
Kursus
Regresi Tingkat Menengah di R
4 Hr
35.3K
Dikembangkan oleh ahli statistik Cuthbert Daniel, VIF adalah alat diagnostik yang banyak digunakan dalam analisis regresi untuk mendeteksi multikolinearitas, yang diketahui memengaruhi stabilitas dan keterjelasan interpretasi koefisien regresi. Secara lebih teknis, VIF bekerja dengan mengkuantifikasi seberapa besar varians suatu koefisien regresi membesar akibat adanya korelasi antar prediktor.
Semua ini penting karena korelasi tersebut menyulitkan untuk mengisolasi efek unik setiap prediktor pada variabel target, sehingga menghasilkan estimasi model yang kurang andal. Perlu juga saya tekankan bahwa, untuk benar-benar menceritakan kisah yang tepat, VIF selalu dihitung untuk setiap prediktor dalam sebuah model.
VIF untuk suatu prediktor X dihitung sebagai:
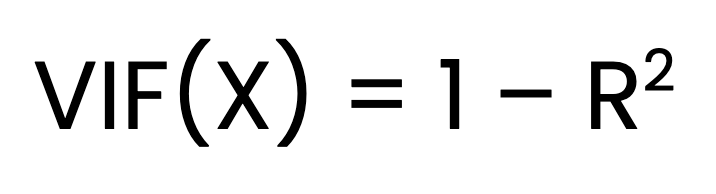
Dengan:
X diregresikan terhadap semua prediktor lainnya.Mencari VIF adalah proses tiga langkah. Langkah pertama adalah memasang model regresi linear terpisah untuk setiap prediktor terhadap semua prediktor lainnya. Langkah kedua adalah memperoleh nilai R2 untuk tiap model. Langkah terakhir adalah menghitung VIF menggunakan rumus di atas.
Berikut cara menafsirkan nilai VIF untuk memahami tingkat multikolinearitas:
Misalnya, jika VIF suatu prediktor adalah 10, itu menunjukkan bahwa varians koefisien prediktor tersebut menjadi 10 kali lebih besar dibandingkan jika tidak ada multikolinearitas.
Multikolinearitas menyebabkan galat baku meningkat, sehingga makin sulit menilai signifikansi masing-masing prediktor. Ini terjadi karena variabel yang kolinear membawa informasi serupa, sehingga sulit memisahkan efek spesifik masing-masing variabel terhadap variabel keluaran.
Walaupun multikolinearitas tidak selalu merusak kemampuan prediksi model, hal itu memang mengurangi keandalan dan kejelasan koefisien. Ini sangat bermasalah ketika kita ingin memahami dampak individual tiap prediktor.
Variance inflation factor (VIF) berfungsi sebagai metrik diagnostik yang tepat untuk mengidentifikasi multikolinearitas. Berbeda dengan pengamatan umum tentang korelasi, VIF mengisolasi pengaruh gabungan semua prediktor pada tiap variabel, menyoroti interaksi yang mungkin tidak terlihat dari korelasi berpasangan.
Agar lebih aplikatif, mari kita melalui contoh baik di Python maupun R menggunakan sebuah dataset unik. Kita akan menghitung VIF menggunakan paket otomatis dan juga dengan rumus VIF untuk membangun intuisi. Demi praktik yang baik, saya sengaja membuat dataset di mana kita akan menemukan nilai VIF tinggi untuk salah satu variabel meski tidak ada korelasi berpasangan yang sangat tinggi antara dua variabel mana pun — jadi menurut saya ini contoh yang menarik. Mari mulai dengan ikhtisar dataset yang akan kita gunakan.
Gambaran Dataset:
Dataset fiktif ini merepresentasikan hasil survei dari studi yang dilakukan di 1.000 toko milik sebuah raksasa ritel. Pelanggan di setiap toko diminta menilai berbagai aspek pengalaman berbelanja mereka pada skala dari -5 hingga +5, di mana -5 menunjukkan pengalaman yang sangat negatif, dan +5 menunjukkan pengalaman yang sangat positif. Rata-rata penilaian pelanggan di setiap toko diambil pada empat parameter kunci:
Ambience: Persepsi pelanggan terhadap lingkungan toko, seperti kebersihan, tata letak, pencahayaan, dan suasana keseluruhan.
Customer_service: Penilaian terhadap layanan yang diberikan staf toko, termasuk sikap membantu, keramahan, dan daya tanggap terhadap kebutuhan pelanggan.
Offers: Penilaian terhadap penawaran promosi, diskon, dan deal yang tersedia di toko.
Product_range: Evaluasi terhadap variasi dan kualitas produk yang tersedia di toko.
Variabel target, Performance, mengukur kinerja keseluruhan tiap toko. Namun, variabel ini tidak relevan dari perspektif VIF. Anda dapat mengunduh dataset tersebut di sini.
Kita akan mulai dengan menghitung nilai VIF menggunakan paket Python. Langkah pertama adalah memuat dataset dan pustaka yang diperlukan.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
datacamp_retail_data = pd.read_csv(' vif_data.csv')
datacamp_retail_data.head()Kode di atas akan memuat data dan menampilkan lima catatan pertama.
Langkah berikutnya, kita dapat menjalankan matriks korelasi untuk memeriksa korelasi berpasangan.
Kode di bawah ini memilih empat kolom dan menyimpannya dalam DataFrame baru bernama correl_data. Lalu menghitung matriks korelasi berpasangan menggunakan fungsi .corr(). Hasilnya disimpan dalam objek corr_matrix, yang merupakan tabel yang menunjukkan koefisien korelasi antara setiap pasangan kolom yang dipilih.
Matriks tersebut kemudian divisualisasikan menggunakan fungsi heatmap() dari Seaborn, menampilkan setiap koefisien korelasi sebagai sel berwarna, di mana biru merepresentasikan korelasi negatif dan merah merepresentasikan korelasi positif, berdasarkan peta warna coolwarm.
correl_data = datacamp_retail_data[['Ambience', 'Customer_service', 'Offers', 'Product_range']]
# Compute the pairwise correlation matrix
corr_matrix = correl_data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pairwise Correlation Matrix')
plt.show()Keluaran:
Korelasi antar variabel. Gambar oleh Penulis
Plot memberikan ringkasan visual hubungan antar variabel dalam correl_data. Nilai korelasi berkisar dari -1 hingga 1, di mana nilai mendekati 1 menunjukkan korelasi positif kuat, nilai mendekati -1 menunjukkan korelasi negatif kuat, dan nilai sekitar 0 menunjukkan tidak ada korelasi. Terlihat jelas tidak ada korelasi berpasangan yang kuat di antara variabel-variabel tersebut, dengan tidak ada nilai korelasi yang bahkan melebihi 0,6.
Langkah selanjutnya adalah menghitung nilai VIF untuk variabel prediktor. Kode di bawah ini menghitung nilai untuk setiap variabel prediktor dalam dataset untuk memeriksa multikolinearitas.
Pertama, didefinisikan X dengan menghapus kolom target Performance dan menambahkan intersep. Lalu dibuat DataFrame, datacamp_vif_data, untuk menyimpan nama prediktor dan nilai VIF-nya. Menggunakan loop, kemudian dihitung VIF untuk setiap prediktor dengan fungsi variance_inflation_factor(), di mana VIF yang lebih tinggi menunjukkan adanya multikolinearitas.
# Define the predictor variables
X = datacamp_retail_data.drop(columns=['Performance'])
# Add a constant to the model (intercept)
X = add_constant(X)
# Calculate VIF for each feature
datacamp_vif_data = pd.DataFrame()
datacamp_vif_data['Feature'] = X.columns
datacamp_vif_data['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(datacamp_vif_data)Keluaran:
Keluaran yang menampilkan nilai VIF. Gambar oleh Penulis
Keluaran ini menunjukkan nilai VIF untuk setiap variabel prediktor, yang mengindikasikan tingkat multikolinearitas dalam dataset. Baris const merepresentasikan suku intersep, dengan VIF mendekati 1, artinya tidak ada multikolinearitas. Di antara variabel prediktor, Product_range memiliki VIF tertinggi (5,94), yang menunjukkan perlu adanya tindakan korektif. Semua prediktor lainnya memiliki nilai VIF di bawah 3, menandakan multikolinearitas rendah.
Pendekatan lain adalah menghitung nilai secara terpisah dengan meregresikan setiap variabel independen terhadap variabel prediktor lainnya.
Cara kerjanya, untuk setiap fitur dalam retail_data, fitur tersebut ditetapkan sebagai variabel dependen (y) dan fitur yang tersisa sebagai variabel independen (X). Model regresi linear kemudian dipasang untuk memprediksi y menggunakan X, dan nilai R-squared model digunakan untuk menghitung VIF menggunakan rumus yang kita bahas di bagian awal.
Selanjutnya, setiap fitur dan nilai VIF terkait disimpan dalam dictionary (vif_manual), yang kemudian diubah menjadi DataFrame (vif_manual_df) untuk ditampilkan.
datacamp_retail_data = retail_data.drop(columns=['Performance'])
# Manual VIF Calculation
vif_manual = {}
for feature in retail_data.columns:
# Define the target variable (current feature) and predictors (all other features)
y = datacamp_retail_data[feature]
X = datacamp_retail_data.drop(columns=[feature])
# Fit the linear regression model
model = LinearRegression().fit(X, y)
# Calculate R-squared
r_squared = model.score(X, y)
# Calculate VIF
vif = 1 / (1 - r_squared)
vif_manual[feature] = vif
# Convert the dictionary to a DataFrame for better display
vif_manual_df = pd.DataFrame(list(vif_manual.items()), columns=['Feature', 'VIF'])
print(vif_manual_df)Keluaran:

Keluaran yang menampilkan nilai VIF. Gambar oleh Penulis
Keluaran menunjukkan setiap fitur beserta nilai VIF-nya, sehingga membantu mengidentifikasi potensi masalah multikolinearitas. Anda dapat melihat hasilnya jelas sama seperti yang kita peroleh di atas; demikian pula interpretasinya, yakni variabel Product_range menunjukkan multikolinearitas.
Pada bagian ini, kita akan mengulangi latihan variance inflation factor di bagian Python di atas, khususnya bagi pengembang yang bekerja dengan bahasa pemrograman R. Kita mulai dengan memuat dataset dan pustaka yang diperlukan.
library(tidyverse)
library(car)
library(corrplot)
data <- read.csv('vif_data.csv')
str(data)Keluaran:

Langkah berikutnya adalah menghitung matriks korelasi berpasangan, dan memvisualisasikannya dengan heatmap. Fungsi cor() dan corrplot membantu kita menyelesaikan tugas ini.
# Remove the target column
predictors_data <- data[, !(names(data) %in% "Performance")]
# Calculate the correlation matrix
correlation_matrix <- cor(predictors_data)
# Plot the correlation heatmap
# Load necessary libraries
library(ggplot2)
library(reshape2)
melted_corr_matrix <- melt(correlation_matrix)
# Plot the heatmap with ggplot2
ggplot(data = melted_corr_matrix, aes(x = Var1, y = Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Correlation") +
theme_minimal() + # Minimal theme for a clean look
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(x = "", y = "") + # Remove axis labels
geom_text(aes(Var1, Var2, label = round(value, 2)), color = "black", size = 4) +
theme(axis.text=element_text(size=15))Keluaran:
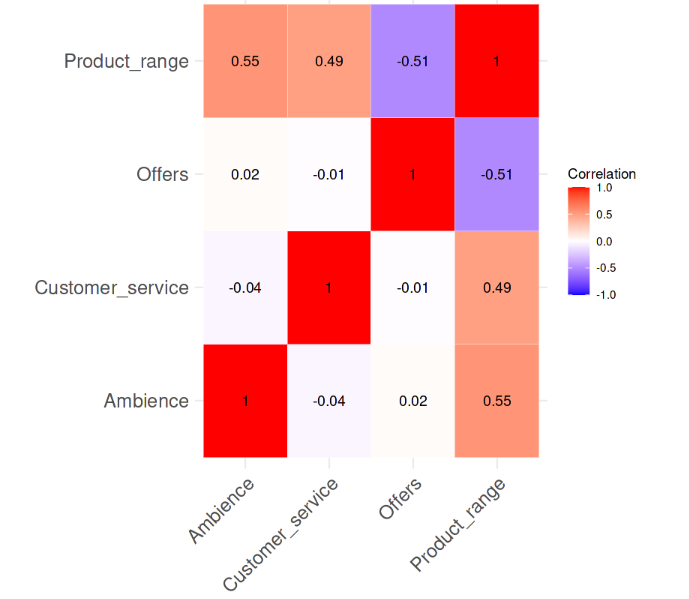
Korelasi antar variabel. Gambar oleh Penulis
Terlihat dari heatmap korelasi bahwa tidak ada korelasi berpasangan yang kuat di antara variabel-variabel tersebut, dengan tidak ada nilai korelasi yang bahkan melebihi 0,6. Kini, kita akan menghitung nilai VIF dan melihat apakah ada hal yang mengkhawatirkan. Baris kode berikut melakukan tugas tersebut.
# Fit a regression model
model <- lm(Performance ~ Ambience + Customer_service + Offers + Product_range, data = data)
# Calculate VIF
vif(model)Keluaran:

Dari keluaran, kita dapat melihat bahwa di antara variabel prediktor, hanya variabel Product_range yang memiliki nilai VIF lebih besar dari 5, yang menunjukkan multikolinearitas tinggi yang memerlukan tindakan korektif.
Pendekatan lain untuk perhitungan VIF adalah menghitung nilai VIF untuk setiap variabel secara terpisah dengan meregresikan setiap variabel independen terhadap variabel prediktor lainnya.
Hal ini dilakukan pada kode di bawah, yang menggunakan fungsi sapply() pada setiap prediktor, di mana tiap prediktor ditetapkan sebagai variabel dependen dalam model regresi linear dengan prediktor lainnya sebagai variabel independen.
Nilai R-squared dari setiap model kemudian digunakan untuk menghitung nilai VIF dengan rumusnya. Terakhir, hasilnya, vif_values, menampilkan VIF untuk setiap prediktor, membantu mengidentifikasi masalah multikolinearitas.
# VIF calculation for each predictor manually
predictors <- c("Ambience", "Customer_service", "Offers", "Product_range")
vif_values <- sapply(predictors, function(pred) {
formula <- as.formula(paste(pred, "~ ."))
model <- lm(formula, data = data[, predictors])
1 / (1 - summary(model)$r.squared)
})
print(vif_values)Keluaran:

Kita memperoleh hasil yang sama dan terlihat jelas bahwa variabel Product_range dengan nilai VIF tinggi di atas 5 memerlukan intervensi.
Sebagai rekap, berikut metode populer untuk mendeteksi multikolinearitas:
Di antara semua metode ini, VIF sangat berguna karena dapat mendeteksi multikolinearitas bahkan ketika korelasi berpasangan rendah, seperti yang kita lihat pada contoh kita sendiri. Ini membuat VIF menjadi alat yang lebih komprehensif.
Jika nilai VIF menunjukkan multikolinearitas tinggi, dan Anda tidak serta-merta ingin menghapus variabelnya, ada beberapa strategi lanjutan untuk mengurangi multikolinearitas:
Mengetahui cara menggunakan VIF penting untuk mengidentifikasi dan memperbaiki multikolinearitas, yang meningkatkan akurasi dan kejelasan model regresi. Secara rutin memeriksa nilai VIF dan menerapkan langkah korektif saat diperlukan membantu para profesional data dan analis membangun model yang dapat mereka percayai. Pendekatan ini memastikan bahwa efek masing-masing prediktor jelas, sehingga lebih mudah menarik kesimpulan yang andal dari model dan membuat keputusan yang lebih baik berdasarkan hasilnya. Ikuti Machine Learning Scientist in Python career track kami untuk benar-benar memahami cara membangun model dan menggunakannya. Plus, penyelesaian program ini terlihat bagus di resume.
Belajar bersama DataCamp
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
