ Power, data = car_prices_jordan)
# Generate Q-Q plot for residuals
qq_plot <- ggplot(data = data.frame(resid = residuals(car_linear_model)), aes(sample = resid)) +
stat_qq() +
stat_qq_line(linetype = 'dashed', color = '#ef8a47', size = 1) +
labs(
title = "Car Prices in Jordan",
subtitle = "Residual QQ Plot"
)
# Combine scatter plot and Q-Q plot using patchwork
library(patchwork)
car_prices_graph + qq_plot
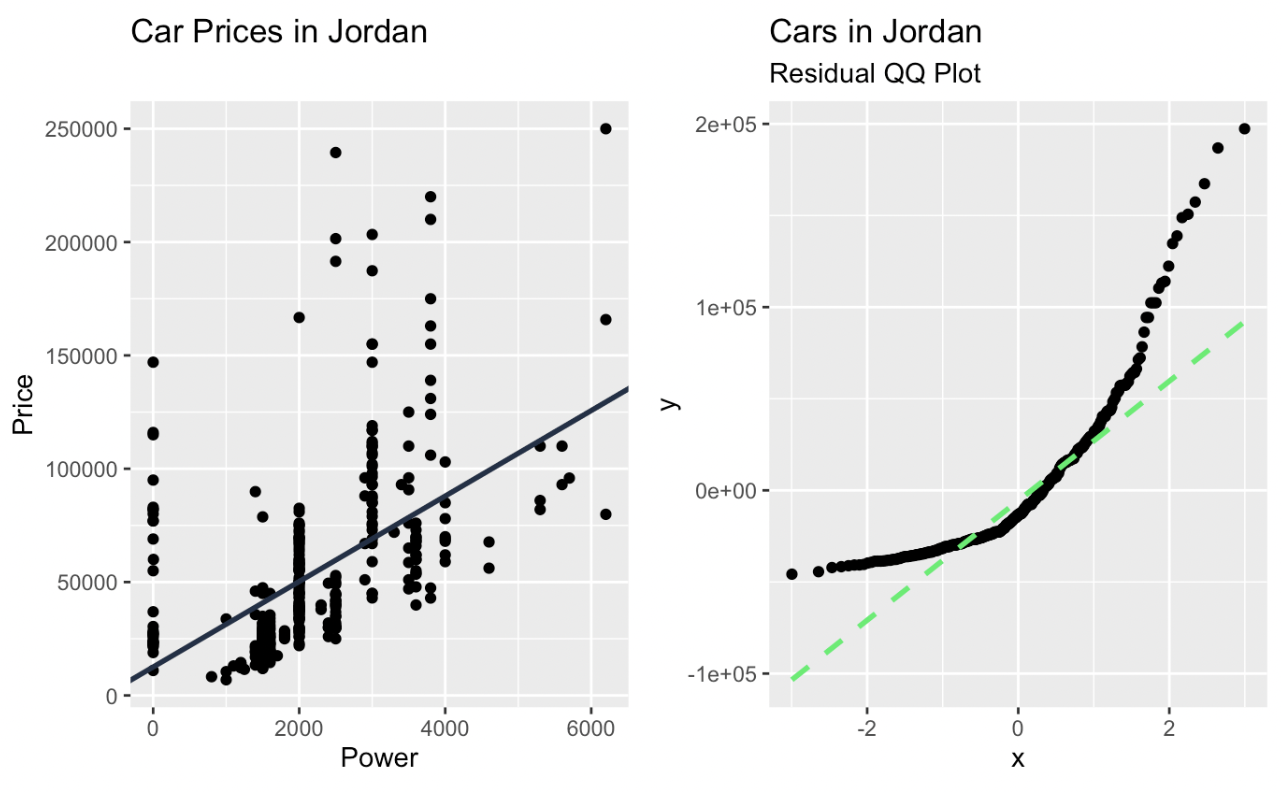
ggplot2 ile oluşturulan doğrusal regresyon ve artıkların Q-Q grafiği. Görsel: Yazar
Q-Q grafiğinde, gözlemlenen verilerin kantilleri teorik kantillere karşı çizilir. Eğer veriler teorik dağılımı yakından izliyorsa, Q-Q grafiğindeki noktalar diyagonal bir çizgi üzerinde ilerler. Bu çizgiden sapmalar, beklenen dağılımdan uzaklaşmaları gösterir. Çizginin üstüne veya altına düşen noktalar çarpıklık veya aykırı değerlere işaret eder; eğriler veya S-şeklindeki sapmalar gibi desenler ise kuyrukların daha ağır ya da daha hafif olması gibi sistematik farkları gösterir.
Genel olarak üç şeye bakarız.
Her biri için bir örnekle gösterelim:
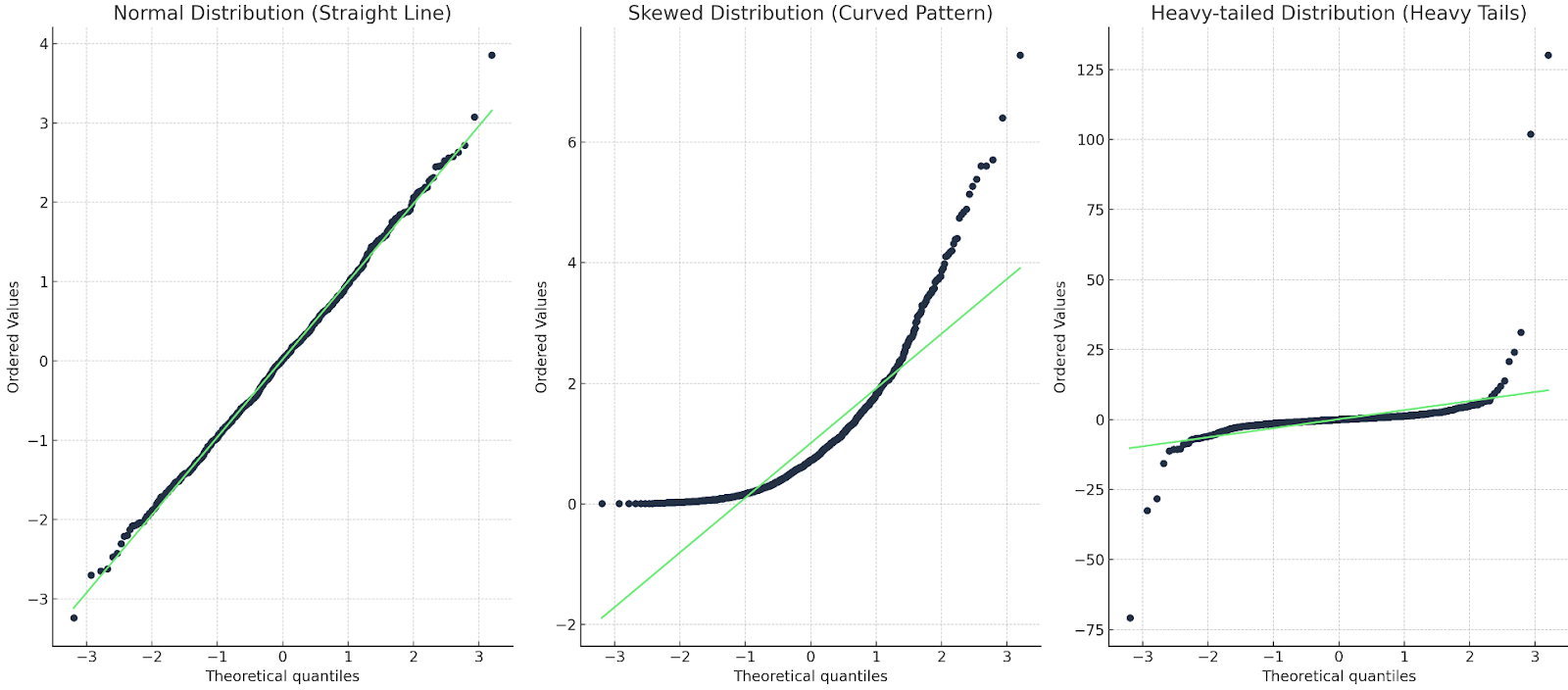
Üç Q-Q grafiği: biri düz çizgili; biri eğrili; biri ağır kuyruklu. Görsel: Yazar
İlk durumda, Q-Q çizgisi veri noktalarıyla örtüşüyor; dolayısıyla dağılım gerçekten normal. İkinci durumda eğrisel bir desen görüyoruz; dolayısıyla veriler ya normal değil ya da çarpık. Son durumda bir tür ‘s’ şekli görüyoruz; bu da dağılımın ağır kuyruklara veya daha uç değerlere sahip olduğunu gösteriyor.
Birkaç farklı doğrusal model varsayımı vardır; bunlar arasında doğrusallık (değişkenler arasındaki ilişkinin doğrusal olması), hataların bağımsızlığı (hataların birbiriyle ilişkili olmaması), homoskedastisite (artıkların sabit varyansa sahip olması) ve artıkların normalliği (artıkların normal dağılımı izlemesi) bulunur. Q-Q grafiği özellikle dördüncü varsayımla, yani artıkların normalliğiyle ilgili yardımcı olur.
Farklı desenlerin modelimizin yorumunu ve güvenilirliğini nasıl etkilediği şöyle:
Doğrusal model teşhis grafiklerine aşinaysanız, model uyumunu değerlendirmek için epey seçenek olduğunu da biliyor olabilirsiniz. Q-Q grafiğinin tam olarak ne gösterdiğini anlamak için, birkaç başka teşhise bakalım. Bu, Q-Q grafiğinin ne yaptığını ve onu hangi grafiklerin tamamlayabileceğini daha iyi anlamamıza yardımcı olacaktır.
Her bir grafiği tidyverse yöntemleriyle nasıl oluşturacağınızı kısaca göstereceğim. Buradaki amaç, listemizdeki her doğrusal model teşhisi için “Ürdün’deki Arabalar” veri setinden doğrusal modeli yorumlamak değil. Daha ziyade, diğer teşhis grafiklerini göstermek istiyorum ki onları tanıyabilesiniz, işinize yararsa kodu kullanabilesiniz ve bu yazının konusu bağlamında Q-Q grafiğini diğer teşhis grafiklerinin arasında daha iyi konumlandırabilesiniz. Böylece Q-Q grafiğinin neyi gösterip neyi göstermediğini, nasıl yardımcı olduğunu ve neleri kaçırdığını daha iyi anlayacaksınız.
fitted_values_vs_residuals <- ggplot(data = car_linear_model, aes(x = .fitted, y = .resid)) +
geom_point(color = '#203147') +
geom_hline(yintercept = 0, linetype = "dashed", color = '#01ef63', size = 1) +
xlab("fitted values") +
ylab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Fitted Values vs Residuals")
histogram_of_residuals <- ggplot(data = car_linear_model, aes(x = .resid)) +
geom_histogram(color = '#01ef63') +
xlab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Histogram of Residuals")
scale_location <- ggplot(car_linear_model, aes(.fitted, sqrt(abs(.stdresid)))) +
geom_point(color = '#203147', na.rm=TRUE) +
stat_smooth(method="loess", na.rm = TRUE, color = '#01ef63', size = 1, se = FALSE) +
xlab("Fitted Value") +
ylab(expression(sqrt("|Standardized residuals|"))) +
labs(title = "Cars in Jordan") +
labs(subtitle = "Scale-Location")
leverage_vs_standardized_residuals <- ggplot(data = car_linear_model, aes(.hat, .stdresid)) +
geom_point(aes(size = .cooksd), color = '#203147') +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage") +
ylab("Standardized Residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Residuals vs Leverage") +
scale_size_continuous("Cook's Distance", range=c(1,5)) +
theme(legend.title = element_blank()) +
theme(legend.position= "none")
observation_number_vs_cooks_distance <- ggplot(car_linear_model, aes(seq_along(.cooksd), .cooksd)) +
geom_bar(stat="identity", position="identity", color = '#01ef63', size = 1) +
xlab("Obs. Number") +
ylab("Cook's distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's distance")
leverage_vs_cooks_distance <- ggplot(car_linear_model, aes(.hat, .cooksd))+geom_point(na.rm=TRUE) +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage hii")+
ylab("Cook's Distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's dist vs Leverage hii/(1-hii)") +
geom_abline(slope=seq(0,3,0.5), color = "gray", linetype = "dotdash")
library(patchwork)
fitted_values_vs_residuals + histogram_of_residuals
library(patchwork)
scale_location + leverage_vs_standardized_residuals
library(patchwork)
observation_number_vs_cooks_distance + leverage_vs_cooks_distance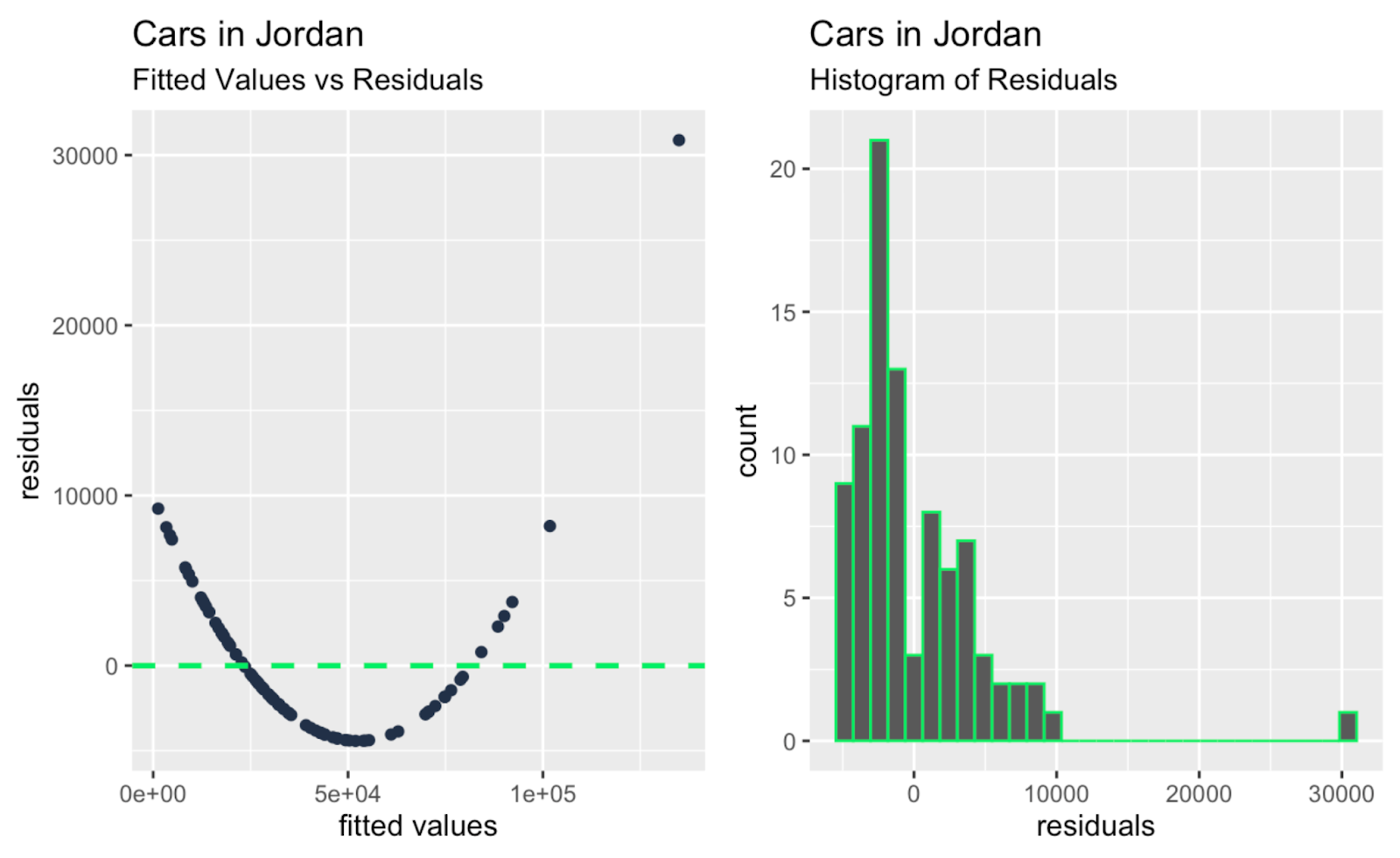
Uyarlanmış değerler ve artıklar; artıkların histogramı. Görsel: Yazar
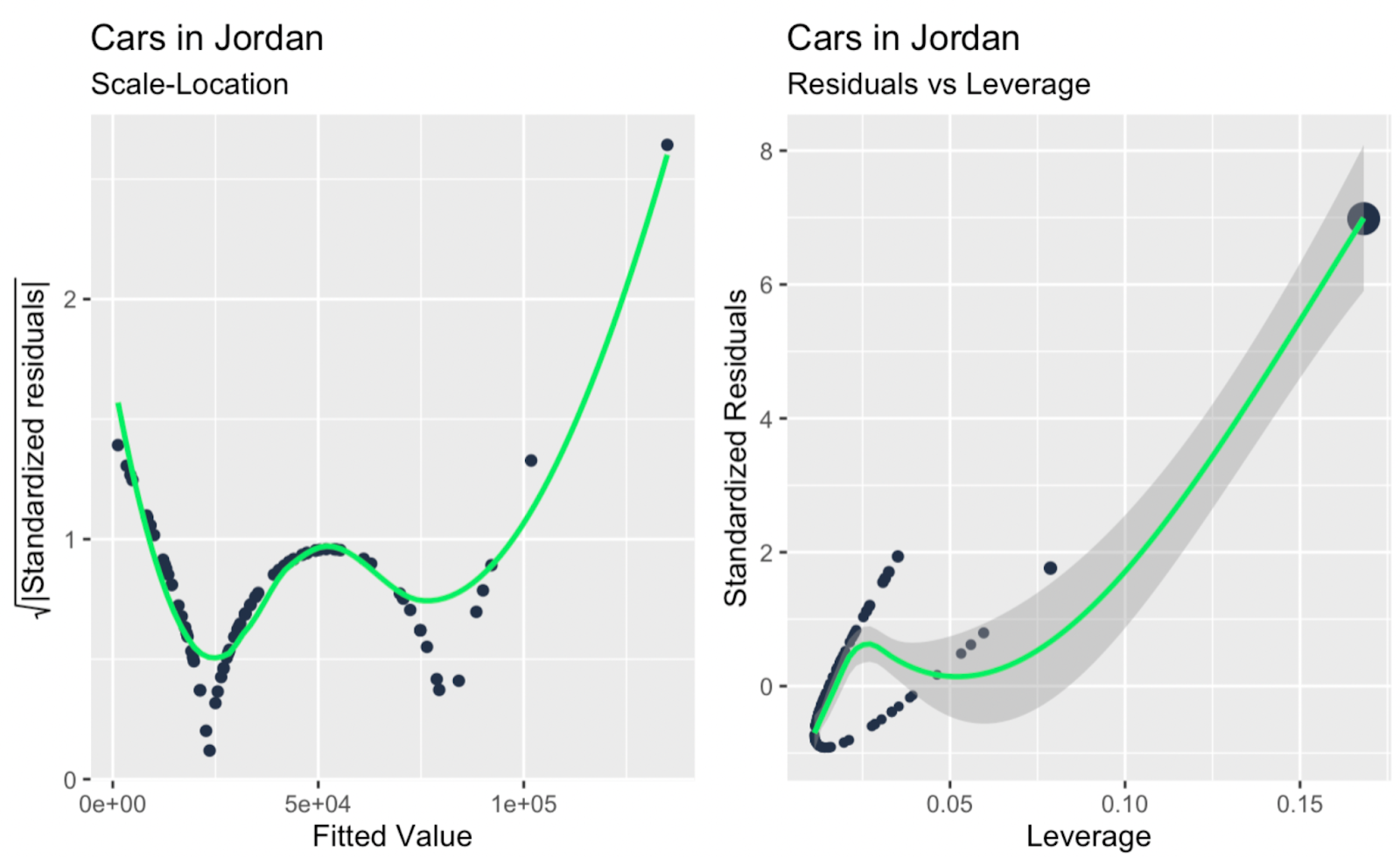
Ölçek-konum grafiği; kaldıraç ve standardize artıklar. Görsel: Yazar
Gözlem numarası ve Cook mesafesi; Cook mesafesi ve kaldıraç. Görsel: Yazar
Yukarıdaki ek teşhis grafiklerine hızlıca bakıldığında belki de en önemli çıkarım, regresyon doğrusunun eğimini büyük ölçüde etkileyen bir veya iki büyük aykırı değerin olduğudur ve bu aykırı değerler yalnızca Q-Q grafiğine bakıldığında o kadar belirgin değildir. Dolayısıyla, örneğimizde Q-Q grafiği işlevini yerine getiriyor—artıkların normalliğini test ediyor—ve aynı zamanda bir sınırlamayı da ortaya koyuyor: bağımsızlık, homoskedastisite veya aykırı değerlere değinmiyor.
Ek başvuru için, burada her teşhis grafiğiyle hangi doğrusal model varsayımının test edildiğini gösteren üst düzey bir tablo ve ayrıca diğer teşhis grafiklerinin Q-Q grafiğiyle nasıl birlikte çalışabileceğine dair bir öneri ekliyorum. Unutmayın, verilere bağlı olarak farklı teşhis grafikleriyle farklı türde desenler ortaya çıkabilir ve bazı şeyler ancak birlikte kullanıldığında görülebilir. Örneğin, bir Q-Q grafiği normalliği doğrulayabilirken, ölçek-konum grafiği heteroskedastisiteyi belirleyebilir ve hem normalliği hem heteroskedastisiteyi yalnızca her iki grafiği de kullanarak görebilirsiniz.
| Teşhis Grafik Türü | Şuna Yardımcı Olur | Q-Q Grafiğiyle Nasıl Çalışır |
|---|---|---|
| Q-Q Grafiği | Artıkların normalliği | |
| Artıkların Histogramı | Artıkların normalliği | Simetri ve yayılıma dair hızlı ve genel bir görsel sunar. |
| Uyarlanmış Değerler ve Artıklar | Doğrusallık, hataların bağımsızlığı | Desenleri ve doğrusallık dışını ortaya koyar; Q-Q grafiğinin normallik kontrolünü tamamlar. |
| Ölçek-Konum Grafiği | Homoskedastisite | Artık yayılımının tutarlılığını vurgular; Q-Q grafiğinin normallik kontrolünü tamamlar. |
| Kaldıraç ve Artıklar Grafiği | Hataların bağımsızlığı | Q-Q grafiklerin ele almadığı yüksek kaldıraçlı noktaları odaklar. |
| Gözlem Numarası ve Cook Mesafesi | Etkili noktaları belirleme | Q-Q grafiklerini, yüksek etkiye sahip aykırıları konumlandırarak tamamlar. |
| Kaldıraç ve Cook Mesafesi Grafiği | Yüksek kaldıraçlı noktaları tanımlama | Etkili gözlemleri vurgularken Q-Q grafikleri normalliği doğrular. |
Q-Q grafiklerine, normalliği değerlendirmede kullanışlı bir araç olarak yeni bir bakış açısı kazanmanızı ve doğrusal regresyonda artıkların normalliğini değerlendirmenin yaygın kullanımını daha iyi anlamanızı umuyorum. Ayrıca, genel olarak doğrusal model teşhislerinin fikrine ve önemine dair yeni bir farkındalık kazanmanızı da umuyorum.
Doğrusal regresyon hakkında öğrenmeye, birden fazla yordayıcı içeren daha karmaşık modelleri ve regresyonda çoklu eşdoğrusallık fikirlerini kapsayan R'de Çoklu Doğrusal Regresyon: Örneklerle Eğitim yazımızla devam edin. Model kurma iş akışının tamamını, denetimli ve denetimsiz öğrenmeyi kapsayacak şekilde öğrenmek için kapsamlı kariyer programımız Python ile Makine Öğrenimi Bilimcisi eğitimine kaydolmanızı önemle öneririm.
DataCamp ile Öğrenin
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
