
Kurs
R'de Orta Düzey Regresyon
4 sa
35.4K
İstatistikçi Cuthbert Daniel tarafından geliştirilen VIF, regresyon analizinde çoklu doğrusal bağıntıyı tespit etmek için yaygın olarak kullanılan bir tanılama aracıdır; çoklu doğrusal bağıntının regresyon katsayılarının kararlılığını ve yorumlanabilirliğini etkilediği bilinir. Daha teknik olarak VIF, öngörücüler arasındaki korelasyonlar nedeniyle bir regresyon katsayısının varyansının ne kadar şiştiğini niceliksel olarak ifade eder.
Bütün bunlar önemlidir çünkü bu korelasyonlar, her öngörücünün hedef değişken üzerindeki özgün etkisini izole etmeyi zorlaştırır ve daha az güvenilir model tahminlerine yol açar. Ayrıca doğru resmi çizebilmek için şunu da belirtmeliyim: VIF her zaman modeldeki her öngörücü için ayrı ayrı hesaplanır.
Bir X öngörücüsü için VIF şu şekilde hesaplanır:
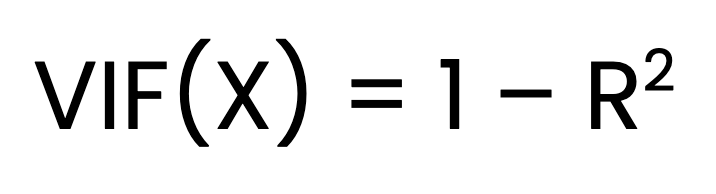
Burada:
X diğer tüm öngörücülere karşı regresyona tabi tutulduğunda elde edilen belirleme katsayısıdır.VIF bulma üç aşamalı bir işlemdir. İlk adım, her bir öngörücü için diğer tüm öngörücülere karşı ayrı bir doğrusal regresyon modeli kurmaktır. İkinci adım, her model için R2 değerini elde etmektir. Son adım ise yukarıdaki formülü kullanarak VIF’i hesaplamaktır.
Çoklu doğrusal bağıntı düzeyini anlamak için VIF değerleri şöyle yorumlanır:
Örneğin, bir öngörücünün VIF’i 10 ise, o öngörücünün katsayısının varyansının, hiç çoklu doğrusal bağıntı olmasaydı olacağının 10 katı olduğu anlamına gelir.
Çoklu doğrusal bağıntı, standart hataların artmasına neden olur; bu da tek tek öngörücülerin anlamlılığını değerlendirmeyi zorlaştırır. Bunun nedeni, ortak doğrusal olan değişkenlerin benzer bilgi taşıması ve sonuç değişkeni üzerindeki özgül bireysel etkilerini ayırmayı güçleştirmesidir.
Her ne kadar çoklu doğrusal bağıntı, modelin öngörü yapma yeteneğine mutlaka zarar vermese de katsayıların güvenilirliğini ve açıklığını azaltır. Bu durum, her bir öngörücünün bireysel etkisini anlamak istediğimizde özellikle sorunludur.
Varyans şişirme faktörü (VIF), çoklu doğrusal bağıntıyı belirlemek için kesin bir tanılama ölçütü olarak hizmet eder. Genel korelasyon gözlemlerinden farklı olarak VIF, her değişken üzerinde tüm öngörücülerin birleşik etkisini izole eder ve ikili korelasyonlardan anlaşılmayabilecek etkileşimleri vurgular.
Bunu uygulanabilir kılmak için, hem Python hem de R ile özgün bir veri kümesi üzerinde bir örnek üzerinden gidelim. VIF’i hem otomatik paketlerle hem de formülünü kullanarak hesaplayacağız ki sezgimizi güçlendirelim. İyi bir alıştırma olması için, iki değişken arasında çok yüksek ikili korelasyonlar olmamasına rağmen değişkenlerimizden biri için yüksek VIF değeri bulacağımız bir veri kümesi oluşturdum — bu nedenle etkileyici bir örnek olduğunu düşünüyorum. Kullanacağımız veri kümesine genel bir bakışla başlayalım.
Veri Kümesine Genel Bakış:
Bu kurgusal veri kümesi, bir perakende devinin 1.000 mağazasında yürütülen bir çalışmanın anket sonuçlarını temsil eder. Her mağazada, müşterilerden alışveriş deneyimlerinin çeşitli yönlerini -5 ile +5 arasında puanlamaları istenmiştir; -5 çok olumsuz, +5 çok olumlu deneyimi ifade eder. Her mağazada müşteri puanlarının ortalaması dört temel parametre üzerinden alınmıştır:
Ambience: Mağazanın temizlik, düzen, aydınlatma ve genel atmosfer gibi çevresine yönelik müşteri algısı.
Customer_service: Mağaza personelinin sunduğu hizmetin; yardımseverlik, güler yüz ve müşteri ihtiyaçlarına yanıt verme hızı gibi yönlerden değerlendirilmesi.
Offers: Mağazanın sunduğu promosyonlar, indirimler ve fırsatların değerlendirilmesi.
Product_range: Mağazada sunulan ürün çeşitliliği ve kalitesinin değerlendirilmesi.
Hedef değişken olan Performance, her mağazanın genel performansını ölçer. Ancak VIF açısından doğrudan ilgili değildir. Veri kümesini buradan indirebilirsiniz.
VIF değerlerini Python paketlerini kullanarak hesaplayarak başlayacağız. İlk adım veri kümesini ve gerekli kütüphaneleri yüklemektir.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
datacamp_retail_data = pd.read_csv(' vif_data.csv')
datacamp_retail_data.head()Yukarıdaki kod, verileri yükleyecek ve ilk beş kaydı görüntüleyecektir.
Bir sonraki adım olarak, ikili korelasyonları kontrol etmek için bir korelasyon matrisi çalıştırabiliriz.
Aşağıdaki kod dört sütunu seçer ve bunları correl_data adlı yeni bir DataFrame’e kaydeder. Ardından .corr() işlevini kullanarak ikili korelasyon matrisini hesaplar. Sonuç, seçilen sütunların her bir çifti arasındaki korelasyon katsayılarını gösteren bir tablo olan corr_matrix nesnesinde saklanır.
Matris daha sonra Seaborn’un heatmap() işleviyle görselleştirilir; her bir korelasyon katsayısı renk kodlu bir hücre olarak gösterilir. coolwarm renk haritasına göre mavi negatif, kırmızı pozitif korelasyonları temsil eder.
correl_data = datacamp_retail_data[['Ambience', 'Customer_service', 'Offers', 'Product_range']]
# Compute the pairwise correlation matrix
corr_matrix = correl_data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pairwise Correlation Matrix')
plt.show()Çıktı:
Değişkenler arasındaki korelasyon. Görsel: Yazar
Grafik, correl_data içindeki değişkenler arasındaki ilişkilerin görsel bir özetini sunar. Korelasyon değerleri -1 ile 1 arasında değişir; 1’e yakın değerler güçlü pozitif korelasyonu, -1’e yakın değerler güçlü negatif korelasyonu, 0 civarı değerler ise korelasyon olmadığını gösterir. Değerlerin hiçbiri 0,6’yı aşmadığından, değişkenler arasında güçlü ikili korelasyon olmadığı açıktır.
Sonraki adım, öngörücü değişkenler için VIF değerlerini hesaplamaktır. Aşağıdaki kod, veri kümesindeki her bir öngörücü değişken için çoklu doğrusal bağıntıyı kontrol etmek üzere değerleri hesaplar.
Önce, hedef sütun Performance çıkarılarak X tanımlanır ve bir sabit terim eklenir. Ardından öngörücü adlarını ve VIF değerlerini saklamak için datacamp_vif_data adlı bir DataFrame oluşturulur. Bir döngü ile her öngörücü için variance_inflation_factor() işlevi kullanılarak VIF hesaplanır; daha yüksek VIF’ler çoklu doğrusal bağıntının varlığına işaret eder.
# Define the predictor variables
X = datacamp_retail_data.drop(columns=['Performance'])
# Add a constant to the model (intercept)
X = add_constant(X)
# Calculate VIF for each feature
datacamp_vif_data = pd.DataFrame()
datacamp_vif_data['Feature'] = X.columns
datacamp_vif_data['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(datacamp_vif_data)Çıktı:
VIF değerlerini gösteren çıktı. Görsel: Yazar
Bu çıktı, veri kümesindeki her bir öngörücü değişken için VIF değerini göstererek çoklu doğrusal bağıntı düzeylerini belirtir. const satırı, VIF’i 1’e yakın olan sabit terimi temsil eder; bu, çoklu doğrusal bağıntı olmadığını ifade eder. Öngörücü değişkenler arasında Product_range en yüksek VIF’e (5,94) sahiptir ve bu da düzeltici önlemler gerektirdiğini düşündürür. Diğer tüm öngörücülerin VIF değerleri 3’ün altındadır ve düşük çoklu doğrusal bağıntıya işaret eder.
Diğer yaklaşım, her bir bağımsız değişkeni diğer öngörücü değişkenlere karşı regresyona tabi tutarak değerleri ayrı ayrı hesaplamaktır.
Çalışma şekli şudur: retail_data içindeki her özellik için, o özellik bağımlı değişken (y) olarak, kalan özellikler ise bağımsız değişkenler (X) olarak belirlenir. Ardından y’yi X ile tahmin etmek için bir doğrusal regresyon modeli kurulur ve modelin R-kare değeri, ilk bölümde ele aldığımız VIF formülünü kullanarak VIF’i hesaplamak için kullanılır.
Sonrasında, her özellik ve karşılık gelen VIF değerleri bir sözlükte (vif_manual) saklanır ve görüntüleme için bir DataFrame’e (vif_manual_df) dönüştürülür.
datacamp_retail_data = retail_data.drop(columns=['Performance'])
# Manual VIF Calculation
vif_manual = {}
for feature in retail_data.columns:
# Define the target variable (current feature) and predictors (all other features)
y = datacamp_retail_data[feature]
X = datacamp_retail_data.drop(columns=[feature])
# Fit the linear regression model
model = LinearRegression().fit(X, y)
# Calculate R-squared
r_squared = model.score(X, y)
# Calculate VIF
vif = 1 / (1 - r_squared)
vif_manual[feature] = vif
# Convert the dictionary to a DataFrame for better display
vif_manual_df = pd.DataFrame(list(vif_manual.items()), columns=['Feature', 'VIF'])
print(vif_manual_df)Çıktı:

VIF değerlerini gösteren çıktı. Görsel: Yazar
Çıktı, her özelliği VIF değeriyle birlikte göstererek potansiyel çoklu doğrusal bağıntı sorunlarını belirlemeye yardımcı olur. Sonucun yukarıda elde ettiğimizle aynı olduğu ve yorumunun da aynı şekilde Product_range değişkeninin çoklu doğrusal bağıntı sergilediği yönünde olduğu görülüyor.
Bu bölümde, özellikle R programlama diliyle çalışan geliştiriciler için, yukarıdaki Python bölümündeki varyans şişirme faktörü alıştırmasını tekrarlayacağız. Veri kümesini ve gerekli kütüphaneleri yükleyerek başlıyoruz.
library(tidyverse)
library(car)
library(corrplot)
data <- read.csv('vif_data.csv')
str(data)Çıktı:

Bir sonraki adım, ikili korelasyon matrisini hesaplamak ve ısı haritasıyla görselleştirmektir. cor() ve corrplot işlevleri bu görevi yerine getirmemizi sağlar.
# Remove the target column
predictors_data <- data[, !(names(data) %in% "Performance")]
# Calculate the correlation matrix
correlation_matrix <- cor(predictors_data)
# Plot the correlation heatmap
# Load necessary libraries
library(ggplot2)
library(reshape2)
melted_corr_matrix <- melt(correlation_matrix)
# Plot the heatmap with ggplot2
ggplot(data = melted_corr_matrix, aes(x = Var1, y = Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Correlation") +
theme_minimal() + # Minimal theme for a clean look
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(x = "", y = "") + # Remove axis labels
geom_text(aes(Var1, Var2, label = round(value, 2)), color = "black", size = 4) +
theme(axis.text=element_text(size=15))Çıktı:
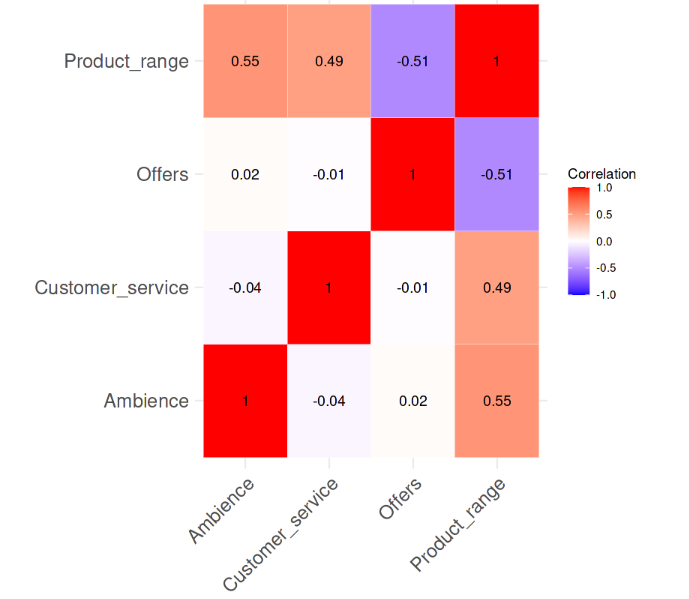
Değişkenler arasındaki korelasyon. Görsel: Yazar
Korelasyon ısı haritasından, değişkenler arasında güçlü bir ikili korelasyon olmadığı; korelasyon değerlerinin hiçbirinin 0,6’yı dahi aşmadığı açıktır. Şimdi VIF değerlerini hesaplayacağız ve kayda değer bir durum olup olmadığına bakacağız. Aşağıdaki kod satırı bu görevi yerine getirir.
# Fit a regression model
model <- lm(Performance ~ Ambience + Customer_service + Offers + Product_range, data = data)
# Calculate VIF
vif(model)Çıktı:

Çıktıdan görüldüğü üzere öngörücü değişkenler arasında yalnızca Product_range değişkeninin VIF değeri 5’in üzerindedir; bu da düzeltici önlemler gerektiren yüksek çoklu doğrusal bağıntıya işaret eder.
VIF hesaplamanın diğer bir yolu, her değişken için değerleri ayrı ayrı hesaplayarak her bağımsız değişkeni diğer öngörücü değişkenlere karşı regresyona tabi tutmaktır.
Aşağıdaki kodda bu yapılmaktadır; sapply() işlevi her öngörücü üzerinde çalıştırılır; her seferinde ilgili öngörücü, diğer öngörücülerin bağımsız değişken olduğu bir doğrusal regresyon modelinde bağımlı değişken olarak ayarlanır.
Her modelden elde edilen R-kare değeri, formülüyle VIF değerlerini hesaplamak için kullanılır. Sonuçta vif_values, her öngörücü için VIF’i görüntüler ve çoklu doğrusal bağıntı sorunlarını belirlemeye yardımcı olur.
# VIF calculation for each predictor manually
predictors <- c("Ambience", "Customer_service", "Offers", "Product_range")
vif_values <- sapply(predictors, function(pred) {
formula <- as.formula(paste(pred, "~ ."))
model <- lm(formula, data = data[, predictors])
1 / (1 - summary(model)$r.squared)
})
print(vif_values)Aynı sonucu elde ediyoruz ve Product_range değişkeninin 5’in üzerinde yüksek bir VIF değeriyle müdahale gerektirdiği açıktır.
Özet olarak, çoklu doğrusal bağıntıyı tespit etmek için yaygın yöntemler şunlardır:
Tüm bu yöntemler arasında VIF özellikle kullanışlıdır; çünkü kendi örneğimizde gördüğümüz gibi, ikili korelasyonlar düşük olduğunda bile çoklu doğrusal bağıntıyı tespit edebilir. Bu da VIF’i daha kapsamlı bir araç yapar.
VIF değerleri yüksek çoklu doğrusal bağıntıya işaret ediyorsa ve değişkeni doğrudan kaldırmak istemiyorsanız, çoklu doğrusal bağıntıyı azaltmak için daha ileri düzey bazı stratejiler vardır:
VIF’i kullanmayı bilmek, çoklu doğrusal bağıntıyı tespit edip düzeltmenin anahtarıdır; bu da regresyon modellerinin doğruluğunu ve açıklığını artırır. VIF değerlerini düzenli olarak kontrol etmek ve gerektiğinde düzeltici önlemler almak, veri profesyonelleri ve analistlerin güvenebilecekleri modeller kurmalarına yardımcı olur. Bu yaklaşım, her öngörücünün etkisinin net olmasını sağlar; böylece modelden güvenilir sonuçlar çıkarmak ve sonuçlara dayalı daha iyi kararlar almak kolaylaşır. Modelleri nasıl kuracağınızı ve kullanacağınızı gerçekten anlamak için Python ile Makine Öğrenimi Bilimcisi kariyer yolumuzu alın. Ayrıca programı tamamlamak özgeçmişinizde harika durur.
DataCamp ile Öğrenin
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
