
Che cos'è il Deep Learning?
Il deep learning è un tipo di machine learning che insegna ai computer a svolgere compiti imparando dagli esempi, un po' come fanno gli esseri umani. Immagina di insegnare a un computer a riconoscere i gatti: invece di dirgli di cercare baffi, orecchie e coda, gli mostri migliaia di foto di gatti. Il computer trova da solo i modelli ricorrenti e impara a identificare un gatto. Questa è l'essenza del deep learning.
In termini tecnici, il deep learning utilizza qualcosa chiamato "reti neurali", ispirate al cervello umano. Queste reti sono composte da strati di nodi interconnessi che elaborano informazioni. Più strati ci sono, più la rete è "profonda", il che le consente di apprendere caratteristiche più complesse ed eseguire compiti più sofisticati.
La somiglianza tra neuroni e reti neurali
L'evoluzione dal Machine Learning al Deep Learning
Che cos'è il machine learning?
Il machine learning è a sua volta un sottoinsieme dell'intelligenza artificiale (AI) che consente ai computer di imparare dai dati e prendere decisioni senza programmazione esplicita. Comprende varie tecniche e algoritmi che permettono ai sistemi di riconoscere schemi, fare previsioni e migliorare le prestazioni nel tempo. Puoi approfondire la differenza tra machine learning e AI in un articolo dedicato.
In cosa il deep learning differisce dal machine learning tradizionale
Sebbene il machine learning sia stato di per sé una tecnologia trasformativa, il deep learning fa un ulteriore passo avanti automatizzando molte attività che normalmente richiedono competenze umane.
Il deep learning è essenzialmente un sottoinsieme specializzato del machine learning, distinto dall'uso di reti neurali con tre o più strati. Queste reti neurali cercano di simulare il comportamento del cervello umano—pur essendo lontane dal raggiungerne le capacità—per "imparare" da grandi quantità di dati. Puoi esplorare più in dettaglio le differenze tra machine learning e deep learning in un post dedicato.
L'importanza della feature engineering
La feature engineering è il processo di selezione, trasformazione o creazione delle variabili più rilevanti, dette "feature", a partire da dati grezzi da utilizzare nei modelli di machine learning.
Per esempio, se stai costruendo un modello di previsione meteo, i dati grezzi potrebbero includere temperatura, umidità, velocità del vento e pressione barometrica. La feature engineering consiste nel determinare quali di queste variabili sono più importanti per prevedere il tempo e, possibilmente, trasformarle (ad esempio, convertire la temperatura da Fahrenheit a Celsius) per renderle più utili al modello.
Nel machine learning tradizionale, la feature engineering è spesso un processo manuale e dispendioso che richiede competenze di dominio. Uno dei vantaggi del deep learning, però, è la capacità di apprendere automaticamente le feature rilevanti dai dati grezzi, riducendo la necessità di intervento manuale.
Perché il Deep Learning è importante?
Ecco perché il deep learning è diventato lo standard del settore:
- Gestione dei dati non strutturati: Modelli addestrati su dati strutturati possono imparare facilmente anche da dati non strutturati, riducendo tempo e risorse per standardizzare i dataset.
- Gestione di grandi quantità di dati: Grazie all'introduzione delle GPU (graphics processing unit), i modelli di deep learning possono elaborare grandi volumi di dati a velocità fulminea.
- Alta accuratezza: I modelli di deep learning offrono i risultati più accurati in computer vision, elaborazione del linguaggio naturale (NLP) ed elaborazione audio.
- Riconoscimento di pattern: La maggior parte dei modelli richiede l'intervento di un machine learning engineer, ma i modelli di deep learning possono rilevare automaticamente tutti i tipi di pattern.
In questo tutorial esploreremo il mondo del deep learning e scopriremo tutti i concetti chiave necessari per iniziare una carriera nell'intelligenza artificiale (AI). Se vuoi imparare con esercizi pratici, dai un'occhiata al nostro corso An Introduction to Deep Learning in Python.
Concetti fondamentali del Deep Learning
Prima di addentrarci nelle complessità degli algoritmi di deep learning e delle loro applicazioni, è essenziale comprendere i concetti di base che rendono questa tecnologia così rivoluzionaria. In questa sezione conoscerai i mattoni del deep learning: reti neurali, reti neurali profonde e funzioni di attivazione.
Reti neurali
Al cuore del deep learning ci sono le reti neurali, modelli computazionali ispirati al cervello umano. Queste reti sono costituite da nodi interconnessi, o "neuroni", che lavorano insieme per elaborare informazioni e prendere decisioni. Proprio come il nostro cervello ha aree diverse per compiti diversi, una rete neurale ha strati destinati a funzioni specifiche.
Abbiamo una guida completa, Cosa sono le reti neurali, che copre gli elementi essenziali in maggiore dettaglio.
Reti neurali profonde
Ciò che rende una rete neurale "profonda" è il numero di strati tra input e output. Una rete neurale profonda ha più strati, che le permettono di imparare caratteristiche più complesse e formulare previsioni più accurate. La "profondità" di queste reti è ciò che dà il nome al deep learning e la sua capacità di risolvere problemi intricati.
Il nostro tutorial di introduzione alle reti neurali profonde spiega l'importanza delle DNN nel deep learning e nell'intelligenza artificiale.
Funzioni di attivazione
In una rete neurale, le funzioni di attivazione sono come i decisori. Determinano quali informazioni devono essere trasmesse allo strato successivo. Queste funzioni aggiungono un livello di complessità, consentendo alla rete di apprendere dai dati e prendere decisioni sfumate.
Come funziona il Deep Learning
Il deep learning utilizza l'estrazione delle feature per riconoscere caratteristiche simili dello stesso etichetta e poi usa le decision boundaries per determinare quali caratteristiche rappresentano accuratamente ciascuna etichetta. Nella classificazione cani e gatti, i modelli di deep learning estrarranno informazioni come occhi, volto e forma del corpo degli animali e li divideranno in due classi.
Un modello di deep learning è composto da reti neurali profonde. La rete neurale semplice è composta da uno strato di input, uno strato nascosto e uno strato di output. I modelli di deep learning sono costituiti da più strati nascosti e, con strati aggiuntivi, l'accuratezza del modello migliora.
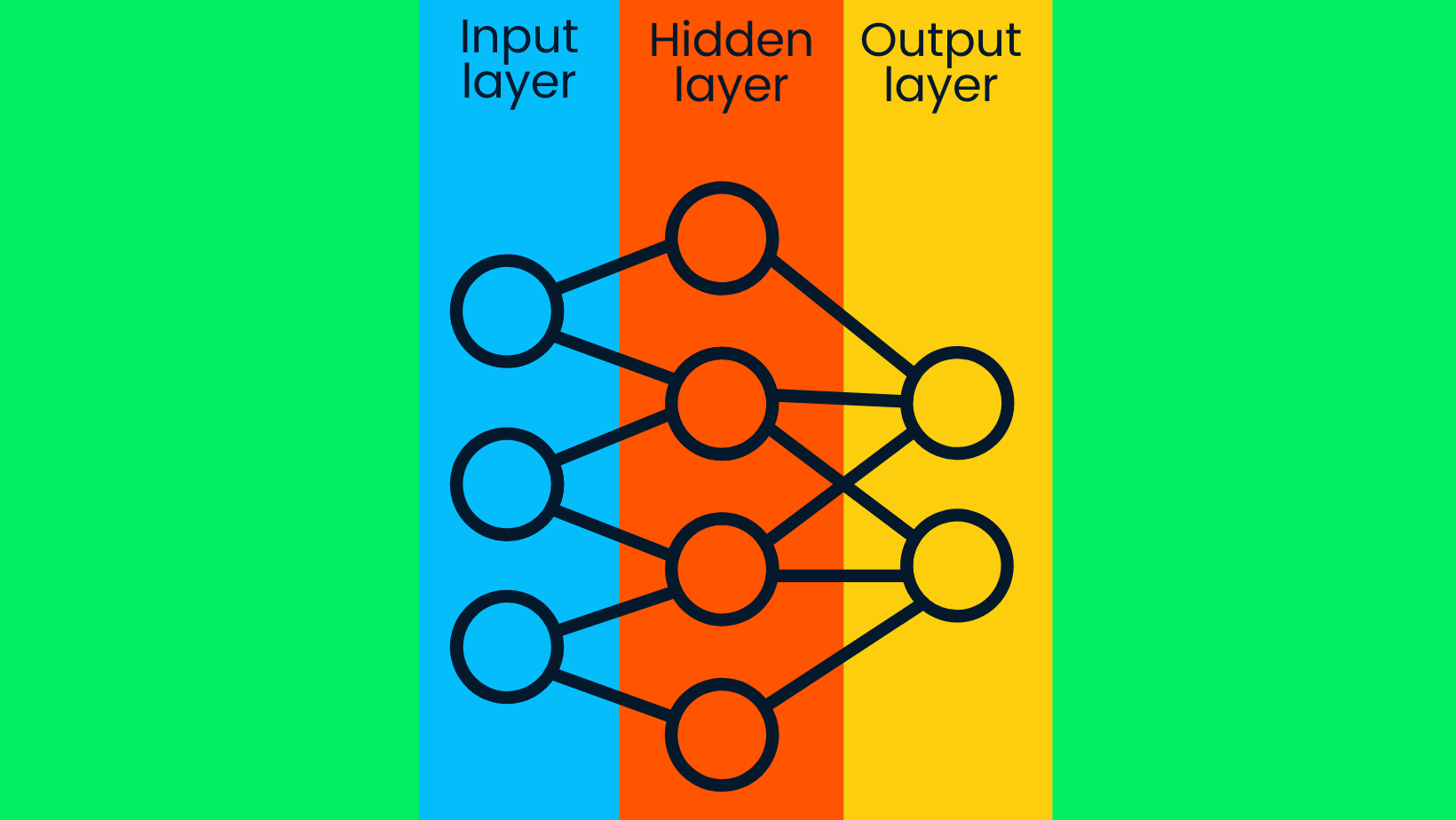 Rete neurale semplice
Rete neurale semplice
Gli strati di input contengono dati grezzi e li trasferiscono ai nodi degli strati nascosti. I nodi degli strati nascosti classificano i punti dati in base a informazioni bersaglio più ampie e, con ogni strato successivo, la portata del valore bersaglio si restringe per produrre ipotesi accurate. Lo strato di output utilizza le informazioni degli strati nascosti per selezionare l'etichetta più probabile. Nel nostro caso, prevedere con precisione l'immagine di un cane piuttosto che di un gatto.
Intelligenza artificiale vs Deep Learning
Rispondiamo a una delle domande più frequenti su internet: "Il deep learning è intelligenza artificiale?". La risposta breve è sì. Il deep learning è un sottoinsieme del machine learning, e il machine learning è un sottoinsieme dell'AI.
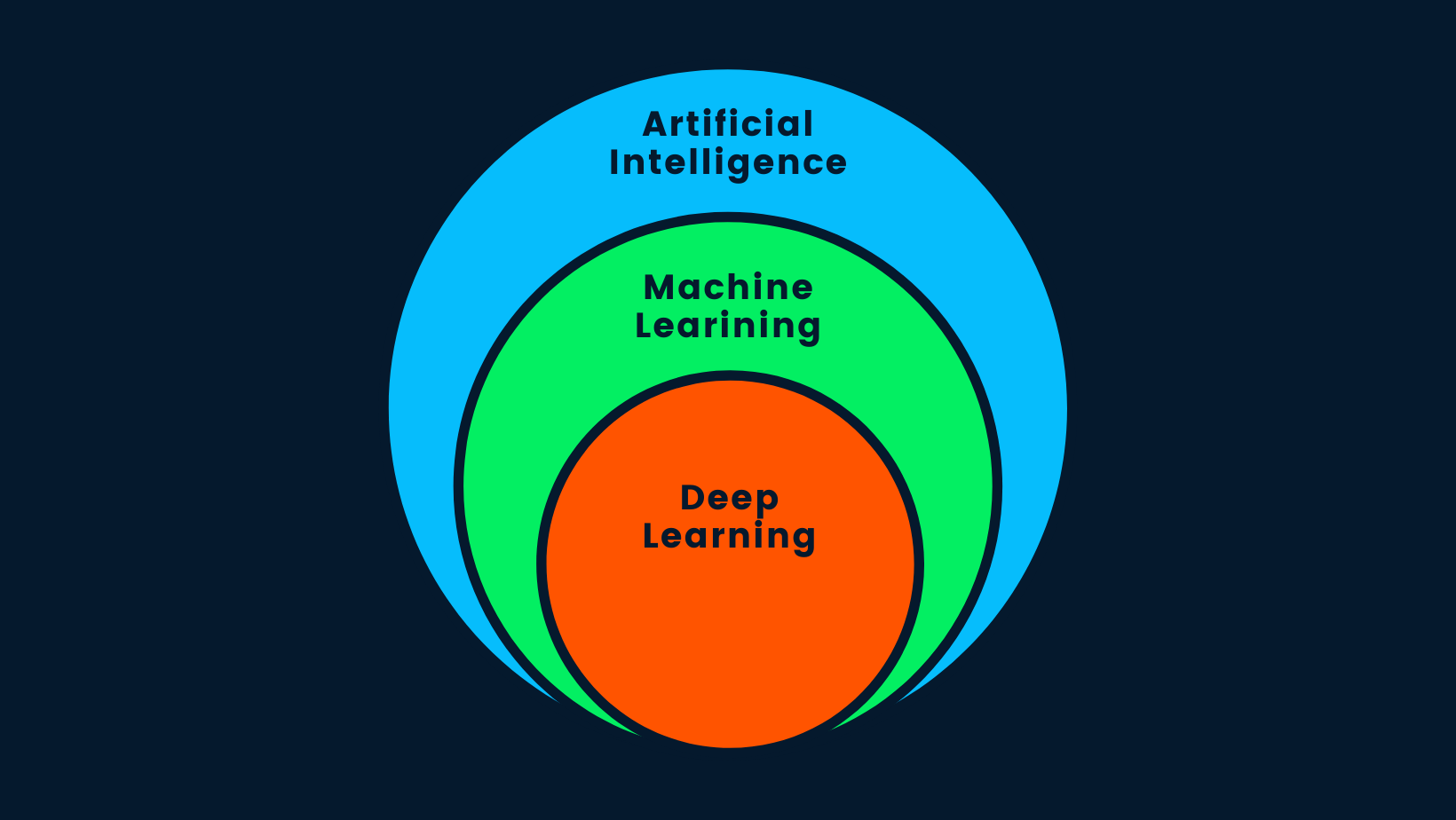 AI vs. ML vs. DL
AI vs. ML vs. DL
L'intelligenza artificiale è il concetto secondo cui è possibile costruire macchine intelligenti che imitano il comportamento umano o superano l'intelligenza umana. L'AI utilizza metodi di machine learning e deep learning per completare compiti umani. In breve, l'AI comprende il deep learning, poiché è l'algoritmo più avanzato in grado di prendere decisioni intelligenti.
A cosa serve il Deep Learning?
Di recente, il mondo della tecnologia ha visto un'esplosione di applicazioni di intelligenza artificiale, tutte alimentate da modelli di deep learning. Le applicazioni spaziano dalla raccomandazione di film su Netflix ai sistemi di gestione dei magazzini di Amazon.
In questa sezione vedremo alcune delle applicazioni più note costruite con il deep learning. Questo ti aiuterà a cogliere il pieno potenziale delle reti neurali profonde.
Computer Vision
La computer vision (CV) è utilizzata nelle auto a guida autonoma per rilevare oggetti ed evitare collisioni. È impiegata anche per il riconoscimento facciale, la stima della posa, la classificazione di immagini e il rilevamento di anomalie.
 Riconoscimento facciale
Riconoscimento facciale
Riconoscimento vocale automatico
Il riconoscimento vocale automatico (ASR) è utilizzato da miliardi di persone in tutto il mondo. È nei nostri telefoni e si attiva comunemente dicendo "Hey, Google" o "Ciao, Siri". Queste applicazioni audio sono usate anche per text-to-speech, classificazione audio e voice activity detection.
 Riconoscimento dei pattern vocali
Riconoscimento dei pattern vocali
AI generativa
L'AI generativa ha visto un'impennata della domanda quando un CryptoPunk NFT è stato venduto per 1 milione di dollari. CryptoPunk è una collezione di arte generativa creata utilizzando modelli di deep learning. L'introduzione del modello GPT-4 di OpenAI ha rivoluzionato il dominio della generazione di testo con il potente strumento ChatGPT; ora puoi insegnare ai modelli a scrivere un intero romanzo o persino a scrivere codice per i tuoi progetti di data science.
 Arte generativa
Arte generativa
Traduzione
La traduzione con deep learning non si limita alla traduzione tra lingue, poiché ora siamo in grado di tradurre foto in testo usando l'OCR, o tradurre testo in immagini usando GauGAN2 di NVIDIA.
 Traduzione linguistica
Traduzione linguistica
Previsioni su serie temporali
Le previsioni su serie temporali sono utilizzate per prevedere crolli di mercato, prezzi azionari e cambiamenti meteorologici. Il settore finanziario vive di speculazioni e proiezioni future. I modelli di deep learning e di serie temporali sono migliori degli umani nel rilevare pattern e sono quindi strumenti fondamentali in questo e in settori affini.
 Previsioni su serie temporali
Previsioni su serie temporali
Automazione
Il deep learning è usato per automatizzare compiti, ad esempio addestrare robot per la gestione dei magazzini. L'applicazione più nota è giocare ai videogiochi e migliorare nella risoluzione di enigmi. Recentemente, l'AI di Dota di OpenAI ha battuto il team professionista OG, sorprendendo il mondo poiché non ci si aspettava che tutti e cinque i bot superassero in astuzia i campioni del mondo.
 Braccio robotico alimentato dal reinforcement learning
Braccio robotico alimentato dal reinforcement learning
Feedback dei clienti
Il deep learning è utilizzato per gestire i feedback e i reclami dei clienti. È impiegato in ogni applicazione di chatbot per fornire servizi al cliente senza interruzioni.
 Feedback dei clienti
Feedback dei clienti
Biomedicina
Questo campo ha beneficiato maggiormente dell'introduzione del deep learning. Il DL è usato in biomedicina per rilevare il cancro, sviluppare farmaci stabili, rilevare anomalie nelle radiografie del torace e assistere le apparecchiature mediche.
 Analisi di sequenze di DNA
Analisi di sequenze di DNA
Modelli di Deep Learning
Vediamo i diversi tipi di modelli di deep learning e come funzionano.
Apprendimento supervisionato
L'apprendimento supervisionato utilizza un dataset etichettato per addestrare modelli a classificare i dati o prevedere valori. Il dataset contiene feature ed etichette bersaglio, che consentono all'algoritmo di imparare nel tempo minimizzando la perdita tra etichette previste e reali. L'apprendimento supervisionato può essere suddiviso in problemi di classificazione e regressione.
Classificazione
L'algoritmo di classificazione divide il dataset in varie categorie basandosi sull'estrazione delle feature. I modelli di deep learning più popolari sono ResNet50 per la classificazione di immagini e BERT (modello linguistico)) per la classificazione di testi.
 Classificazione
Classificazione
Regressione
Invece di dividere il dataset in categorie, il modello di regressione apprende la relazione tra variabili di input e di output per prevedere l'esito. I modelli di regressione sono comunemente utilizzati per analisi predittiva, previsioni meteo e previsione delle performance del mercato azionario. LSTM e RNN sono popolari modelli di regressione nel deep learning.
 Regressione lineare
Regressione lineare
Apprendimento non supervisionato
Gli algoritmi di apprendimento non supervisionato apprendono lo schema all'interno di un dataset non etichettato e creano cluster. I modelli di deep learning possono apprendere pattern nascosti senza intervento umano e sono spesso utilizzati nei motori di raccomandazione.
L'apprendimento non supervisionato è usato per raggruppare varie specie, nell'imaging medico e nella ricerca di mercato. Il modello di deep learning più comune per il clustering è l'algoritmo di deep embedded clustering.
 Clustering dei dati
Clustering dei dati
Reinforcement Learning
Il reinforcement learning (RL) è un metodo di machine learning in cui agenti apprendono diversi comportamenti dall'ambiente. L'agente compie azioni casuali e riceve ricompense. L'agente impara a raggiungere obiettivi per tentativi ed errori in un ambiente complesso senza intervento umano.
Proprio come un bimbo, incoraggiato dai genitori, impara a camminare, l'AI impara a svolgere determinati compiti massimizzando le ricompense, e il progettista definisce la politica delle ricompense. Di recente, l'RL ha visto una forte richiesta nell'automazione grazie ai progressi nella robotica, nelle auto a guida autonoma, nel battere giocatori professionisti nei giochi e nel far atterrare i razzi di nuovo sulla Terra.
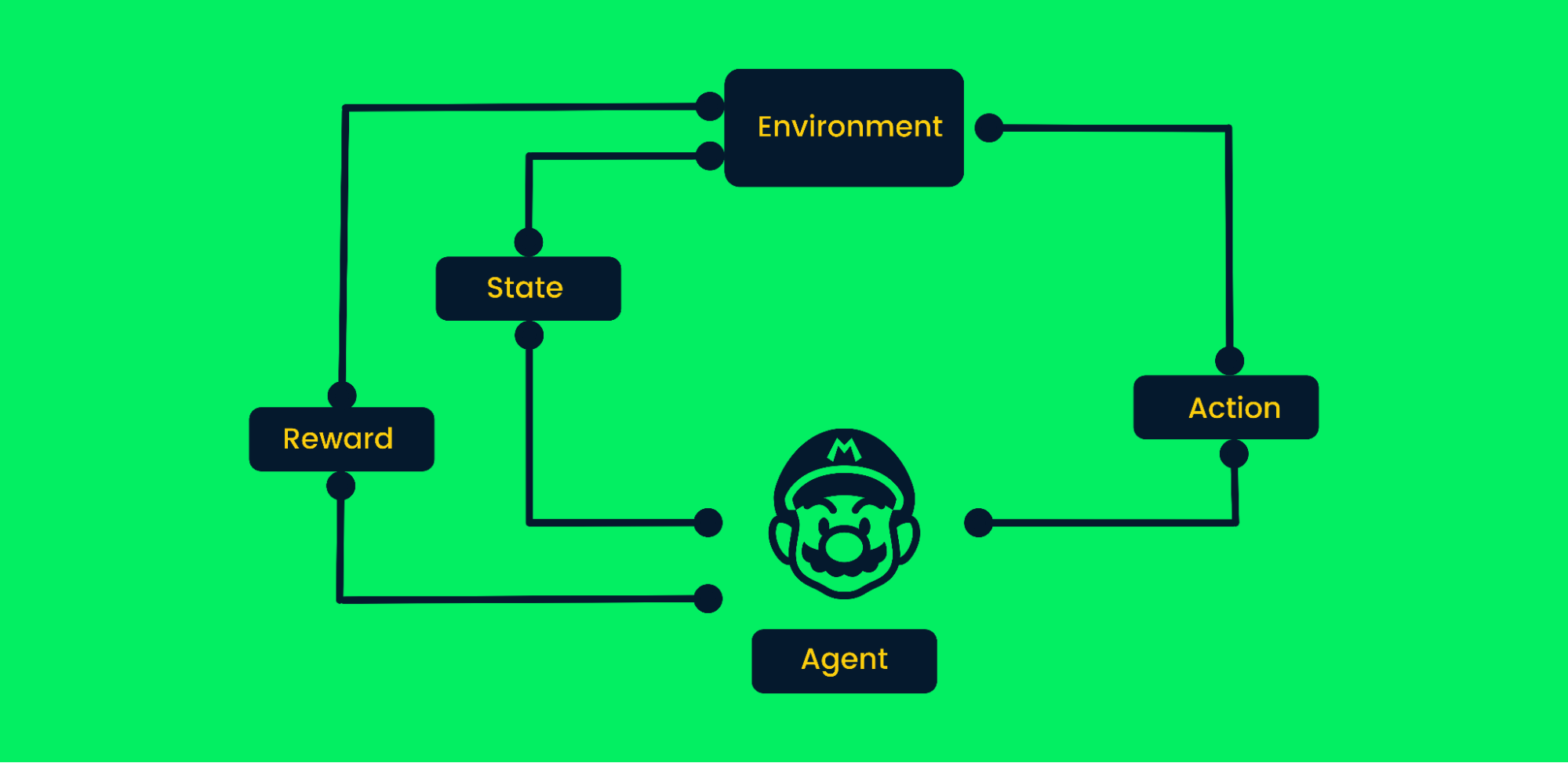 Framework di Reinforcement Learning
Framework di Reinforcement Learning
Prendiamo come esempio il videogioco di Mario:
- All'inizio, l'agente (personaggio di Mario) riceve lo stato zero dall'ambiente.
- In base allo stato, un agente intraprende un'azione; nel nostro caso, Mario si è mosso a destra.
- Ora lo stato è cambiato e il personaggio si trova in un nuovo frame.
- L'agente riceve una ricompensa, poiché muovendosi a destra il personaggio non è morto. Il nostro obiettivo principale è massimizzare le ricompense.
L'agente continuerà il ciclo di azioni e massimizzazione delle ricompense finché non raggiungerà la fine del livello o morirà. Scopri di più in An Introduction to Reinforcement Learning.
Generative Adversarial Networks
Le Generative adversarial networks (GAN) utilizzano due reti neurali che, insieme, producono istanze sintetiche dei dati originali. Le GAN hanno guadagnato molta popolarità negli ultimi anni poiché sono in grado di imitare alcuni grandi artisti per produrre capolavori. Sono ampiamente utilizzate per generare arte, video, musica e testi sintetici. Scopri di più sulle applicazioni reali nel tutorial sulle Generative Adversarial Networks.
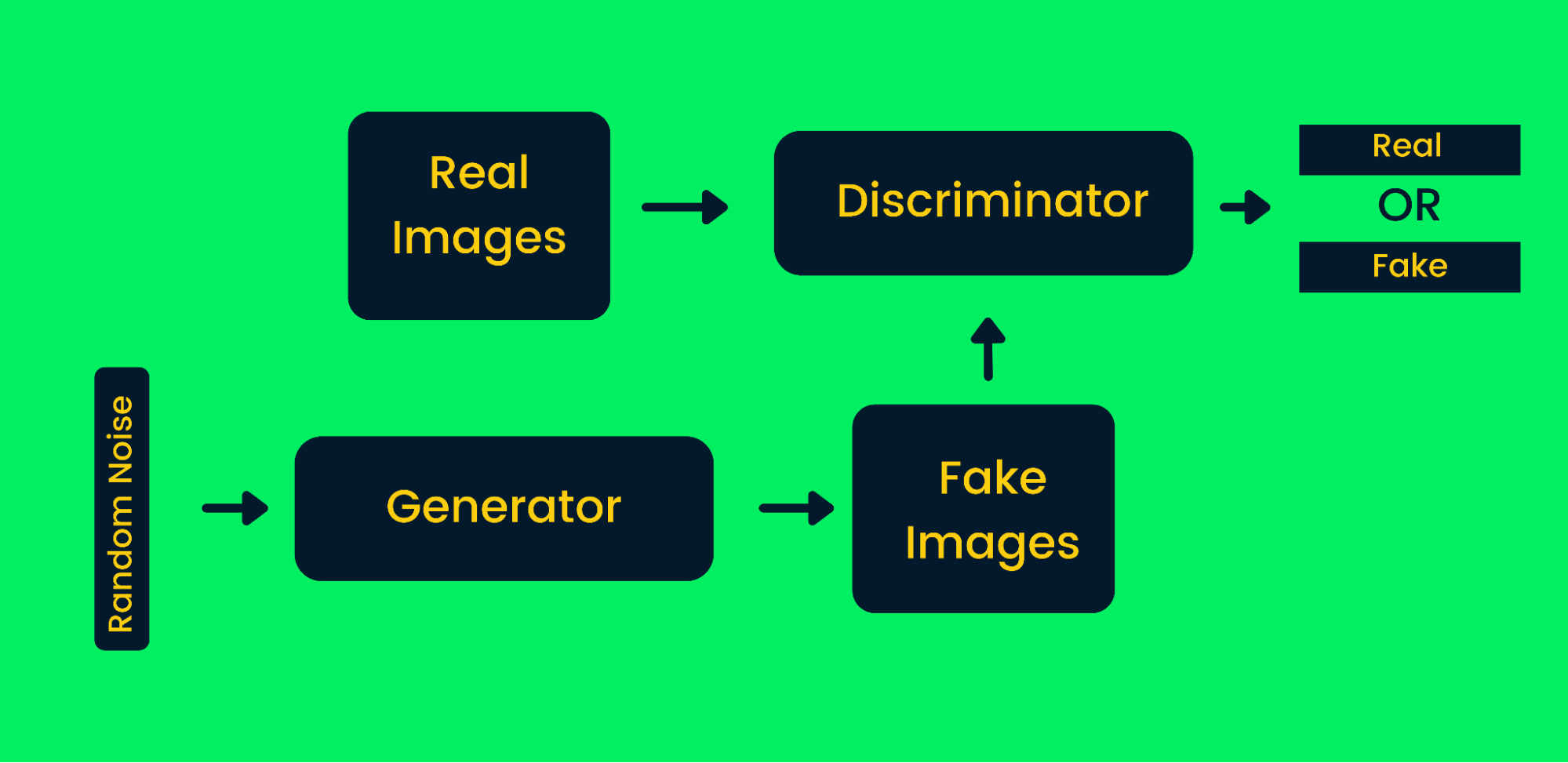 Framework delle Generative Adversarial Network
Framework delle Generative Adversarial Network
Come funzionano le GAN nella generazione di immagini sintetiche:
- Per prima cosa, le reti del generatore prendono in input rumore casuale e generano immagini false.
- Le immagini generate e quelle reali vengono fornite al discriminatore.
- Il discriminatore decide se l'immagine generata è reale o meno. Restituisce probabilità da zero a uno, dove zero rappresenta un'immagine falsa e uno rappresenta un'immagine autentica. Le architetture GAN contengono due cicli di feedback. Il discriminatore è in un ciclo di feedback con immagini reali, mentre il generatore è in un ciclo di feedback con il discriminatore. Lavorano in sincronia per produrre immagini più autentiche.
Graph Neural Network
Un grafo è una struttura dati composta da archi e vertici. Gli archi possono essere direzionati se esistono dipendenze direzionali tra i vertici (nodi), noti anche come grafi diretti. I cerchi verdi nel diagramma qui sotto sono nodi e le frecce rappresentano gli archi.
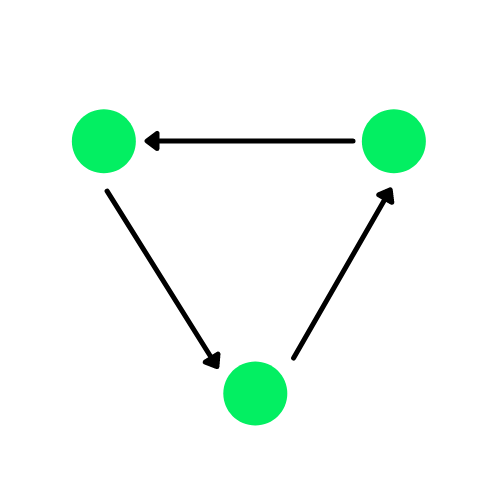
Un grafo diretto
Una graph neural network (GNN) è un tipo di architettura di deep learning che opera direttamente su strutture a grafo. Le GNN sono applicate nell'analisi di grandi dataset, nei sistemi di raccomandazione e nella computer vision.
 Una rete a grafo
Una rete a grafo
Vengono utilizzate anche per la classificazione dei nodi, la previsione dei collegamenti e il clustering. In alcuni casi, le graph neural network hanno ottenuto risultati migliori delle convolutional neural network, ad esempio nel riconoscere oggetti e prevedere relazioni semantiche.
Elaborazione del linguaggio naturale
Il natural language processing (NLP) utilizza la tecnologia di deep learning per aiutare i computer a imparare una lingua umana naturale. L'NLP utilizza il deep learning per leggere, decifrare e comprendere il linguaggio umano. È ampiamente usato per l'elaborazione di voce, testo e immagini. L'introduzione del transfer learning ha portato l'NLP al livello successivo, poiché possiamo fare fine-tuning del modello con pochi campioni e raggiungere prestazioni all'avanguardia.
 Sottocategorie dell'NLP
Sottocategorie dell'NLP
L'NLP può essere suddiviso in più campi:
- Traduzione: traduzione di lingue, strutture molecolari ed equazioni matematiche
- Riassunto: sintetizzare grandi blocchi di testo in poche righe mantenendo le informazioni chiave.
- Classificazione: suddividere il testo in varie categorie.
- Generazione: generazione testo-su-testo; può essere usata per generare interi saggi con una sola riga di testo.
- Conversazionale: assistente virtuale, conservando la memoria delle conversazioni passate e imitando le conversazioni umane.
- Risposta a domande: l'AI risponde alle domande utilizzando dati di Q&A.
- Estrazione di feature: rilevare pattern nel testo o estrarre informazioni come "named entity recognition" e "part-of-speech".
- Similarità tra frasi: valutare le somiglianze tra testi diversi.
- Text to speech: conversione del testo in parlato udibile.
- Riconoscimento vocale automatico: comprendere vari suoni e convertirli in testo.
- Riconoscimento ottico dei caratteri: estrazione di testo dalle immagini.
Se vuoi provare tutte le varie applicazioni dell'NLP, prova gli Hugging Face Spaces. Gli Spaces ospitano tutti i tipi di applicazioni web con cui puoi sperimentare per trovare ispirazione per il tuo progetto NLP.
Uno sguardo più approfondito ai concetti di Deep Learning
Funzioni di attivazione
Nelle reti neurali, la funzione di attivazione produce confini decisionali in output ed è utilizzata per migliorare le prestazioni del modello. La funzione di attivazione è un'espressione matematica che decide se l'input debba passare attraverso un neurone oppure no, in base alla sua rilevanza. Fornisce inoltre non linearità alle reti. Senza una funzione di attivazione, la rete neurale diventa un semplice modello di regressione lineare.
Esistono diversi tipi di funzioni di attivazione:
- Tanh
- ReLU
- Sigmoid
- Linear
- Softmax
- Swish
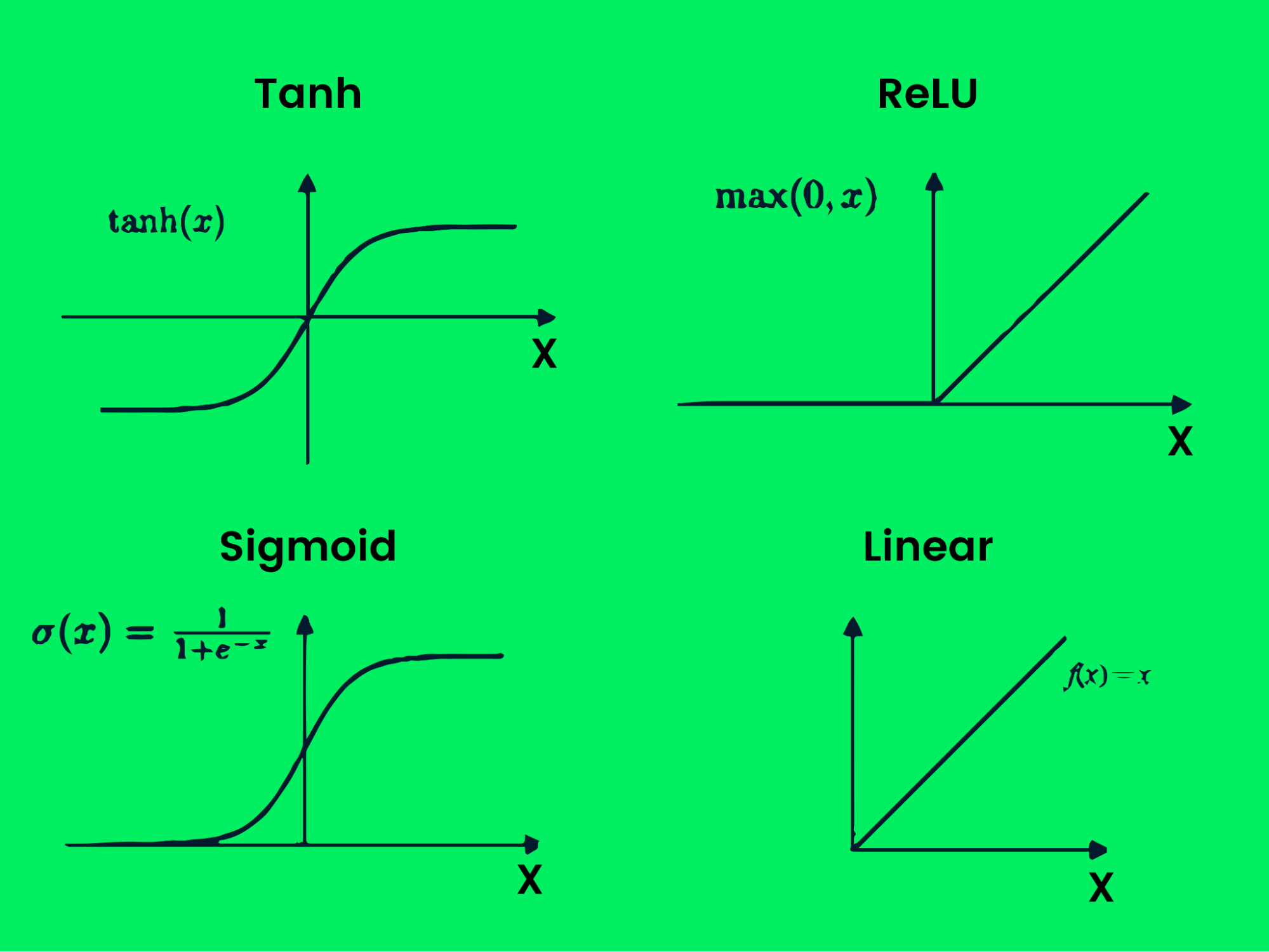 Funzione di attivazione
Funzione di attivazione
Queste funzioni producono vari confini di output, come mostrato nell'immagine sopra. Con più strati e funzioni di attivazione, puoi risolvere qualsiasi problema complesso. Scopri di più su cosa sono le funzioni di attivazione nel deep learning?
Funzione di perdita
La funzione di perdita è la differenza tra valori reali e previsti. Permette alle reti neurali di monitorare le prestazioni complessive del modello. A seconda dei problemi specifici, scegliamo un certo tipo di funzione, ad esempio l'errore quadratico medio.
Loss = Somma (Predetto - Reale)²
Le funzioni di perdita più utilizzate nel deep learning sono:
- Binary cross-entropy
- Categorical hinge
- Mean squared error
- Huber
- Sparse categorical cross-entropy
Backpropagation
Nella propagazione in avanti, inizializziamo la nostra rete neurale con input casuali per produrre un output anch'esso casuale. Per migliorare le prestazioni del modello, regoliamo i pesi in modo iterativo usando la backpropagation. Per monitorare le prestazioni del modello, abbiamo bisogno di una funzione di perdita che trovi il minimo globale per massimizzare l'accuratezza del modello.
Discesa del gradiente stocastica
La discesa del gradiente è utilizzata per ottimizzare la funzione di perdita cambiando i pesi in modo controllato per ottenere una perdita minima. Ora abbiamo un obiettivo, ma ci serve una direzione su come aumentare o diminuire i pesi per ottenere prestazioni migliori. La derivata della funzione di perdita ci fornirà la direzione e potremo usarla per aggiornare i pesi della rete.
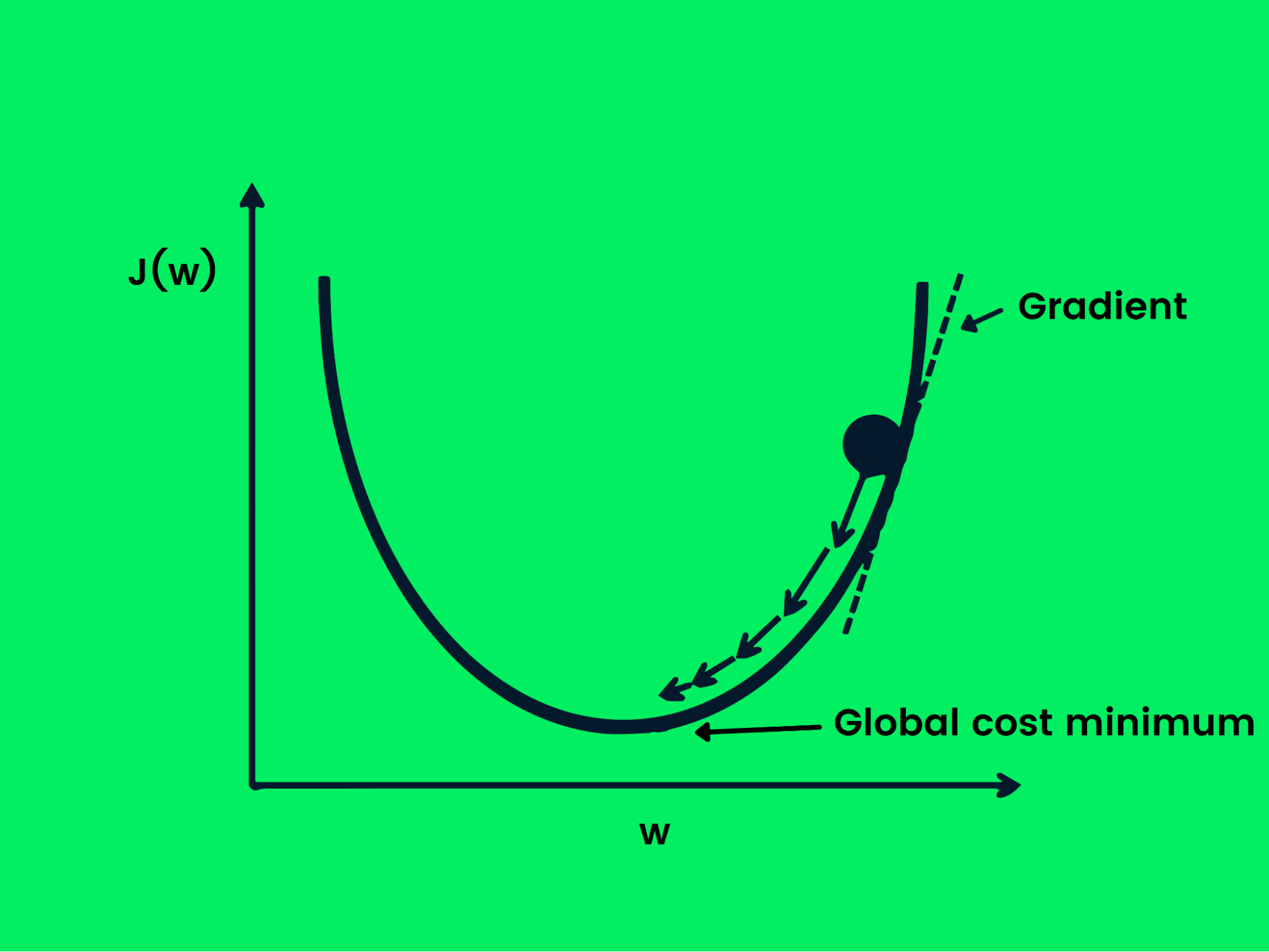 Discesa del gradiente
Discesa del gradiente
L'equazione seguente mostra come si aggiornano i pesi usando la discesa del gradiente.
w = w -Jw
Nella discesa del gradiente stocastica, i campioni sono suddivisi in batch invece di usare l'intero dataset per ottimizzare la discesa del gradiente. Questo è utile se vuoi raggiungere più velocemente la perdita minima e ottimizzare la potenza di calcolo.
Iperparametri
Gli iperparametri sono parametri regolabili impostati prima di avviare il processo di training. Questi parametri influenzano direttamente le prestazioni del modello e aiutano a raggiungere più rapidamente il minimo globale.
Elenco degli iperparametri più usati:
- Learning rate: dimensione del passo di ogni iterazione e può essere impostata da 0,1 a 0,0001. In breve, determina la velocità con cui il modello apprende.
- Batch size: numero di campioni che passano attraverso una rete neurale alla volta.
- Numero di epoche: quante volte il modello aggiorna i pesi. Troppe epoche possono causare overfitting e troppo poche underfitting, quindi dobbiamo scegliere un numero intermedio.
Per saperne di più su come questi componenti lavorano insieme, segui Keras Tutorial: Deep Learning in Python.
Algoritmi popolari
Convolutional Neural Networks
La convolutional neural network (CNN) è una rete neurale feed-forward in grado di elaborare una matrice strutturata di dati. È ampiamente utilizzata per applicazioni di computer vision, come la classificazione di immagini.
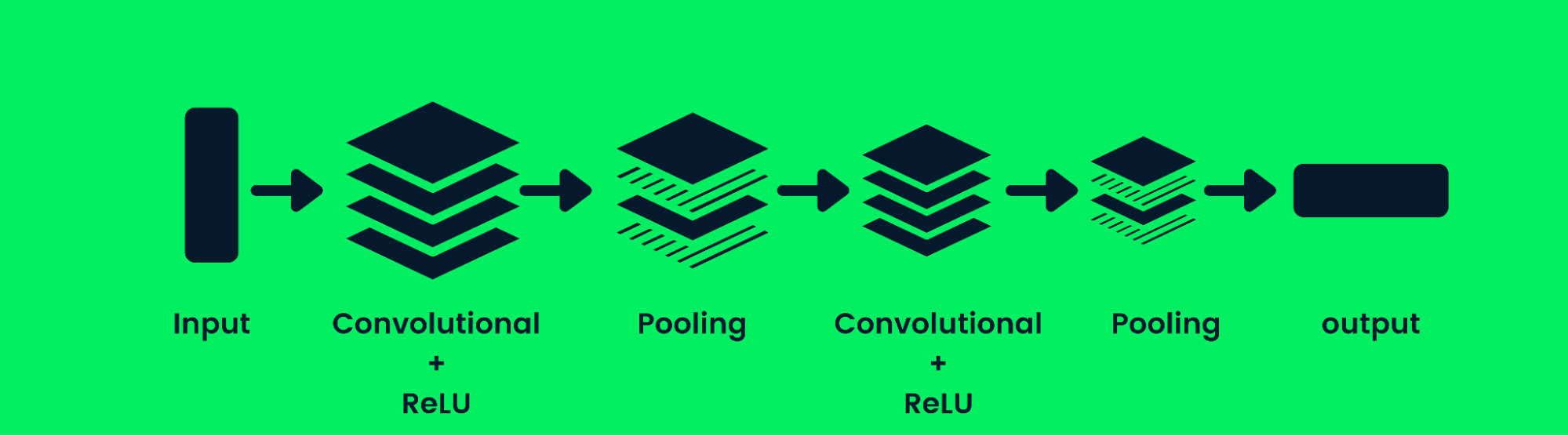 Architettura di una Convolutional Neural Network
Architettura di una Convolutional Neural Network
Le CNN sono brave a riconoscere pattern, linee e forme. Una CNN è composta da uno strato di convoluzione, uno strato di pooling e uno strato di output (strati completamente connessi). I modelli di classificazione di immagini solitamente contengono più strati di convoluzione seguiti da strati di pooling, poiché strati aggiuntivi aumentano l'accuratezza del modello. Scopri di più sugli strati di convoluzione qui: Convolutional Neural Networks in Python.
Recurrent Neural Networks
Le recurrent neural network (RNN) sono diverse dalle reti feed-forward perché l'output dello strato viene reintrodotto in input per prevedere l'output dello strato successivo. Questo le aiuta a performare meglio con dati sequenziali, poiché possono memorizzare le informazioni dei campioni precedenti per prevedere quelli futuri. Scopri di più nel tutorial sulle Recurrent Neural Network (RNN): Tipi ed esempi.
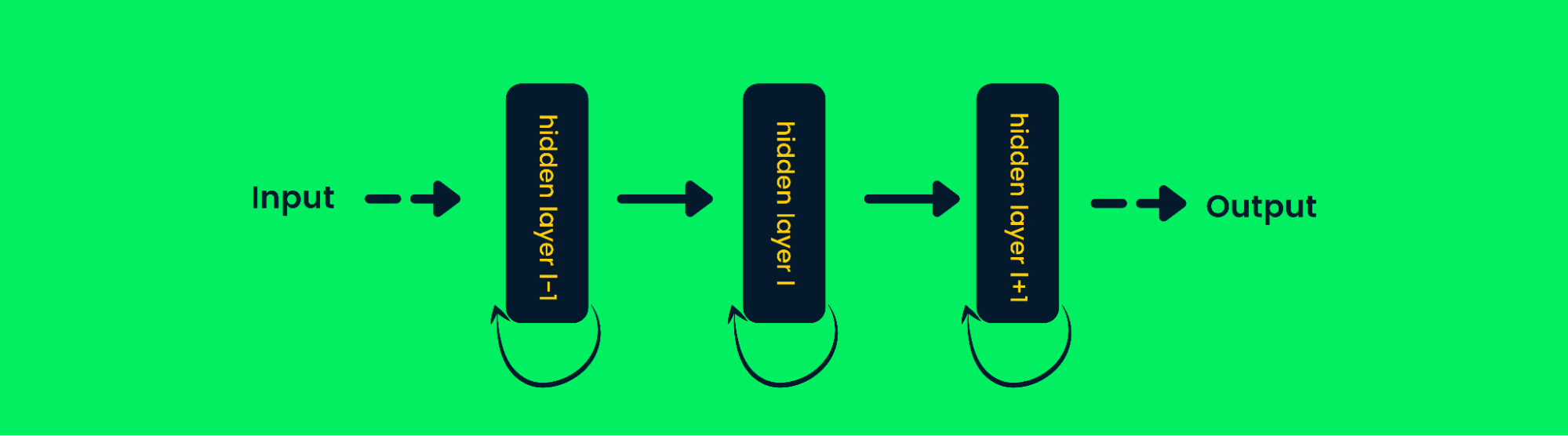 Architettura di una Recurrent Neural Network
Architettura di una Recurrent Neural Network
Nelle reti neurali tradizionali, l'output degli strati è calcolato in base ai valori di input correnti, ma nelle RNN l'output è calcolato anche in base agli input precedenti. Questo le rende molto efficaci nel prevedere la parola successiva, nel prevedere i prezzi azionari, nei chatbot di AI e nel rilevamento di anomalie.
Long Short-term Memory Networks
Le long short-term memory network (LSTM) sono tipi avanzati di reti neurali ricorrenti che possono trattenere più informazioni sui valori passati. Risolvono i problemi di vanishing gradient presenti nelle semplici RNN.
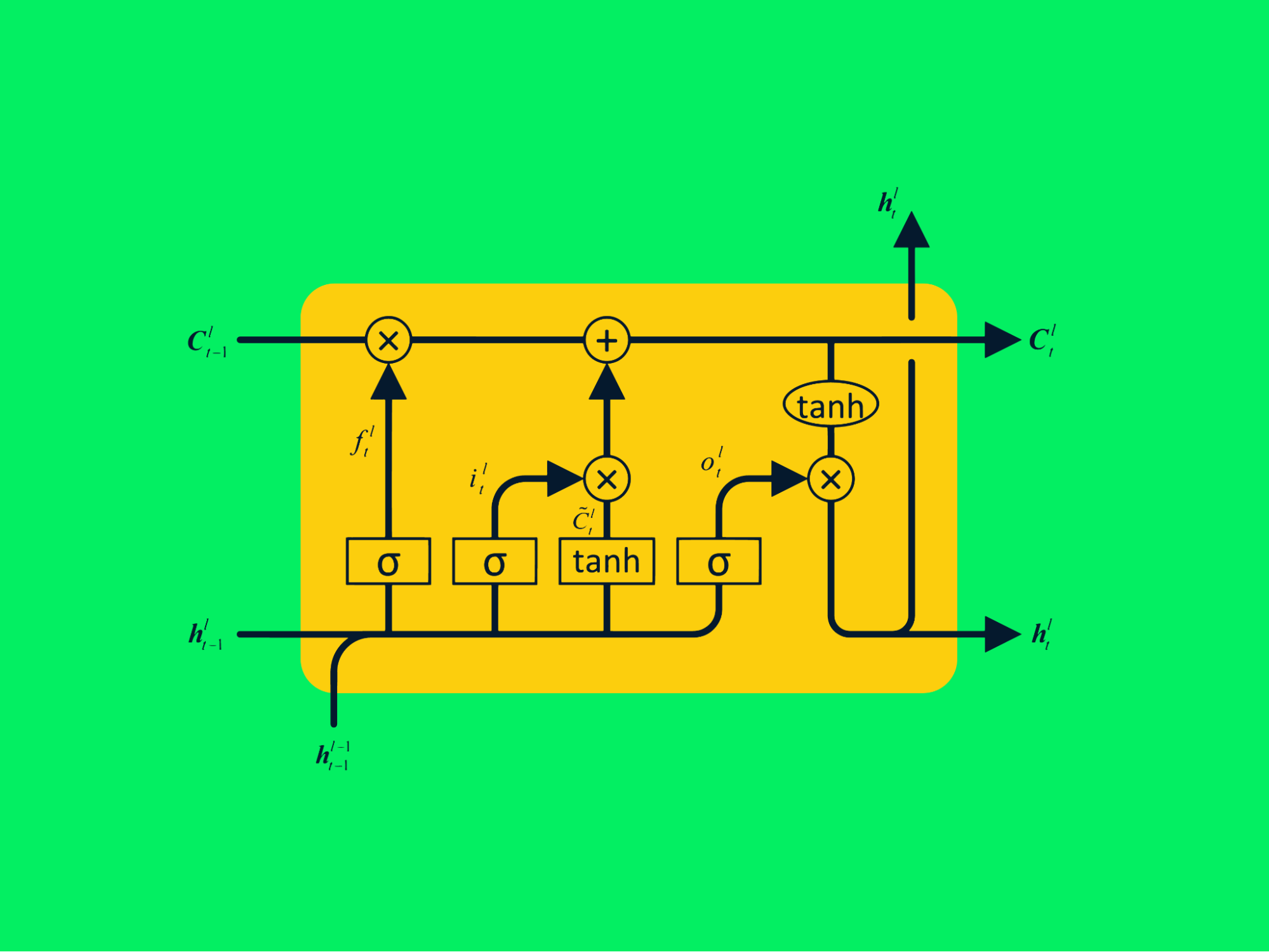 Architettura LSTM
Architettura LSTM
Una RNN tipica è composta da reti neurali ripetute con un singolo strato tanh, mentre una LSTM è composta da quattro strati interattivi che comunicano per elaborare lunghe sequenze di dati.
Puoi fare pratica con il Tutorial: LSTM per previsioni azionarie o con il corso advanced deep learning with Keras se vuoi approfondire i modelli di deep learning.
Framework di Deep Learning
Esistono diversi framework di deep learning, come MxNet, CNTK e Caffe2, ma vedremo i più popolari.
Tensorflow
Tensorflow (TF) è una libreria open source utilizzata per creare applicazioni di deep learning. Include tutti gli strumenti necessari per sperimentare e sviluppare prodotti di AI commerciali. Supporta CPU, GPU e TPU per l'addestramento di modelli complessi. TF è stato originariamente sviluppato dal team Google AI per uso interno ed è ora disponibile al pubblico.
L'API di Tensorflow è disponibile per applicazioni basate su browser, dispositivi mobili e TensorFlow Extended è ideale per la produzione. TF è ormai diventato lo standard del settore ed è utilizzato sia per la ricerca accademica sia per il deploy di modelli di deep learning in produzione.
TF include anche Tensorboard, una dashboard in grado di analizzare i tuoi esperimenti di machine learning. Recentemente, gli sviluppatori di Tensorflow hanno integrato Keras nel framework, molto popolare per lo sviluppo di reti neurali profonde. Scopri di più nel corso Introduction to TensorFlow in Python.
Keras
Keras è un framework per reti neurali scritto in Python e in grado di funzionare su più framework, come Tensorflow e Theano. Keras è una libreria open source sviluppata per abilitare una sperimentazione rapida nel deep learning, così da poter trasformare facilmente i tuoi concetti in applicazioni di AI funzionanti.
La documentazione è piuttosto facile da comprendere e l'API è simile a Numpy, il che consente di integrarla facilmente in qualsiasi progetto di data science. Come TF, anche Keras può essere eseguito su CPU, GPU e TPU, a seconda dell'hardware disponibile. Scopri di più in Introduction to Deep Learning with Keras.
PyTorch
PyTorch è il framework di deep learning più popolare e semplice da usare. Utilizza tensori invece di array Numpy per eseguire calcoli numerici rapidi grazie alla GPU. PyTorch è usato principalmente per il deep learning e per sviluppare modelli di machine learning complessi.
I ricercatori accademici preferiscono usare PyTorch per la sua flessibilità e facilità d'uso. È scritto in C++ e Python e supporta anche l'accelerazione con GPU e TPU. È diventato una soluzione completa per tutti i problemi di deep learning. Se vuoi saperne di più su PyTorch, prova il corso Introduction to Deep Learning with PyTorch.
Conclusione
In questo tutorial abbiamo visto che cos'è il deep learning, alcune basi del deep learning, come funziona e le sue applicazioni. Abbiamo anche imparato come funzionano le reti neurali profonde e i diversi tipi di modelli di deep learning. Infine, hai conosciuto alcuni framework popolari per il deep learning.
Questo tutorial ti ha fornito tutte le informazioni chiave necessarie per iniziare nel campo del deep learning. Per proseguire nell'apprendimento, il Deep Learning in Python Track ti preparerà a lavorare su progetti reali. Se ti trovi a tuo agio con il linguaggio R, puoi dare un'occhiata anche a deep learning con Keras in R.


