
Corso
Regressione intermedia in R
4 h
35.3K
Sviluppato dallo statistico Cuthbert Daniel, il VIF è uno strumento diagnostico ampiamente utilizzato nell’analisi di regressione per rilevare la multicollinearità, nota per influenzare la stabilità e l’interpretabilità dei coefficienti di regressione. Più tecnicamente, il VIF quantifica di quanto la varianza di un coefficiente di regressione è gonfiata a causa delle correlazioni tra i predittori.
Tutto ciò è importante perché queste correlazioni rendono difficile isolare l’effetto specifico di ciascun predittore sulla variabile target, portando a stime del modello meno affidabili. Va detto anche che, per raccontare davvero la storia nel modo giusto, il VIF viene sempre calcolato per ciascun predittore in un modello.
Il VIF per un predittore X si calcola come:
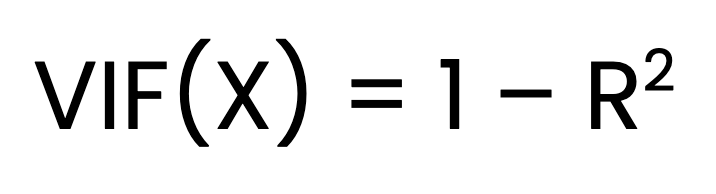
Dove:
X viene messo in regressione su tutti gli altri predittori.Trovare il VIF è un processo in tre fasi. Il primo passo è adattare un modello di regressione lineare separato per ciascun predittore rispetto a tutti gli altri predittori. Il secondo passo è ottenere il valore R2 per ciascun modello. L’ultimo passo è calcolare il VIF usando la formula sopra.
Ecco come interpretare i valori VIF per comprendere il livello di multicollinearità:
Per esempio, se il VIF di un predittore è 10, significa che la varianza del coefficiente di quel predittore è 10 volte quella che sarebbe in assenza di multicollinearità.
La multicollinearità fa aumentare gli errori standard, rendendo più difficile valutare la significatività dei singoli predittori. Questo accade perché le variabili collineari veicolano informazioni simili, rendendo difficile separare i loro effetti individuali specifici sulla variabile di output.
Anche se la multicollinearità non danneggia necessariamente la capacità predittiva del modello, riduce l’affidabilità e la chiarezza dei coefficienti. Questo è particolarmente problematico quando vogliamo comprendere l’impatto individuale di ciascun predittore.
Il fattore di inflazione della varianza (VIF) è una metrica diagnostica precisa per identificare la multicollinearità. A differenza delle osservazioni generali sulla correlazione, il VIF isola l’effetto combinato di tutti i predittori su ciascuna variabile, mettendo in evidenza interazioni che potrebbero non emergere dalle correlazioni a coppie.
Per renderlo operativo, vediamo un esempio sia in Python sia in R usando un dataset specifico. Calcoleremo il VIF con pacchetti automatizzati e anche usando la formula del VIF per costruire intuizione. Per esercitarci al meglio, ho creato deliberatamente un dataset in cui scopriremo un valore VIF alto per una delle nostre variabili anche se non c’è una correlazione a coppie molto elevata tra nessuna coppia di variabili: per questo penso sia un esempio convincente. Iniziamo con una panoramica del dataset che useremo.
Panoramica del dataset:
Questo dataset fittizio rappresenta i risultati di un sondaggio condotto in 1.000 negozi di una grande catena retail. Ai clienti di ciascun negozio è stato chiesto di valutare vari aspetti della loro esperienza di acquisto su una scala da -5 a +5, dove -5 indica un’esperienza molto negativa e +5 indica un’esperienza molto positiva. Per ciascun negozio è stata calcolata la media delle valutazioni dei clienti su quattro parametri chiave:
Ambience: Percezione dei clienti dell’ambiente del negozio, come pulizia, layout, illuminazione e atmosfera generale.
Customer_service: Valutazione del servizio fornito dal personale del negozio, inclusi disponibilità, cordialità e reattività alle esigenze dei clienti.
Offers: Valutazione delle offerte promozionali, degli sconti e delle promozioni disponibili per i clienti.
Product_range: Valutazione della varietà e qualità dei prodotti disponibili nel negozio.
La variabile target, Performance, misura le prestazioni complessive di ciascun negozio. Tuttavia, non è rilevante dal punto di vista del VIF. Puoi scaricare il dataset qui.
Inizieremo calcolando i valori VIF usando i pacchetti Python. Il primo passo è caricare il dataset e le librerie necessarie.
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
datacamp_retail_data = pd.read_csv(' vif_data.csv')
datacamp_retail_data.head()Il codice qui sopra caricherà i dati e mostrerà i primi cinque record.
Come passo successivo, possiamo eseguire una matrice di correlazione per controllare la correlazione a coppie.
Il codice seguente seleziona quattro colonne e le memorizza in un nuovo DataFrame chiamato correl_data. Quindi calcola la matrice di correlazione a coppie usando la funzione .corr(). Il risultato viene memorizzato nell’oggetto corr_matrix, che è una tabella che mostra i coefficienti di correlazione tra ciascuna coppia delle colonne selezionate.
La matrice viene poi visualizzata usando la funzione heatmap() di Seaborn, che mostra ciascun coefficiente di correlazione come una cella colorata, dove il blu rappresenta correlazioni negative e il rosso rappresenta correlazioni positive, in base alla mappa colori coolwarm.
correl_data = datacamp_retail_data[['Ambience', 'Customer_service', 'Offers', 'Product_range']]
# Compute the pairwise correlation matrix
corr_matrix = correl_data.corr()
# Visualize the correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('Pairwise Correlation Matrix')
plt.show()Output:
Correlazione tra le variabili. Immagine dell’autore
Il grafico fornisce un riepilogo visivo delle relazioni tra le variabili in correl_data. I valori di correlazione vanno da -1 a 1: valori prossimi a 1 indicano una forte correlazione positiva, valori prossimi a -1 indicano una forte correlazione negativa e valori intorno a 0 suggeriscono assenza di correlazione. È evidente che non c’è una forte correlazione a coppie tra le variabili, nessuno dei valori di correlazione supera nemmeno 0,6.
Il passo successivo è calcolare i valori VIF per le variabili predittive. Il codice seguente calcola i valori per ciascun predittore nel dataset per verificare la presenza di multicollinearità.
Per prima cosa, definisce X rimuovendo la colonna target Performance e aggiungendo un intercetta. Quindi crea un DataFrame, datacamp_vif_data, per memorizzare i nomi dei predittori e i loro valori VIF. Usando un ciclo, calcola poi il VIF per ciascun predittore con la funzione variance_inflation_factor(), dove VIF più alti indicano la presenza di multicollinearità.
# Define the predictor variables
X = datacamp_retail_data.drop(columns=['Performance'])
# Add a constant to the model (intercept)
X = add_constant(X)
# Calculate VIF for each feature
datacamp_vif_data = pd.DataFrame()
datacamp_vif_data['Feature'] = X.columns
datacamp_vif_data['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(datacamp_vif_data)Output:
Output che mostra i valori VIF. Immagine dell’autore
Questo output mostra il valore VIF per ciascuna variabile predittiva, indicando i livelli di multicollinearità nel dataset. La riga const rappresenta il termine di intercetta, con un VIF vicino a 1, il che significa che non ha multicollinearità. Tra le variabili predittive, Product_range ha il VIF più alto (5,94), il che suggerisce che richiede misure correttive. Tutti gli altri predittori hanno valori VIF inferiori a 3, indicando bassa multicollinearità.
L’altro approccio è calcolare i valori separatamente mettendo in regressione ciascuna variabile indipendente rispetto alle altre variabili predittive.
In pratica, per ciascuna feature in retail_data si imposta quella feature come variabile dipendente (y) e le feature rimanenti come variabili indipendenti (X). Si adatta quindi un modello di regressione lineare per predire y usando X e il valore R-quadro del modello viene utilizzato per calcolare il VIF con la formula di cui abbiamo parlato nella sezione iniziale.
Successivamente, ciascuna feature e il relativo valore VIF vengono memorizzati in un dizionario (vif_manual), che viene poi convertito in un DataFrame (vif_manual_df) per la visualizzazione.
datacamp_retail_data = retail_data.drop(columns=['Performance'])
# Manual VIF Calculation
vif_manual = {}
for feature in retail_data.columns:
# Define the target variable (current feature) and predictors (all other features)
y = datacamp_retail_data[feature]
X = datacamp_retail_data.drop(columns=[feature])
# Fit the linear regression model
model = LinearRegression().fit(X, y)
# Calculate R-squared
r_squared = model.score(X, y)
# Calculate VIF
vif = 1 / (1 - r_squared)
vif_manual[feature] = vif
# Convert the dictionary to a DataFrame for better display
vif_manual_df = pd.DataFrame(list(vif_manual.items()), columns=['Feature', 'VIF'])
print(vif_manual_df)Output:

Output che mostra i valori VIF. Immagine dell’autore
L’output mostra ciascuna feature insieme al suo valore VIF, aiutando a identificare potenziali problemi di multicollinearità. Come vedi, il risultato è ovviamente lo stesso ottenuto sopra; e lo è anche l’interpretazione, cioè che la variabile Product_range sta mostrando multicollinearità.
In questa sezione, ripeteremo l’esercizio sul fattore di inflazione della varianza visto nella sezione Python, in particolare per gli sviluppatori che lavorano con il linguaggio R. Iniziamo caricando il dataset e le librerie necessarie.
library(tidyverse)
library(car)
library(corrplot)
data <- read.csv('vif_data.csv')
str(data)Output:

Il passo successivo è calcolare la matrice di correlazione a coppie e visualizzarla con una heatmap. Le funzioni cor() e corrplot ci aiutano a svolgere questo compito.
# Remove the target column
predictors_data <- data[, !(names(data) %in% "Performance")]
# Calculate the correlation matrix
correlation_matrix <- cor(predictors_data)
# Plot the correlation heatmap
# Load necessary libraries
library(ggplot2)
library(reshape2)
melted_corr_matrix <- melt(correlation_matrix)
# Plot the heatmap with ggplot2
ggplot(data = melted_corr_matrix, aes(x = Var1, y = Var2, fill = value)) +
geom_tile(color = "white") +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1, 1), space = "Lab",
name="Correlation") +
theme_minimal() + # Minimal theme for a clean look
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust = 1)) +
labs(x = "", y = "") + # Remove axis labels
geom_text(aes(Var1, Var2, label = round(value, 2)), color = "black", size = 4) +
theme(axis.text=element_text(size=15))Output:
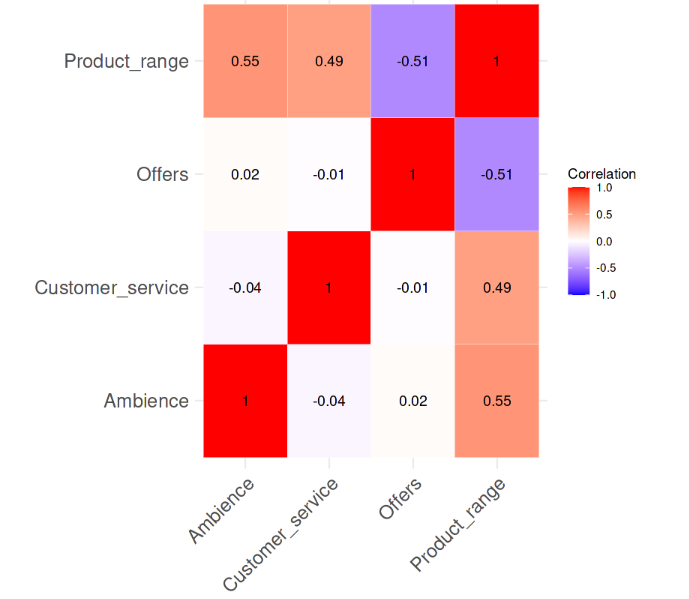
Correlazione tra le variabili. Immagine dell’autore
Dalla heatmap delle correlazioni è evidente che non c’è una forte correlazione a coppie tra le variabili: nessuno dei valori supera nemmeno 0,6. Ora calcoleremo i valori VIF per vedere se c’è qualcosa di preoccupante. La riga di codice seguente svolge questo compito.
# Fit a regression model
model <- lm(Performance ~ Ambience + Customer_service + Offers + Product_range, data = data)
# Calculate VIF
vif(model)Output:

Dall’output si vede che tra le variabili predittive solo la variabile Product_range ha un valore VIF superiore a 5, il che suggerisce un’elevata multicollinearità che richiede misure correttive.
L’altro approccio al calcolo del VIF consiste nel calcolare i valori VIF per ciascuna variabile separatamente mettendo in regressione ciascuna variabile indipendente rispetto alle altre variabili predittive.
Questo viene eseguito nel codice qui sotto, che usa la funzione sapply() su ciascun predittore, dove ogni predittore è impostato come variabile dipendente in un modello di regressione lineare con gli altri predittori come variabili indipendenti.
Il valore R-quadro di ciascun modello viene poi utilizzato per calcolare i valori VIF con la sua formula. Infine, il risultato, vif_values, mostra il VIF per ciascun predittore, aiutando a identificare problemi di multicollinearità.
# VIF calculation for each predictor manually
predictors <- c("Ambience", "Customer_service", "Offers", "Product_range")
vif_values <- sapply(predictors, function(pred) {
formula <- as.formula(paste(pred, "~ ."))
model <- lm(formula, data = data[, predictors])
1 / (1 - summary(model)$r.squared)
})
print(vif_values)Output:

Otteniamo lo stesso risultato ed è evidente che la variabile Product_range con un valore VIF elevato sopra 5 necessita di intervento.
Per ricapitolare, ecco i metodi più diffusi per rilevare la multicollinearità:
Tra tutti questi metodi, il VIF è particolarmente utile perché può rilevare la multicollinearità anche quando le correlazioni a coppie sono basse, come abbiamo visto nel nostro esempio. Questo rende il VIF uno strumento più completo.
Se i valori VIF indicano un’elevata multicollinearità e non vuoi necessariamente rimuovere la variabile, ci sono altre strategie più avanzate per mitigare la multicollinearità:
Saper usare il VIF è fondamentale per identificare e correggere la multicollinearità, migliorando l’accuratezza e la chiarezza dei modelli di regressione. Controllare regolarmente i valori VIF e applicare misure correttive quando necessario aiuta professionisti e analisti dei dati a costruire modelli affidabili. Questo approccio assicura che l’effetto di ciascun predittore sia chiaro, facilitando il trarre conclusioni attendibili dal modello e prendere decisioni migliori in base ai risultati. Segui il nostro percorso professionale Machine Learning Scientist in Python per capire davvero come costruire modelli e usarli. In più, completare il programma fa un’ottima impressione sul CV.
Impara con DataCamp
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

