
Corso
Supervised Learning in R: Regression
4 h
46.4K
Alla base, R-quadro spiega la quota di varianza nella variabile dipendente attribuibile alla variabile (o alle variabili) indipendente. Possiamo considerarlo come una misura di quanto bene il nostro modello cattura la storia nei dati e quanto resta come rumore non spiegato. La sua semplicità e l’interpretazione diretta lo rendono molto diffuso nella diagnostica della regressione lineare, soprattutto nella regressione lineare semplice e multipla.
In questo articolo parleremo del significato, del calcolo, dell’interpretazione e delle insidie comuni legate a R-quadro, così da usarlo con sicurezza e attenzione. Inoltre, daremo un’occhiata ad alcuni esempi di snippet di codice per calcolare R-quadro in R e Python.
R-quadro, indicato come R², è una misura statistica della bontà di adattamento nei modelli di regressione. Ci dice quanta parte della variazione nella variabile dipendente può essere spiegata dal modello.
Il valore di R-quadro è compreso tra 0 e 1:
Sebbene il concetto sia lineare, la sua interpretazione richiede un approccio sfumato, soprattutto passando dalla teoria alla pratica.
Esistono diversi modi matematicamente equivalenti per calcolare R-quadro, ognuno dei quali offre una prospettiva diversa su cosa significhi davvero “adattamento”, a seconda del contesto — regressione semplice, multipla, algebra matriciale o modellazione bayesiana. Vediamo gli approcci più usati.
Questa è la formula più standard e diffusa:
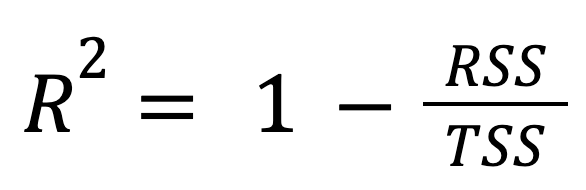
dove:
In altre parole, R-quadro rappresenta la frazione della variazione totale che il modello spiega.
Questo approccio evidenzia quanto il modello di regressione sia migliore rispetto a limitarsi a predire la media della risposta.
R-quadro può anche essere espresso direttamente in termini di varianza spiegata:
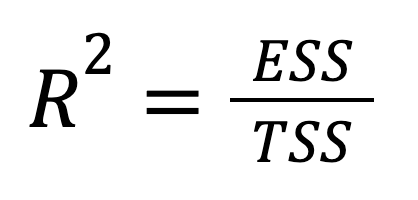
dove:
Si vede che questa versione enfatizza quanta parte della variazione totale dell’esito è catturata dalle previsioni del modello. In altre parole, qui l’attenzione passa da ciò che non abbiamo spiegato (RSS) a ciò che abbiamo spiegato (ESS), offrendo un inquadramento più ottimistico.
Per approfondire i tre componenti della somma dei quadrati, leggi Understanding Sum of Squares: A Guide to SST, SSR, and SSE.
Nel contesto di una tabella ANOVA, R-quadro emerge naturalmente dalla scomposizione della variabilità totale:

dove:
Questa formulazione mostra quanta parte della varianza totale è intercettata dal modello e quanta rimane non spiegata.
Questa prospettiva è un po’ particolare perché collega R-quadro al test d’ipotesi. Questo perché il rapporto tra ESS e RSS è usato per calcolare la statistica F, rendendo R-quadro una parte importante dei test di significatività nei report in stile ANOVA.
Le tre precedenti erano tutte formule algebricamente equivalenti derivate dalla scomposizione della regressione. Ora, ecco una nuova prospettiva:
Nella regressione lineare semplice con un solo predittore, R-quadro ha una scorciatoia:
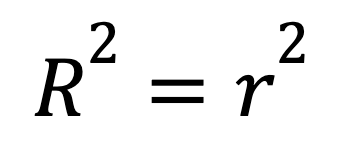
dove
Questa formula mostra come una forte relazione lineare tra due variabili si traduca direttamente in un R-quadro elevato.
Per capire la teoria alla base della regressione lineare semplice, passa per Simple Linear Regression: Everything You Need to Know.
R-quadro può essere calcolato come misura normalizzata dell’errore del modello:
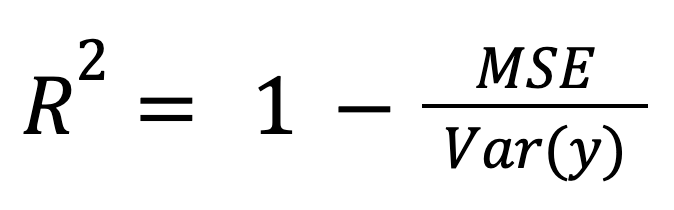
dove:
Questa impostazione è particolarmente utile quando si confrontano modelli su scale o unità diverse, perché normalizza l’errore del modello rispetto alla dispersione complessiva dei dati.
Assumendo che i residui non siano correlati con le previsioni, R-quadro può anche essere interpretato come la frazione di varianza catturata dal modello:
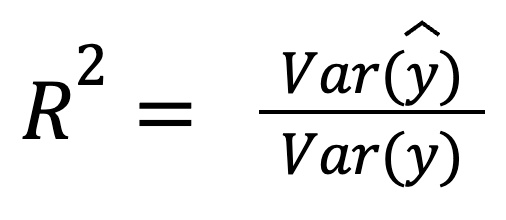
dove:
Questa versione mette in evidenza quanto bene le previsioni riflettano la dispersione dei dati reali.
Come abbiamo accennato, R-quadro è facile da calcolare ma un po’ più difficile da interpretare in modo significativo.
È importante ricordare che R-quadro misura la correlazione, ma non misura la causalità. Il fatto che i nostri predittori spieghino l’esito non significa che lo causino, perché la correlazione non implica causalità. Inoltre, R-quadro non indica se le previsioni sono accurate.
Ecco due risorse utili su argomenti più avanzati legati alla regressione lineare:
R-quadro può essere molto utile se usato nelle situazioni giuste. È appropriato per:
D’altra parte, R-quadro può essere fuorviante nei seguenti scenari:
Ora illustriamo il concetto di R-quadro in R e Python usando il dataset Kaggle Fish Market. In entrambi i linguaggi costruiremo due modelli:
Iniziamo con R.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredOutput:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredOutput:
[1] 0.8679Come si vede, R-quadro aumenta leggermente dopo aver aggiunto un predittore irrilevante (Modello 2). Tuttavia, ciò non significa che il modello sia migliorato. Dopotutto, abbiamo solo aggiunto rumore casuale.
Per ulteriori letture sull’argomento, vedi i seguenti tutorial:
E ricorda di iscriverti al nostro corso dedicato:
Ora, proviamo in Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Output:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Output:
0.8679Anche qui osserviamo un lieve aumento del valore di R-quadro, ma sta solo catturando rumore casuale.
Per continuare a imparare, iscriviti ai nostri corsi:
Ora confronteremo brevemente R-quadro con due metriche correlate: R-quadro corretto e R-quadro predetto.
A differenza di R-quadro, R-quadro corretto tiene conto del numero di predittori. In particolare, penalizza il modello per l’inclusione di predittori inutili:
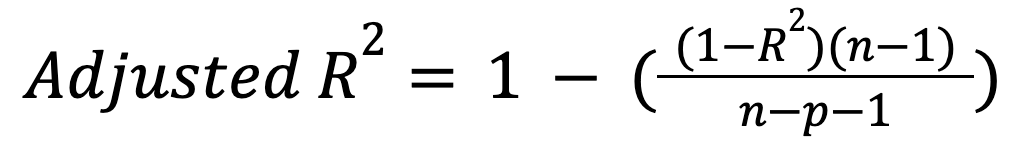
dove:
Questa metrica aumenta solo se un nuovo predittore migliora davvero il modello in modo significativo e può diminuire nel caso opposto. Leggi il nostro tutorial per saperne di più su questa importante estensione: Adjusted R-Squared: A Clear Explanation with Examples.
Mentre il normale R-quadro mostra quanto bene il modello si comporta sui dati di training, R-quadro predetto ci dice quanto bene si comporta su nuovi dati, non visti. Quindi, questa metrica valuta la capacità di generalizzazione del modello.
R-quadro predetto si calcola usando la cross-validation o tenendo da parte una porzione dei dati di training per test successivi. Può essere significativamente più basso del normale R-quadro se il modello è sovradattato. Pertanto, uno scenario in cui otteniamo un valore alto di R-quadro normale ma un valore basso di R-quadro predetto può indicare molto probabilmente overfitting del modello.
Diamo un’occhiata ad alcuni miti diffusi su R-quadro, insieme alla realtà dei fatti:
In sintesi, abbiamo visto cos’è R-quadro, come calcolare questa metrica (sia matematicamente che in R e Python), quando usarla e quando evitarla, e come interpretarne i risultati. Inoltre, abbiamo toccato due metriche correlate e alcuni fraintendimenti diffusi su R-quadro.
In poche parole, R-quadro è una misura utile, intuitiva e lineare dell’aderenza di un modello di regressione. È un ottimo punto di partenza per la valutazione dei modelli, ma va usata con giudizio, interpretata insieme ad altre metriche e non scambiata per l’intero quadro. Questo è particolarmente vero nella regressione multipla e nei contesti di selezione dei modelli.
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

