
Cursus
Supervised Learning in R: Regressie
4 Hr
46.4K
In de kern geeft R-kwadraat aan welk deel van de variantie in de afhankelijke variabele kan worden toegeschreven aan de onafhankelijke variabele(n). Je kunt het zien als een maat voor hoe goed ons model het verhaal in de data weet te vangen, en hoeveel er overblijft als onverklaard lawaai. Door zijn eenvoud en directe interpretatie is het wijdverbreid in de diagnostiek van lineaire regressie, vooral bij enkelvoudige en meervoudige lineaire regressie.
In dit artikel bespreken we de betekenis, berekening, interpretatie en veelvoorkomende valkuilen rond R-kwadraat, zodat we het zowel met vertrouwen als met zorg kunnen gebruiken. Daarnaast bekijken we enkele voorbeeldsnippets voor het berekenen van R-kwadraat in R en Python.
R-kwadraat, genoteerd als R², is een statistische maat voor de goodness of fit in regressiemodellen. Het vertelt ons hoeveel van de variatie in de afhankelijke variabele door het model kan worden verklaard.
De waarde van R-kwadraat ligt tussen 0 en 1:
Hoewel het concept eenvoudig is, vergt de interpretatie nuance, zeker wanneer je van theorie naar praktijk gaat.
Er zijn meerdere wiskundig equivalente manieren om R-kwadraat te berekenen, die elk een ander inzicht geven in wat “fit” nu precies betekent, afhankelijk van de context—enkelvoudige regressie, meervoudige regressie, matrixalgebra of Bayesiaanse modellering. Laten we de meest gebruikte benaderingen verkennen.
Dit is de meest standaard en veelgebruikte formule:
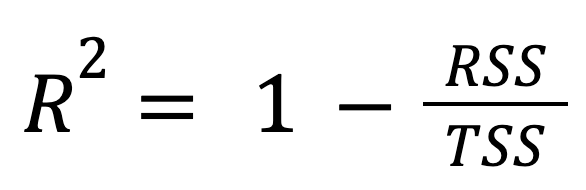
waarbij:
Met andere woorden, R-kwadraat is het deel van de totale variatie dat door het model wordt verklaard.
Deze benadering benadrukt hoeveel beter het regressiemodel presteert dan simpelweg het gemiddelde van de respons voorspellen.
R-kwadraat kan ook direct worden uitgedrukt in termen van verklaarde variantie:
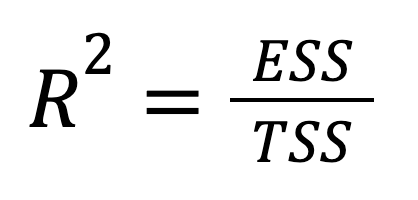
waarbij:
We zien dat deze versie benadrukt hoeveel van de totale variatie in de uitkomst wordt opgevangen door de voorspellingen van het model. Met andere woorden, de focus verschuift hier van wat we niet hebben verklaard (RSS) naar wat we wel hebben verklaard (ESS), wat een optimistischere framing geeft.
Voor een deepdive in de drie componenten van de kwadratensommen, lees Understanding Sum of Squares: A Guide to SST, SSR, and SSE.
In de context van een ANOVA-tabel komt R-kwadraat vanzelf voort uit de ontbinding van de totale variabiliteit:

waarbij:
Deze formulering laat zien hoeveel van de totale variantie door het model wordt opgepikt en hoeveel onverklaard blijft.
Dit perspectief is wat unieker omdat het R-kwadraat koppelt aan hypothesetoetsing. De verhouding ESS tot RSS wordt namelijk gebruikt om de F-statistic te berekenen, waardoor R-kwadraat een belangrijk onderdeel is van significantietoetsing in ANOVA-rapportages.
De vorige drie methoden waren allemaal algebraïsch equivalente formules afgeleid uit regressie-ontbinding. Hier is nu een nieuw perspectief:
Bij enkelvoudige lineaire regressie met slechts één voorspeller heeft R-kwadraat een snelkoppeling:
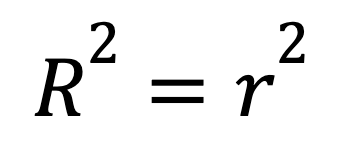
waar
Deze formule laat zien hoe een sterke lineaire relatie tussen twee variabelen zich direct vertaalt in een hoge R-kwadraat.
Om de onderliggende theorie achter enkelvoudige lineaire regressie te begrijpen, bekijk Simple Linear Regression: Everything You Need to Know.
R-kwadraat kan worden berekend als een genormaliseerde maat voor modelerror:
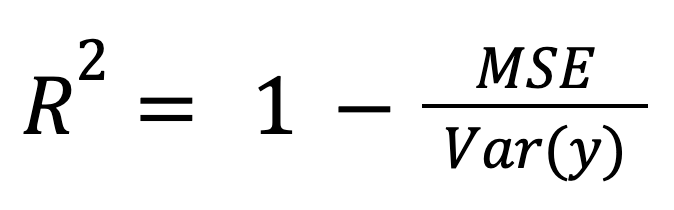
waarbij:
Deze benadering is vooral relevant bij het vergelijken van modellen over verschillende schalen of eenheden, omdat het de modelerror normaliseert naar de totale spreiding in de data.
Uitgaande van residuen die niet gecorreleerd zijn met de voorspellingen, kan R-kwadraat ook worden geïnterpreteerd als het deel van de variantie dat door het model wordt opgevangen:
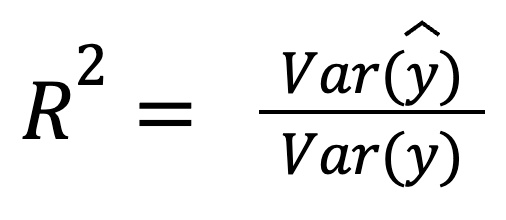
waarbij:
Deze versie benadrukt hoe goed de voorspellingen zelf de spreiding van de werkelijke data weerspiegelen.
Zoals eerder genoemd, is R-kwadraat makkelijk te berekenen maar wat lastiger om zinvol te interpreteren.
Het is belangrijk te onthouden dat R-kwadraat correlatie meet, maar geen causaliteit. Dat onze voorspellers de uitkomst verklaren, betekent nog niet dat ze die veroorzaken, want correlatie is nog steeds geen causaliteit. Bovendien zegt R-kwadraat niets over of voorspellingen accuraat zijn.
Hier zijn twee nuttige resources over meer geavanceerde onderwerpen rond lineaire regressie:
R-kwadraat kan erg behulpzaam zijn als je het in de juiste situaties gebruikt. Het is geschikt voor:
Aan de andere kant kan R-kwadraat misleidend zijn in de volgende scenario's:
Laten we het concept van R-kwadraat nu illustreren in R en Python met de Fish Market Kaggle-dataset. In beide programmeertalen bouwen we twee modellen:
Laten we beginnen met R.
# Load data
fish <- read.csv("Fish.csv")
# Model 1
model1 <- lm(Weight ~ Length1 + Length2 + Height + Width, data=fish)
summary(model1)$r.squaredOutput:
[1] 0.8673# Model 2 with an irrelevant predictor
fish$random_noise <- rnorm(nrow(fish))
model2 <- lm(Weight ~ Length1 + Length2 + Height + Width + random_noise, data=fish)
summary(model2)$r.squaredOutput:
[1] 0.8679Zoals we zien, stijgt R-kwadraat licht na het toevoegen van een irrelevante voorspeller (Model 2). Dat betekent echter niet dat het model beter is geworden. We hebben immers alleen willekeurige ruis toegevoegd.
Voor verdere lectuur over dit onderwerp, zie de volgende tutorials:
En vergeet niet je in te schrijven voor onze aangewezen cursus:
Nu proberen we het in Python.
import pandas as pd
import statsmodels.api as sm
import numpy as np
# Load data
fish = pd.read_csv('Fish.csv')
X1 = fish[['Length1', 'Length2', 'Height', 'Width']]
y = fish['Weight']
# Model 1
X1 = sm.add_constant(X1)
model1 = sm.OLS(y, X1).fit()
print(model1.rsquared)Output:
0.8673# Model 2 with an irrelevant predictor
fish['random_noise'] = np.random.randn(len(fish))
X2 = fish[['Length1', 'Length2', 'Height', 'Width', 'random_noise']]
X2 = sm.add_constant(X2)
model2 = sm.OLS(y, X2).fit()
print(model2.rsquared)Output:
0.8679Opnieuw zien we een kleine stijging in de R-kwadraatwaarde, maar dit vangt slechts willekeurige ruis.
Blijf leren en schrijf je in voor onze cursussen:
Nu vergelijken we R-kwadraat kort met twee gerelateerde metrics: adjusted R-kwadraat en predicted R-kwadraat.
In tegenstelling tot R-kwadraat houdt adjusted R-kwadraat rekening met het aantal voorspellers. Het bestraft het model met name voor het opnemen van onnodige voorspellers:
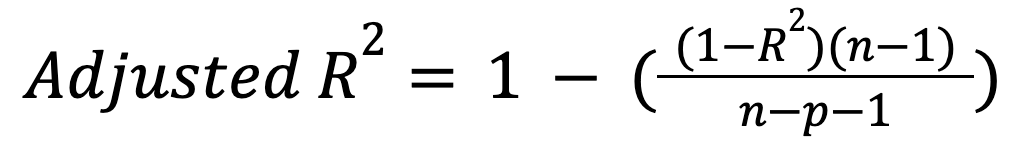
waarbij:
Deze metric stijgt alleen als een nieuwe voorspeller het model daadwerkelijk zinvol verbetert, en kan dalen in het omgekeerde geval. Lees onze tutorial om meer te leren over deze belangrijke uitbreiding: Adjusted R-Squared: A Clear Explanation with Examples.
Waar gewone R-kwadraat laat zien hoe goed het model presteert op de trainingsdata, vertelt predicted R-kwadraat hoe goed het presteert op nieuwe, ongeziene data. Deze metric beoordeelt dus het generalisatievermogen van het model.
Predicted R-kwadraat wordt berekend met cross-validatie of door een deel van de trainingsdata apart te houden voor latere tests. Het kan significant lager zijn dan gewone R-kwadraat als het model overfit is. Een scenario waarin we een hoge waarde voor gewone R-kwadraat krijgen maar een lage waarde voor predicted R-kwadraat, kan dus zeer waarschijnlijk wijzen op overfitting.
Laten we enkele populaire mythes over R-kwadraat bekijken, samen met hoe het echt zit:
Kort samengevat hebben we geleerd wat R-kwadraat is, hoe je deze metric berekent (zowel wiskundig als in R en Python), wanneer je hem gebruikt en wanneer je hem beter vermijdt, en hoe je de resultaten interpreteert. Daarnaast bespraken we twee gerelateerde metrics en enkele wijdverspreide misvattingen over R-kwadraat.
Kortom, R-kwadraat is een nuttige, intuïtieve en rechtlijnige maat voor de fit van een regressiemodel. Het is een prima startpunt voor modelevaluatie, maar het moet verstandig worden gebruikt, samen met andere metrics worden geïnterpreteerd, en niet worden aangezien voor het hele plaatje. Dit geldt zeker bij meervoudige regressie en modelselectie.
Leer met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
