
Cursus
Intermediary Regression in R
4 Hr
35.3K
VIF, ontwikkeld door statisticus Cuthbert Daniel, is een veelgebruikt diagnostisch hulpmiddel in regressieanalyse om multicollineariteit op te sporen, wat bekendstaat om het beïnvloeden van de stabiliteit en interpreteerbaarheid van regressiecoëfficiënten. Technischer gezegd kwantificeert VIF in welke mate de variantie van een regressiecoëfficiënt wordt opgeblazen door correlaties tussen voorspellers.
Dit is belangrijk omdat deze correlaties het moeilijk maken om het unieke effect van elke voorspeller op de doelvariabele te isoleren, wat leidt tot minder betrouwbare schattingen. Ook goed om te weten: VIF wordt altijd per voorspeller in een model berekend.
De VIF voor een voorspeller X wordt als volgt berekend:
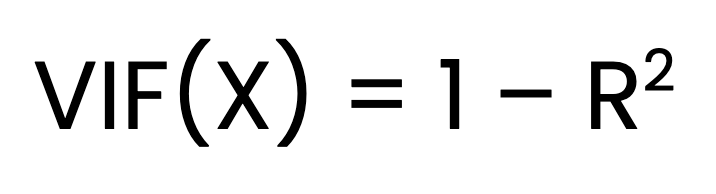
Waarbij:
X wordt geregressieerd op alle andere voorspellers.VIF bepalen bestaat uit drie stappen. Stap één: pas voor elke voorspeller een apart lineair regressiemodel toe tegen alle andere voorspellers. Stap twee: verzamel voor elk model de R2-waarde. Stap drie: bereken de VIF met de bovenstaande formule.
Zo interpreteer je VIF-waarden om het niveau van multicollineariteit te begrijpen:
Als een voorspeller bijvoorbeeld een VIF van 10 heeft, betekent dit dat de variantie van de coëfficiënt 10 keer zo groot is als wanneer er geen multicollineariteit zou zijn.
Multicollineariteit zorgt voor hogere standaardfouten, waardoor het lastiger wordt om de significantie van individuele voorspellers te beoordelen. Dit komt doordat collineaire variabelen vergelijkbare informatie bevatten, waardoor hun specifieke, individuele effecten op de uitkomst moeilijk te scheiden zijn.
Hoewel multicollineariteit niet per se het voorspellend vermogen van het model schaadt, vermindert het wel de betrouwbaarheid en duidelijkheid van de coëfficiënten. Dat is vooral problematisch wanneer we de individuele impact van elke voorspeller willen begrijpen.
De variance inflation factor (VIF) fungeert als een nauwkeurige diagnostische maat om multicollineariteit te identificeren. In tegenstelling tot algemene observaties over correlatie, isoleert VIF het gecombineerde effect van alle voorspellers op elke variabele en legt het interacties bloot die mogelijk niet zichtbaar zijn met paargewijze correlaties.
Om dit praktisch te maken, lopen we een voorbeeld door in zowel Python als R met een uniek dataset. We berekenen VIF met geautomatiseerde pakketten en ook met de VIF-formule om gevoel te krijgen voor de berekening. Om goede oefening te hebben, heb ik bewust een dataset gecreëerd waarin we een hoge VIF-waarde voor een van onze variabelen ontdekken, zelfs als er geen zeer hoge paargewijze correlatie is tussen twee variabelen. Het is dus een aansprekend voorbeeld. Laten we beginnen met een overzicht van de dataset die we gebruiken.
Datasetoverzicht:
Deze fictieve dataset vertegenwoordigt enquête-resultaten van een onderzoek bij 1.000 filialen van een retailgigant. Klanten in elk filiaal is gevraagd om verschillende aspecten van hun winkelervaring te beoordelen op een schaal van -5 tot +5, waarbij -5 een zeer negatieve ervaring aangeeft en +5 een zeer positieve. Het gemiddelde van de klantbeoordelingen per filiaal is genomen over vier kernparameters:
Ambience: Klantperceptie van de winkelomgeving, zoals netheid, indeling, verlichting en algemene sfeer.
Customer_service: Beoordeling van de service van het winkelpersoneel, inclusief behulpzaamheid, vriendelijkheid en respons op klantbehoeften.
Offers: Beoordeling van de promoties, kortingen en deals die in de winkel beschikbaar zijn.
Product_range: Beoordeling van de variëteit en kwaliteit van de producten in de winkel.
De doelvariabele, Performance, meet de algehele prestaties van elk filiaal. Dit is echter niet relevant vanuit VIF-perspectief. Je kunt de dataset hier downloaden.
We beginnen met het berekenen van VIF-waarden met Python-pakketten. De eerste stap is het laden van de dataset en de benodigde libraries.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
datacamp_retail_data = pd.read_csv(' vif_data.csv')
datacamp_retail_data.head()De bovenstaande code laadt de data en toont de eerste vijf records.
Vervolgens kunnen we een correlatiematrix draaien om paargewijze correlatie te controleren.
De onderstaande code selecteert vier kolommen en slaat die op in een nieuwe DataFrame met de naam correl_data. Vervolgens wordt de paargewijze correlatiematrix berekend met de functie .corr(). Het resultaat wordt opgeslagen in het object corr_matrix, een tabel met de correlatiecoëfficiënten tussen elk paar van de geselecteerde kolommen.
De matrix wordt gevisualiseerd met de functie heatmap() van Seaborn, waarbij elke correlatiecoëfficiënt als een kleurgecodeerde cel wordt weergegeven. Blauw staat voor negatieve correlaties en rood voor positieve correlaties, op basis van de coolwarm-kleurenkaart.
correl_data = datacamp_retail_data[['Ambience', 'Customer_service', 'Offers', 'Product_range']]
# Compute the pairwise correlation matrix
corr_matrix = correl_data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pairwise Correlation Matrix')
plt.show()Output:
Correlatie tussen de variabelen. Afbeelding door de auteur
De grafiek geeft een visuele samenvatting van de relaties tussen variabelen in correl_data. De correlatiewaarden variëren van -1 tot 1: dichter bij 1 betekent een sterke positieve correlatie, dichter bij -1 een sterke negatieve correlatie en rond 0 geen correlatie. Het is duidelijk dat er geen sterke paargewijze correlatie is tussen de variabelen; geen enkele correlatie is zelfs maar groter dan 0,6.
De volgende stap is het berekenen van de VIF-waarden voor de voorspellers. De onderstaande code berekent de waarden voor elke voorspeller in de dataset om te controleren op multicollineariteit.
Eerst definiëren we X door de doelkolom Performance te verwijderen en een intercept toe te voegen. Vervolgens maken we een DataFrame, datacamp_vif_data, om de namen van de voorspellers en hun VIF-waarden op te slaan. Met een lus berekenen we daarna de VIF voor elke voorspeller met de variance_inflation_factor()-functie; hogere VIF-waarden wijzen op multicollineariteit.
# Define the predictor variables
X = datacamp_retail_data.drop(columns=['Performance'])
# Add a constant to the model (intercept)
X = add_constant(X)
# Calculate VIF for each feature
datacamp_vif_data = pd.DataFrame()
datacamp_vif_data['Feature'] = X.columns
datacamp_vif_data['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(datacamp_vif_data)Output:
Output met de VIF-waarden. Afbeelding door de auteur
Deze output toont de VIF-waarde voor elke voorspeller en geeft het niveau van multicollineariteit in de dataset aan. De rij const staat voor de interceptterm, met een VIF dicht bij 1, wat betekent dat er geen multicollineariteit is. Van de voorspellers heeft Product_range de hoogste VIF (5,94), wat suggereert dat corrigerende maatregelen nodig zijn. Alle andere voorspellers hebben VIF-waarden onder 3, wat duidt op lage multicollineariteit.
Een andere aanpak is om de waarden afzonderlijk te berekenen door elke onafhankelijke variabele te regressiëren tegen de andere voorspellers.
Concreet werkt dit zo: voor elke feature in retail_data wordt die feature ingesteld als afhankelijke variabele (y) en de overige features als onafhankelijke variabelen (X). Vervolgens wordt een lineair regressiemodel gefit om y te voorspellen met X, en de R-kwadraatwaarde van het model wordt gebruikt om de VIF te berekenen met de formule die we in het eerste deel bespraken.
Daarna worden elke feature en de bijbehorende VIF-waarde opgeslagen in een dictionary (vif_manual), die vervolgens wordt omgezet naar een DataFrame (vif_manual_df) voor weergave.
datacamp_retail_data = retail_data.drop(columns=['Performance'])
# Manual VIF Calculation
vif_manual = {}
for feature in retail_data.columns:
# Define the target variable (current feature) and predictors (all other features)
y = datacamp_retail_data[feature]
X = datacamp_retail_data.drop(columns=[feature])
# Fit the linear regression model
model = LinearRegression().fit(X, y)
# Calculate R-squared
r_squared = model.score(X, y)
# Calculate VIF
vif = 1 / (1 - r_squared)
vif_manual[feature] = vif
# Convert the dictionary to a DataFrame for better display
vif_manual_df = pd.DataFrame(list(vif_manual.items()), columns=['Feature', 'VIF'])
print(vif_manual_df)Output:

Output met de VIF-waarden. Afbeelding door de auteur
De output toont elke feature met zijn VIF-waarde en helpt om mogelijke multicollineariteitsproblemen te identificeren. Je ziet dat het resultaat hetzelfde is als hierboven; en de interpretatie ook, namelijk dat de variabele Product_range multicollineariteit vertoont.
In dit deel herhalen we de oefening uit de Python-sectie, speciaal voor ontwikkelaars die met R werken. We beginnen met het laden van de dataset en de benodigde libraries.
library(tidyverse)
library(car)
library(corrplot)
data <- read.csv('vif_data.csv')
str(data)Output:

De volgende stap is het berekenen van de paargewijze correlatiematrix en deze te visualiseren met een heatmap. De functies cor() en corrplot helpen ons hierbij.
# Remove the target column
predictors_data <- data[, !(names(data) %in% "Performance")]
# Calculate the correlation matrix
correlation_matrix <- cor(predictors_data)
# Plot the correlation heatmap
# Load necessary libraries
library(ggplot2)
library(reshape2)
melted_corr_matrix <- melt(correlation_matrix)
# Plot the heatmap with ggplot2
ggplot(data = melted_corr_matrix, aes(x = Var1, y = Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Correlation") +
theme_minimal() + # Minimal theme for a clean look
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(x = "", y = "") + # Remove axis labels
geom_text(aes(Var1, Var2, label = round(value, 2)), color = "black", size = 4) +
theme(axis.text=element_text(size=15))Output:
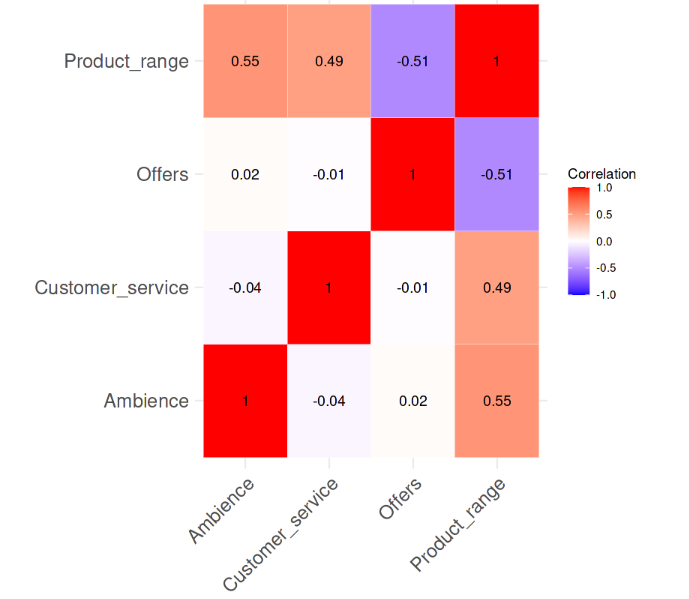
Correlatie tussen de variabelen. Afbeelding door de auteur
Uit de heatmap blijkt duidelijk dat er geen sterke paargewijze correlaties zijn tussen de variabelen; geen van de waarden is groter dan 0,6. We berekenen nu de VIF-waarden om te zien of er iets zorgwekkends is. De volgende regel code doet dat.
# Fit a regression model
model <- lm(Performance ~ Ambience + Customer_service + Offers + Product_range, data = data)
# Calculate VIF
vif(model)Output:

Uit de output blijkt dat onder de voorspellers alleen de variabele Product_range een VIF-waarde boven 5 heeft, wat wijst op hoge multicollineariteit die om corrigerende maatregelen vraagt.
Een andere aanpak voor VIF-berekening is om de VIF-waarden per variabele afzonderlijk te berekenen door elke onafhankelijke variabele te regressiëren tegen de andere voorspellers.
Dit gebeurt in de code hieronder, die de functie sapply() gebruikt over elke voorspeller. Elke voorspeller wordt ingesteld als afhankelijke variabele in een lineair regressiemodel met de andere voorspellers als onafhankelijke variabelen.
De R-kwadraatwaarde uit elk model wordt vervolgens gebruikt om de VIF te berekenen met de formule. Ten slotte toont vif_values de VIF voor elke voorspeller, wat helpt om multicollineariteit te identificeren.
# VIF calculation for each predictor manually
predictors <- c("Ambience", "Customer_service", "Offers", "Product_range")
vif_values <- sapply(predictors, function(pred) {
formula <- as.formula(paste(pred, "~ ."))
model <- lm(formula, data = data[, predictors])
1 / (1 - summary(model)$r.squared)
})
print(vif_values)Output:

We krijgen hetzelfde resultaat en het is duidelijk dat de variabele Product_range met een hoge VIF-waarde boven 5 om ingrijpen vraagt.
Ter recapitulatie de populairste methoden om multicollineariteit op te sporen:
Van al deze methoden is VIF bijzonder nuttig omdat het multicollineariteit kan detecteren zelfs wanneer paargewijze correlaties laag zijn, zoals we in ons voorbeeld zagen. Dit maakt VIF een completer hulpmiddel.
Als VIF-waarden op hoge multicollineariteit wijzen en je het betreffende kenmerk niet zomaar wilt verwijderen, zijn er enkele meer geavanceerde strategieën om multicollineariteit te beperken:
Weten hoe je VIF gebruikt is cruciaal om multicollineariteit te identificeren en te verhelpen, wat de nauwkeurigheid en duidelijkheid van regressiemodellen verbetert. Het regelmatig controleren van VIF-waarden en het toepassen van corrigerende maatregelen wanneer nodig helpt data professionals en analisten om modellen te bouwen waarop ze kunnen vertrouwen. Zo blijft het effect van elke voorspeller helder, kun je betrouwbaarder conclusies trekken uit het model en betere beslissingen nemen op basis van de resultaten. Volg onze Machine Learning Scientist in Python-carrièreroute om echt te begrijpen hoe je modellen bouwt en gebruikt. Bovendien staat het afronden van het programma goed op je cv.
Leer met DataCamp
Cursus
Cursus
blog
Adel Nehme
15 min
