
Courses
Supervised Learning in R: Regression
4 giờ
46.4K
Cốt lõi của R-squared là giải thích tỷ lệ phương sai của biến phụ thuộc có thể quy cho biến độc lập (hoặc các biến độc lập). Ta có thể xem nó như một thước đo cho biết mô hình của chúng ta nắm bắt câu chuyện trong dữ liệu tốt đến đâu, và còn bao nhiêu phần là nhiễu chưa giải thích được. Sự đơn giản và khả năng diễn giải trực tiếp khiến nó được sử dụng rộng rãi trong chẩn đoán hồi quy tuyến tính, đặc biệt trong hồi quy tuyến tính đơn và bội.
Trong bài viết này, chúng ta sẽ bàn về ý nghĩa, cách tính, cách diễn giải và các sai lầm thường gặp xoay quanh R-squared, để có thể dùng chỉ số này vừa tự tin vừa thận trọng. Ngoài ra, chúng ta sẽ xem một số ví dụ mã để tính R-squared trong R và Python.
R-squared, ký hiệu là R², là một thước đo thống kê về độ phù hợp của mô hình trong hồi quy. Nó cho biết bao nhiêu phần biến thiên của biến phụ thuộc được mô hình giải thích.
Giá trị R-squared nằm trong khoảng từ 0 đến 1:
Mặc dù khái niệm khá đơn giản, cách diễn giải lại đòi hỏi sự tinh tế, nhất là khi chuyển từ lý thuyết sang thực hành.
Có một số cách tính R-squared tương đương về mặt toán học, mỗi cách mang lại góc nhìn khác nhau về ý nghĩa của “độ phù hợp” tuỳ theo bối cảnh—hồi quy đơn, hồi quy bội, đại số ma trận, hay mô hình hoá Bayes. Hãy cùng tìm hiểu các cách dùng phổ biến nhất.
Đây là công thức tiêu chuẩn và được dùng rộng rãi nhất:
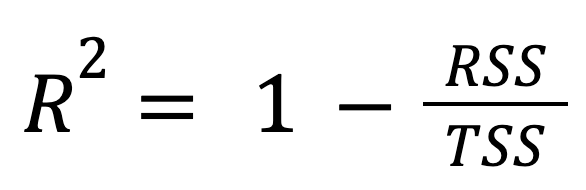
trong đó:
Nói cách khác, R-squared biểu thị phần tỷ lệ của tổng biến thiên mà mô hình giải thích được.
Cách tiếp cận này làm nổi bật mức độ mô hình hồi quy tốt hơn so với việc chỉ dự đoán giá trị trung bình của biến phản hồi.
R-squared cũng có thể biểu diễn trực tiếp theo phương sai được giải thích:
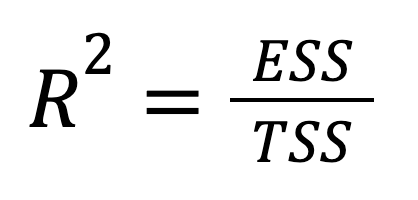
trong đó:
Ta thấy phiên bản này nhấn mạnh mức độ biến thiên của kết quả được nắm bắt bởi dự đoán của mô hình. Nói cách khác, trọng tâm chuyển từ những gì ta không giải thích được (RSS) sang những gì ta đã giải thích (ESS), mang lại một cách nhìn lạc quan hơn.
Để tìm hiểu sâu về ba thành phần của tổng bình phương, hãy đọc Understanding Sum of Squares: A Guide to SST, SSR, and SSE.
Trong bối cảnh bảng ANOVA, R-squared xuất hiện tự nhiên từ việc phân rã tổng biến thiên:

trong đó:
Dạng này cho thấy bao nhiêu phần tổng phương sai được mô hình nắm bắt, và bao nhiêu phần còn lại chưa được giải thích.
Cách nhìn này hơi đặc biệt vì nó gắn R-squared với kiểm định giả thuyết. Lý do là tỷ số ESS trên RSS được dùng để tính thống kê F, khiến R-squared trở thành một phần quan trọng của kiểm định ý nghĩa trong báo cáo kiểu ANOVA.
Ba phương pháp vừa rồi đều là các công thức tương đương đại số suy ra từ phân rã hồi quy. Giờ đây, là một góc nhìn mới:
Trong hồi quy tuyến tính đơn với chỉ một biến dự báo, R-squared có một lối tắt:
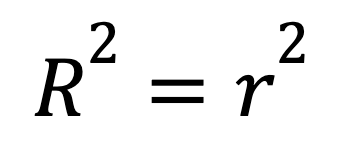
trong đó
Công thức này cho thấy mối quan hệ tuyến tính mạnh giữa hai biến sẽ trực tiếp chuyển thành R-squared cao.
Để hiểu lý thuyết nền tảng của hồi quy tuyến tính đơn, hãy xem Simple Linear Regression: Everything You Need to Know.
R-squared có thể được tính như một thước đo lỗi mô hình đã chuẩn hoá:
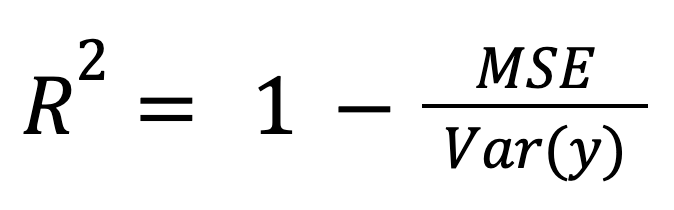
trong đó:
Cách nhìn này đặc biệt hữu ích khi so sánh các mô hình có thang đo hoặc đơn vị khác nhau, bởi nó chuẩn hoá lỗi mô hình theo mức độ phân tán chung của dữ liệu.
Giả sử phần dư không tương quan với dự đoán, R-squared cũng có thể được diễn giải là tỷ lệ phương sai do mô hình nắm bắt:
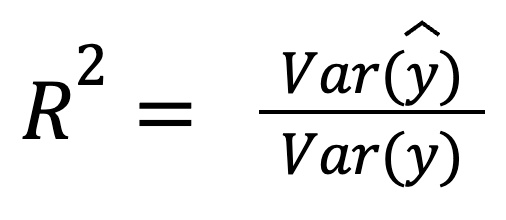
trong đó:
Phiên bản này nhấn mạnh mức độ phân tán của dự đoán phản ánh độ phân tán của dữ liệu thực tốt đến đâu.
Như đã đề cập, R-squared dễ tính nhưng khó diễn giải một cách có ý nghĩa hơn.
Điều quan trọng cần nhớ là R-squared đo lường tương quan, chứ không đo lường quan hệ nhân quả. Việc các biến dự báo giải thích được kết quả không có nghĩa là chúng gây ra kết quả đó, vì tương quan vẫn không đồng nghĩa với nhân quả. Ngoài ra, R-squared không cho biết dự đoán có chính xác hay không.
Dưới đây là hai tài nguyên hữu ích về các chủ đề nâng cao liên quan đến hồi quy tuyến tính:
R-squared có thể rất hữu ích nếu dùng đúng tình huống. Nó phù hợp cho:
Mặt khác, R-squared có thể gây hiểu lầm trong các trường hợp sau:
Giờ hãy minh họa khái niệm R-squared trong R và Python bằng bộ dữ liệu Fish Market trên Kaggle. Ở cả hai ngôn ngữ, chúng ta sẽ xây dựng hai mô hình:
Hãy bắt đầu với R.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredKết quả:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredKết quả:
[1] 0.8679Như ta thấy, R-squared tăng nhẹ sau khi thêm một biến dự báo không liên quan (Mô hình 2). Tuy nhiên, điều đó không có nghĩa mô hình tốt hơn. Suy cho cùng, ta chỉ thêm nhiễu ngẫu nhiên.
Để đọc thêm về chủ đề này, xem các hướng dẫn sau:
Và đừng quên đăng ký khoá học phù hợp của chúng tôi:
Bây giờ, hãy thử với Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Kết quả:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Kết quả:
0.8679Một lần nữa, ta quan sát thấy R-squared tăng nhẹ, nhưng điều này chỉ là do nắm bắt nhiễu ngẫu nhiên.
Để tiếp tục học, hãy đăng ký các khoá học:
Giờ chúng ta sẽ so sánh ngắn gọn R-squared với hai chỉ số liên quan: R-squared hiệu chỉnh và R-squared dự đoán.
Khác với R-squared, R-squared hiệu chỉnh tính đến số lượng biến dự báo. Cụ thể, nó phạt mô hình khi thêm các biến không cần thiết:
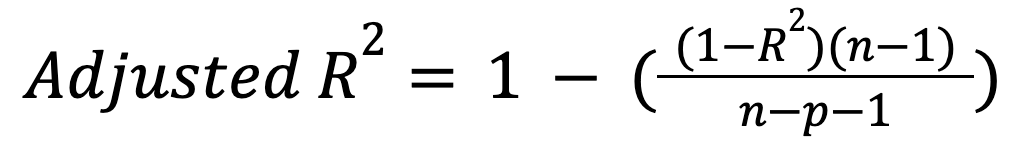
trong đó:
Chỉ số này chỉ tăng nếu một biến dự báo mới thực sự cải thiện mô hình một cách có ý nghĩa, và có thể giảm trong trường hợp ngược lại. Đọc hướng dẫn của chúng tôi để tìm hiểu thêm về mở rộng quan trọng này: Adjusted R-Squared: A Clear Explanation with Examples.
Trong khi R-squared thông thường cho biết mô hình hoạt động tốt thế nào trên dữ liệu huấn luyện, R-squared dự đoán cho biết nó hoạt động ra sao trên dữ liệu mới, chưa thấy. Do đó, chỉ số này đánh giá khả năng khái quát hoá của mô hình.
R-squared dự đoán được tính bằng cách dùng cross-validation hoặc giữ lại một phần dữ liệu huấn luyện để kiểm tra sau. Nó có thể thấp hơn đáng kể so với R-squared thông thường nếu mô hình bị quá khớp. Vì vậy, tình huống có R-squared thông thường cao nhưng R-squared dự đoán thấp rất có thể cho thấy mô hình bị quá khớp.
Hãy xem một số quan niệm sai lầm phổ biến về R-squared, kèm thực tế đúng đắn:
Tóm lại, chúng ta đã học R-squared là gì, cách tính chỉ số này (cả về mặt toán học và trong R, Python), khi nào nên dùng và khi nào nên tránh, cũng như cách diễn giải kết quả. Bên cạnh đó, chúng ta đã đề cập hai chỉ số liên quan và một số hiểu lầm phổ biến về R-squared.
Tóm gọn lại, R-squared là một thước đo hữu ích, trực quan và đơn giản về độ phù hợp của mô hình hồi quy. Nó là điểm khởi đầu tốt cho đánh giá mô hình, nhưng cần dùng khôn ngoan, diễn giải cùng các chỉ số khác và không bị nhầm lẫn là bức tranh toàn diện. Điều này đặc biệt đúng trong bối cảnh hồi quy bội và lựa chọn mô hình.
Học cùng DataCamp
Courses
Courses
Courses