
Kurs
Supervised Learning in R: Regression
4 Std.
46.4K
Im Kern erklärt R-Quadrat den Anteil der Varianz in der abhängigen Variable, der auf die unabhängige(n) Variable(n) zurückgeführt werden kann. Wir können sie als Maß dafür betrachten, wie gut unser Modell die Geschichte in den Daten erfasst und wie viel als unerklärtes Rauschen übrig bleibt. Aufgrund ihrer Einfachheit und direkten Interpretation ist sie in der linearen Regressionsdiagnostik weit verbreitet, insbesondere bei der einfachen und multiplen linearen Regression.
In diesem Artikel werden wir die Bedeutung, die Berechnung, die Interpretation und die häufigsten Fallstricke von R-Quadrat besprechen, damit wir es mit Zuversicht und Sorgfalt verwenden können. Außerdem sehen wir uns einige Beispiele für Codeschnipsel zur Berechnung von R-Quadrat in R und Python an.
Das R-Quadrat (R²) ist ein statistisches Maß für die Anpassungsgüte von Regressionsmodellen. Sie sagt uns, wie viel der Variation in der abhängigen Variable durch das Modell erklärt werden kann.
Der Wert von R-Quadrat liegt zwischen 0 und 1:
Das Konzept ist zwar einfach, aber seine Auslegung erfordert einen differenzierten Ansatz, vor allem, wenn man von der Theorie zur Praxis übergeht.
Es gibt mehrere mathematisch äquivalente Methoden zur Berechnung des R-Quadrats, die je nach Kontext einen anderen Einblick in die Bedeutung von "Passung" bieten: einfache Regression, multiple Regression, Matrixalgebra oder Bayes'sche Modellierung. Schauen wir uns die am häufigsten verwendeten Ansätze an.
Dies ist die gängigste und am häufigsten verwendete Formel:
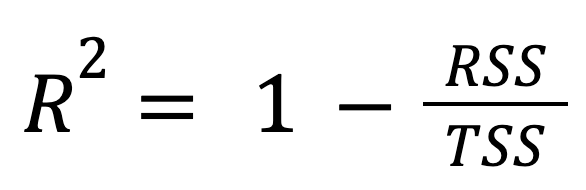
wo:
Mit anderen Worten: Das R-Quadrat gibt den Anteil der Gesamtvariation an, den das Modell abdeckt.
Dieser Ansatz verdeutlicht, wie viel besser das Regressionsmodell im Vergleich zur einfachen Vorhersage des Mittelwerts der Antwort abschneidet.
Das R-Quadrat kann auch direkt in Form der erklärten Varianz ausgedrückt werden:
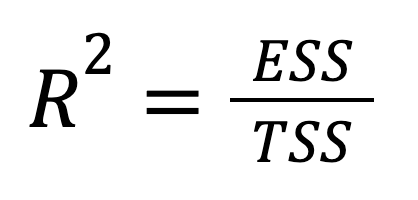
wo:
Wir sehen, dass diese Version hervorhebt, wie viel von der Gesamtvariation des Ergebnisses von den Vorhersagen des Modells erfasst wird. Mit anderen Worten: Der Schwerpunkt wird von dem, was wir nicht erklären konnten (RSS), auf das verlagert, was wir erklärt haben (ESS), was eine optimistischere Sichtweise ermöglicht.
Einen tieferen Einblick in die drei Komponenten der Quadratsumme erhältst du unter Summen der Quadrate verstehen: Ein Leitfaden für SST, SSR und SSE.
Im Zusammenhang mit einer ANOVA-Tabelle ergibt sich das R-Quadrat natürlich aus der Zerlegung der Gesamtvariabilität:

wo:
Diese Formulierung zeigt, wie viel von der Gesamtvarianz durch das Modell erfasst wird und wie viel unerklärt bleibt.
Diese Perspektive ist ein wenig einzigartig, weil sie das R-Quadrat mit dem Hypothesentest verbindet. Das liegt daran, dass das Verhältnis von ESS zu RSS zur Berechnung der F-Statistik verwendet wird, wodurch das R-Quadrat ein wichtiger Bestandteil der Signifikanztests in der ANOVA-Berichterstattung ist.
Die letzten drei Methoden waren alle algebraisch gleichwertige Formeln, die aus der Regressionszerlegung abgeleitet wurden. Jetzt gibt es eine neue Perspektive:
Bei einer einfachen linearen Regression mit nur einem Prädiktor hat das R-Quadrat eine Abkürzung:
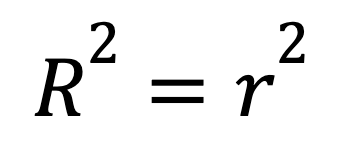
wo
Diese Formel zeigt, wie sich eine starke lineare Beziehung zwischen zwei Variablen direkt in einem hohen R-Quadrat niederschlägt.
Um die zugrundeliegende Theorie hinter der einfachen linearen Regression zu verstehen, besuche Einfache lineare Regression: Alles, was du wissen musst.
Das R-Quadrat kann als normalisiertes Maß für den Modellfehler berechnet werden:
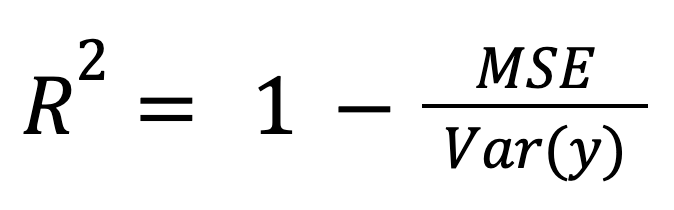
wo:
Dieser Rahmen ist besonders wichtig, wenn du Modelle in verschiedenen Maßstäben oder Einheiten vergleichst, da er den Modellfehler durch die Gesamtdatenstreuung normalisiert.
Unter der Annahme, dass die Residuen nicht mit den Vorhersagen korreliert sind, kann R-Quadrat auch als der Anteil der Varianz interpretiert werden, den das Modell erfasst:
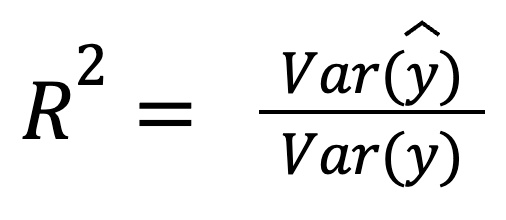
wo:
Diese Version zeigt, wie gut die Vorhersagen selbst die Streuung der tatsächlichen Daten widerspiegeln.
Wie wir bereits erwähnt haben, ist das R-Quadrat leicht zu berechnen, aber etwas schwieriger zu interpretieren.
Es ist wichtig, daran zu denken, dass das R-Quadrat die Korrelationmisst , aber nicht die Kausalität. Nur weil unsere Prädiktoren das Ergebnis erklären, bedeutet das nicht, dass sie Ursache essind, denn Korrelation bedeutet noch lange nicht Kausalität. Außerdem sagt das R-Quadrat nichts darüber aus, ob die Vorhersagen richtig sind.
Hier sind zwei nützliche Ressourcen zu fortgeschrittenen Themen im Zusammenhang mit der linearen Regression:
R-Quadrat kann sehr hilfreich sein, wenn es in den richtigen Situationen eingesetzt wird. Es ist geeignet für:
Andererseits kann das R-Quadrat in den folgenden Szenarien irreführend sein:
Veranschaulichen wir uns nun das Konzept von R-Quadrat in R und Python anhand des Fish Market Kaggle-Datensatzes. In beiden Programmiersprachen werden wir zwei Modelle erstellen:
Fangen wir mit R an.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredAusgabe:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredAusgabe:
[1] 0.8679Wie wir sehen können, steigt das R-Quadrat leicht an, wenn wir einen irrelevanten Prädiktor hinzufügen (Modell 2). Das heißt aber nicht, dass das Modell besser geworden ist. Schließlich haben wir nur zufälliges Rauschen hinzugefügt.
Weitere Informationen zu diesem Thema findest du in den folgenden Tutorials:
Und vergiss nicht, dich für den vorgesehenen Kurs anzumelden:
Versuchen wir es jetzt in Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Ausgabe:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Ausgabe:
0.8679Auch hier beobachten wir einen leichten Anstieg des R-Quadratwerts, aber das ist nur ein zufälliges Rauschen.
Um weiter zu lernen, melde dich für unsere Kurse an:
Wir werden nun kurz das R-Quadrat mit zwei verwandten Kennzahlen vergleichen: dem bereinigten R-Quadrat und dem vorhergesagten R-Quadrat.
Im Gegensatz zum R-Quadrat berücksichtigt das bereinigte R-Quadrat die Anzahl der Prädiktoren. Insbesondere wird das Modell für die Einbeziehung unnötiger Prädiktoren bestraft:
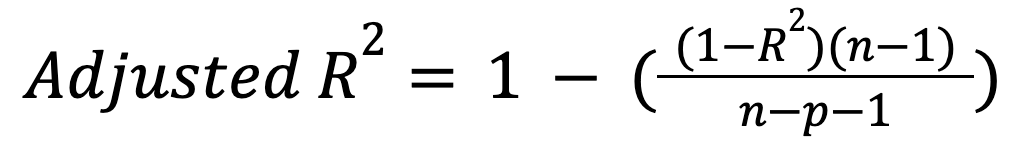
wo:
Diese Kennzahl steigt nur, wenn ein neuer Prädiktor das Modell tatsächlich sinnvoll verbessert, und kann im umgekehrten Fall sinken. Lies unseren Leitfaden, um mehr über diese wichtige Erweiterung zu erfahren: Bereinigtes R-Quadrat: Eine klare Erläuterung mit Beispielen.
Während das reguläre R-Quadrat zeigt, wie gut das Modell in den Trainingsdaten abschneidet, sagt das vorhergesagte R-Quadrat aus, wie gut es in neuen, ungesehenen Daten abschneidet. Mit dieser Kennzahl wird also die Generalisierungsfähigkeit des Modells bewertet.
Das vorhergesagte R-Quadrat wird mithilfe einer Kreuzvalidierung oder durch das Zurückhalten eines Teils der Trainingsdaten für weitere Tests berechnet. Er kann deutlich niedriger sein als das reguläre R-Quadrat, wenn das Modell überangepasst ist. Ein Szenario, in dem wir einen hohen Wert für das reguläre R-Quadrat, aber einen niedrigen Wert für das vorhergesagte R-Quadrat erhalten, kann daher höchstwahrscheinlich auf eine Überanpassung des Modells hinweisen.
Werfen wir einen Blick auf einige populäre Mythen über das R-Quadrat und den wahren Stand der Dinge:
Zusammenfassend haben wir gelernt, was R-Quadrat ist, wie man diese Kennzahl berechnet (sowohl mathematisch als auch in R und Python), wann man sie verwenden und wann man sie vermeiden sollte und wie man die Ergebnisse interpretiert. Außerdem haben wir zwei verwandte Metriken und einige weit verbreitete Missverständnisse über das R-Quadrat angesprochen.
Kurz gesagt ist das R-Quadrat ein nützliches, intuitives und einfaches Maß für die Anpassung eines Regressionsmodells. Sie ist ein guter Ausgangspunkt für die Bewertung von Modellen, sollte aber mit Bedacht eingesetzt und zusammen mit anderen Kennzahlen interpretiert werden und nicht mit dem Gesamtbild verwechselt werden. Das gilt vor allem für die multiple Regression und die Modellauswahl.
Lernen mit DataCamp
Kurs
Kurs
Kurs
Tutorial
Allan Ouko
Tutorial
Allan Ouko
Tutorial
Aditya Sharma
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree

