
Courses
Suy luận cho hồi quy tuyến tính trong R
4 giờ
16K
Mô hình hồi quy tuyến tính được sử dụng rộng rãi trong thống kê và học máy để dự đoán giá trị số dựa trên các đặc trưng đầu vào, đồng thời để hiểu mối quan hệ giữa các biến. Tuy nhiên, không phải cứ vẽ được một đường thẳng qua dữ liệu là bạn nên dùng. Chúng ta cũng phải chẩn đoán chất lượng của phép khớp để xác định xem mô hình có phù hợp với dữ liệu hay cần tinh chỉnh thêm.
Có vài cách khác nhau để kiểm tra mô hình, bao gồm đánh giá mô hình bằng quy trình train/test và xem các thống kê mô hình như R-bình phương hiệu chỉnh. Trong bài viết này, tôi sẽ tập trung vào cách tạo và diễn giải một biểu đồ chẩn đoán cụ thể gọi là biểu đồ Q-Q, và tôi sẽ chỉ cho bạn vài phương pháp khác nhau để tạo biểu đồ Q-Q này trong ngôn ngữ R. Để thực sự tiếp tục làm chủ các kỹ thuật hồi quy, hãy học khóa Introduction to Regression in R hoặc Intermediate Regression in R hoặc, với Python, hãy học Introduction to Regression in Python hoặc Intermediate Regression in Python, tùy vào mức độ thoải mái của bạn.
Biểu đồ Q-Q (Quantile-Quantile) được dùng để xem một tập dữ liệu có tuân theo một phân phối lý thuyết cụ thể hay không. Nó hoạt động bằng cách so sánh các phân vị của dữ liệu quan sát với các phân vị của phân phối kia. Tôi nói ‘phân phối lý thuyết’ cho chính xác, nhưng thường khi tạo biểu đồ Q-Q, chúng ta nghĩ cụ thể đến phân phối chuẩn, hay Gaussian, và gọi đó là biểu đồ Q-Q chuẩn. Tuy nhiên, biểu đồ Q-Q cũng có thể được dùng để so sánh dữ liệu với các phân phối khác như mũ, đều, khi bình phương, phân phối t, phân phối Poisson, hay các phân phối khác, tùy bối cảnh.
Cách hiểu tốt nhất là qua ví dụ. Ở đây, tôi đã tạo 10 con số. Để dựng một biểu đồ Q-Q chuẩn, trước tiên tôi sắp các số theo thứ tự. Sau đó tôi tính xác suất bằng công thức: q = (i– 0.5)/n. Tiếp đó, tôi có thể dùng hàm phần trăm điểm (PPF) của phân phối chuẩn tắc (hàm qnorm()) để tìm giá trị tương ứng cho thứ hạng. (Bạn có thể quen thuộc hơn với hàm phân phối tích lũy (CDF), cho biết xác suất đến một giá trị x. PPF thì ngược lại: Nó cho giá trị x ứng với một xác suất đã cho.)
Cuối cùng, để tạo đồ thị, ta vẽ các phân vị của giá trị quan sát so với các phân vị lý thuyết (vì vậy có hai chữ Q trong Q-Q). Đường thẳng được dựng bằng cách tính hệ số góc và giao điểm dựa trên tứ phân vị thứ nhất và thứ ba của cả phân phối quan sát và phân phối lý thuyết.
library(dplyr)
library(ggplot2)
# Create a data frame
data <- data.frame(
numbers = c(
-2.28261064680868, -0.91977039576432, -2.08595211862542,
1.29734993896137, -0.200143957176023, -0.693254525721567,
-3.90536265272207, 4.16373814964331, 2.3499592867344,
0.299856042823977
)
)
# Prepare Q-Q plot data
qq_data <- data %>%
arrange(numbers) %>% # Step 1: Arrange the numbers in ascending order
mutate(
rank = seq(1, n()), # Step 2: Rank each number from 1 to n
prob = (rank - 0.5) / n(), # Step 3: Calculate empirical cumulative probability
theoretical_quantile = qnorm(prob) # Step 4: Calculate theoretical quantiles
)
# Calculate slope and intercept for the Q-Q line
q1_obs <- quantile(qq_data$numbers, probs = 0.25)
q3_obs <- quantile(qq_data$numbers, probs = 0.75)
q1_theo <- qnorm(0.25)
q3_theo <- qnorm(0.75)
slope <- (q3_obs - q1_obs) / (q3_theo - q1_theo)
intercept <- q1_obs - slope * q1_theo
# Create the Q-Q plot
(qq_plot <- ggplot(data = qq_data, aes(x = theoretical_quantile, y = numbers)) +
geom_point(fill = '#01ef63', color = '#203147', shape = 21, size = 2) + # Points with a border
labs(title = "Q-Q Plot") +
geom_abline(slope = slope, intercept = intercept, color = '#203147', linetype = "dashed"))| Numbers | Hạng | Xác suất (prob) | Phân vị lý thuyết (qnorm(Probability)) |
|---|---|---|---|
| -3.905363 | 1 | 0.05 | -1.644854 |
| -2.282611 | 2 | 0.15 | -1.036433 |
| -2.085952 | 3 | 0.25 | -0.674490 |
| -0.919770 | 4 | 0.35 | -0.385321 |
| -0.693255 | 5 | 0.45 | -0.125661 |
| -0.200144 | 6 | 0.55 | 0.125661 |
| 0.299856 | 7 | 0.65 | 0.385321 |
| 1.297350 | 8 | 0.75 | 0.674490 |
| 2.349959 | 9 | 0.85 | 1.036433 |
| 4.163738 | 10 | 0.95 | 1.644854 |

Biểu đồ Q-Q minh họa. Hình do Tác giả tạo
Biểu đồ Q-Q là cách trực quan hữu ích để kiểm tra các giả định về phân phối. Có những cách khác để kiểm tra dữ liệu có tuân theo phân phối chuẩn hay không, như kiểm định Shapiro-Wilk chẳng hạn, nhưng theo tôi, không gì trực quan và làm câu chuyện trở nên rõ ràng như biểu đồ Q-Q.
Biết phân phối của một đại lượng quan trọng theo vài cách. Thứ nhất, ta sẽ muốn biết thước đo tốt nhất cho xu hướng trung tâm và độ phân tán. Ngoài ra, khi xây dựng hồi quy tuyến tính, ta muốn biết biến phụ thuộc, đặc biệt là, có tuân theo phân phối chuẩn hay không, và cũng muốn xem phần dư từ mô hình có phân phối chuẩn để có niềm tin tốt hơn vào các ước lượng. Tóm lại, tôi nghĩ biểu đồ Q-Q hữu ích cho hai mục đích chung: so sánh dữ liệu với các phân phối mẫu và kiểm tra tính chuẩn.
Giờ hãy xem cách tạo biểu đồ Q-Q trong R. Ở phần này, tôi sẽ trình bày ba phương pháp khác nhau: base R, gói car, và phương pháp tidyverse. Bạn sẽ thấy tôi ưu tiên phương pháp tidyverse vì nó cho phép linh hoạt hơn để làm đồ thị đẹp hơn và dễ mở rộng với các gói khác.
Với mỗi phương pháp, tôi sẽ tạo biểu đồ Q-Q trên phần dư của một hồi quy tuyến tính đơn, đây là một trong những cách dùng phổ biến nhất - nếu không muốn nói là phổ biến nhất - của biểu đồ Q-Q. Tuy nhiên, bạn cũng có thể tạo biểu đồ Q-Q để kiểm tra phân phối của các biến trước khi xây dựng hồi quy tuyến tính ngay từ đầu. Tất cả những gì cần là phân phối của một biến và một phân phối lý thuyết để so sánh.
Nếu muốn thực hành theo, bạn có thể tải bộ dữ liệu Kaggle mà tôi đang dùng: Car Prices Jordan 2023.
Trước tiên hãy tạo biểu đồ Q-Q trong base R, tức là chúng ta sẽ không cài thêm gói nào mà chỉ dùng các hàm dựng sẵn.
# Importing data (in this example, saved on the desktop)
car_prices_jordan <- read.csv('~/Desktop/car_prices_jordan.csv')
# Create a linear model
car_linear_model <- lm(Price ~ sqrt(Price), data = filtered_car_prices)
# Extract the residuals
residuals <- resid(car_linear_model)
# Q-Q plot of residuals
qqnorm(residuals, main = "Q-Q Plot of Residuals from Linear Regression")
qqline(residuals, col = "red")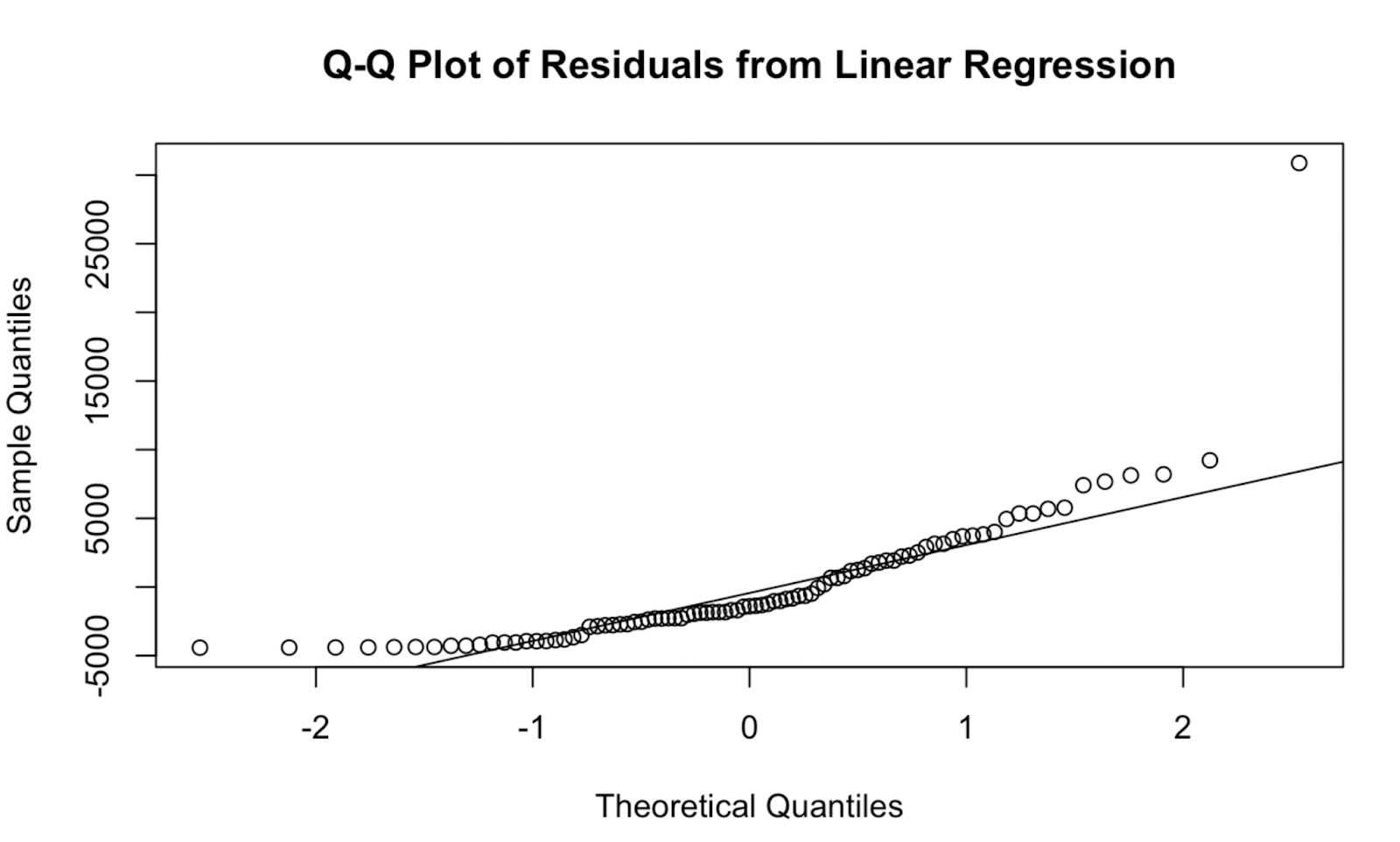 Biểu đồ Q-Q tạo bằng base R. Hình do Tác giả tạo
Biểu đồ Q-Q tạo bằng base R. Hình do Tác giả tạo
Giờ hãy thử tạo biểu đồ Q-Q bằng gói car. Theo tôi, chất lượng trực quan không khác quá nhiều, nhưng biểu đồ Q-Q này có ưu điểm là hiển thị bao tin cậy, xác định vùng mà các điểm dữ liệu được kỳ vọng sẽ nằm trong đó nếu giả định chuẩn của mô hình là đúng.
# Install and load the 'car' package
# install.packages("car") # Uncomment this line if the 'car' package is not installed
library(car)
# Q-Q plot of residuals using the 'car' package
car::qqPlot(car_linear_model, main = "Q-Q Plot of Residuals from Linear Regression")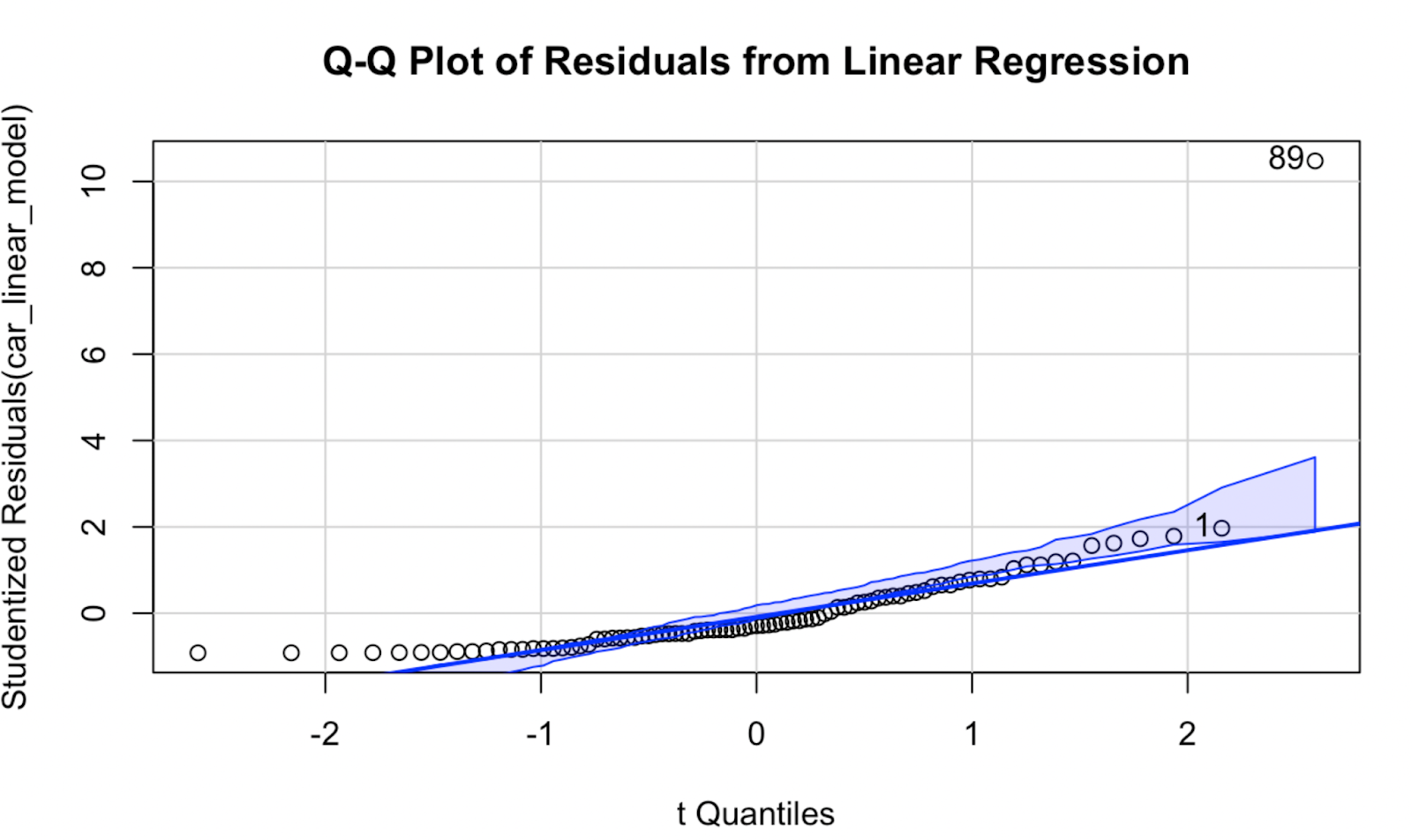 Biểu đồ Q-Q tạo bằng gói car trong R. Hình do Tác giả tạo
Biểu đồ Q-Q tạo bằng gói car trong R. Hình do Tác giả tạo
Giờ hãy xem cách tạo biểu đồ Q-Q bằng phương pháp tidyverse để linh hoạt hơn và trông đẹp mắt hơn. Lần này, tôi sẽ đặt biểu đồ Q-Q thành một ô cạnh scatterplot gốc.
# Load necessary libraries
library(tidyverse)
library(metBrewer)
# Clean and convert Power and Price columns to numeric
car_prices_jordan$Power <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Power))
car_prices_jordan$Price <- as.numeric(gsub("[^0-9]", "", car_prices_jordan$Price))
# Calculate slope and intercept for linear regression line
slope <- (cor(car_prices_jordan$Power, car_prices_jordan$Price) *
(sd(car_prices_jordan$Price)) /
sd(car_prices_jordan$Power))
intercept <- (mean(car_prices_jordan$Price) - slope * mean(car_prices_jordan$Power))
# Create scatter plot with regression line
car_prices_graph <- ggplot(car_prices_jordan, aes(x = Power, y = Price)) +
geom_point() +
ggtitle("Car Prices in Jordan") +
geom_abline(slope = slope, intercept = intercept, color = '#376795', size = 1)
# Fit a linear model
car_linear_model <- lm(Price ~ Power, data = car_prices_jordan)
# Generate Q-Q plot for residuals
qq_plot <- ggplot(data = data.frame(resid = residuals(car_linear_model)), aes(sample = resid)) +
stat_qq() +
stat_qq_line(linetype = 'dashed', color = '#ef8a47', size = 1) +
labs(
title = "Car Prices in Jordan",
subtitle = "Residual QQ Plot"
)
# Combine scatter plot and Q-Q plot using patchwork
library(patchwork)
car_prices_graph + qq_plot
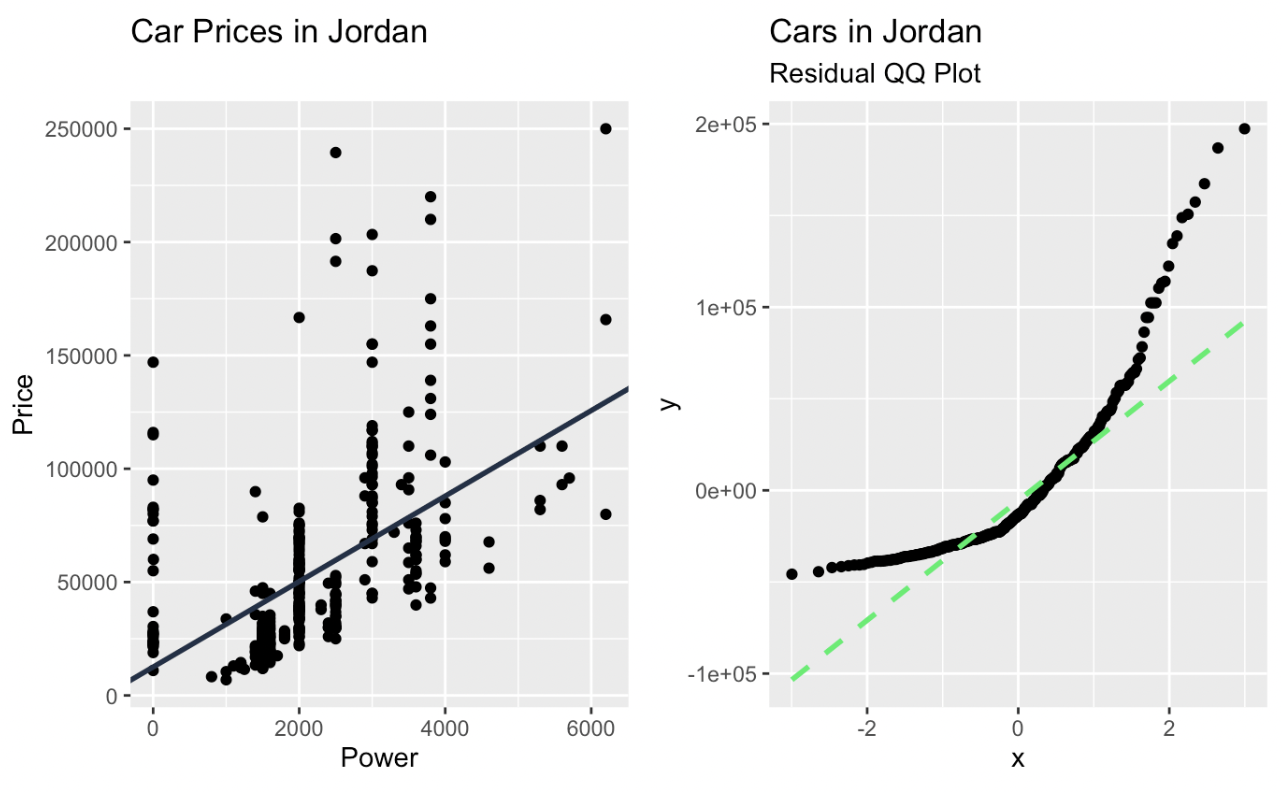
Hồi quy tuyến tính và biểu đồ Q-Q của phần dư tạo bằng ggplot2. Hình do Tác giả tạo
Với biểu đồ Q-Q, các phân vị của dữ liệu quan sát được vẽ đối chiếu với các phân vị lý thuyết. Nếu dữ liệu bám sát phân phối lý thuyết, các điểm trên biểu đồ Q-Q sẽ nằm dọc theo một đường chéo. Độ lệch khỏi đường này cho thấy sự sai khác so với phân phối kỳ vọng. Các điểm nằm trên hoặc dưới đường gợi ý có độ lệch hoặc ngoại lai, và các mô hình như đường cong hay lệch dạng chữ S cho thấy khác biệt có hệ thống, như đuôi nặng hoặc nhẹ hơn.
Có khoảng ba điều chúng ta cần nhìn.
Hãy minh họa bằng ví dụ cho từng trường hợp:
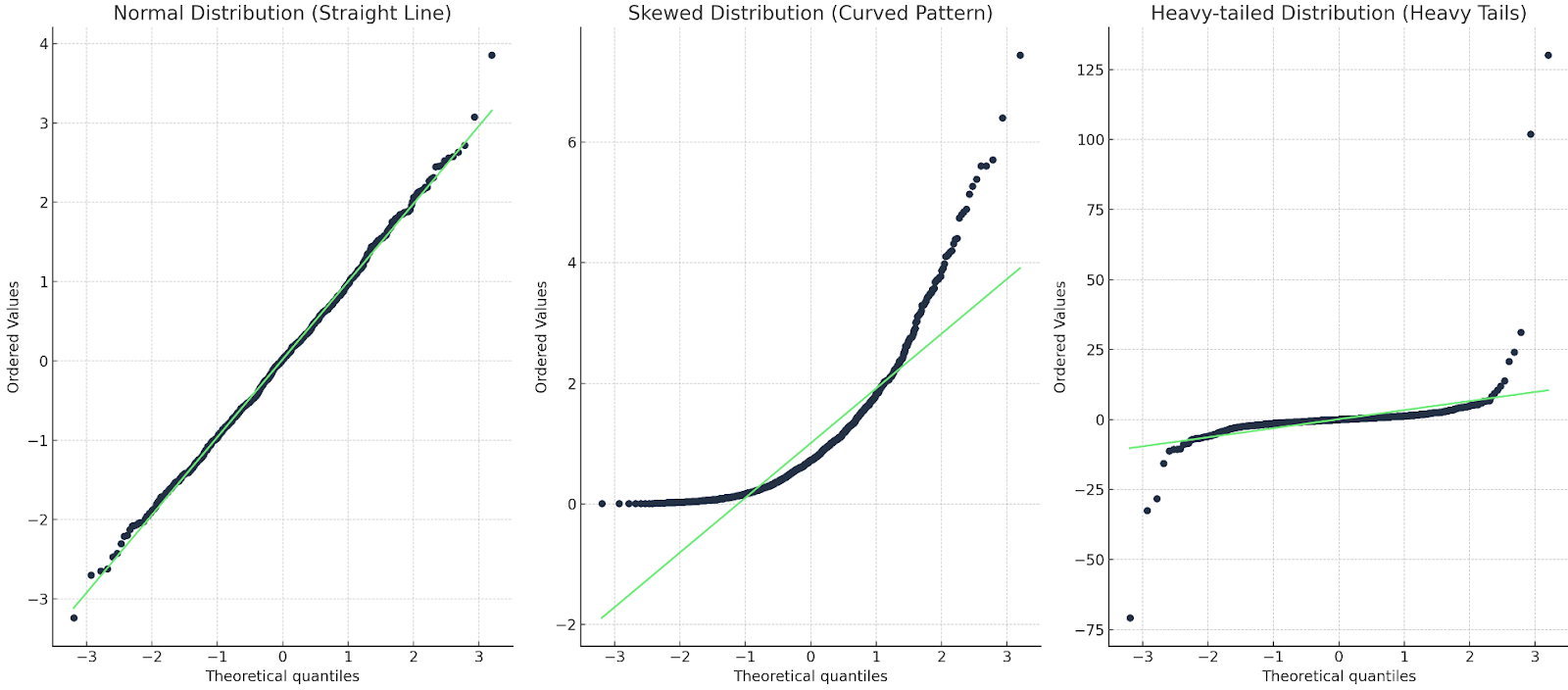
Ba biểu đồ Q-Q: một thẳng; một cong; một có đuôi nặng. Hình do Tác giả tạo
Trong trường hợp đầu, đường Q-Q khớp với các điểm dữ liệu, nên phân phối quả thực là chuẩn. Ở trường hợp thứ hai, ta thấy mẫu hình cong, vậy dữ liệu không chuẩn hoặc bị lệch. Ở trường hợp cuối, ta thấy dạng ‘s’, nghĩa là phân phối có đuôi nặng hoặc nhiều giá trị cực trị hơn.
Có vài giả định của mô hình tuyến tính, gồm tính tuyến tính (mối quan hệ giữa các biến là tuyến tính), độc lập của sai số (các sai số không tương quan với nhau), phương sai đồng nhất (homoscedasticity) (rằng phần dư nên có phương sai không đổi), và tính chuẩn của phần dư (phần dư tuân theo phân phối chuẩn). Biểu đồ Q-Q đặc biệt hữu ích với giả định thứ tư này: tính chuẩn của phần dư.
Dưới đây là cách các mẫu hình khác nhau ảnh hưởng đến diễn giải và độ tin cậy của mô hình:
Nếu bạn quen với các biểu đồ chẩn đoán mô hình tuyến tính, bạn cũng sẽ biết có khá nhiều lựa chọn để đánh giá độ phù hợp của mô hình. Để hiểu chính xác biểu đồ Q-Q đang cho thấy điều gì, hãy xem một vài biểu đồ chẩn đoán khác. Điều này sẽ giúp ta hiểu rõ hơn biểu đồ Q-Q làm gì và những biểu đồ nào có thể bổ trợ cho nó.
Tôi sẽ nhanh chóng chỉ cách tạo từng biểu đồ bằng phương pháp tidyverse. Mục đích ở đây không phải là diễn giải mô hình tuyến tính từ bộ dữ liệu “Cars in Jordan” cho mọi biểu đồ chẩn đoán trong danh sách. Thay vào đó, tôi muốn cho bạn thấy các biểu đồ chẩn đoán khác để bạn có thể nhận ra chúng, dùng mã nếu hữu ích, và, đúng với chủ điểm bài viết, để bạn đặt biểu đồ Q-Q vào tổng thể các biểu đồ chẩn đoán khác. Bằng cách này, bạn sẽ hiểu rõ hơn biểu đồ Q-Q cho thấy và không cho thấy điều gì, nó hữu ích ra sao, và còn thiếu gì.
fitted_values_vs_residuals <- ggplot(data = car_linear_model, aes(x = .fitted, y = .resid)) +
geom_point(color = '#203147') +
geom_hline(yintercept = 0, linetype = "dashed", color = '#01ef63', size = 1) +
xlab("fitted values") +
ylab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Fitted Values vs Residuals")
histogram_of_residuals <- ggplot(data = car_linear_model, aes(x = .resid)) +
geom_histogram(color = '#01ef63') +
xlab("residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Histogram of Residuals")
scale_location <- ggplot(car_linear_model, aes(.fitted, sqrt(abs(.stdresid)))) +
geom_point(color = '#203147', na.rm=TRUE) +
stat_smooth(method="loess", na.rm = TRUE, color = '#01ef63', size = 1, se = FALSE) +
xlab("Fitted Value") +
ylab(expression(sqrt("|Standardized residuals|"))) +
labs(title = "Cars in Jordan") +
labs(subtitle = "Scale-Location")
leverage_vs_standardized_residuals <- ggplot(data = car_linear_model, aes(.hat, .stdresid)) +
geom_point(aes(size = .cooksd), color = '#203147') +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage") +
ylab("Standardized Residuals") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Residuals vs Leverage") +
scale_size_continuous("Cook's Distance", range=c(1,5)) +
theme(legend.title = element_blank()) +
theme(legend.position= "none")
observation_number_vs_cooks_distance <- ggplot(car_linear_model, aes(seq_along(.cooksd), .cooksd)) +
geom_bar(stat="identity", position="identity", color = '#01ef63', size = 1) +
xlab("Obs. Number") +
ylab("Cook's distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's distance")
leverage_vs_cooks_distance <- ggplot(car_linear_model, aes(.hat, .cooksd))+geom_point(na.rm=TRUE) +
stat_smooth(method="loess", na.rm=TRUE, color = '#01ef63', size = 1) +
xlab("Leverage hii")+
ylab("Cook's Distance") +
labs(title = "Cars in Jordan") +
labs(subtitle = "Cook's dist vs Leverage hii/(1-hii)") +
geom_abline(slope=seq(0,3,0.5), color = "gray", linetype = "dotdash")
library(patchwork)
fitted_values_vs_residuals + histogram_of_residuals
library(patchwork)
scale_location + leverage_vs_standardized_residuals
library(patchwork)
observation_number_vs_cooks_distance + leverage_vs_cooks_distance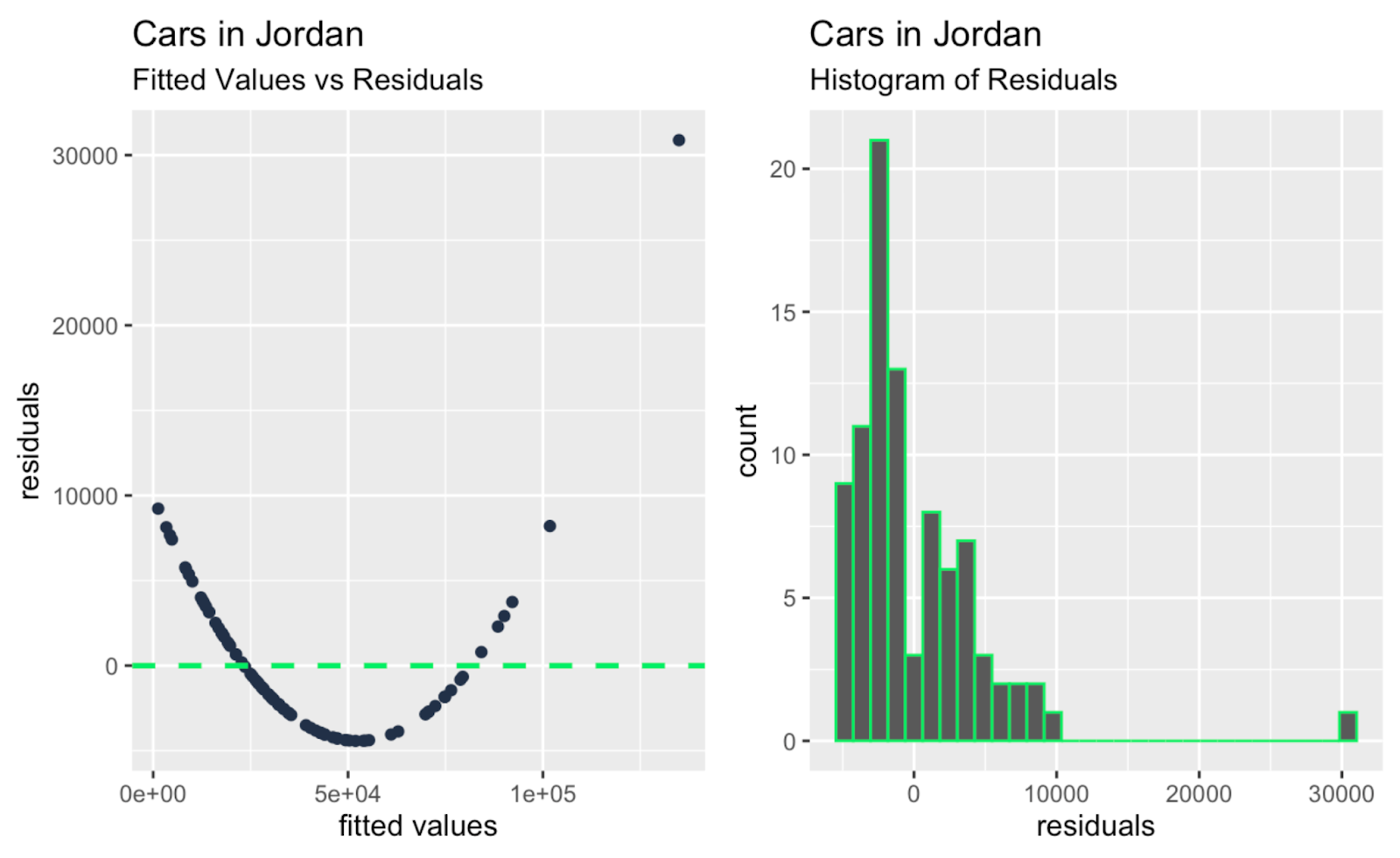
Giá trị khớp so với phần dư; histogram phần dư. Hình do Tác giả tạo
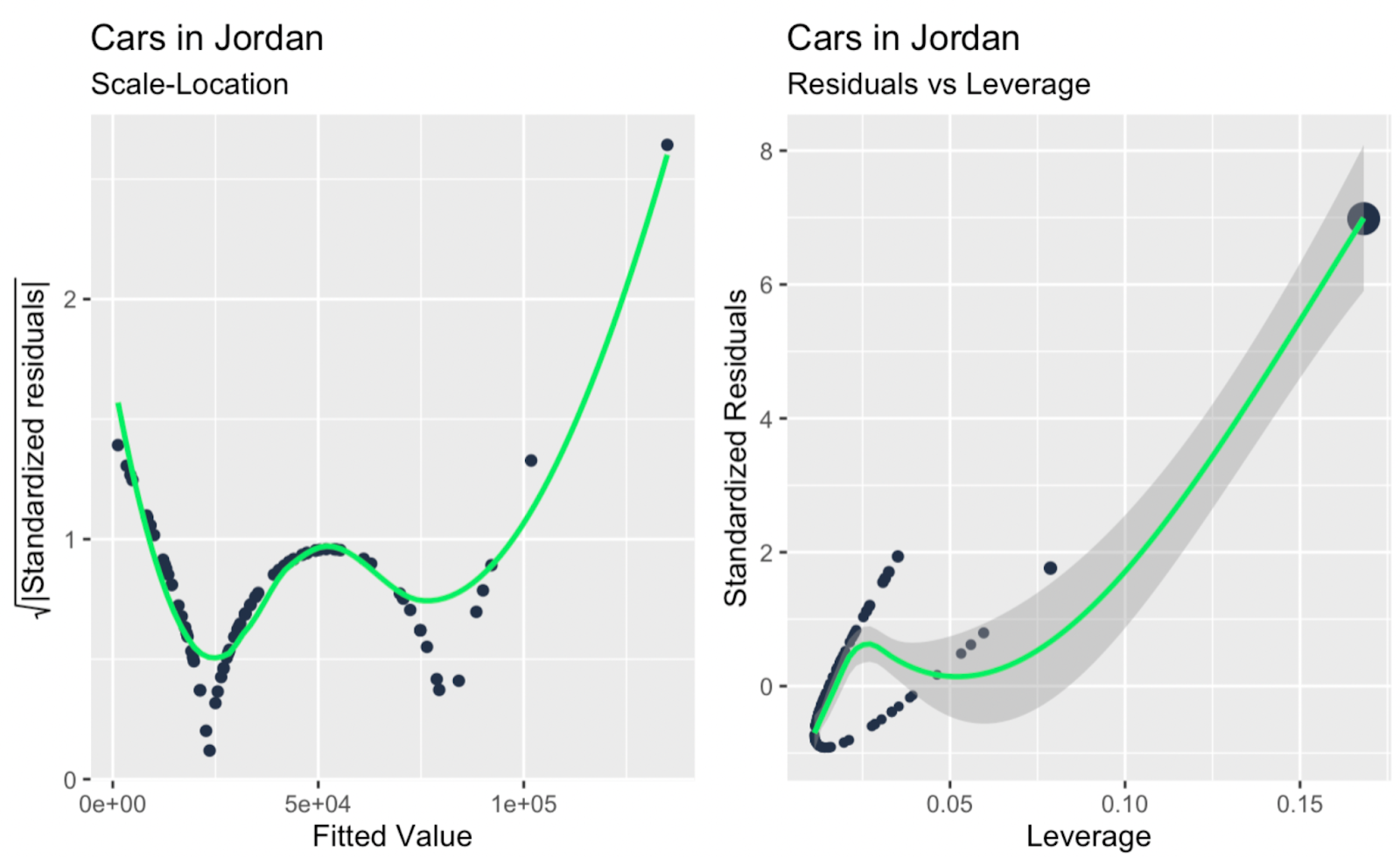
Biểu đồ scale-location; đòn bẩy so với phần dư chuẩn hóa. Hình do Tác giả tạo
Số thứ tự quan sát so với khoảng cách Cook; khoảng cách Cook so với đòn bẩy. Hình do Tác giả tạo
Có lẽ điều rút ra chính, khi lướt qua tất cả các biểu đồ chẩn đoán bổ sung ở trên, là có một hai ngoại lai lớn đang tác động mạnh đến độ dốc của đường hồi quy, và những ngoại lai này không quá hiển nhiên nếu chỉ nhìn vào biểu đồ Q-Q. Vậy biểu đồ Q-Q trong ví dụ của chúng ta hoàn thành chức năng của nó - kiểm tra tính chuẩn của phần dư - đồng thời cũng bộc lộ một hạn chế, đó là nó không đề cập đến tính độc lập, phương sai đồng nhất hay ngoại lai.
Để tham khảo thêm, tôi đưa vào đây một bảng tóm tắt ở mức cao cho thấy mỗi giả định của mô hình tuyến tính được kiểm tra bằng biểu đồ chẩn đoán nào, và tôi cũng gợi ý cách các biểu đồ chẩn đoán khác có thể phối hợp với biểu đồ Q-Q. Hãy nhớ rằng, tùy dữ liệu, các kiểu mẫu hình khác nhau có thể được bộc lộ với các biểu đồ chẩn đoán khác nhau, và một số điều chỉ lộ rõ khi kết hợp. Ví dụ, một biểu đồ Q-Q có thể xác nhận tính chuẩn, trong khi biểu đồ scale-location có thể chỉ ra hiện tượng phương sai không đồng nhất, và bạn có thể chỉ thấy cả tính chuẩn lẫn phương sai không đồng nhất khi dùng cả hai biểu đồ.
| Loại biểu đồ chẩn đoán | Hỗ trợ kiểm tra | Cách phối hợp với biểu đồ Q-Q |
|---|---|---|
| Biểu đồ Q-Q | Tính chuẩn của phần dư | |
| Histogram phần dư | Tính chuẩn của phần dư | Cung cấp cái nhìn nhanh và cảm nhận chung về tính đối xứng và độ phân tán. |
| Giá trị khớp so với phần dư | Tính tuyến tính, độc lập của sai số | Bộc lộ mẫu hình và phi tuyến, bổ trợ cho kiểm tra tính chuẩn của biểu đồ Q-Q. |
| Biểu đồ Scale-Location | Phương sai đồng nhất | Làm nổi bật độ phân tán phần dư có nhất quán hay không, bổ trợ cho kiểm tra tính chuẩn bằng biểu đồ Q-Q. |
| Biểu đồ Đòn bẩy so với Phần dư | Độc lập của sai số | Tập trung vào các điểm có đòn bẩy cao, điều mà biểu đồ Q-Q không đề cập. |
| Số thứ tự quan sát so với khoảng cách Cook | Xác định điểm ảnh hưởng lớn | Bổ trợ cho biểu đồ Q-Q bằng cách xác định ngoại lai có ảnh hưởng lớn. |
| Biểu đồ Đòn bẩy so với Khoảng cách Cook | Xác định điểm có đòn bẩy cao | Làm nổi bật các quan sát có ảnh hưởng, trong khi biểu đồ Q-Q kiểm tra tính chuẩn. |
Hy vọng bạn có thêm sự trân trọng đối với biểu đồ Q-Q như một công cụ hữu ích để đánh giá tính chuẩn và hiểu rõ hơn về cách dùng phổ biến của nó trong việc đánh giá tính chuẩn của phần dư trong hồi quy tuyến tính. Tôi cũng hy vọng bạn có thêm sự trân trọng đối với ý tưởng và tầm quan trọng của các biểu đồ chẩn đoán mô hình tuyến tính nói chung.
Tiếp tục học về hồi quy tuyến tính với Multiple Linear Regression in R: Tutorial With Examples bao quát các mô hình phức tạp hơn với nhiều biến dự báo, bao gồm các ý tưởng về đa cộng tuyến trong hồi quy. Tôi rất khuyến khích bạn đăng ký lộ trình nghề nghiệp đầy đủ và toàn diện Machine Learning Scientist in Python để học toàn bộ quy trình xây dựng mô hình, bao gồm cả học có giám sát và không giám sát.
Học cùng DataCamp
Courses
Courses
Courses