
Curso
Aprendizado Supervisionado em R: Regressão
4 h
46.4K
Em sua essência, o R-quadrado explica a proporção da variação na variável dependente que pode ser atribuída à variável (ou variáveis) independente(s). Podemos pensar nisso como uma medida de quão bem nosso modelo captura a história nos dados e quanto é deixado como ruído inexplicável. Sua simplicidade e interpretação direta fazem com que seja amplamente utilizado em diagnósticos de regressão linear, especialmente em regressão linear simples e múltipla.
Neste artigo, discutiremos o significado, o cálculo, a interpretação e as armadilhas comuns relacionadas ao R-quadrado, para que você possa usá-lo com confiança e cuidado. Além disso, daremos uma olhada em alguns exemplos de trechos de código para calcular o R-quadrado no R e no Python.
O R-quadrado, denotado como R², é uma medida estatística da qualidade do ajuste em modelos de regressão. Ele nos informa quanto da variação na variável dependente pode ser explicada pelo modelo.
O valor do R-quadrado está entre 0 e 1:
Embora o conceito seja simples, sua interpretação exige uma abordagem diferenciada, especialmente quando se passa da teoria para a prática.
Há várias maneiras matematicamente equivalentes de calcular o R-quadrado, cada uma oferecendo uma visão diferente do que realmente significa "ajuste", dependendo do contexto - regressão simples, regressão múltipla, álgebra matricial ou modelagem bayesiana. Vamos explorar as abordagens usadas com mais frequência.
Essa é a fórmula mais padrão e amplamente utilizada:
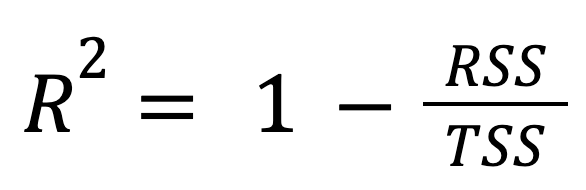
where:
Em outras palavras, o R-quadrado representa a fração da variação total que o modelo considera.
Essa abordagem destaca o desempenho muito melhor do modelo de regressão em comparação com a simples previsão da média da resposta.
O R-quadrado também pode ser expresso diretamente em termos de variação explicada:
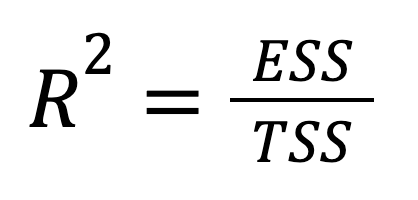
where:
Podemos ver que essa versão enfatiza o quanto da variação total do resultado é capturada pelas previsões do modelo. Em outras palavras, o foco aqui é deslocado do que não conseguimos explicar (RSS) para o que conseguimos (ESS), proporcionando um enquadramento mais otimista.
Para se aprofundar nos três componentes da soma de quadrados, leia Understanding Sum of Squares: Um guia para SST, SSR e SSE.
No contexto de uma tabela ANOVA, o R-quadrado surge naturalmente da decomposição da variabilidade total:

where:
Essa formulação mostra quanto da variação total é captada pelo modelo e quanto é deixado sem explicação.
Essa perspectiva é um pouco diferente porque vincula o R-quadrado ao teste de hipóteses. Isso ocorre porque a proporção de ESS para RSS é usada para calcular a estatística F , tornando o R-quadrado uma parte importante do teste de significância em relatórios no estilo ANOVA.
Os três últimos métodos eram todos fórmulas algebricamente equivalentes derivadas da decomposição da regressão. Agora, aqui está uma nova perspectiva:
Na regressão linear simples com apenas um preditor, o R-quadrado tem um atalho:
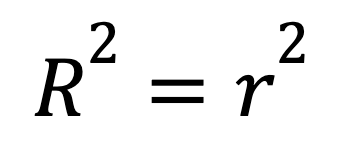
onde
Essa fórmula mostra como uma forte relação linear entre duas variáveis se traduz diretamente em um R-quadrado alto.
Para entender a teoria subjacente à regressão linear simples, acesse Simple Linear Regression: Tudo o que você precisa saber.
O R-quadrado pode ser calculado como uma medida normalizada do erro do modelo:
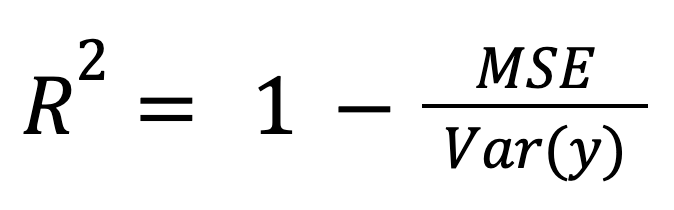
where:
Esse enquadramento é especialmente relevante na comparação de modelos em diferentes escalas ou unidades, pois normaliza o erro do modelo pela dispersão geral dos dados.
Supondo que os resíduos não estejam correlacionados com as previsões, o R-quadrado também pode ser interpretado como a fração da variação capturada pelo modelo:
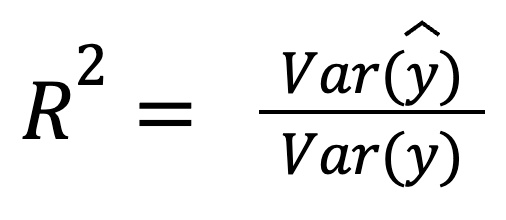
where:
Essa versão destaca o quanto as próprias previsões refletem a dispersão dos dados reais.
Como mencionamos anteriormente, o R-quadrado é fácil de calcular, mas um pouco mais complicado de interpretar de forma significativa.
É importante lembrar que o R-quadrado mede a correlação, mas não mede a causalidade. O fato de nossos preditores explicarem o resultado não significa que eles causam isso, pois a correlação ainda não significa causalidade. Além disso, o R-quadrado não indica se as previsões são precisas.
Aqui estão dois recursos úteis sobre tópicos mais avançados relacionados à regressão linear:
O R-quadrado pode ser muito útil se usado nas situações certas. É apropriado para você:
Por outro lado, o R-quadrado pode ser enganoso nos seguintes cenários:
Vamos agora ilustrar o conceito de R-quadrado em R e Python usando o conjunto de dados do Fish Market do Kaggle. Em ambas as linguagens de programação, criaremos dois modelos:
Vamos começar com o R.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredSaída:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredSaída:
[1] 0.8679Como podemos ver, o R-quadrado aumenta ligeiramente após a adição de um preditor irrelevante (Modelo 2). No entanto, isso não significa que o modelo ficou melhor. Afinal, apenas adicionamos ruído aleatório.
Para ler mais sobre o assunto, consulte os tutoriais a seguir:
E lembre-se de se inscrever em nosso curso designado:
Agora, vamos tentar em Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Saída:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Saída:
0.8679Novamente, observamos um ligeiro aumento no valor R-quadrado, mas isso é apenas a captura de ruído aleatório.
Para continuar aprendendo, inscreva-se em nossos cursos:
Agora, faremos uma breve comparação do R-quadrado com duas métricas relacionadas: R-quadrado ajustado e R-quadrado previsto.
Ao contrário do R-quadrado, o R-quadrado ajustado leva em conta o número de preditores. Em particular, ele penaliza o modelo por incluir preditores desnecessários:
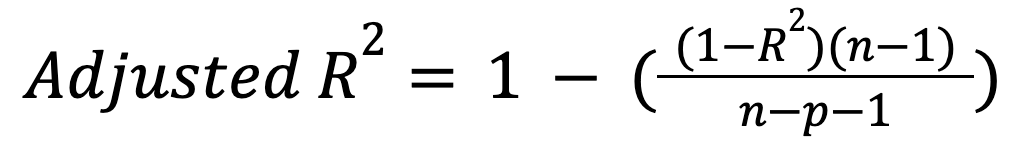
where:
Essa métrica só aumenta se um novo preditor realmente melhorar o modelo de forma significativa, e pode diminuir no caso oposto. Leia nosso tutorial para saber mais sobre essa importante extensão: R-quadrado ajustado: Uma explicação clara com exemplos.
Enquanto o R-quadrado normal mostra o desempenho do modelo nos dados de treinamento, o R-quadrado previsto nos informa o desempenho do modelo em dados novos e não vistos. Portanto, essa métrica avalia a capacidade de generalização do modelo.
O R-quadrado previsto é calculado usando validação cruzada ou retendo parte dos dados de treinamento para testes adicionais. Ele pode ser significativamente menor do que o R-quadrado regular se o modelo for ajustado em excesso. Portanto, um cenário em que obtemos um valor alto de R-quadrado regular, mas um valor baixo de R-quadrado previsto, provavelmente indica um ajuste excessivo do modelo.
Vamos dar uma olhada em alguns mitos populares sobre o R-quadrado, juntamente com a situação real:
Em resumo, aprendemos o que é o R-quadrado, como calcular essa métrica (matematicamente e em R e Python), quando usá-la e quando evitá-la e como interpretar os resultados. Além disso, abordamos duas métricas relacionadas e alguns equívocos generalizados sobre o R-quadrado.
Em resumo, o R-quadrado é uma medida útil, intuitiva e direta do ajuste de um modelo de regressão. É um ótimo ponto de partida para a avaliação do modelo, mas deve ser usado com sabedoria, interpretado juntamente com outras métricas e não deve ser confundido com o panorama geral. Isso é especialmente verdadeiro para contextos de regressão múltipla e seleção de modelos.
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Summer Worsley
15 min
Tutorial
Zoumana Keita
Tutorial
Eladio Montero Porras
Tutorial
Vidhi Chugh
Tutorial
Avinash Navlani
Tutorial
Allan Ouko


