O que é aprendizagem profunda?
A aprendizagem profunda é um tipo de aprendizado de máquina que ensina os computadores a executar tarefas aprendendo com exemplos, como fazem os humanos. Imagine ensinar um computador a reconhecer gatos: em vez de dizer a ele para procurar bigodes, orelhas e uma cauda, você mostra a ele milhares de fotos de gatos. O computador encontra os padrões comuns por si só e aprende a identificar um gato. Essa é a essência da aprendizagem profunda.
Em termos técnicos, a aprendizagem profunda usa algo chamado "redes neurais", que são inspiradas no cérebro humano. Essas redes consistem em camadas de nós interconectados que processam informações. Quanto mais camadas, mais "profunda" é a rede, permitindo que ela aprenda recursos mais complexos e execute tarefas mais sofisticadas.
A semelhança entre neurônios e redes neurais
A evolução da aprendizagem automática para a aprendizagem profunda
O que é aprendizado de máquina?
O aprendizado de máquina é um subconjunto da inteligência artificial (IA) que permite que os computadores aprendam com os dados e tomem decisões sem programação explícita. Ele abrange várias técnicas e algoritmos que permitem que os sistemas reconheçam padrões, façam previsões e melhorem o desempenho ao longo do tempo. Você pode explorar a diferença entre aprendizado de máquina e IA em um artigo separado.
Como a aprendizagem profunda difere da aprendizagem de máquina tradicional
Embora o aprendizado de máquina tenha sido uma tecnologia transformadora por si só, o aprendizado profundo dá um passo adiante, automatizando muitas das tarefas que normalmente exigem conhecimento humano.
A aprendizagem profunda é essencialmente um subconjunto especializado da aprendizagem automática, que se distingue pelo uso de redes neurais com três ou mais camadas. Essas redes neurais tentam simular o comportamento do cérebro humano - embora longe de corresponder à sua capacidade - para "aprender" com grandes quantidades de dados. Você pode explorar a aprendizagem automática versus a aprendizagem profunda com mais detalhes em um post separado.
A importância da engenharia de recursos
A engenharia de recursos é o processo de selecionar, transformar ou criar as variáveis mais relevantes, conhecidas como "recursos", a partir de dados brutos para uso em modelos de aprendizado de máquina.
Por exemplo, se você estiver criando um modelo de previsão do tempo, os dados brutos podem incluir temperatura, umidade, velocidade do vento e pressão barométrica. A engenharia de recursos envolveria determinar quais dessas variáveis são mais importantes para prever o clima e possivelmente transformá-las (por exemplo, converter a temperatura de Fahrenheit para Celsius) para torná-las mais úteis para o modelo.
No aprendizado de máquina tradicional, a engenharia de recursos costuma ser um processo manual e demorado que exige conhecimento especializado no domínio. No entanto, uma das vantagens da aprendizagem profunda é que ela pode aprender automaticamente os recursos relevantes dos dados brutos, reduzindo a necessidade de intervenção manual.
Por que a aprendizagem profunda é importante?
Os motivos pelos quais a aprendizagem profunda se tornou o padrão do setor:
- Manuseio de dados não estruturados: Os modelos treinados em dados estruturados podem aprender facilmente com dados não estruturados, o que reduz o tempo e os recursos na padronização de conjuntos de dados.
- Manuseio de dados grandes: Devido à introdução das unidades de processamento gráfico (GPUs), os modelos de aprendizagem profunda podem processar grandes quantidades de dados na velocidade da luz.
- Alta precisão: Os modelos de aprendizagem profunda fornecem os resultados mais precisos em visões de computador, processamento de linguagem natural (NLP) e processamento de áudio.
- Reconhecimento de padrões: A maioria dos modelos exige a intervenção do engenheiro de aprendizado de máquina, mas os modelos de aprendizado profundo podem detectar todos os tipos de padrões automaticamente.
Neste tutorial, vamos mergulhar no mundo da aprendizagem profunda e descobrir todos os principais conceitos necessários para você começar uma carreira em inteligência artificial (IA). Se você deseja aprender com alguns exercícios práticos, confira nosso curso, Uma introdução à aprendizagem profunda em Python.
Conceitos básicos da aprendizagem profunda
Antes de mergulhar nas complexidades dos algoritmos de aprendizagem profunda e suas aplicações, é essencial entender os conceitos fundamentais que tornam essa tecnologia tão revolucionária. Esta seção apresentará a você os blocos de construção da aprendizagem profunda: redes neurais, redes neurais profundas e funções de ativação.
Redes neurais
No centro da aprendizagem profunda estão as redes neurais, que são modelos computacionais inspirados no cérebro humano. Essas redes consistem em nós interconectados, ou "neurônios", que trabalham juntos para processar informações e tomar decisões. Assim como nosso cérebro tem regiões diferentes para tarefas diferentes, uma rede neural tem camadas designadas para funções específicas.
Temos um guia completo, What are Neural Networks (O que são redes neurais), que aborda os aspectos essenciais com mais detalhes.
Redes neurais profundas
O que torna uma rede neural "profunda" é o número de camadas que ela tem entre a entrada e a saída. Uma rede neural profunda tem várias camadas, o que permite que ela aprenda recursos mais complexos e faça previsões mais precisas. A "profundidade" dessas redes é o que dá o nome à aprendizagem profunda e sua capacidade de resolver problemas complexos.
Nosso tutorial de introdução às redes neurais profundas aborda a importância das DNNs na aprendizagem profunda e na inteligência artificial.
Funções de ativação
Em uma rede neural, as funções de ativação são como os tomadores de decisão. Eles determinam quais informações devem ser passadas para a próxima camada. Essas funções adicionam um nível de complexidade, permitindo que a rede aprenda com os dados e tome decisões diferenciadas.
Como funciona a aprendizagem profunda
A aprendizagem profunda usa a extração de recursos para reconhecer recursos semelhantes do mesmo rótulo e, em seguida, usa limites de decisão para determinar quais recursos representam com precisão cada rótulo. Na classificação de cães e gatos, os modelos de aprendizagem profunda extrairão informações como os olhos, o rosto e o formato do corpo dos animais e os dividirão em duas classes.
O modelo de aprendizagem profunda consiste em redes neurais profundas. A rede neural simples consiste em uma camada de entrada, uma camada oculta e uma camada de saída. Os modelos de aprendizagem profunda consistem em várias camadas ocultas, com camadas adicionais que melhoram a precisão do modelo.
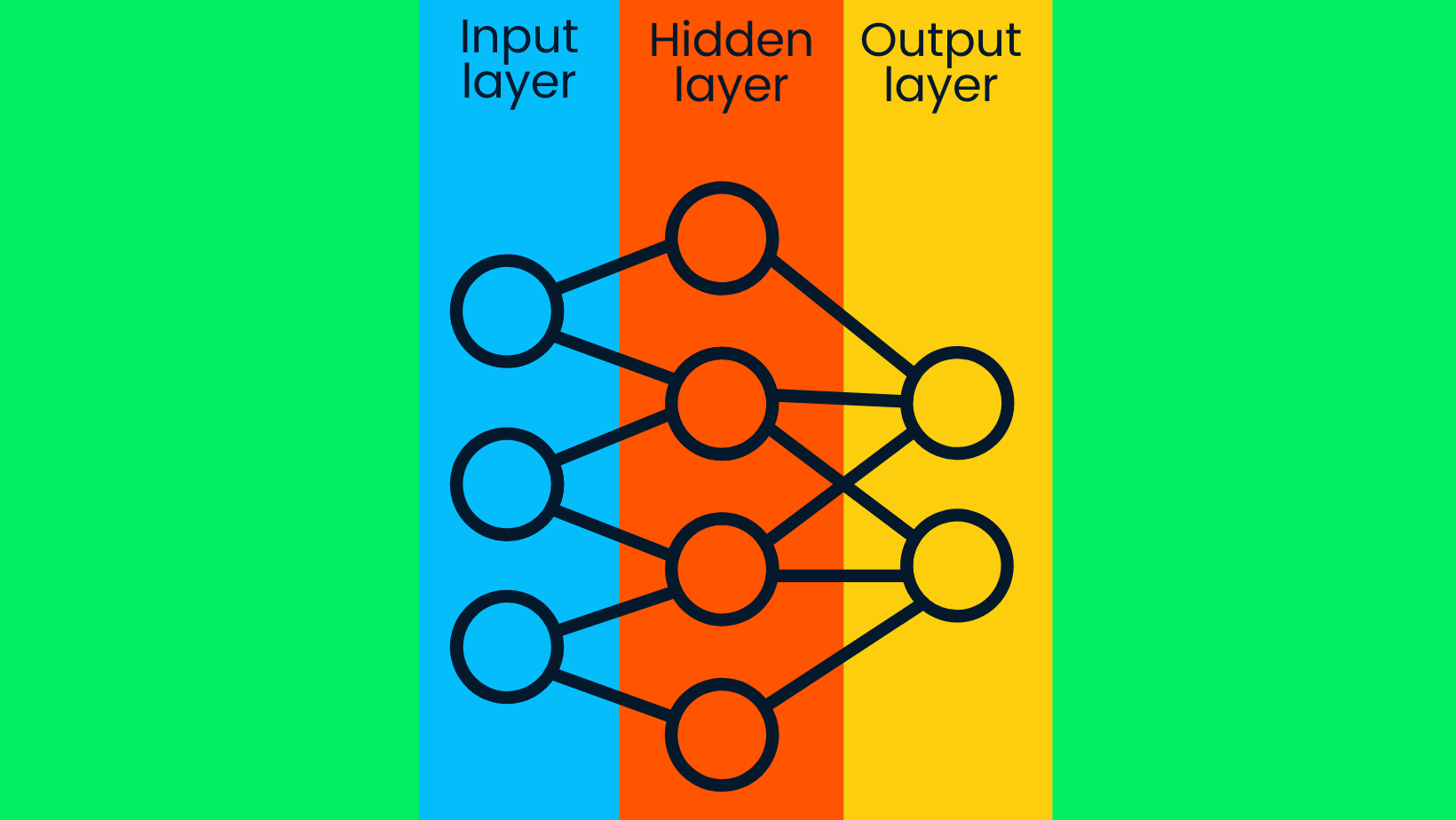 Rede neural simples
Rede neural simples
As camadas de entrada contêm dados brutos e transferem os dados para os nós das camadas ocultas. Os nós das camadas ocultas classificam os pontos de dados com base nas informações de destino mais amplas e, a cada camada subsequente, o escopo do valor de destino é reduzido para produzir suposições precisas. A camada de saída usa as informações da camada oculta para selecionar o rótulo mais provável. No nosso caso, prever com precisão a imagem de um cachorro em vez da de um gato.
Inteligência Artificial vs. Aprendizagem profunda
Vamos responder a uma das perguntas mais frequentes na Internet: "A aprendizagem profunda é inteligência artificial?". A resposta curta é sim. A aprendizagem profunda é um subconjunto da aprendizagem automática, e a aprendizagem automática é um subconjunto da IA.
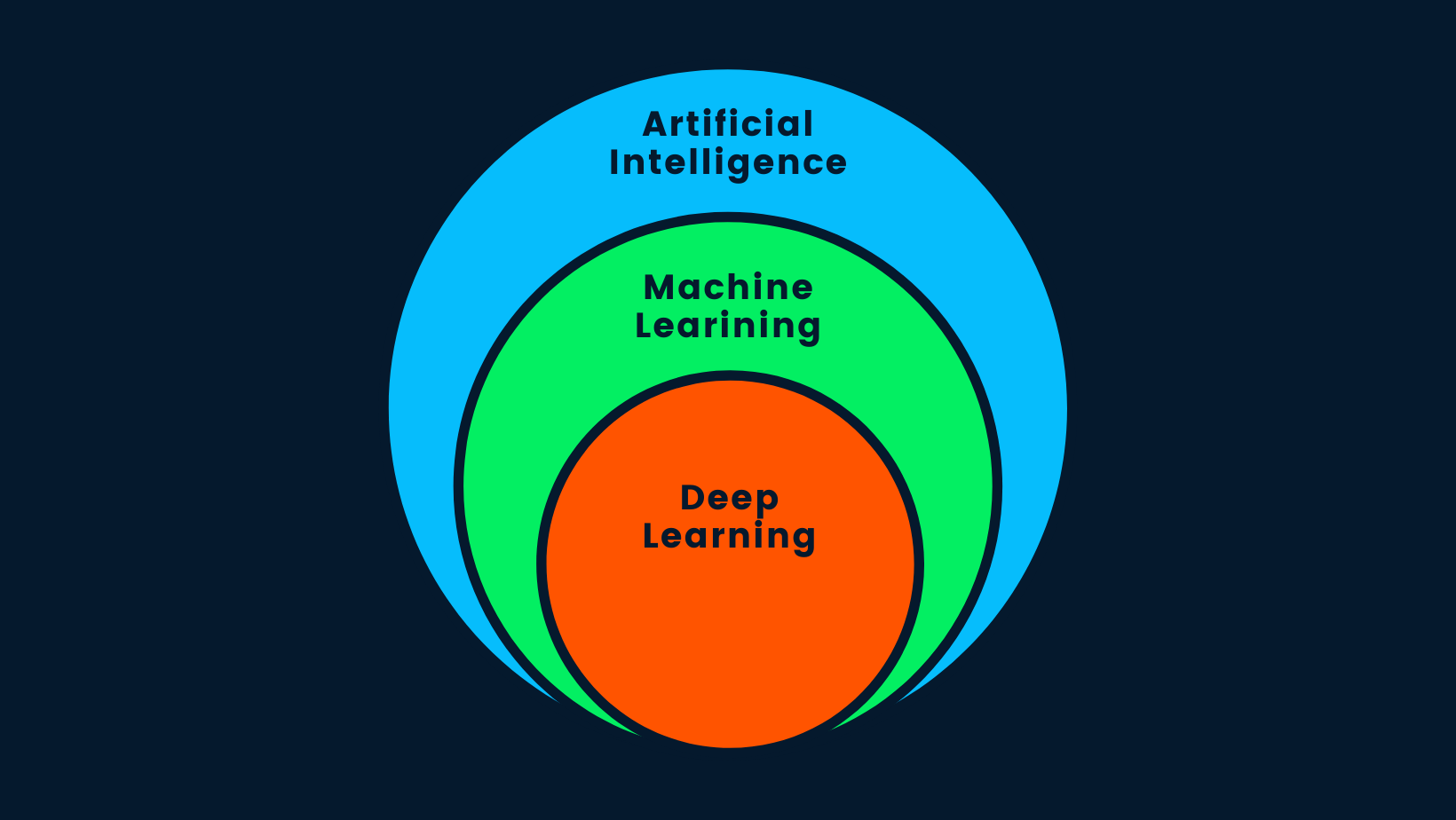 IA vs. DL ML vs. DL
IA vs. DL ML vs. DL
A inteligência artificial é o conceito de que máquinas inteligentes podem ser construídas para imitar o comportamento humano ou superar a inteligência humana. A IA usa métodos de aprendizado de máquina e aprendizado profundo para realizar tarefas humanas. Em resumo, a IA é a aprendizagem profunda, pois é o algoritmo mais avançado capaz de tomar decisões inteligentes.
Para que é usada a aprendizagem profunda?
Recentemente, o mundo da tecnologia tem visto um aumento nos aplicativos de inteligência artificial, e todos eles são alimentados por modelos de aprendizagem profunda. Os aplicativos vão desde a recomendação de filmes na Netflix até os sistemas de gerenciamento de armazéns da Amazon.
Nesta seção, aprenderemos sobre alguns dos aplicativos mais famosos criados com o uso da aprendizagem profunda. Isso ajudará você a perceber todo o potencial das redes neurais profundas.
Visão computacional
A visão computacional (CV) é usada em carros autônomos para detectar objetos e evitar colisões. Ele também é usado para reconhecimento facial, estimativa de pose, classificação de imagens e detecção de anomalias.
 Reconhecimento facial
Reconhecimento facial
Reconhecimento automático de fala
O reconhecimento automático de fala (ASR) é usado por bilhões de pessoas em todo o mundo. Ele está em nossos telefones e geralmente é ativado ao dizer "Hey, Google" ou "Hi, Siri". Esses aplicativos de áudio também são usados para conversão de texto em fala, classificação de áudio e detecção de atividade de voz.
 Reconhecimento de padrões de fala
Reconhecimento de padrões de fala
IA generativa
A IA generativa teve um aumento na demanda, já que o CryptoPunk NFT acabou de ser vendido por US$ 1 milhão. CryptoPunk é uma coleção de arte generativa que foi criada usando modelos de aprendizagem profunda. A introdução do modelo GPT-4 pela OpenAI revolucionou o domínio de geração de texto com sua poderosa ferramenta ChatGPT; agora, você pode ensinar modelos a escrever um romance inteiro ou até mesmo escrever código para seus projetos de ciência de dados.
 Arte generativa
Arte generativa
Tradução
A tradução com aprendizagem profunda não se limita à tradução de idiomas, pois agora podemos traduzir fotos para texto usando OCR ou traduzir texto para imagens usando o NVIDIA GauGAN2.
 Tradução de idiomas
Tradução de idiomas
Previsão de séries temporais
A previsão de séries temporais é usada para prever quebras de mercado, preços de ações e mudanças no clima. O setor financeiro sobrevive de especulações e projeções futuras. A aprendizagem profunda e os modelos de séries temporais são melhores do que os humanos na detecção de padrões e, portanto, são ferramentas essenciais nesse e em outros setores semelhantes.
 Previsão de séries temporais
Previsão de séries temporais
Automação
A aprendizagem profunda é usada para automatizar tarefas, por exemplo, treinar robôs para o gerenciamento de armazéns. A aplicação mais popular é jogar videogames e melhorar a resolução de quebra-cabeças. Recentemente, o Dota AI da OpenAI venceu a equipe profissional OG, o que chocou o mundo, pois as pessoas não esperavam que os cinco bots fossem mais espertos que os campeões mundiais.
 Braço robótico alimentado por aprendizado por reforço
Braço robótico alimentado por aprendizado por reforço
Feedback do cliente
A aprendizagem profunda é usada para lidar com o feedback e as reclamações dos clientes. Ele é usado em todos os aplicativos de chatbot para fornecer serviços de atendimento ao cliente perfeitos.
 Feedback do cliente
Feedback do cliente
Biomédico
Esse campo foi o que mais se beneficiou com a introdução da aprendizagem profunda. O DL é usado na biomedicina para detectar câncer, criar medicamentos estáveis, detectar anomalias em raios X do tórax e auxiliar equipamentos médicos.
 Análise de sequências de DNA
Análise de sequências de DNA
Modelos de aprendizagem profunda
Vamos conhecer os diferentes tipos de modelos de aprendizagem profunda e como eles funcionam.
Aprendizagem supervisionada
O aprendizado supervisionado usa um conjunto de dados rotulados para treinar modelos para classificar dados ou prever valores. O conjunto de dados contém recursos e rótulos de destino, que permitem que o algoritmo aprenda com o tempo, minimizando a perda entre rótulos previstos e reais. O aprendizado supervisionado pode ser dividido em problemas de classificação e regressão.
Classificação
O algoritmo de classificação divide o conjunto de dados em várias categorias com base na extração de recursos. Os modelos populares de aprendizagem profunda são o ResNet50 para classificação de imagens e o BERT (modelo de linguagem) para classificação de texto.
 Classificação
Classificação
Regressão
Em vez de dividir o conjunto de dados em categorias, o modelo de regressão aprende a relação entre as variáveis de entrada e saída para prever o resultado. Os modelos de regressão são comumente usados para análise preditiva, previsão do tempo e previsão do desempenho do mercado de ações. LSTM e RNN são modelos populares de regressão de aprendizagem profunda.
 Regressão linear
Regressão linear
Aprendizagem não supervisionada
Os algoritmos de aprendizado não supervisionado aprendem o padrão em um conjunto de dados não rotulado e criam clusters. Os modelos de aprendizagem profunda podem aprender padrões ocultos sem intervenção humana, e esses modelos são frequentemente usados em mecanismos de recomendação.
O aprendizado não supervisionado é usado para agrupar várias espécies, imagens médicas e pesquisa de mercado. O modelo de aprendizagem profunda mais comum para clusterização é o algoritmo de clusterização profunda incorporada.
 Agrupamento de dados
Agrupamento de dados
Aprendizagem por reforço
O aprendizado por reforço (RL) é um método de aprendizado de máquina em que os agentes aprendem vários comportamentos com o ambiente. Esse agente realiza ações aleatórias e recebe recompensas. O agente aprende a atingir metas por tentativa e erro em um ambiente complexo sem intervenção humana.
Assim como um bebê que, com o incentivo dos pais, aprende a andar, a IA aprende a executar determinadas tarefas maximizando as recompensas, e o designer define a política de recompensas. Recentemente, a RL tem visto altas demandas em automação devido aos avanços em robótica, carros autônomos, derrotar jogadores profissionais em jogos e pousar foguetes de volta à Terra.
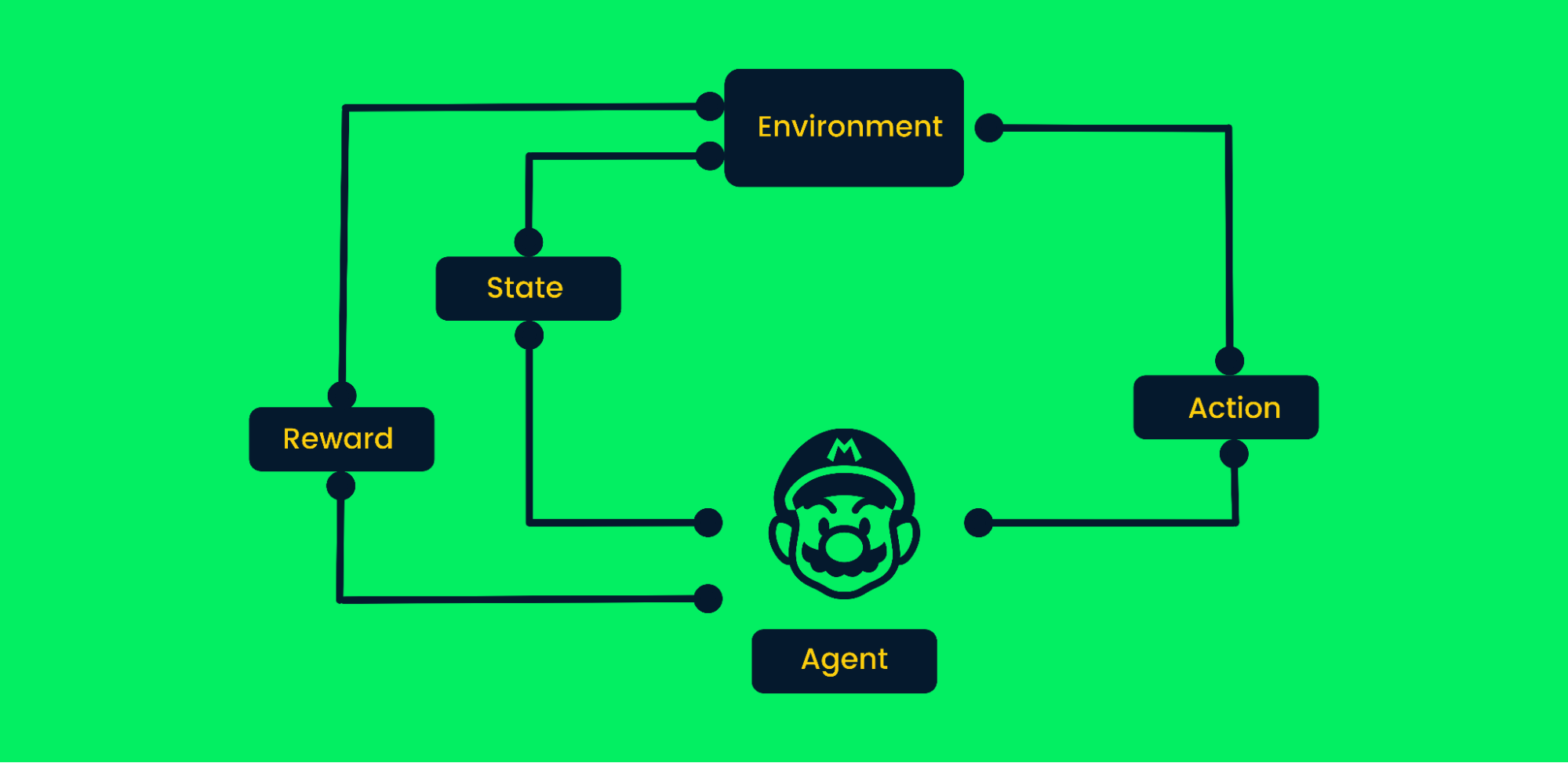 Estrutura de aprendizado por reforço
Estrutura de aprendizado por reforço
Vamos usar o videogame Mario como exemplo:
- No início, o agente (personagem Mario) recebe o estado zero do ambiente.
- Com base no estado, um agente realizará uma ação, no nosso caso, Mario se moveu para a direita.
- Agora o estado mudou e o personagem está em um novo quadro.
- O agente recebe uma recompensa, pois, ao mover-se para a direita, o personagem não está morto. Nosso principal objetivo é maximizar as recompensas.
O agente continuará o ciclo de ação e maximização das recompensas até chegar ao final do estágio ou morrer. Saiba mais em Uma introdução ao aprendizado por reforço.
Redes adversariais generativas
As redes adversárias generativas (GANs) usam duas redes neurais e, juntas, produzem instâncias sintéticas de dados originais. Os GANs ganharam muita popularidade nos últimos anos, pois são capazes de imitar alguns dos grandes artistas para produzir obras-primas. Eles são amplamente usados para gerar arte, vídeo, música e textos sintéticos. Saiba mais sobre aplicativos reais de trabalho no Tutorial de Redes Adversárias Generativas.
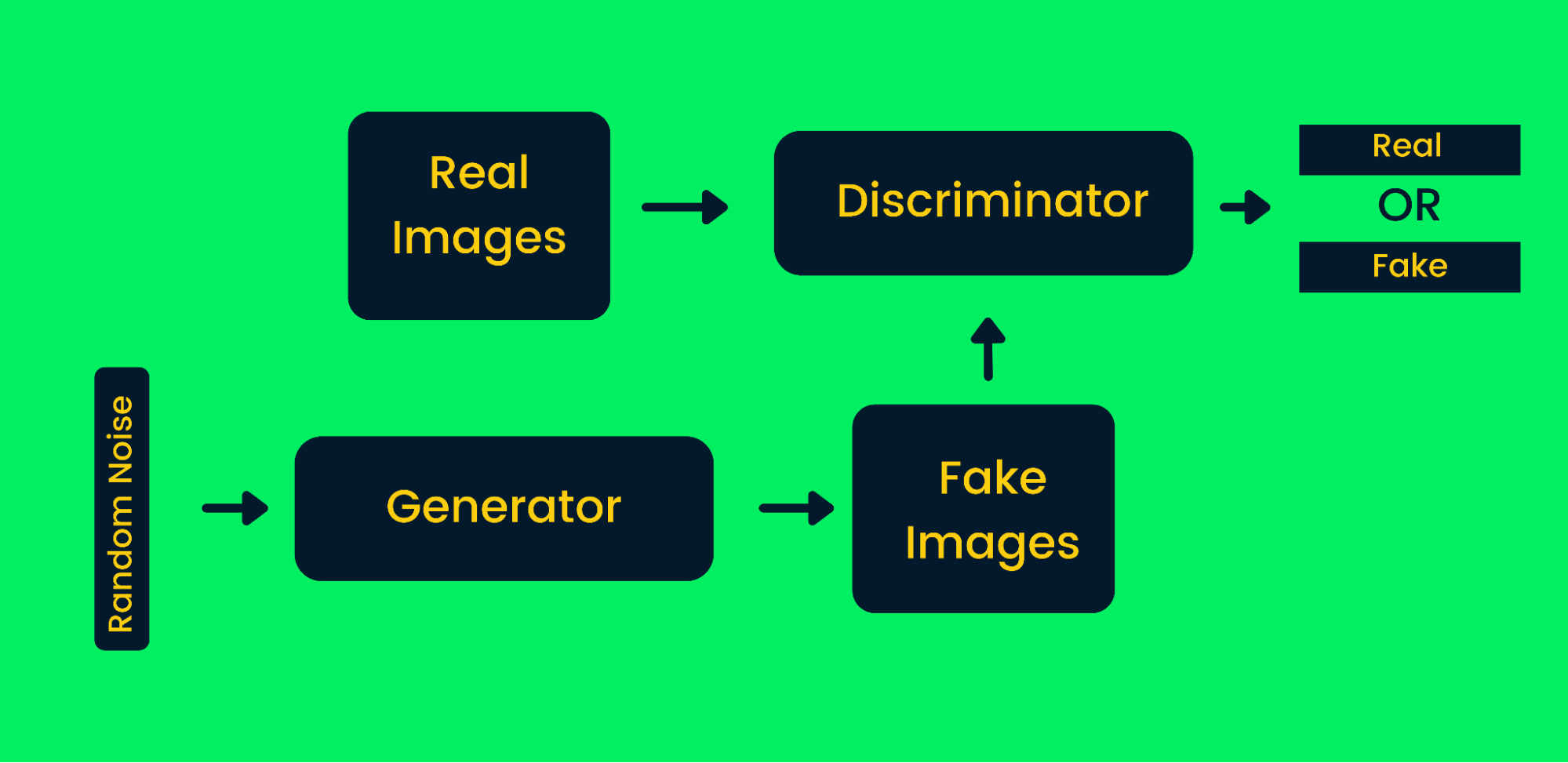 Estrutura de rede adversarial generativa
Estrutura de rede adversarial generativa
Como os GANs funcionam na geração de imagens sintéticas:
- Primeiro, as redes geradoras recebem uma entrada de ruído aleatório e geram imagens falsas.
- As imagens geradas e as reais são inseridas no discriminador.
- O discriminador decide se a imagem gerada é real ou não. Ele retorna probabilidades de zero a um, em que zero representa uma imagem falsa e um representa uma imagem autêntica. A arquitetura dos GANs contém dois loops de feedback. O discriminador está em um loop de feedback com imagens reais, enquanto o gerador está em um loop de feedback com um discriminador. Eles trabalham em sincronia para produzir imagens mais autênticas.
Rede neural de grafos
Um gráfico é uma estrutura de dados que consiste em bordas e vértices. As bordas podem ser direcionadas se houver dependências direcionais entre os vértices(nós), também conhecidos como gráficos direcionados. Os círculos verdes no diagrama abaixo são os nós, e as setas representam as bordas.
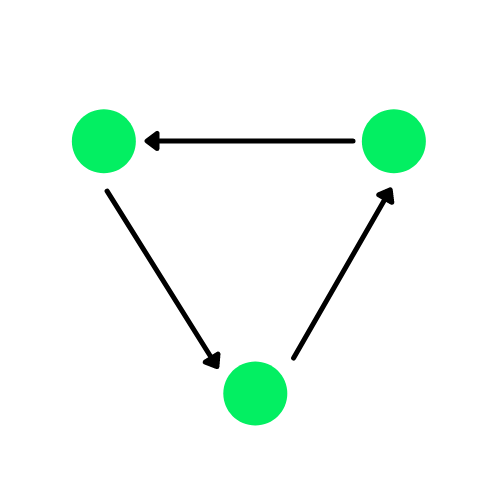
Um gráfico direcionado
Uma rede neural de gráficos (GNN) é um tipo de arquitetura de aprendizagem profunda que opera diretamente em estruturas de gráficos. Os GNNs são aplicados em análises de grandes conjuntos de dados, sistemas de recomendação e visões de computador.
 Uma rede de grafos
Uma rede de grafos
Eles também são usados para classificação de nós, previsão de links e clustering. Em alguns casos, as redes neurais gráficas tiveram um desempenho melhor do que as redes neurais de convolução, por exemplo, no reconhecimento de objetos e na previsão de relações semânticas.
Processamento de linguagem natural
O processamento de linguagem natural (NLP) usa a tecnologia de aprendizagem profunda para ajudar os computadores a aprender uma linguagem humana natural. A PNL usa a aprendizagem profunda para ler, decifrar e entender a linguagem humana. Ele é amplamente usado para processar fala, texto e imagens. A introdução da aprendizagem por transferência levou a PNL ao próximo nível, pois podemos ajustar o modelo com algumas amostras e obter um desempenho de última geração.
 Subcategorias da PNL
Subcategorias da PNL
A PNL pode ser dividida em vários campos:
- Tradução: tradução de idiomas, estrutura molecular e equações matemáticas
- Resumir: resumir grandes blocos de texto em poucas linhas, mantendo as principais informações.
- Classificação: dividir o texto em várias categorias.
- Geração: geração de texto para texto; pode ser usado para gerar redações inteiras com uma única linha de texto.
- Conversação: Assistente virtual que retém o conhecimento anterior de conversas e imita conversas humanas.
- Responder a perguntas: A IA responde a perguntas usando dados de perguntas e respostas.
- Extração de recursos: para detectar padrões no texto ou extrair informações, como "reconhecimento de entidade de nome" e "parte da fala".
- Semelhanças de frases: avaliação de semelhanças entre vários textos.
- Texto para fala: conversão de texto em fala audível.
- Reconhecimento automático de fala: compreensão de vários sons e conversão deles em texto.
- Reconhecimento óptico de caracteres: extração de dados de texto de imagens.
Se você quiser testar todas as várias aplicações da PNL, experimente o Hugging Face Spaces. O Spaces hospeda todos os tipos de aplicativos da Web com os quais você pode brincar para obter inspiração para seu projeto de PNL.
Um olhar mais profundo sobre os conceitos de aprendizagem profunda
Funções de ativação
Nas redes neurais, a função de ativação produz limites de decisão de saída e é usada para melhorar o desempenho do modelo. A função de ativação é uma expressão matemática que decide se a entrada deve passar por um neurônio ou não com base em seu significado. Ele também fornece não linearidade às redes. Sem a função de ativação, a rede neural se torna um modelo de regressão linear simples.
Há vários tipos de funções de ativação:
- Tanh
- ReLU
- Sigmoide
- Linear
- Softmax
- Swish
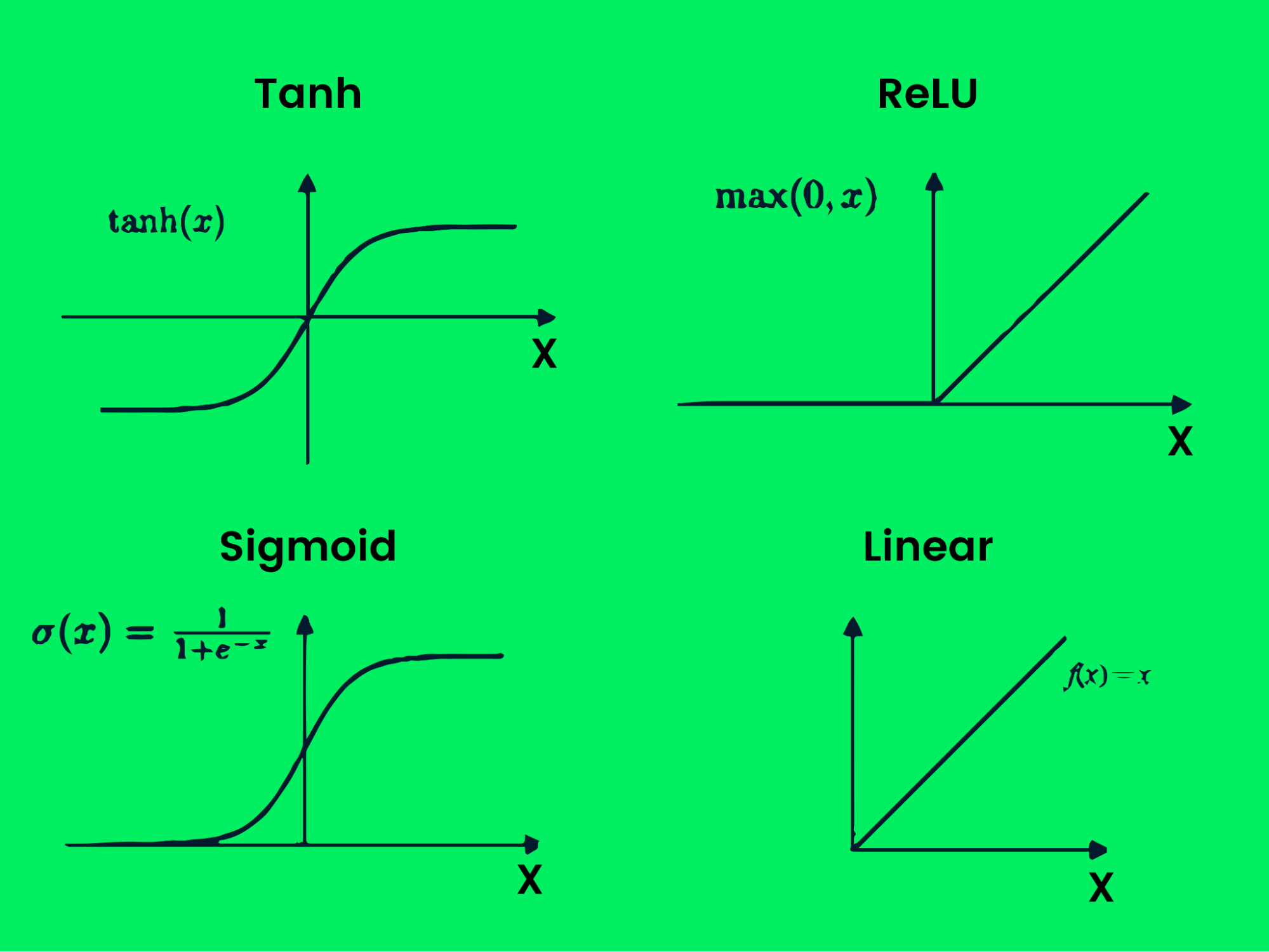 Função de ativação
Função de ativação
Essas funções produzem vários limites de saída, conforme mostrado na imagem acima. Com várias camadas e funções de ativação, você pode resolver qualquer problema complexo. Saiba mais sobre o que são funções de ativação na aprendizagem profunda.
Função de perda
A função de perda é a diferença entre os valores reais e os previstos. Ele permite que as redes neurais acompanhem o desempenho geral do modelo. Dependendo dos problemas específicos, escolhemos um determinado tipo de função, por exemplo, o erro quadrático médio.
Perda = Soma (Previsto - Real)²
As funções de perda mais usadas na aprendizagem profunda são:
- Entropia cruzada binária
- Dobradiça categórica
- Erro médio quadrático
- Huber
- Entropia cruzada categórica esparsa
Retropropagação
Na propagação de encaminhamento, inicializamos nossa rede neural com entradas aleatórias para produzir uma saída que também é aleatória. Para melhorar o desempenho do nosso modelo, ajustamos os pesos aleatoriamente usando a retropropagação. Para acompanhar o desempenho do modelo, precisamos de uma função de perda que encontre mínimos globais para maximizar a precisão do modelo.
Descida de gradiente estocástica
O gradiente de descida é usado para otimizar a função de perda, alterando os pesos de forma controlada para atingir a perda mínima. Agora temos um objetivo, mas precisamos de orientação sobre como aumentar ou diminuir os pesos para obter um desempenho melhor. A derivada da função de perda nos dará uma direção e podemos usá-la para atualizar os pesos da rede.
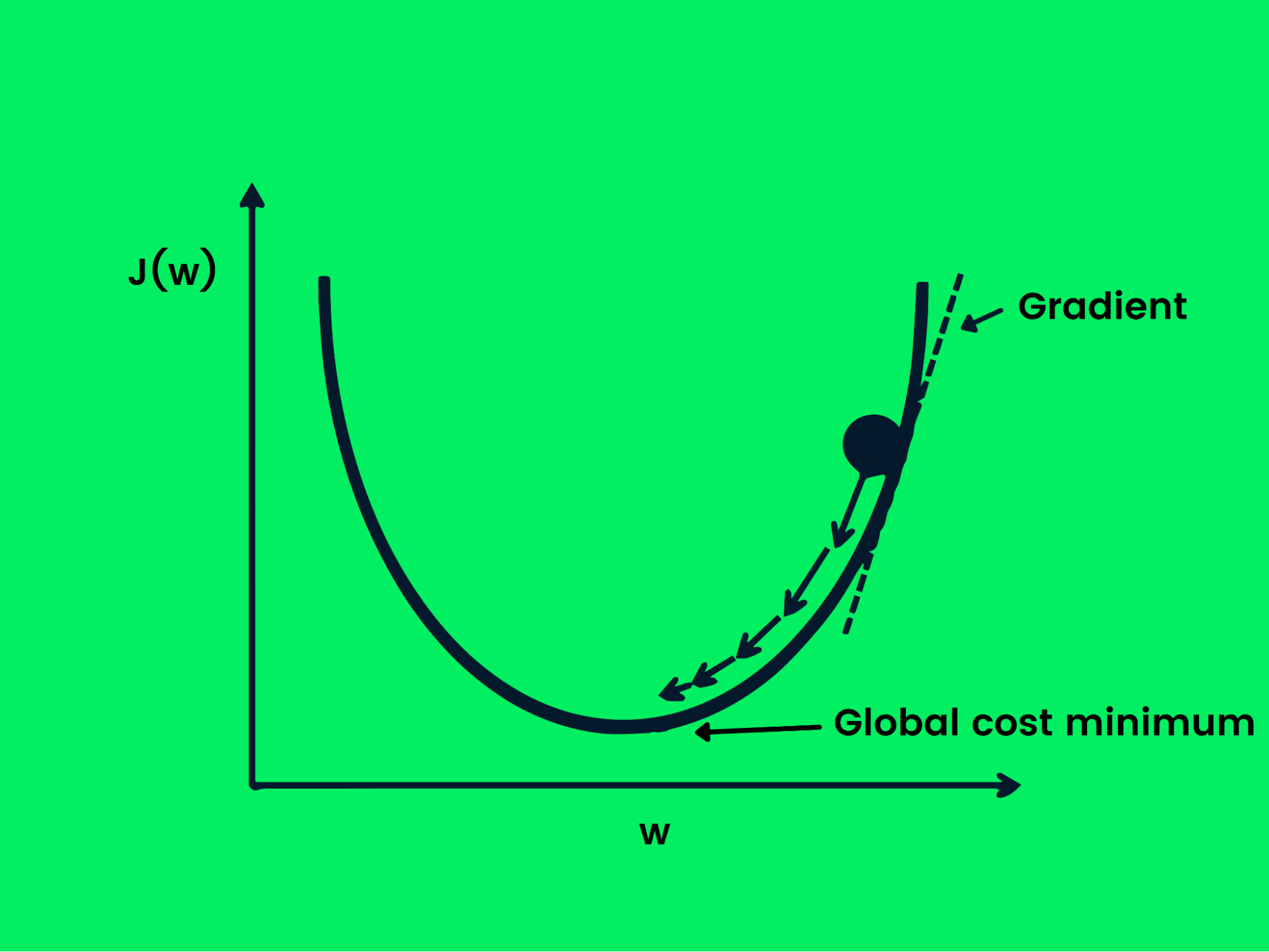 Descida de gradiente
Descida de gradiente
A equação abaixo mostra como os pesos são atualizados usando a descida do gradiente.
w = w -Jw
Na descida gradiente estocástica, as amostras são divididas em lotes em vez de usar todo o conjunto de dados para otimizar a descida gradiente. Isso é útil se você quiser atingir a perda mínima mais rapidamente e otimizar a potência computacional.
Hiperparâmetro
Os hiperparâmetros são os parâmetros ajustáveis ajustados antes da execução do processo de treinamento. Esses parâmetros afetam diretamente o desempenho do modelo e ajudam você a atingir mínimos globais mais rapidamente.
Lista dos hiperparâmetros mais usados:
- Taxa de aprendizado: tamanho da etapa de cada iteração e pode ser definido de 0,1 a 0,0001. Em resumo, ele determina a velocidade de aprendizado do modelo.
- Tamanho do lote: número de amostras que passam por uma rede neural de cada vez.
- Número de épocas: uma iteração de quantas vezes o modelo altera os pesos. Um número muito grande de épocas pode fazer com que os modelos se ajustem demais e um número muito pequeno pode fazer com que os modelos se ajustem de menos, portanto, temos que escolher um número médio.
Para saber mais sobre como esses componentes funcionam juntos, siga o tutorial Keras Tutorial: Aprendizagem profunda em Python.
Algoritmos populares
Redes neurais convolucionais
A rede neural convolucional (CNN) é uma rede neural feed-forward capaz de processar uma matriz estruturada de dados. Ele é amplamente usado para aplicativos de visão computacional, como classificação de imagens.
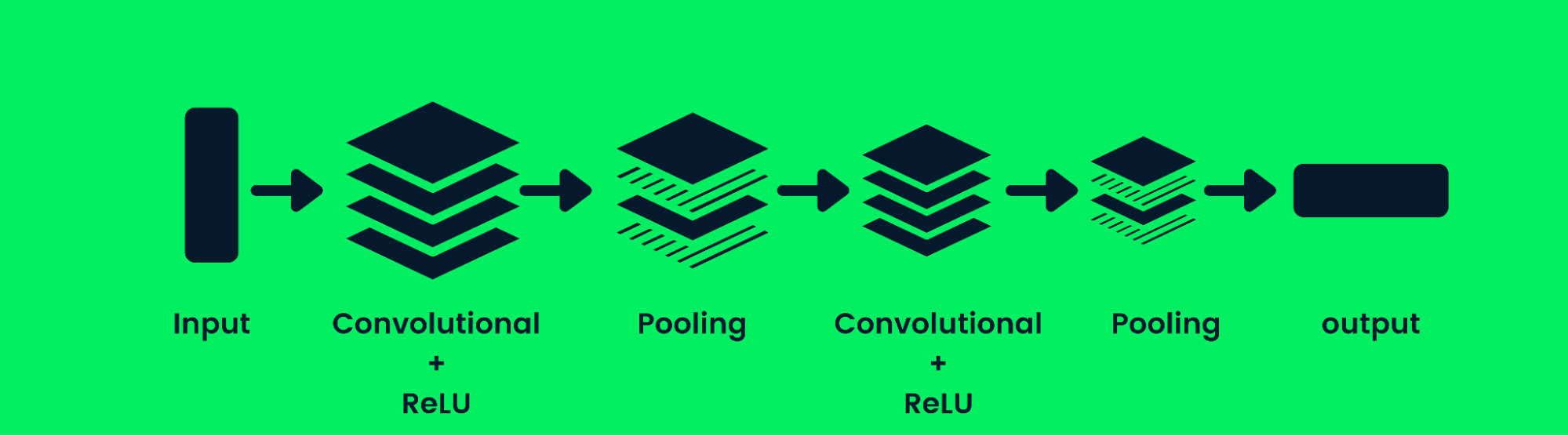 Arquitetura de rede neural de convolução
Arquitetura de rede neural de convolução
As CNNs são boas no reconhecimento de padrões, linhas e formas. A CNN consiste em uma camada convolucional, uma camada de pooling e uma camada de saída (camadas totalmente conectadas). Os modelos de classificação de imagens geralmente contêm várias camadas de convolução, seguidas de camadas de agrupamento, pois camadas adicionais aumentam a precisão do modelo. Saiba mais sobre camadas convolucionais aqui: Redes neurais convolucionais em Python.
Redes neurais recorrentes
As redes neurais recorrentes (RNN) são diferentes das redes feed-forward, pois a saída da camada é realimentada na entrada para prever a saída da camada. Isso o ajuda a ter um desempenho melhor com dados sequenciais, pois ele pode armazenar as informações de amostras anteriores para prever amostras futuras. Saiba mais em Tutorial de Rede Neural Recorrente (RNN): Tipos e exemplos.
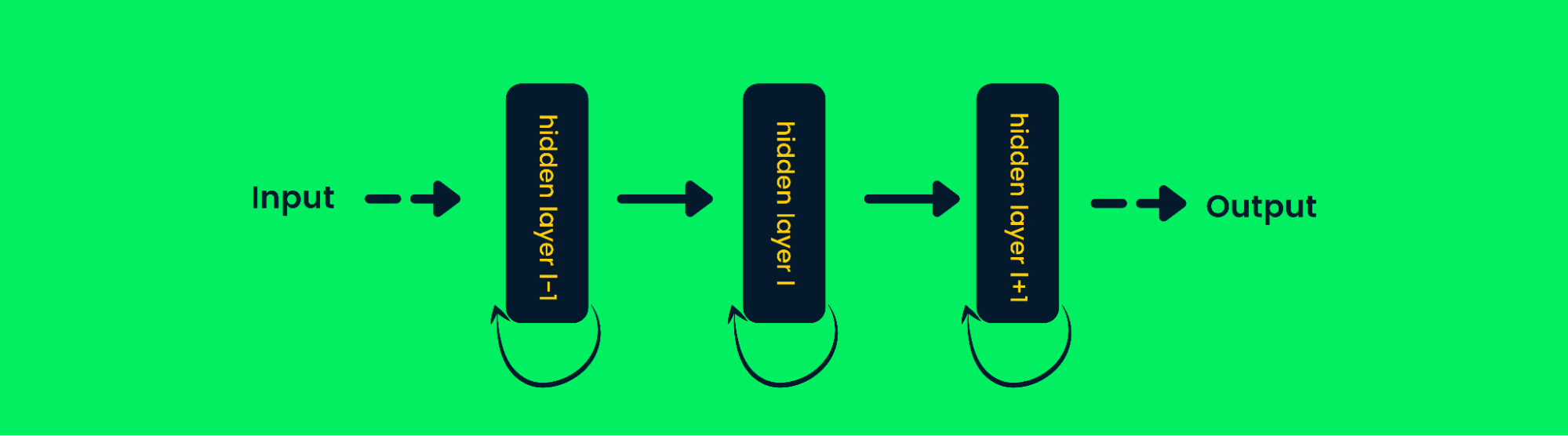 Arquitetura de rede neural recorrente
Arquitetura de rede neural recorrente
Nas redes neurais tradicionais, a saída das camadas é calculada com base nos valores de entrada atuais, mas na RNN a saída também é calculada com base nas entradas anteriores. Isso o torna muito bom para prever a próxima palavra, prever preços de ações, em chatbots de IA e detecção de anomalias.
Redes de memória de longo prazo e curto prazo
As redes de memória de longo prazo (LSTM) são tipos avançados de redes neurais recorrentes que podem reter mais informações sobre valores passados. Ele resolve problemas de gradiente decrescente que existem em RNN simples.
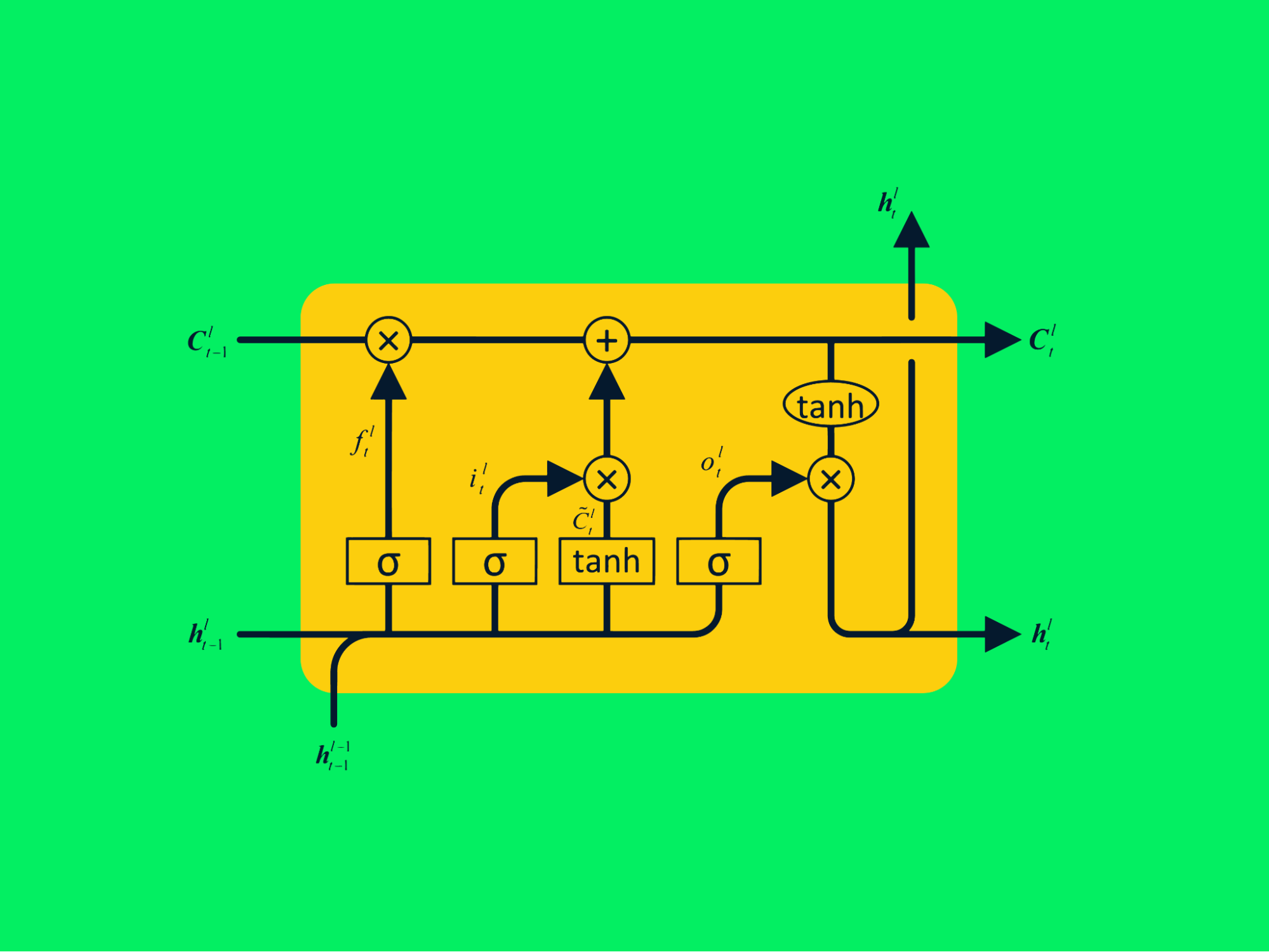 Arquitetura LSTM
Arquitetura LSTM
A RNN típica consiste em redes neurais repetitivas com uma única camada tanh, enquanto a LSTM consiste em quatro camadas interativas que se comunicam para processar grandes sequências de dados.
Você pode obter experiência prática com o seguinte tutorial : LSTM para previsões de ações ou o curso de aprendizagem profunda avançada com Keras se você quiser saber mais sobre modelos de aprendizagem profunda.
Estruturas de aprendizagem profunda
Há várias estruturas de aprendizagem profunda, como MxNet, CNTK e Caffe2, mas aprenderemos sobre as estruturas mais populares.
Tensorflow
O Tensorflow (TF) é uma biblioteca de código aberto usada para criar aplicativos de aprendizagem profunda. Ele inclui todas as ferramentas necessárias para que você possa experimentar e desenvolver produtos comerciais de IA. Ele é compatível com CPU, GPU e TPU para treinamento de modelos complexos. O TF foi originalmente desenvolvido pela equipe de IA do Google para uso interno e agora está disponível para o público.
A API do Tensorflow está disponível para aplicativos baseados em navegador, dispositivos móveis e o TensorFlow Extended é ideal para produção. O TF agora se tornou o padrão do setor e é usado tanto para pesquisas acadêmicas quanto para a implantação de modelos de aprendizagem profunda na produção.
O TF também vem com o Tensorboard, que é um painel capaz de analisar seus experimentos de aprendizado de máquina. Recentemente, os desenvolvedores do Tensorflow integraram o Keras à sua estrutura, que é popular para o desenvolvimento de redes neurais profundas. Saiba mais no curso Introdução ao TensorFlow em Python.
Keras
O Keras é uma estrutura de rede neural escrita em Python e capaz de ser executada em várias estruturas, como Tensorflow e Theano. O Keras é uma biblioteca de código aberto desenvolvida para permitir a experimentação rápida em aprendizagem profunda, de modo que você possa converter facilmente seus conceitos em aplicativos de IA funcionais.
A documentação é bastante fácil de entender, e a API é semelhante à do Numpy, o que permite que você a integre facilmente a qualquer projeto de ciência de dados. Assim como o TF, o Keras também pode ser executado em CPU, GPU e TPU, com base no hardware disponível. Saiba mais em Introdução à aprendizagem profunda com o Keras.
PyTorch
O PyTorch é a estrutura de aprendizagem profunda mais popular e mais fácil de usar. Ele usa tensor em vez de matriz Numpy para realizar cálculos numéricos rápidos com a ajuda da GPU. O PyTorch é usado principalmente para aprendizagem profunda e desenvolvimento de modelos complexos de aprendizagem de máquina.
Os pesquisadores acadêmicos preferem usar o PyTorch devido à sua flexibilidade e facilidade de uso. Ele é escrito em C++ e Python, e também vem com aceleração de GPUs e TPUs. Ele se tornou uma solução completa para todos os problemas de aprendizagem profunda. Se você quiser saber mais sobre o PyTorch, experimente fazer o curso Introdução à aprendizagem profunda com o PyTorch.
Conclusão
Neste tutorial, abordamos tudo o que é a aprendizagem profunda, alguns dos conceitos básicos da aprendizagem profunda, como ela funciona e suas aplicações. Também aprendemos como funcionam as redes neurais profundas e sobre os diferentes tipos de modelos de aprendizagem profunda. Por fim, você foi apresentado a algumas estruturas populares de aprendizagem profunda.
Este tutorial forneceu todas as principais informações necessárias para você começar a trabalhar no campo da aprendizagem profunda. Para aprofundar o seu aprendizado, o curso de Deep Learning em Python preparará você para trabalhar em projetos do mundo real. Você também pode conferir a aprendizagem profunda com Keras em R se estiver familiarizado com a linguagem de programação R.