
Curso
Regressão intermediária no R
4 h
35.1K
Desenvolvido pelo estatístico Cuthbert Daniel, o VIF é uma ferramenta de diagnóstico amplamente usada na análise de regressão para detectar multicolinearidade, que é conhecida por afetar a estabilidade e a interpretabilidade dos coeficientes de regressão. Mais tecnicamente, o VIF funciona quantificando o quanto a variação de um coeficiente de regressão é inflada devido às correlações entre os preditores.
Tudo isso é importante porque essas correlações dificultam o isolamento do efeito exclusivo de cada preditor sobre a variável-alvo, o que leva a estimativas de modelos menos confiáveis. Devo dizer também que, para realmente contar a história certa, o VIF é sempre calculado para cada preditor em um modelo.
O VIF para um preditor X é calculado como:
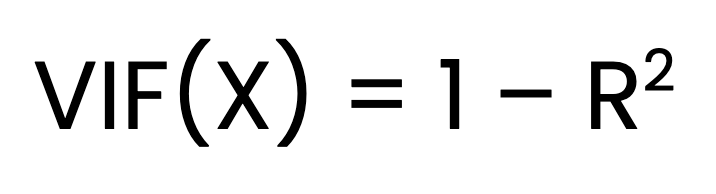
Onde:
X é regredido em todos os outros preditores.Encontrar o VIF é um processo de três etapas. A primeira etapa é ajustar um modelo de regressão linear separado para cada preditor em relação a todos os outros preditores. A segunda etapa é obter o valorR2 para cada modelo. A etapa final é calcular o VIF usando a fórmula acima.
Veja como você pode interpretar os valores de VIF para entender o nível de multicolinearidade:
Por exemplo, se o VIF de um preditor for 10, isso indica que a variação do coeficiente desse preditor é 10 vezes maior do que seria se não houvesse multicolinearidade.
A multicolinearidade faz com que os erros padrão aumentem, o que dificulta a avaliação da importância dos preditores individuais. Isso ocorre porque as variáveis colineares carregam informações semelhantes, o que dificulta a separação de seus efeitos individuais específicos sobre a variável de resultado.
Embora a multicolinearidade não prejudique necessariamente a capacidade de previsão do modelo, ela reduz a confiabilidade e a clareza dos coeficientes. Isso é especialmente problemático quando queremos entender o impacto individual de cada preditor.
O fator de inflação de variância (VIF) serve como uma métrica de diagnóstico precisa para identificar a multicolinearidade. Diferentemente das observações gerais sobre correlação, o VIF isola o efeito combinado de todos os preditores em cada variável, destacando as interações que podem não ser evidentes nas correlações entre pares.
Para tornar isso prático, vamos analisar um exemplo em Python e R usando um conjunto de dados exclusivo. Calcularemos o VIF usando pacotes automatizados e também usando a fórmula VIF para criar intuição. Para que você tenha uma boa prática, criei deliberadamente um conjunto de dados em que descobriremos um alto valor de VIF para uma de nossas variáveis, mesmo que não haja uma correlação muito alta entre as duas variáveis - portanto, acho que é um exemplo convincente. Vamos começar com uma visão geral do conjunto de dados que usaremos.
Visão geral do conjunto de dados:
Esse conjunto de dados fictício representa os resultados de uma pesquisa realizada em 1.000 lojas de um gigante do varejo. Os clientes de cada loja foram solicitados a classificar vários aspectos de sua experiência de compra em uma escala de -5 a +5, em que -5 indica uma experiência muito negativa e +5 indica uma experiência muito positiva. A média das classificações dos clientes em cada loja foi obtida com base em quatro parâmetros principais:
Ambience: Percepção do cliente sobre o ambiente da loja, como limpeza, layout, iluminação e atmosfera geral.
Customer_service: Avaliação do serviço prestado pela equipe da loja, incluindo a ajuda, a simpatia e a capacidade de resposta às necessidades do cliente.
Offers: Classificação das ofertas promocionais, descontos e promoções da loja disponíveis para os clientes.
Product_range: Avaliação da variedade e da qualidade dos produtos disponíveis na loja.
A variável-alvo, Performance, mede o desempenho geral de cada loja. No entanto, isso não é relevante do ponto de vista do VIF. Você pode fazer o download do conjunto de dados aqui.
Começaremos calculando os valores VIF usando os pacotes python. A primeira etapa é carregar o conjunto de dados e as bibliotecas necessárias.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
datacamp_retail_data = pd.read_csv(' vif_data.csv')
datacamp_retail_data.head()O código acima carregará os dados e exibirá os cinco primeiros registros.
Como próxima etapa, podemos executar uma matriz de correlação para verificar a correlação entre pares.
O código abaixo seleciona quatro colunas e as armazena em um novo DataFrame chamado correl_data . Em seguida, você calcula a matriz de correlação de pares usando a função .corr(). O resultado é armazenado no objeto corr_matrix, que é uma tabela que mostra os coeficientes de correlação entre cada par das colunas selecionadas.
A matriz é então visualizada usando a função heatmap() do Seaborn, exibindo cada coeficiente de correlação como uma célula codificada por cores, em que o azul representa correlações negativas e o vermelho representa correlações positivas, com base no mapa de cores coolwarm.
correl_data = datacamp_retail_data[['Ambience', 'Customer_service', 'Offers', 'Product_range']]
# Compute the pairwise correlation matrix
corr_matrix = correl_data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pairwise Correlation Matrix')
plt.show()Saída:
Correlação entre as variáveis. Imagem do autor
O gráfico fornece um resumo visual das relações entre as variáveis em correl_data. Os valores de correlação variam de -1 a 1, sendo que os valores mais próximos de 1 indicam uma forte correlação positiva, os valores mais próximos de -1 indicam uma forte correlação negativa e os valores em torno de 0 sugerem que não há correlação. É evidente que não há correlação forte entre as variáveis, sendo que nenhum dos valores de correlação é maior do que 0,6.
A próxima etapa é calcular os valores VIF para as variáveis preditoras. O código abaixo calcula os valores de cada variável preditora no conjunto de dados para verificar se há multicolinearidade.
Primeiro, ele define X removendo a coluna de destino Performance e adicionando um intercepto. Em seguida, ele cria um DataFrame, datacamp_vif_data, para armazenar os nomes dos preditores e seus valores VIF. Usando um loop, ele calcula o VIF para cada preditor com afunção variance_inflation_factor() , em que VIFs mais altos indicam a presença de multicolinearidade .
# Define the predictor variables
X = datacamp_retail_data.drop(columns=['Performance'])
# Add a constant to the model (intercept)
X = add_constant(X)
# Calculate VIF for each feature
datacamp_vif_data = pd.DataFrame()
datacamp_vif_data['Feature'] = X.columns
datacamp_vif_data['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(datacamp_vif_data)Saída:
Saída mostrando os valores VIF. Imagem do autor
Esse resultado mostra o valor VIF para cada variável preditora, indicando os níveis de multicolinearidade no conjunto de dados. A linha const representa o termo de interceptação, com um VIF próximo a 1, o que significa que não há multicolinearidade. Entre as variáveis preditoras, Product_range tem o VIF mais alto (5,94), o que sugere que ele precisa de medidas corretivas. Todos os outros preditores têm valores de VIF abaixo de 3, indicando baixa multicolinearidade.
A outra abordagem é calcular os valores separadamente, regredindo cada variável independente em relação às outras variáveis preditoras.
Portanto, o funcionamento é que, para cada recurso em retail_data, ele define esse recurso como a variável dependente (y) e os recursos restantes como variáveis independentes (X). Um modelo de regressão linear é então ajustado para prever y usando X, e o valor R-quadrado do modelo é usado para calcular o VIF usando a fórmula que discutimos na seção inicial.
Posteriormente, cada recurso e seus valores VIF correspondentes são armazenados em um dicionário (vif_manual), que é então convertido em um DataFrame (vif_manual_df) para exibição.
datacamp_retail_data = retail_data.drop(columns=['Performance'])
# Manual VIF Calculation
vif_manual = {}
for feature in retail_data.columns:
# Define the target variable (current feature) and predictors (all other features)
y = datacamp_retail_data[feature]
X = datacamp_retail_data.drop(columns=[feature])
# Fit the linear regression model
model = LinearRegression().fit(X, y)
# Calculate R-squared
r_squared = model.score(X, y)
# Calculate VIF
vif = 1 / (1 - r_squared)
vif_manual[feature] = vif
# Convert the dictionary to a DataFrame for better display
vif_manual_df = pd.DataFrame(list(vif_manual.items()), columns=['Feature', 'VIF'])
print(vif_manual_df)Saída:

Saída mostrando os valores VIF. Imagem do autor
O resultado mostra cada recurso junto com seu valor VIF, ajudando a identificar possíveis problemas de multicolinearidade. Você pode ver que o resultado é obviamente o mesmo que obtivemos acima, assim como sua interpretação, que é a de que a variável Product_range está apresentando multicolinearidade.
Nesta seção, repetiremos o exercício do fator de inflação da variância acima na seção Python, especialmente para os desenvolvedores que trabalham com a linguagem de programação R. Começamos carregando o conjunto de dados e as bibliotecas necessárias.
library(tidyverse)
library(car)
library(corrplot)
data <- read.csv('vif_data.csv')
str(data)Saída:

A próxima etapa é calcular a matriz de correlação entre pares e visualizá-la com o mapa de calor. As funções cor() e corrplot nos ajudam a realizar essa tarefa.
# Remove the target column
predictors_data <- data[, !(names(data) %in% "Performance")]
# Calculate the correlation matrix
correlation_matrix <- cor(predictors_data)
# Plot the correlation heatmap
# Load necessary libraries
library(ggplot2)
library(reshape2)
melted_corr_matrix <- melt(correlation_matrix)
# Plot the heatmap with ggplot2
ggplot(data = melted_corr_matrix, aes(x = Var1, y = Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Correlation") +
theme_minimal() + # Minimal theme for a clean look
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(x = "", y = "") + # Remove axis labels
geom_text(aes(Var1, Var2, label = round(value, 2)), color = "black", size = 4) +
theme(axis.text=element_text(size=15))Saída:
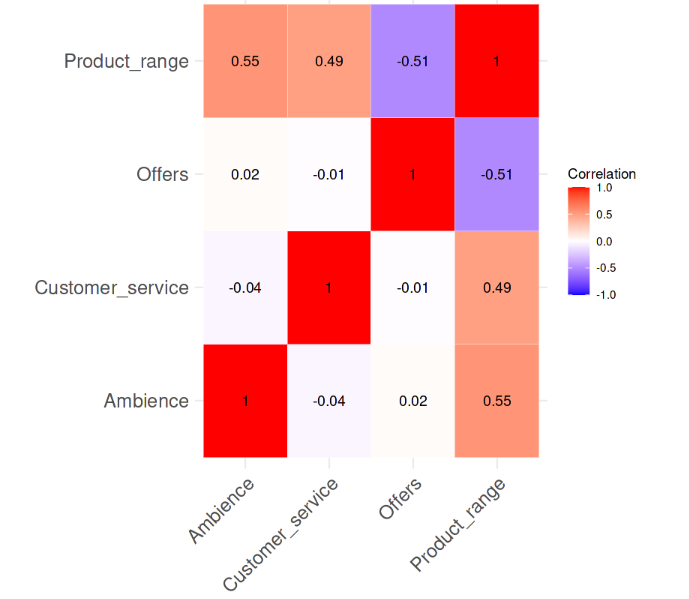
Correlação entre as variáveis. Imagem do autor
Fica evidente no mapa de calor da correlação que não há uma forte correlação entre as variáveis, sendo que nenhum dos valores de correlação é superior a 0,6. Agora, calcularemos os valores VIF e veremos se há algo alarmante. A linha de código a seguir faz essa tarefa.
# Fit a regression model
model <- lm(Performance ~ Ambience + Customer_service + Offers + Product_range, data = data)
# Calculate VIF
vif(model)Saída:

A partir do resultado, podemos ver que, entre as variáveis preditoras, somente a variável Product_range tem o valor VIF maior que 5, o que sugere alta multicolinearidade que precisa de medidas corretivas.
A outra abordagem para o cálculo do VIF seria calcular os valores do VIF para cada variável separadamente, regredindo cada variável independente em relação às outras variáveis preditoras.
Isso é feito no código abaixo, que usa a função sapply()em cada preditor, em que cada preditor é definido como a variável dependente em um modelo de regressão linear com os outros preditores como variáveis independentes.
O valor R-quadrado de cada modelo é então usado para calcular os valores VIF com sua fórmula. Por fim, o resultado, vif_values, exibe o VIF para cada preditor, ajudando a identificar problemas de multicolinearidade.
# VIF calculation for each predictor manually
predictors <- c("Ambience", "Customer_service", "Offers", "Product_range")
vif_values <- sapply(predictors, function(pred) {
formula <- as.formula(paste(pred, "~ ."))
model <- lm(formula, data = data[, predictors])
1 / (1 - summary(model)$r.squared)
})
print(vif_values)Saída:

Obtemos o mesmo resultado e fica evidente que a variável Product_range com um valor VIF alto, acima de 5, precisa de intervenção.
Recapitulando, aqui estão os métodos populares para detectar multicolinearidade:
Entre todos esses métodos, o VIF é particularmente útil porque pode detectar multicolinearidade mesmo quando as correlações entre pares são baixas, como vimos em nosso próprio exemplo. Isso torna o VIF uma ferramenta mais abrangente.
Se os valores de VIF indicarem alta multicolinearidade e você não quiser necessariamente apenas remover a variável, há outras estratégias mais avançadas para atenuar a multicolinearidade:
Saber como usar o VIF é fundamental para identificar e corrigir a multicolinearidade, o que melhora a precisão e a clareza dos modelos de regressão. A verificação regular dos valores de VIF e a aplicação de medidas corretivas quando necessário ajudam os profissionais de dados e analistas a criar modelos nos quais podem confiar. Essa abordagem garante que o efeito de cada preditor seja claro, facilitando a obtenção de conclusões confiáveis do modelo e a tomada de decisões melhores com base nos resultados. Acesse nossa trilha de carreira de Cientista de Aprendizado de Máquina em Python para você realmente entender como criar modelos e usá-los. Além disso, a conclusão do programa fica muito bem em um currículo.
Aprenda com a DataCamp
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Zoumana Keita
Tutorial
Eladio Montero Porras
Tutorial
Vidhi Chugh
Tutorial
Zoumana Keita
Tutorial
Moez Ali
