courses
머신 러닝 이해하기
2
299.3K
예측의 품질은 투입되는 재료의 품질에 좌우됩니다. 우선 원재료부터 살펴볼 가치가 있습니다. 모델은 두 가지 실시간 데이터 소스에서 학습하고 이를 하나의 정돈된 피처 테이블로 변환합니다.
모든 것은 두 곳에서 출발합니다. API-Football은 경기 일정과 경기별 통계를 제공합니다. 누가 누구와 언제, 어디서 경기했으며 결과가 어땠는지까지요. eloratings.net은 모든 국가대표팀의 Elo 레이팅을 제공합니다.
Elo 레이팅은 팀의 전력을 하나의 숫자로 표현한 값입니다. 모든 팀은 이 스케일 어딘가에 위치하며, 경기 후에는 레이팅이 업데이트됩니다. 더 강한 팀을 이기면 많이 오르고, 더 약한 팀에게 지면 크게 떨어집니다. 체스에서 유래해 축구에도 잘 맞도록 응용된 개념입니다. 전체 개념이 궁금하시다면, 이전 DataCamp 글에서 2022 월드컵을 배경으로 직관을 자세히 설명합니다.
두 소스를 결합해 2018년 이후 약 6,900건의 A매치로 구성된 Gold 데이터셋을 만들어 학습합니다.
여기서 중요한 설계 선택이 나옵니다. 승/무/패 결과를 직접 예측하는 대신, 모델은 더 세밀한 값을 예측합니다. 바로 각 팀이 경기에서 넣는 득점 수입니다. 축구의 득점 수는 좋은 근사로 푸아송 분포를 따릅니다. 일정 시간 창에서 드물게 발생하는 사건의 횟수를 모델링하는 표준 방식입니다.
결과가 아니라 득점을 예측해야 이후 모든 것이 가능해집니다. 모델이 임의의 대진에 대해 그럴듯한 스코어라인을 생성할 수 있으면, 실제로 모두가 궁금해하는 질문—누가 조별리그를 통과하고 누가 트로피를 들어 올리는가—을 그 스코어라인을 수천 번 시뮬레이션해 답할 수 있습니다.
각 경기는 소수의, 신중하게 고른 피처로 설명됩니다.
모든 피처는 철저히 누수 안전합니다. 킥오프 이전에 이용 가능한 정보만 사용합니다. 당연해 보이지만, 테스트에서는 뛰어나 보이다가 현실에서 무너지는 모델을 우연히 만들어내는 가장 쉬운 방법이 바로 이 원칙을 어기는 것입니다.
채택되지 않은 아이디어 하나: 경기 내 통계로 팀을 클러스터링해 만든 "플레이 스타일" 피처 세트를 계획했는데, 이는 비지도 학습 단계였습니다. 실제로는 팀이 의미 있게 분리되지 않아, 모델에 잡음을 공급하느니 제외했습니다. 부정적 결과도 결과입니다.
두 소스에서 데이터가 계속 들어오는 만큼, 원시 파일에서 모델 준비 피처까지의 경로는 매번 동일해야 합니다. 이를 보장하는 것이 바로 메달리온 아키텍처입니다. 세 개의 레이어로 데이터를 구성합니다.
각 레이어는 다음 레이어의 입력이므로, 이상이 보이면 한 단계씩 거슬러 올라가 원인을 찾을 수 있습니다. 전체 경로를 재현 가능하게 만들기 위해 DVC(Data Version Control)를 사용합니다. 새로운 결과가 들어올 때마다 dvc repro 한 번으로 Silver와 Gold를 Bronze에서부터 재생성합니다. 입력이 바뀐 단계만 다시 실행하고, 결과 데이터셋에 버전을 매겨 이전 상태를 정확히 복원할 수 있게 합니다.
득점 예측은 연구가 많이 된 문제이며, 정답인 도구가 하나로 정해져 있지 않습니다. 그래서 저는 한 가지 방법에 고정하지 않고 열 개를 만들어 경쟁시켰습니다.
열 개의 모델은 다섯 계열과 단순 베이스라인으로 구성됩니다. 각 모델의 내부를 알 필요는 없습니다. 중요한 것은 득점 메커니즘에 대해 매우 다른 가정을 한다는 점입니다.
| 계열 | 모델 | 핵심 아이디어 |
|---|---|---|
| 베이스라인 | 평균율 푸아송 | 모든 팀이 피처를 무시하고 장기 평균 득점만 낸다고 가정합니다. 다른 모델이 넘어야 할 하한선입니다. |
| 통계적 | 이변량 푸아송, 음이항 | 두 팀의 득점 수를 사건 카운팅에 적합한 확률분포로 직접 모델링합니다. |
| 베이즈 | 베이즈 푸아송(MCMC) | 카운팅 아이디어는 같지만, 각 추정치에 대한 불확실성 범위를 전체 분포로 반환합니다. 계산 비용이 큽니다. 다른 모델보다 적합 시간이 약 100배 느립니다. |
| 시계열 | SARIMAX | 팀의 결과를 시간에 따른 시퀀스로 보고 이를 앞으로 투영합니다. |
| 머신러닝 | 리지, 랜덤 포레스트, XGBoost | 고정된 방정식에 얽매이지 않고 피처에서 직접 패턴을 학습합니다. |
| 딥러닝 | LSTM, 1D CNN | 데이터의 순차적/국소적 패턴을 찾는 신경망입니다. |
열 명의 후보를 눈대중으로 고를 수는 없습니다. 각 모델은 세 단계를 거치고, 코드를 통해 다음 단계 이동 여부가 결정됩니다. 이것이 코드 기반 배포의 의미입니다. 수동 튜닝이 아니라 자동 점검으로 모델이 환경 간 승격되므로, 선택 과정 전체가 재현 가능하고 감사가 쉽습니다.
어떤 접근이 최종 우승을 차지했을까요? 다음은 RPS(낮을수록 좋음)로 평가한 홀드아웃 리더보드 전체입니다.
| 모델 | 홀드아웃 RPS |
|---|---|
| XGBoost | 0.18289 |
| 베이즈 푸아송 | 0.18316 |
| 음이항 | 0.18373 |
| 이변량 푸아송 | 0.18389 |
| 랜덤 포레스트 | 0.18392 |
| SARIMAX | 0.18583 |
| 리지 | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| 평균율 푸아송(베이스라인) | 0.22872 |
이 결과에서 네 가지가 눈에 띕니다.
 실제 대회에서는 열 개를 모두 돌리지 않습니다. 더 작은 로스터를 유지합니다. 기준점으로 평균율 베이스라인, 그리고 상위 세 모델입니다. XGBoost와 베이즈 푸아송이 상위 두 자리를 차지합니다.
실제 대회에서는 열 개를 모두 돌리지 않습니다. 더 작은 로스터를 유지합니다. 기준점으로 평균율 베이스라인, 그리고 상위 세 모델입니다. XGBoost와 베이즈 푸아송이 상위 두 자리를 차지합니다.
3위는 사실상 동률입니다. 음이항과 이변량 푸아송은 0.0002 RPS 이내로 붙고 난수 시드에 따라 순위가 바뀝니다. 통계적으로 구분되지 않는 두 모델 중에서는, 축구 예측 문헌에서 더 탄탄한 정식화를 가진 이변량 푸아송을 선택했습니다(Karlis and Ntzoufras, 2004).
결국 로스터는 XGBoost(머신러닝), 이변량 푸아송(고전 통계), 베이즈 푸아송(베이지안 추론)으로 구성됩니다. 다음 섹션에서는 이 모델들이 어떻게 실행·재학습되며, 단일 경기 예측을 전체 대회 전망으로 바꾸는지 다룹니다.
노트북에만 사는 모델은 앉아 있는 동안에만 쓸모가 있습니다. 한 달짜리 대회 기간 동안 경기를 예측하려면, 전체가 스스로 돌아가야 합니다. 새 결과 수집, 재학습, 재시뮬레이션, 예측 갱신까지 사람 손 없이요. 그 역할을 파이프라인이 맡습니다.
프로젝트 전체는 Google Cloud Run의 단일 예약 작업으로 실행됩니다. 대회 전에는 하루 한 번 깨우고, 6월 11일 개막전부터는 2시간마다 실행합니다. 각 실행은 동일한 사이클을 따릅니다.
dvc repro 한 번으로 Silver와 Gold 레이어를 재생성해 피처를 최신 상태로 만듭니다.모든 단계가 스케줄에 따라 코드로 트리거되므로, 대회 중에 수동 버튼을 누를 일은 없습니다. 새 결과 입력, 갱신 예측 출력.
이 프로젝트는 동시에 실험이기도 합니다. 대회 기간 로스터를 두 개의 병렬 모드로 돌립니다. 그리고 그 차이는 데이터로 확인하려는 질문과 연결됩니다. 대회가 진행되며 재학습하면 예측이 더 좋아질까요?
두 모드를 나란히 돌리면 대회가 끝난 뒤 두 측면에서 비교할 수 있습니다. 순수 예측 정확도, 그리고 참가 팀이 줄어들수록 불확실성이 얼마나 빨리 줄어드는지입니다. 라운드별이 이기면 정기 재학습의 가치가 입증되고, 동결이 선전하면 추가 복잡성이 가치 없을 수 있습니다.
단일 경기 예측은 비교적 간단합니다. 이를 "각 팀의 우승 확률"로 바꾸는 단계에서 몬테카를로 시뮬레이션이 필요합니다.
먼저 추론입니다. 이미 확정된 대진만 예측하는 대신, 48개 팀 사이의 모든 가능한 대진을 예측합니다. 과해 보일 수 있지만, 토너먼트에서는 어떤 팀이든 결선에서 만나 가능하므로 모든 페어링에 대한 예측이 준비되어 있어야 합니다.
다음으로 룰을 코드화해야 하는데, 2026년 포맷은 특히 까다롭습니다. 12개 조에서 각 조 상위 2팀이 자동 진출하고, 3위 중 상위 8팀도 진출합니다. 이 8팀이 어떤 32강 슬롯에 들어가는지는 이들이 나온 조 조합에 따라 달라집니다.
열두 조 중 여덟 조를 고르는 방법은 495가지(12C8)이고, 각각 다른 32강 대진을 만듭니다. 깔끔한 공식이 없고, FIFA가 표를 발표할 뿐입니다. 그래서 저는(정확히는 제 유능한 동료 Cursor가) 공식 표를 바탕으로 495개 조합 전부를 매핑으로 하드코딩했습니다.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...EFGHIJKL 같은 키는 3위로 진출한 여덟 개 조를 나타내고, 값은 그 팀들(3E, 3F 등)을 특정 32강 경기 번호에 배정합니다. 이게 하나의 항목이고, 전체 매핑은 495번 반복됩니다. 조합마다 한 번씩입니다.
세 개최국(미국, 캐나다, 멕시코)에 대해서는 별도의 처리가 하나 있습니다. 개최국이 자국에서 열리는 경기를 치를 때는 그 경기만 홈 어드밴티지를 적용하고, 나머지는 중립 경기로 처리합니다.
예측과 규칙을 갖췄다면, 시뮬레이션은 대회를 10,000번 돌립니다. 각 실행에서 다음 절차를 따릅니다.
10,000번의 시뮬레이션에서, 결승 진출 혹은 우승을 차지한 비율이 해당 팀의 확률이 됩니다. 한 번의 실행은 추정치이고, 만 번의 실행이 예측입니다.
지금까지 설명한 모든 실행(두 모드 전부)은 MLflow(DagsHub 호스팅)에 기록됩니다. 실험 추적은 각 실행의 입력, 설정, 결과, 출력을 체계적으로 기록해 서로 비교하거나 정확히 재현할 수 있게 합니다. 그중 몇 가지를 짚어보면 다음과 같습니다.
학습된 모델과 예측 파일(토너먼트 확률, 조 순위, 경기 예측)은 실행 아티팩트로 저장되며, 라이브 대시보드는 바로 이 파일을 읽습니다. 이렇게 해서 루프가 닫힙니다. 원시 결과에서 시작해, 학습과 시뮬레이션을 거쳐, 온라인에서 볼 수 있는 숫자까지.
마지막 단계는 경기가 종료된 뒤에 돌아갑니다. 실제 결과가 들어오면 사전 예측을 채점해 단순 평균율 베이스라인과 비교합니다. 만약 전체 모델이 팀에 대한 정보를 전혀 모르는 모델보다 뒤처지기 시작하면, 이는 드리프트의 경고 신호입니다. 대회 이전에 학습한 패턴이 현재 경기장에서 벌어지는 일과 맞지 않을 수 있음을 뜻합니다.
이는 라이브 예측 시스템에서 표준 관행이며, 더 자세한 탐지 방식은 데이터 드리프트와 모델 드리프트 가이드에서 읽을 수 있습니다.
이 모든 장치의 목적은 결국 이것입니다.
개막 하루 전인 2026년 6월 10일 기준으로, 모델의 최상단은 명확하고 그 뒤는 촘촘합니다. 스페인과 아르헨티나가 각각 약 16%의 우승 확률로 선두입니다. 현 월드챔피언(아르헨티나)과 현 유럽챔피언(스페인)이 최상단에 오른 것은 모델이 현실에 기반하고 있음을 보여주는 안심 신호입니다.
그 뒤를 프랑스, 잉글랜드, 브라질, 콜롬비아가 바짝 추격합니다. 이 수치는 실시간으로 변하며 실제 결과가 들어오는 즉시 움직입니다. 그러니 6월 10일의 스냅샷으로 받아들이세요. 대시보드는 지연이 최대 두 시간인 최신 수치를 항상 보여줍니다.
말이 나왔으니 덧붙이면, 이 글의 모든 숫자는 파이프라인이 실행될 때 자동으로 업데이트되는 라이브 Streamlit 앱에서 가져옵니다. wc2026-predictions.streamlit.app에서 대회 내내 따라가 보세요. 주요 보기는 네 가지입니다.
경기 보기에서 주의할 점이 하나 있습니다. 몇몇 팀이 동시에 두 개의 32강 슬롯에 나타납니다. 버그가 아닙니다. 조가 너무 균형 있어 모델이 그 팀의 최종 순위를 자신 있게 가르지 못할 때 발생합니다. 최고의 3위의 불확실성과 결합하면, 두 가지 결과가 서로 다른 토너먼트 슬롯으로 이어집니다. 터키의 경우에는 16강에 두 번 나타나는 상황까지 있었습니다.
다음 그래픽은 대회 시작 전 XGBoost 모델이 예측한 최종 라운드(8강부터 결승까지)를 보여줍니다.
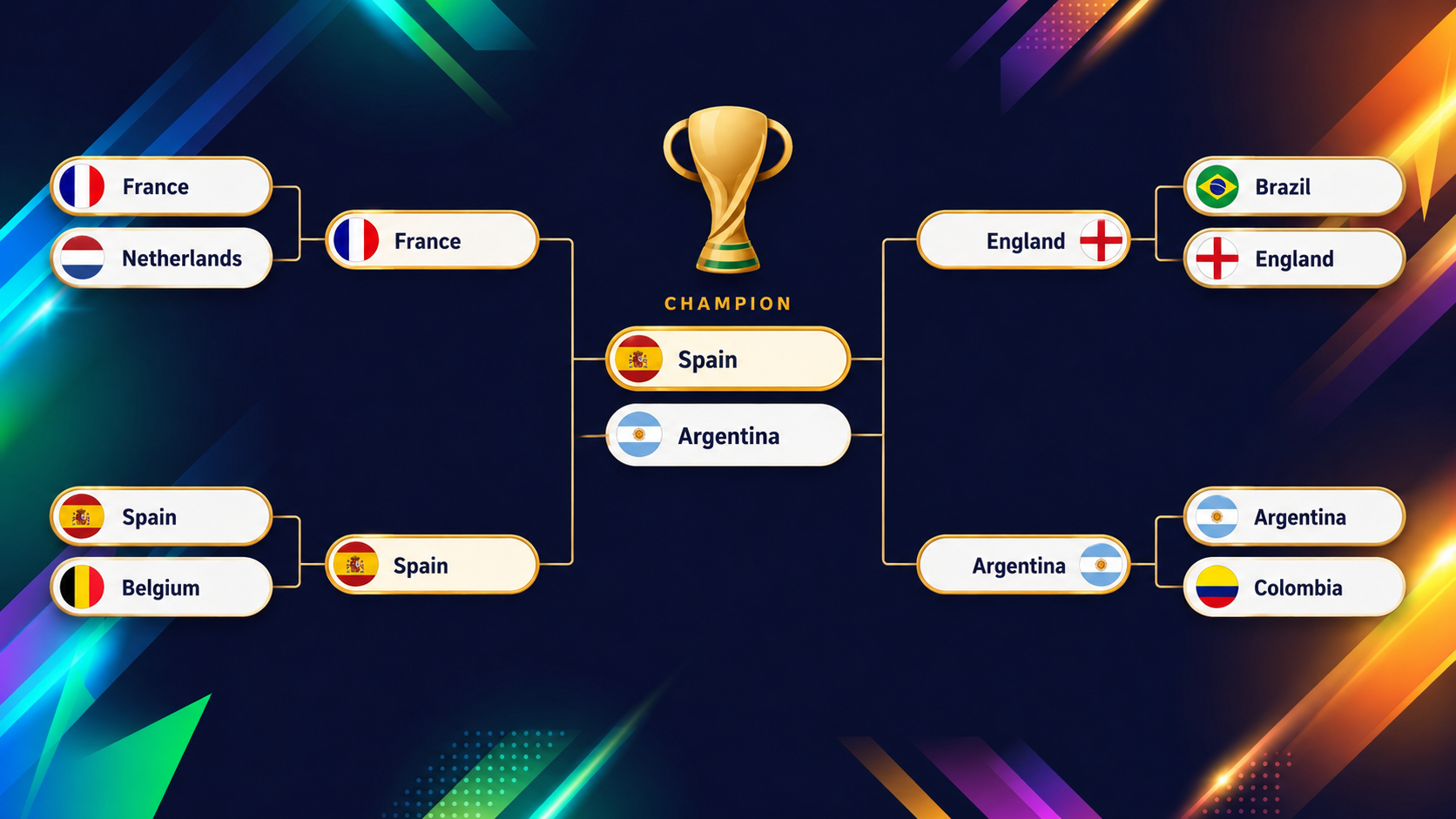
이런 모델의 재미는 눈대중과 어긋나는 팀에서 나옵니다. 가장 뚜렷한 예가 미국입니다. 대시보드의 토너먼트 개요를 보면, 미국이 색상으로 바로 눈에 띕니다.
공동 개최국으로 홈 관중 앞에서 치르니, 무난한 출발을 예상할 수 있겠지만 모델은 훨씬 신중합니다. 조가 호주, 파라과이, 터키로 유난히 균형 잡혀 있어, 조별리그 통과 확률을 약 54.6%로 봅니다. 전체 48팀 중 13번째로 낮은 수치입니다(팀의 3분의 2가 통과한다는 점을 기억하세요!).
흥미로운 건 그다음입니다. 간신히 통과한 뒤에는 매 라운드가 거의 동전 던지기입니다. 그런 동전 던지기를 차곡차곡 쌓으면, 전체 우승 확률이 약 2%가 됩니다. 이는 48팀 중 13번째로 높은 수치입니다.
조별 통과 확률은 하위 13위, 우승 확률은 상위 13위인 팀이라면, 바로 완벽한 동전 던지기 팀입니다. 한 번도 확실한 강자도, 한 번도 탈락 확정도 아닌.
이 프로젝트는 많은 작업이 필요했고, 한 편의 글로 다 담기 어렵습니다. 저장소에는 여기 싣지 못한 내용이 풍부합니다. 전체 후보 모델, 피처 엔지니어링, 모든 것을 돌게 하는 오케스트레이션 등이 그 예입니다.
지금은 모델이 선택을 마쳤고, 심판은 대회입니다. MLOps를 위해 오셨든 축구를 위해 오셨든, 저만큼 즐기시길 바랍니다. 경기 결과가 들어올 때마다 실시간 예측을 따라가며, 예측이 얼마나 잘 맞는지 확인해 보세요.
언급한 개념을 더 자세히 보고 싶다면 MLOps Concepts 과정을 추천합니다.
Top 머신러닝 강의
courses
courses
courses