
Courses
Hồi quy trung cấp với R
4 giờ
35.3K
Được phát triển bởi nhà thống kê Cuthbert Daniel, VIF là một công cụ chẩn đoán được sử dụng rộng rãi trong phân tích hồi quy để phát hiện đa cộng tuyến, vốn được biết là ảnh hưởng đến tính ổn định và khả năng diễn giải của các hệ số hồi quy. Về mặt kỹ thuật, VIF định lượng mức độ phương sai của một hệ số hồi quy bị phồng lên do tương quan giữa các biến dự báo.
Tất cả điều này quan trọng vì những tương quan này khiến khó cô lập tác động riêng của từng biến dự báo lên biến mục tiêu, dẫn đến ước lượng mô hình kém tin cậy hơn. Cũng cần nói rằng, để kể đúng câu chuyện, VIF luôn được tính cho từng biến dự báo trong một mô hình.
VIF cho một biến dự báo X được tính như sau:
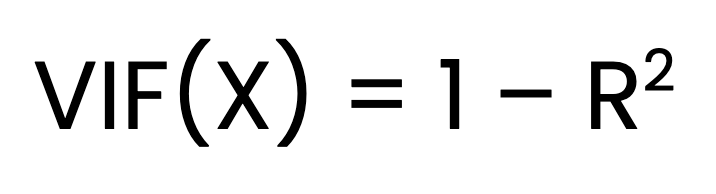
Trong đó:
X trên tất cả các biến dự báo còn lại.Tìm VIF gồm ba bước. Bước đầu là khớp một mô hình hồi quy tuyến tính riêng cho từng biến dự báo so với tất cả biến dự báo khác. Bước hai là lấy giá trị R2 cho mỗi mô hình. Bước cuối là tính VIF bằng công thức ở trên.
Dưới đây là cách diễn giải giá trị VIF để hiểu mức độ đa cộng tuyến:
Ví dụ, nếu VIF của một biến dự báo là 10, điều đó cho thấy phương sai của hệ số biến đó gấp 10 lần so với khi không có đa cộng tuyến.
Đa cộng tuyến làm tăng sai số chuẩn, khiến việc đánh giá ý nghĩa của từng biến dự báo trở nên khó khăn hơn. Điều này xảy ra vì các biến đồng tuyến mang thông tin tương tự nhau, làm khó việc tách biệt tác động riêng của chúng lên biến kết quả.
Mặc dù đa cộng tuyến không nhất thiết làm hại khả năng dự báo của mô hình, nó làm giảm độ tin cậy và rõ ràng của các hệ số. Điều này đặc biệt vấn đề khi chúng ta muốn hiểu tác động riêng của từng biến dự báo.
Hệ số phồng phương sai (VIF) đóng vai trò là chỉ số chẩn đoán chính xác để xác định đa cộng tuyến. Khác với các quan sát chung về tương quan, VIF tách biệt tác động tổng hợp của tất cả biến dự báo lên từng biến, làm nổi bật các tương tác có thể không thấy qua tương quan cặp.
Để có thể áp dụng, hãy cùng đi qua một ví dụ trong cả Python và R với một tập dữ liệu riêng. Chúng ta sẽ tính VIF bằng các gói tự động và cả bằng công thức VIF để xây dựng trực giác. Để luyện tập tốt, tôi đã cố tình tạo một tập dữ liệu mà ở đó chúng ta sẽ phát hiện một giá trị VIF cao cho một biến dù không có tương quan cặp nào quá cao giữa bất kỳ hai biến nào — nên tôi nghĩ đây là một ví dụ thuyết phục. Hãy bắt đầu với tổng quan về tập dữ liệu sẽ dùng.
Tổng quan tập dữ liệu:
Tập dữ liệu giả định này đại diện cho kết quả khảo sát từ một nghiên cứu thực hiện trên 1.000 cửa hàng của một tập đoàn bán lẻ lớn. Khách hàng tại mỗi cửa hàng được yêu cầu đánh giá các khía cạnh về trải nghiệm mua sắm trên thang điểm từ -5 đến +5, trong đó -5 là trải nghiệm rất tiêu cực và +5 là rất tích cực. Điểm trung bình của khách hàng tại mỗi cửa hàng được lấy trên bốn tham số chính:
Ambience: Cảm nhận của khách hàng về môi trường cửa hàng, như vệ sinh, bố cục, ánh sáng và bầu không khí tổng thể.
Customer_service: Đánh giá về dịch vụ do nhân viên cung cấp, bao gồm sự hữu ích, thân thiện và khả năng đáp ứng nhu cầu khách hàng.
Offers: Đánh giá về các ưu đãi khuyến mãi, giảm giá và các chương trình dành cho khách hàng của cửa hàng.
Product_range: Đánh giá về mức độ đa dạng và chất lượng sản phẩm có sẵn trong cửa hàng.
Biến mục tiêu, Performance, đo lường hiệu suất tổng thể của mỗi cửa hàng. Tuy nhiên, nó không liên quan từ góc độ VIF. Bạn có thể tải tập dữ liệu tại đây.
Chúng ta sẽ bắt đầu bằng cách tính các giá trị VIF bằng các gói Python. Bước đầu là tải tập dữ liệu và các thư viện cần thiết.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
datacamp_retail_data = pd.read_csv(' vif_data.csv')
datacamp_retail_data.head()Đoạn mã trên sẽ tải dữ liệu và hiển thị năm bản ghi đầu tiên.
Bước tiếp theo, chúng ta có thể chạy ma trận tương quan để kiểm tra tương quan cặp.
Đoạn mã dưới đây chọn bốn cột và lưu chúng vào một DataFrame mới gọi là correl_data. Sau đó tính ma trận tương quan cặp bằng hàm .corr(). Kết quả được lưu trong đối tượng corr_matrix, là một bảng thể hiện hệ số tương quan giữa từng cặp cột đã chọn.
Ma trận sau đó được trực quan hóa bằng hàm heatmap() của Seaborn, hiển thị mỗi hệ số tương quan dưới dạng một ô mã màu, trong đó màu xanh biểu thị tương quan âm và màu đỏ biểu thị tương quan dương, dựa trên bản đồ màu coolwarm.
correl_data = datacamp_retail_data[['Ambience', 'Customer_service', 'Offers', 'Product_range']]
# Compute the pairwise correlation matrix
corr_matrix = correl_data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pairwise Correlation Matrix')
plt.show()Kết quả:
Tương quan giữa các biến. Ảnh: Tác giả
Biểu đồ cung cấp tóm tắt trực quan về mối quan hệ giữa các biến trong correl_data. Giá trị tương quan nằm trong khoảng từ -1 đến 1, trong đó giá trị gần 1 cho thấy tương quan dương mạnh, gần -1 cho thấy tương quan âm mạnh, và quanh 0 gợi ý không có tương quan. Rõ ràng là không có tương quan cặp mạnh giữa các biến, không giá trị nào thậm chí lớn hơn 0,6.
Bước tiếp theo là tính giá trị VIF cho các biến dự báo. Đoạn mã dưới đây tính giá trị cho từng biến dự báo trong tập dữ liệu để kiểm tra đa cộng tuyến.
Trước hết, xác định X bằng cách loại bỏ cột mục tiêu Performance và thêm hằng số chặn. Sau đó, tạo một DataFrame, datacamp_vif_data, để lưu tên các biến dự báo và giá trị VIF của chúng. Sử dụng vòng lặp, tiếp theo tính VIF cho từng biến dự báo với hàm variance_inflation_factor(), trong đó VIF cao hơn cho thấy có đa cộng tuyến.
# Define the predictor variables
X = datacamp_retail_data.drop(columns=['Performance'])
# Add a constant to the model (intercept)
X = add_constant(X)
# Calculate VIF for each feature
datacamp_vif_data = pd.DataFrame()
datacamp_vif_data['Feature'] = X.columns
datacamp_vif_data['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(datacamp_vif_data)Kết quả:
Kết quả hiển thị các giá trị VIF. Ảnh: Tác giả
Kết quả này cho thấy giá trị VIF cho từng biến dự báo, phản ánh mức độ đa cộng tuyến trong tập dữ liệu. Hàng const đại diện cho hằng số chặn, với VIF xấp xỉ 1, nghĩa là không có đa cộng tuyến. Trong số các biến dự báo, Product_range có VIF cao nhất (5,94), cho thấy cần có biện pháp khắc phục. Tất cả biến dự báo còn lại có VIF dưới 3, chỉ ra đa cộng tuyến thấp.
Cách khác là tính các giá trị riêng lẻ bằng cách hồi quy từng biến độc lập đối với các biến dự báo còn lại.
Cụ thể, với mỗi đặc trưng trong retail_data, ta đặt đặc trưng đó làm biến phụ thuộc (y) và các đặc trưng còn lại làm biến độc lập (X). Sau đó khớp một mô hình hồi quy tuyến tính để dự đoán y từ X, và giá trị R-squared của mô hình được dùng để tính VIF theo công thức đã thảo luận ở phần đầu.
Tiếp đó, từng đặc trưng và giá trị VIF tương ứng được lưu trong một từ điển (vif_manual), rồi chuyển thành DataFrame (vif_manual_df) để hiển thị.
datacamp_retail_data = retail_data.drop(columns=['Performance'])
# Manual VIF Calculation
vif_manual = {}
for feature in retail_data.columns:
# Define the target variable (current feature) and predictors (all other features)
y = datacamp_retail_data[feature]
X = datacamp_retail_data.drop(columns=[feature])
# Fit the linear regression model
model = LinearRegression().fit(X, y)
# Calculate R-squared
r_squared = model.score(X, y)
# Calculate VIF
vif = 1 / (1 - r_squared)
vif_manual[feature] = vif
# Convert the dictionary to a DataFrame for better display
vif_manual_df = pd.DataFrame(list(vif_manual.items()), columns=['Feature', 'VIF'])
print(vif_manual_df)Kết quả:

Kết quả hiển thị các giá trị VIF. Ảnh: Tác giả
Kết quả cho thấy mỗi đặc trưng cùng với giá trị VIF của nó, giúp xác định các vấn đề đa cộng tuyến tiềm ẩn. Bạn có thể thấy kết quả rõ ràng giống như ở trên; và cách diễn giải cũng vậy, đó là biến Product_range đang thể hiện đa cộng tuyến.
Trong phần này, chúng ta sẽ lặp lại bài tập về hệ số phồng phương sai như ở phần Python, đặc biệt cho các nhà phát triển làm việc với ngôn ngữ R. Chúng ta bắt đầu bằng cách tải tập dữ liệu và các thư viện cần thiết.
library(tidyverse)
library(car)
library(corrplot)
data <- read.csv('vif_data.csv')
str(data)Kết quả:

Bước tiếp theo là tính ma trận tương quan cặp và trực quan hóa nó với heatmap. Các hàm cor() và corrplot giúp chúng ta thực hiện tác vụ này.
# Remove the target column
predictors_data <- data[, !(names(data) %in% "Performance")]
# Calculate the correlation matrix
correlation_matrix <- cor(predictors_data)
# Plot the correlation heatmap
# Load necessary libraries
library(ggplot2)
library(reshape2)
melted_corr_matrix <- melt(correlation_matrix)
# Plot the heatmap with ggplot2
ggplot(data = melted_corr_matrix, aes(x = Var1, y = Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Correlation") +
theme_minimal() + # Minimal theme for a clean look
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(x = "", y = "") + # Remove axis labels
geom_text(aes(Var1, Var2, label = round(value, 2)), color = "black", size = 4) +
theme(axis.text=element_text(size=15))Kết quả:
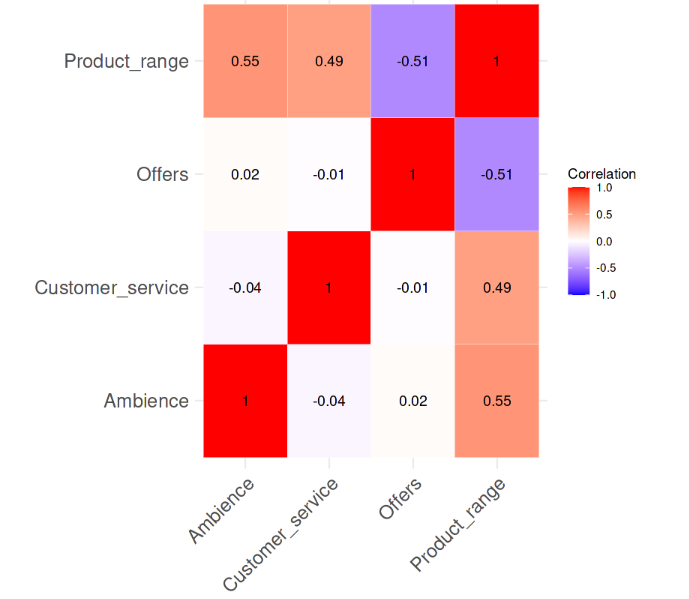
Tương quan giữa các biến. Ảnh: Tác giả
Rõ ràng từ heatmap tương quan là không có tương quan cặp mạnh giữa các biến, không giá trị nào thậm chí lớn hơn 0,6. Giờ chúng ta sẽ tính các giá trị VIF và xem có điều gì đáng lo ngại không. Dòng mã sau thực hiện tác vụ đó.
# Fit a regression model
model <- lm(Performance ~ Ambience + Customer_service + Offers + Product_range, data = data)
# Calculate VIF
vif(model)Kết quả:

Từ kết quả, chúng ta thấy rằng trong số các biến dự báo, chỉ biến Product_range có giá trị VIF lớn hơn 5, gợi ý đa cộng tuyến cao cần có biện pháp khắc phục.
Cách khác để tính VIF là tính giá trị VIF cho từng biến riêng lẻ bằng cách hồi quy từng biến độc lập đối với các biến dự báo còn lại.
Điều này được thực hiện trong đoạn mã dưới đây, sử dụng hàm sapply() trên từng biến dự báo, trong đó mỗi biến được đặt làm biến phụ thuộc trong một mô hình hồi quy tuyến tính với các biến còn lại là biến độc lập.
Giá trị R-squared từ mỗi mô hình sau đó được dùng để tính các giá trị VIF bằng công thức của nó. Cuối cùng, kết quả vif_values hiển thị VIF cho từng biến dự báo, giúp xác định vấn đề đa cộng tuyến.
# VIF calculation for each predictor manually
predictors <- c("Ambience", "Customer_service", "Offers", "Product_range")
vif_values <- sapply(predictors, function(pred) {
formula <- as.formula(paste(pred, "~ ."))
model <- lm(formula, data = data[, predictors])
1 / (1 - summary(model)$r.squared)
})
print(vif_values)Kết quả:

Chúng ta nhận được cùng một kết quả và rõ ràng biến Product_range với giá trị VIF cao trên 5 cần can thiệp.
Tóm lại, đây là các phương pháp phổ biến để phát hiện đa cộng tuyến:
Trong số các phương pháp này, VIF đặc biệt hữu ích vì nó có thể phát hiện đa cộng tuyến ngay cả khi tương quan cặp thấp, như chúng ta đã thấy trong ví dụ của mình. Điều này khiến VIF trở thành công cụ toàn diện hơn.
Nếu các giá trị VIF cho thấy đa cộng tuyến cao và bạn không nhất thiết chỉ muốn loại bỏ biến, có một số chiến lược nâng cao khác để giảm đa cộng tuyến:
Biết cách sử dụng VIF là chìa khóa để xác định và khắc phục đa cộng tuyến, qua đó cải thiện độ chính xác và rõ ràng của các mô hình hồi quy. Thường xuyên kiểm tra các giá trị VIF và áp dụng biện pháp khắc phục khi cần giúp các chuyên gia dữ liệu và nhà phân tích xây dựng những mô hình đáng tin cậy. Cách tiếp cận này đảm bảo tác động của từng biến dự báo là rõ ràng, giúp rút ra kết luận đáng tin và ra quyết định tốt hơn dựa trên kết quả. Hãy tham gia lộ trình nghề nghiệp Machine Learning Scientist in Python của chúng tôi để thực sự hiểu cách xây dựng và sử dụng mô hình. Hơn nữa, hoàn thành chương trình sẽ rất ấn tượng trên hồ sơ xin việc.
Học cùng DataCamp
Courses
Courses