
Curso
Supervised Learning in R: Regression
4 h
46.4K
En esencia, la R-cuadrado explica la proporción de varianza de la variable dependiente que puede atribuirse a la variable (o variables) independiente(s). Podemos considerarlo como una medida de lo bien que nuestro modelo capta la historia en los datos, y cuánto queda como ruido sin explicar. Su sencillez y su interpretación directa hacen que esté muy extendido en los diagnósticos de regresión lineal, especialmente en la regresión lineal simple y múltiple.
En este artículo hablaremos del significado, el cálculo, la interpretación y los errores más comunes que rodean a la R-cuadrado, para que podamos utilizarla con confianza y cuidado. Además, veremos algunos ejemplos de fragmentos de código para calcular R-cuadrado en R y Python.
El R-cuadrado, denotado como R², es una medida estadística de la bondad del ajuste en los modelos de regresión. Nos dice qué parte de la variación de la variable dependiente puede explicar el modelo.
El valor de R-cuadrado se sitúa entre 0 y 1:
Aunque el concepto es sencillo, su interpretación requiere un enfoque matizado, sobre todo cuando se pasa de la teoría a la práctica.
Hay varias formas matemáticamente equivalentes de calcular la R-cuadrado, cada una de las cuales ofrece una visión diferente de lo que realmente significa "ajuste", dependiendo del contexto: regresión simple, regresión múltiple, álgebra matricial o modelización bayesiana. Exploremos el más frecuente de estos enfoques.
Ésta es la fórmula más estándar y utilizada:
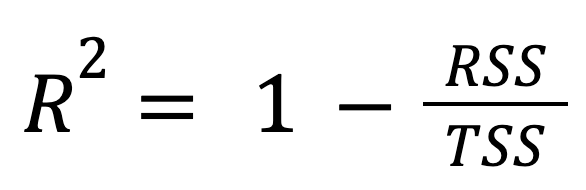
donde:
En otras palabras, la R-cuadrado representa la fracción de la variación total que explica el modelo.
Este enfoque pone de manifiesto cuánto mejor funciona el modelo de regresión en comparación con la simple predicción de la media de la respuesta.
El R-cuadrado también puede expresarse directamente en términos de varianza explicada:
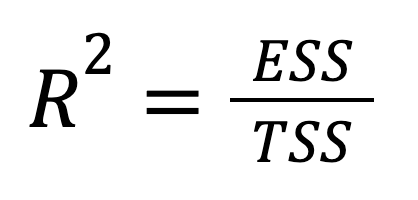
donde:
Podemos ver que esta versión hace hincapié en qué parte de la variación total del resultado es captada por las predicciones del modelo. En otras palabras, aquí el centro de atención se desplaza de lo que no conseguimos explicar (RSS) a lo que sí logramos (ESS), proporcionando un encuadre más optimista.
Para profundizar en los tres componentes de la suma de cuadrados, lee Comprender la suma de cuadrados: Guía de la TSM, la TSS y la TSE.
En el contexto de una tabla ANOVA, la R-cuadrado surge naturalmente de la descomposición de la variabilidad total:

donde:
Esta formulación muestra qué parte de la varianza total recoge el modelo y qué parte queda sin explicar.
Esta perspectiva es un poco única porque vincula la R-cuadrado a la comprobación de hipótesis. Esto se debe a que la relación entre ESS y RSS se utiliza para calcular el estadístico F de , lo que hace que el R-cuadrado sea una parte importante de las pruebas de significación en los informes tipo ANOVA.
Los tres últimos métodos eran fórmulas algebraicamente equivalentes derivadas de la descomposición de la regresión. He aquí una nueva perspectiva:
En la regresión lineal simple con un solo predictor, la R-cuadrado tiene un atajo:
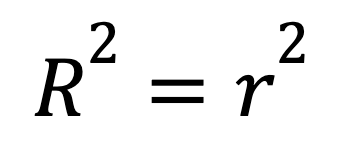
donde
Esta fórmula muestra cómo una fuerte relación lineal entre dos variables se traduce directamente en un elevado R-cuadrado.
Para comprender la teoría subyacente a la regresión lineal simple, consulta Regresión lineal simple: Todo lo que necesitas saber.
El R-cuadrado puede calcularse como una medida normalizada del error del modelo:
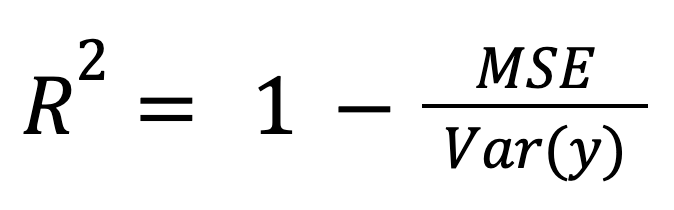
donde:
Este encuadre es especialmente relevante cuando se comparan modelos entre diferentes escalas o unidades, porque normaliza el error del modelo según la dispersión general de los datos.
Suponiendo que los residuos no estén correlacionados con las predicciones, R-cuadrado también puede interpretarse como la fracción de varianza captada por el modelo:
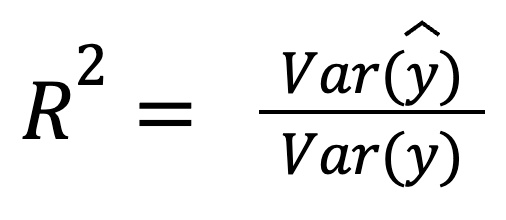
donde:
Esta versión pone de relieve lo bien que las propias predicciones reflejan la dispersión de los datos reales.
Como hemos mencionado antes, la R-cuadrado es fácil de calcular, pero un poco más complicada de interpretar de forma significativa.
Es importante recordar que la R-cuadrado mide la correlación, pero no la causalidad. Que nuestros predictores expliquen el resultado no significa que locausen, porque correlación sigue sin significar causalidad. Además, la R-cuadrado no indica si las predicciones son exactas.
Aquí tienes dos recursos útiles sobre temas más avanzados relacionados con la regresión lineal:
La R-cuadrado puede ser muy útil si se utiliza en las situaciones adecuadas. Es apropiado para:
Por otra parte, la R-cuadrado puede ser engañosa en los siguientes supuestos:
Ilustremos ahora el concepto de R-cuadrado en R y Python utilizando el conjunto de datos Kaggle de la Lonja. En ambos lenguajes de programación, construiremos dos modelos:
Empecemos por R.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredSalida:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredSalida:
[1] 0.8679Como vemos, la R-cuadrado aumenta ligeramente tras añadir un predictor irrelevante (Modelo 2). Sin embargo, eso no significa que el modelo haya mejorado. Al fin y al cabo, sólo hemos añadido ruido aleatorio.
Para leer más sobre el tema, consulta los siguientes tutoriales:
Y recuerda matricularte en nuestro curso designado:
Ahora, probemos en Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Salida:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Salida:
0.8679De nuevo, observamos un ligero aumento del valor R-cuadrado, pero esto no es más que la captura de ruido aleatorio.
Para seguir aprendiendo, inscríbete en nuestros cursos:
Ahora compararemos brevemente la R-cuadrado con dos métricas relacionadas: la R-cuadrado ajustada y la R-cuadrado predicha.
A diferencia de la R-cuadrado, la R-cuadrado ajustada tiene en cuenta el número de predictores. En concreto, penaliza al modelo por incluir predictores innecesarios:
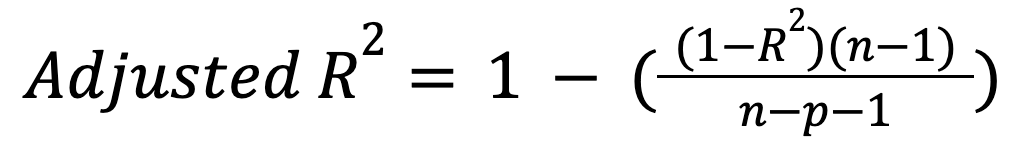
donde:
Esta métrica sólo aumenta si un nuevo predictor mejora realmente el modelo de forma significativa, y puede disminuir en el caso contrario. Lee nuestro tutorial para saber más sobre esta importante extensión: R-cuadrado ajustado: Una explicación clara con ejemplos.
Mientras que el R-cuadrado normal muestra el rendimiento del modelo con los datos de entrenamiento, el R-cuadrado predicho nos indica su rendimiento con datos nuevos, no vistos. Por tanto, esta métrica evalúa la capacidad de generalización del modelo.
El R-cuadrado previsto se calcula mediante validación cruzada o reteniendo parte de los datos de entrenamiento para realizar más pruebas. Puede ser significativamente inferior al R-cuadrado normal si el modelo está sobreajustado. Por tanto, un escenario en el que obtengamos un valor alto de R-cuadrado regular pero un valor bajo de R-cuadrado predicho puede indicar muy probablemente un sobreajuste del modelo.
Echemos un vistazo a algunos mitos populares sobre R-cuadrado, junto con el verdadero estado de las cosas:
En resumen, hemos aprendido qué es la R-cuadrado, cómo calcular esta métrica (tanto matemáticamente como en R y Python), cuándo utilizarla y cuándo evitarla, y cómo interpretar los resultados. Además, tocamos dos métricas relacionadas y algunos conceptos erróneos muy extendidos sobre R-cuadrado.
En pocas palabras, la R-cuadrado es una medida útil, intuitiva y directa del ajuste de un modelo de regresión. Es un buen punto de partida para la evaluación de modelos, pero debe utilizarse con prudencia, interpretarse junto con otras métricas y no confundirse con el cuadro completo. Esto es especialmente cierto en contextos de regresión múltiple y selección de modelos.
Aprende con DataCamp
Curso
Curso
Curso
Tutorial
Eladio Montero Porras
Tutorial
Kurtis Pykes
Tutorial
Avinash Navlani
Tutorial
Zoumana Keita
Tutorial
Vidhi Chugh
Tutorial
Arunn Thevapalan
