
Kursus
Supervised Learning di R: Regresi
4 Hr
46.4K
Pada intinya, R-squared menjelaskan proporsi varians pada variabel dependen yang dapat diatribusikan kepada variabel independen (atau beberapa variabel). Kita dapat memandangnya sebagai ukuran seberapa baik model kita menangkap pola pada data, dan seberapa banyak yang tersisa sebagai derau yang tak terjelaskan. Kesederhanaan dan interpretasinya yang langsung membuatnya banyak digunakan dalam diagnostik regresi linear, terutama pada regresi linear sederhana dan berganda.
Dalam artikel ini, kita akan membahas makna, perhitungan, interpretasi, dan jebakan umum terkait R-squared, sehingga kita dapat menggunakannya dengan percaya diri sekaligus penuh kehati-hatian. Selain itu, kita akan melihat beberapa contoh potongan kode untuk menghitung R-squared di R dan Python.
R-squared, dilambangkan sebagai R², adalah ukuran statistik untuk menilai goodness of fit pada model regresi. Nilai ini memberi tahu kita seberapa besar variasi pada variabel dependen yang dapat dijelaskan oleh model.
Nilai R-squared berada di antara 0 dan 1:
Walaupun konsepnya mudah, interpretasinya memerlukan pendekatan yang bernuansa, terutama saat berpindah dari teori ke praktik.
Ada beberapa cara yang secara matematis ekuivalen untuk menghitung R-squared, masing-masing menawarkan wawasan berbeda tentang apa arti “fit” sebenarnya, tergantung konteks—regresi sederhana, regresi berganda, aljabar matriks, atau pemodelan Bayesian. Mari kita telusuri pendekatan yang paling sering digunakan.
Ini adalah rumus yang paling standar dan paling banyak digunakan:
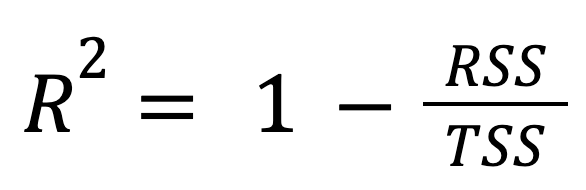
dengan:
Dengan kata lain, R-squared merepresentasikan fraksi dari total variasi yang dapat dijelaskan model.
Pendekatan ini menyoroti seberapa jauh kinerja model regresi lebih baik dibanding sekadar memprediksi rata-rata respons.
R-squared juga dapat dinyatakan langsung dalam hal varians yang dijelaskan:
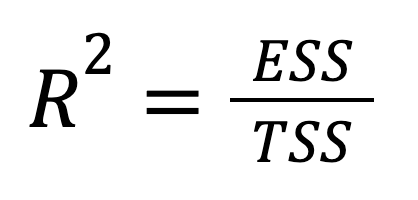
dengan:
Kita dapat melihat bahwa versi ini menekankan seberapa banyak total variasi pada keluaran yang ditangkap oleh prediksi model. Dengan kata lain, fokusnya bergeser dari apa yang gagal kita jelaskan (RSS) ke apa yang berhasil kita jelaskan (ESS), memberikan bingkai yang lebih optimistis.
Untuk telaah mendalam tentang tiga komponen sum of squares, baca Understanding Sum of Squares: A Guide to SST, SSR, and SSE.
Dalam konteks tabel ANOVA, R-squared secara alami muncul dari dekomposisi total variabilitas:

dengan:
Formulasi ini menunjukkan seberapa banyak total varians yang ditangkap oleh model, dan seberapa banyak yang tersisa tidak terjelaskan.
Perspektif ini agak unik karena mengaitkan R-squared dengan pengujian hipotesis. Ini karena rasio ESS terhadap RSS digunakan untuk menghitung F-statistic, sehingga R-squared menjadi bagian penting dari pengujian signifikansi dalam pelaporan bergaya ANOVA.
Tiga metode terakhir adalah rumus yang setara secara aljabar yang diturunkan dari dekomposisi regresi. Sekarang, berikut perspektif baru:
Pada regresi linear sederhana dengan hanya satu prediktor, R-squared memiliki jalan pintas:
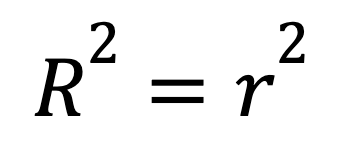
dengan
Rumus ini menunjukkan bagaimana hubungan linear yang kuat antara dua variabel beralih langsung menjadi nilai R-squared yang tinggi.
Untuk memahami teori dasar di balik regresi linear sederhana, pelajari Simple Linear Regression: Everything You Need to Know.
R-squared dapat dihitung sebagai ukuran kesalahan model yang dinormalisasi:
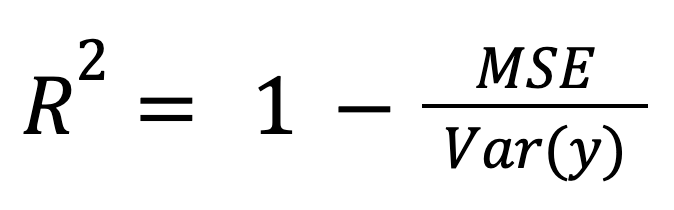
dengan:
Kerangka ini sangat relevan saat membandingkan model pada skala atau satuan yang berbeda, karena menormalkan kesalahan model dengan sebaran data keseluruhan.
Dengan asumsi residual tidak berkorelasi dengan prediksi, R-squared juga dapat ditafsirkan sebagai fraksi varians yang ditangkap oleh model:
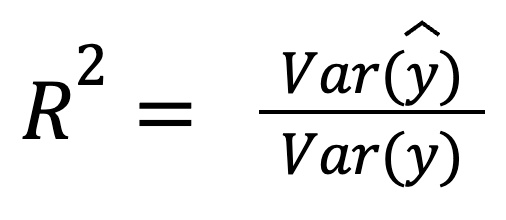
dengan:
Versi ini menyoroti seberapa baik prediksi itu sendiri mencerminkan sebaran data aktual.
Seperti telah disebutkan sebelumnya, R-squared mudah dihitung tetapi sedikit lebih rumit untuk ditafsirkan secara bermakna.
Penting untuk diingat bahwa R-squared mengukur korelasi, tetapi tidak mengukur kausalitas. Hanya karena prediktor kita menjelaskan keluaran tidak berarti mereka menyebabkannya, karena korelasi tetap bukan kausalitas. Selain itu, R-squared tidak menunjukkan apakah prediksi akurat.
Berikut dua sumber yang berguna tentang topik lanjutan terkait regresi linear:
R-squared dapat sangat membantu jika digunakan pada situasi yang tepat. Ukuran ini sesuai untuk:
Di sisi lain, R-squared dapat menyesatkan dalam skenario berikut:
Sekarang mari ilustasikan konsep R-squared di R dan Python menggunakan dataset Kaggle Fish Market. Dalam kedua bahasa pemrograman, kita akan membangun dua model:
Mari mulai dengan R.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredKeluaran:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredKeluaran:
[1] 0.8679Seperti yang kita lihat, R-squared sedikit meningkat setelah menambahkan prediktor yang tidak relevan (Model 2). Namun, itu tidak berarti model menjadi lebih baik. Bagaimanapun, kita hanya menambahkan derau acak.
Untuk bacaan lebih lanjut terkait topik ini, lihat tutorial berikut:
Dan jangan lupa untuk mendaftar di kursus khusus kami:
Sekarang, mari coba di Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Keluaran:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Keluaran:
0.8679Sekali lagi, kita mengamati sedikit peningkatan nilai R-squared, tetapi ini hanya menangkap derau acak.
Untuk terus belajar, daftarlah di kursus kami:
Sekarang kita akan secara singkat membandingkan R-squared dengan dua metrik terkait: adjusted R-squared dan predicted R-squared.
Berbeda dengan R-squared, adjusted R-squared memperhitungkan jumlah prediktor. Secara khusus, ia memberi penalti pada model yang memasukkan prediktor yang tidak perlu:
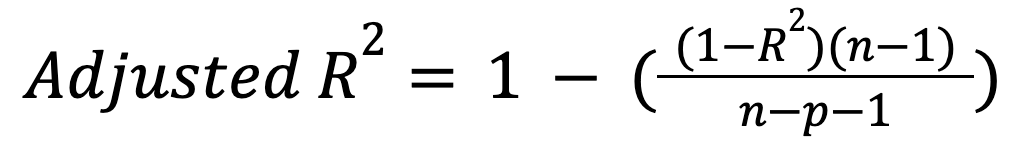
dengan:
Metrik ini hanya meningkat jika prediktor baru benar-benar meningkatkan model secara bermakna, dan dapat menurun pada kasus sebaliknya. Baca tutorial kami untuk mempelajari lebih lanjut tentang perluasan penting ini: Adjusted R-Squared: A Clear Explanation with Examples.
Sementara R-squared biasa menunjukkan seberapa baik model berkinerja pada data pelatihan, predicted R-squared memberi tahu kita seberapa baik kinerjanya pada data baru yang belum terlihat. Maka dari itu, metrik ini mengevaluasi kemampuan generalisasi model.
Predicted R-squared dihitung menggunakan cross-validation atau dengan menyisihkan sebagian data pelatihan untuk pengujian lebih lanjut. Nilainya dapat jauh lebih rendah daripada R-squared biasa jika model mengalami overfitting. Karena itu, skenario di mana kita memperoleh nilai R-squared biasa yang tinggi tetapi predicted R-squared rendah sangat mungkin mengindikasikan overfitting model.
Mari kita lihat beberapa mitos populer tentang R-squared, beserta keadaan yang sebenarnya:
Singkatnya, kita mempelajari apa itu R-squared, cara menghitung metrik ini (baik secara matematis maupun di R dan Python), kapan menggunakannya dan kapan menghindarinya, serta bagaimana menafsirkan hasilnya. Selain itu, kita menyinggung dua metrik terkait dan beberapa miskonsepsi luas tentang R-squared.
Intinya, R-squared adalah ukuran kecocokan model regresi yang berguna, intuitif, dan lugas. Ini adalah titik awal yang bagus untuk evaluasi model, tetapi harus digunakan dengan bijak, ditafsirkan bersama metrik lainnya, dan tidak disalahartikan sebagai keseluruhan gambaran. Hal ini terutama berlaku untuk konteks regresi berganda dan pemilihan model.
Belajar bersama DataCamp
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
