
Kurs
Supervised Learning in R: Regression
4 sa
46.4K
Özünde R-kare, bağımlı değişkendeki varyansın bağımsız değişkene (ya da değişkenlere) atfedilebilen kısmını açıklar. Bunu, modelimizin verideki hikâyeyi ne kadar iyi yakaladığının ve ne kadarının açıklanamayan gürültü olarak kaldığının bir ölçüsü olarak düşünebiliriz. Basitliği ve doğrudan yorumlanabilirliği, özellikle basit ve çoklu doğrusal regresyonda, doğrusal regresyon tanılamalarında yaygın olarak kullanılmasını sağlar.
Bu yazıda, R-karenin anlamını, hesaplanmasını, yorumlanmasını ve yaygın tuzaklarını ele alacağız; böylece onu hem güvenle hem de dikkatle kullanabiliriz. Ayrıca, R ve Python'da R-karenin hesaplanmasına ilişkin bazı kod parçacığı örneklerine de göz atacağız.
R-kare, R² ile gösterilen ve regresyon modellerinde uyum iyiliğinin istatistiksel bir ölçüsüdür. Bağımlı değişkendeki değişimin ne kadarının model tarafından açıklandığını söyler.
R-karenin değeri 0 ile 1 arasındadır:
Kavram basit olsa da, özellikle teoriden uygulamaya geçerken yorumlanması incelikli bir yaklaşım gerektirir.
R-kareyi hesaplamanın, bağlama göre (“uyum”un ne anlama geldiğine dair) farklı içgörüler sunan birkaç matematiksel olarak eşdeğer yolu vardır: basit regresyon, çoklu regresyon, matris cebiri veya Bayesçi modelleme. En sık kullanılan yaklaşımları inceleyelim.
Bu en standart ve yaygın kullanılan formüldür:
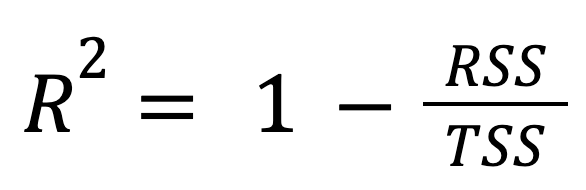
burada:
Başka bir deyişle, R-kare, modelin hesaba kattığı toplam değişimin payını temsil eder.
Bu yaklaşım, regresyon modelinin yanıtın ortalamasını tahmin etmeye kıyasla ne kadar daha iyi performans gösterdiğini vurgular.
R-kare, doğrudan açıklanan varyans cinsinden de ifade edilebilir:
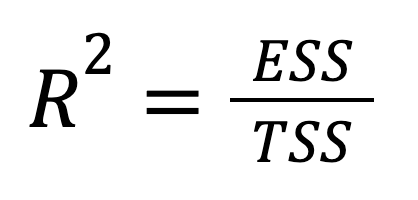
burada:
Bu versiyon, sonucun toplam değişiminin ne kadarının modelin tahminleri tarafından yakalandığını vurgular. Başka bir deyişle, odak, açıklayamadıklarımızdan (RSS) açıkladıklarımıza (ESS) kaydırılarak daha iyimser bir çerçeve sunulur.
Kareler toplamının üç bileşenine derinlemesine bir bakış için Kareler Toplamını Anlamak: SST, SSR ve SSE Rehberi yazısını okuyun.
ANOVA tablosu bağlamında, R-kare toplam değişkenliğin ayrıştırılmasından doğal olarak ortaya çıkar:

burada:
Bu formülasyon, toplam varyansın ne kadarının model tarafından yakalandığını ve ne kadarının açıklanmadığını gösterir.
Bu bakış açısı biraz özeldir çünkü R-kareyi hipotez testine bağlar. Bunun nedeni, ESS ile RSS oranının F-istatistiğini hesaplamak için kullanılmasıdır; bu da R-kareyi ANOVA tarzı raporlamada anlamlılık testinin önemli bir parçası yapar.
Önceki üç yöntem, regresyon ayrıştırmasından türetilen cebirsel olarak eşdeğer formüllerdi. Şimdi yeni bir perspektif:
Yalnızca tek bir yordayıcının olduğu basit doğrusal regresyonda, R-kare için bir kestirme vardır:
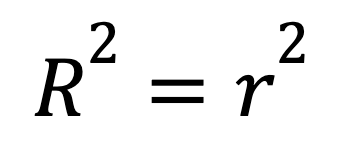
burada
Bu formül, iki değişken arasındaki güçlü bir doğrusal ilişkinin doğrudan yüksek bir R-kareye nasıl dönüştüğünü gösterir.
Basit doğrusal regresyonun temelindeki teoriyi anlamak için şu kaynağa göz atın: Basit Doğrusal Regresyon: Bilmeniz Gereken Her Şey.
R-kare, model hatasının normalize edilmiş bir ölçüsü olarak hesaplanabilir:
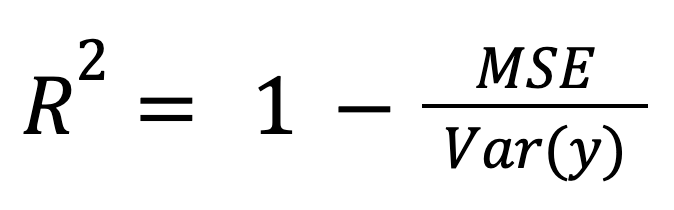
burada:
Bu çerçeve, model hatasını genel veri yayılımı ile normalize ettiği için farklı ölçekler veya birimler arasındaki modelleri karşılaştırırken özellikle uygundur.
Artıkların tahminlerle korelasyonsuz olduğu varsayıldığında, R-kare model tarafından yakalanan varyansın payı olarak da yorumlanabilir:
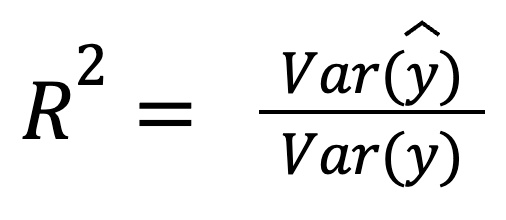
burada:
Bu versiyon, tahminlerin bizzat gerçek verinin yayılımını ne kadar iyi yansıttığını vurgular.
Daha önce belirttiğimiz gibi, R-kareyi hesaplamak kolaydır ancak anlamlı şekilde yorumlamak biraz daha zordur.
Unutulmamalıdır ki R-kare ilişkiyi ölçer, ancak nedenselliği ölçmez. Yordayıcılarımız sonuçu açıklıyor diye onu nedenledikleri anlamına gelmez; korelasyon hâlâ nedensellik demek değildir. Ayrıca R-kare, tahminlerin ne kadar doğru olduğunu göstermez.
Doğrusal regresyonla ilgili daha ileri konularda iki yararlı kaynak:
Doğru durumlarda kullanıldığında R-kare çok yardımcı olabilir. Şu durumlar için uygundur:
Öte yandan, aşağıdaki senaryolarda R-kare yanıltıcı olabilir:
Şimdi R ve Python'da, Kaggle'daki Fish Market veri kümesini kullanarak R-kare kavramını örnekleyelim. Her iki programlama dilinde de iki model kuracağız:
R ile başlayalım.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredÇıktı:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredÇıktı:
[1] 0.8679Görüldüğü gibi, ilgisiz bir yordayıcı eklendikten sonra (Model 2) R-kare biraz artar. Ancak bu, modelin daha iyi olduğu anlamına gelmez. Sonuçta yalnızca rastgele gürültü ekledik.
Konu hakkında daha fazla okumak için şu öğreticilere bakın:
Ve belirlenmiş kursumuza kaydolmayı unutmayın:
Şimdi de Python'da deneyelim.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Çıktı:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Çıktı:
0.8679Yine, R-kare değerinde hafif bir artış gözlemleriz; ancak bu yalnızca rastgele gürültünün yakalanmasıdır.
Öğrenmeye devam etmek için şu kurslara kaydolun:
Şimdi R-kareyi iki ilgili ölçütle kısaca karşılaştıralım: düzeltilmiş R-kare ve tahmin edilen R-kare.
R-kareden farklı olarak, düzeltilmiş R-kare yordayıcı sayısını dikkate alır. Özellikle, gereksiz yordayıcıların modele dahil edilmesini cezalandırır:
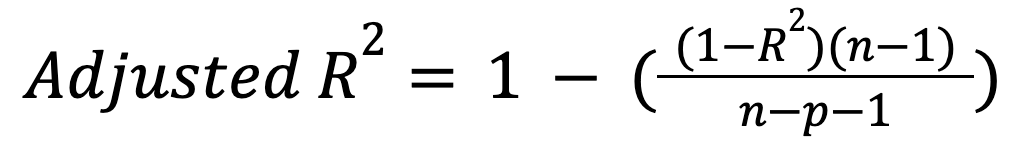
burada:
Bu ölçüt, yeni bir yordayıcı gerçekten anlamlı bir iyileşme sağlıyorsa artar; aksi durumda azalabilir. Bu önemli genişletme hakkında daha fazla bilgi edinmek için öğreticimizi okuyun: Düzeltilmiş R-Kare: Örneklerle Açık Bir Açıklama.
Normal R-kare, modelin eğitim verisi üzerindeki başarısını gösterirken, tahmin edilen R-kare modelin yeni, görülmemiş veride ne kadar iyi performans gösterdiğini anlatır. Dolayısıyla bu ölçüt, modelin genelleme yeteneğini değerlendirir.
Tahmin edilen R-kare, çapraz doğrulama kullanılarak ya da eğitim verisinin bir kısmı ayrılıp test edilerek hesaplanır. Model aşırı uyum göstermişse, normal R-kareye kıyasla belirgin şekilde daha düşük olabilir. Bu nedenle, normal R-kare yüksekken tahmin edilen R-karenin düşük çıkması, büyük olasılıkla modelin aşırı uyumuna işaret eder.
R-kare ile ilgili bazı popüler mitlere ve gerçek duruma bakalım:
Özetle, R-karenin ne olduğunu; bu ölçütün nasıl hesaplandığını (hem matematiksel olarak hem de R ve Python'da); ne zaman kullanılacağını ve ne zaman kaçınılacağını; sonuçların nasıl yorumlanacağını öğrendik. Ayrıca, iki ilgili ölçüte ve R-kare hakkındaki bazı yaygın yanlış kanılara değindik.
Kısacası, R-kare bir regresyon modelinin uyumunu ölçmek için yararlı, sezgisel ve doğrudan bir ölçüdür. Model değerlendirmesi için harika bir başlangıç noktasıdır; ancak akıllıca kullanılmalı, diğer ölçütlerle birlikte yorumlanmalı ve tüm resimle karıştırılmamalıdır. Bu, özellikle çoklu regresyon ve model seçimi bağlamlarında geçerlidir.
DataCamp ile öğrenin
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
