Course
Введение в машинное обучение
2 ч
299.3K
Качество прогноза определяется качеством входящих данных, поэтому начнём с исходников. Модель учится на двух живых источниках данных и превращает их в единую аккуратную таблицу признаков.
Всё строится на двух источниках. API-Football поставляет календарь и поматчевую статистику: кто с кем играл, когда, где и как всё закончилось. eloratings.net предоставляет рейтинги Elo для каждой национальной сборной.
Рейтинг Elo — это одно число, характеризующее силу команды. Каждая команда занимает место на шкале, и после каждого матча рейтинг обновляется: победите более сильного соперника — получите много очков; проиграйте более слабому — сильно потеряете. Идея пришла из шахмат и хорошо адаптируется к футболу. Если нужна полная интуиция, вот предыдущий материал DataCamp с разбором на примере ЧМ‑2022.
Вместе эти два источника дают Gold‑датасет примерно из 6900 международных матчей с 2018 года для обучения.
Первый важный конструкторский выбор: вместо прямого исхода — победа, ничья или поражение — модель предсказывает более детальную величину: количество голов, забитых каждой командой в матче. Число голов в футболе с хорошей точностью следует распределению Пуассона — стандартной модели для редких событий в фиксированном окне времени.
Именно прогноз голов, а не исхода, делает возможным всё остальное. Как только модель может выдать правдоподобный счёт для любой пары соперников, на вопросы, которые действительно интересуют всех — кто выйдет из группы и кто поднимет трофей — можно ответить, многократно моделируя эти счёты.
Каждый матч описывается небольшим, тщательно отобранным набором признаков:
Все признаки строго безопасны с точки зрения утечки — каждый использует только ту информацию, что была доступна до стартового свистка. Звучит очевидно, но это один из самых простых способов случайно построить модель, блестящую в тестах и разваливающуюся в реальности.
Идея, которая не вошла: я планировал признаки «стиля игры», построенные кластеризацией команд по матчевой статистике — шаг обучения без учителя. На практике команды не разделились на осмысленные группы, поэтому, чтобы не кормить модель шумом, я отказался. Негативные результаты — тоже результаты.
Поскольку данные из двух источников приходят непрерывно, путь от сырых файлов до признаков, готовых для модели, должен быть идентичен каждый раз. Это обеспечивает медальонная архитектура. Она организует данные в три слоя:
Каждый слой питает следующий, поэтому, если что‑то выглядит странно, я могу отследить источник поэтапно, а не распутывать всё сразу. Чтобы сделать весь путь воспроизводимым, я использую DVC (Data Version Control). Когда приходят свежие результаты, одна команда dvc repro пересобирает Silver и Gold из Bronze, повторно выполняя шаг только при изменении входов, и версионирует итоговые датасеты, чтобы любую предыдущую версию можно было точно восстановить.
Прогнозирование голов — хорошо изученная задача, и единственно очевидного инструмента нет. Поэтому вместо того, чтобы заранее выбрать один подход, я построил десять и дал им посоревноваться.
Десять моделей охватывают пять семейств плюс простой базовый ориентир. Не нужно знать устройство каждой; важно, что они по‑разному моделируют появление голов.
| Семейство | Модели | Суть подхода |
|---|---|---|
| Базовый | Пуассон с усреднённой скоростью | Предполагает, что каждая команда забивает своё долгосрочное среднее, игнорируя признаки. Планка, которую остальные должны превзойти. |
| Статистический | Двумерный Пуассон, отрицательное биномиальное распределение | Непосредственно моделируют оба счётчика голов с помощью распределений для счёта событий. |
| Байесовский | Байесовский Пуассон (MCMC) | Та же идея счёта событий, но возвращает полный диапазон неопределённости вокруг каждой оценки. Гораздо требовательнее вычислительно: примерно в 100 раз медленнее при обучении. |
| Временные ряды | SARIMAX | Рассматривает результаты команды как последовательность во времени и экстраполирует её вперёд. |
| Машинное обучение | Ridge, Random Forest, XGBoost | Извлекают закономерности напрямую из признаков без жёстко заданного уравнения. |
| Глубокое обучение | LSTM, 1D CNN | Нейросети, ищущие последовательные и локальные паттерны в данных. |
При десяти кандидатах выбирать «на глаз» бессмысленно. Вместо этого каждая модель проходит три стадии, и код решает, переходит ли она дальше. Это и есть code-based deployment: модели продвигаются из одной среды в следующую автоматическими проверками, а не ручной настройкой, что сохраняет воспроизводимость и облегчает аудит.
Итак, какой подход оказался лучшим? Вот полный лидерборд на отложенной выборке по RPS (ниже — лучше):
| Модель | Holdout RPS |
|---|---|
| XGBoost | 0.18289 |
| Байесовский Пуассон | 0.18316 |
| Отрицательное биномиальное | 0.18373 |
| Двумерный Пуассон | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| Пуассон со средней скоростью (база) | 0.22872 |
Из результатов бросаются в глаза четыре момента:
 Вживую я не запускаю все десять. Держу более короткий состав: базовый средний ориентир для сравнения плюс три лучших. XGBoost и байесовский Пуассон занимают два первых места однозначно.
Вживую я не запускаю все десять. Держу более короткий состав: базовый средний ориентир для сравнения плюс три лучших. XGBoost и байесовский Пуассон занимают два первых места однозначно.
Третье место — фактически ничья: отрицательное биномиальное и двумерный Пуассон идут в пределах 0,0002 RPS и меняются местами в зависимости от случайного зерна, поэтому между статистически неразличимыми моделями я выбрал двумерный Пуассон — его постановка сильнее укоренилась в литературе по прогнозированию футбола (Karlis и Ntzoufras, 2004).
В итоге в составе остаются XGBoost (машинное обучение), двумерный Пуассон (классическая статистика) и байесовский Пуассон (байесовский вывод). Далее — как эти модели запускаются, переобучаются и превращают поматчевые прогнозы в прогноз всего турнира.
Модель, живущая в блокноте, полезна лишь пока вы перед ней сидите. Чтобы предсказывать матчи на протяжении месячного турнира, всё должно работать само: подтягивать новые результаты, переобучаться, пересимулировать и обновлять прогноз без вмешательства. Это задача конвейера.
Весь проект работает как одна запланированная задача на Google Cloud Run. До турнира — раз в день; с матча открытия 11 июня — каждые два часа. Каждый запуск проходит один и тот же цикл:
dvc repro пересобирает слои Silver и Gold, чтобы признаки были актуальны.Поскольку каждый шаг запускается по расписанию кодом, никакого ручного «нажимания кнопок» во время турнира нет. На вход — новый результат, на выход — обновлённый прогноз.
Здесь проект ещё и эксперимент. Во время турнира состав моделей работает в двух параллельных режимах, и отличие между ними — вопрос, на который я хочу получить ответ из данных: улучшает ли переобучение по ходу турнира качество прогнозов?
Параллельный запуск позволяет по завершении сравнить их по двум фронтам: по точности и по скорости сходимости неопределённости по мере сужения поля. Если выигрывает режим «по раундам», регулярное переобучение себя оправдывает; если «фиксированный» не уступает, лишняя сложность может быть не нужна.
Предсказать один матч — это одно. Превратить это в «каковы шансы каждой команды выиграть турнир» — здесь и нужна симуляция Монте‑Карло.
Сначала — вывод. Вместо прогнозов только по известным уже матчам модель предсказывает все возможные пары между 48 командами. Звучит избыточно, но в турнире любая команда может встретиться с любой в плей‑офф, значит, прогноз должен быть готов для каждой пары.
Затем нужно закодировать правила — а формат 2026 особенно неудобен. В 12 группах по две команды проходят автоматически, но также проходят восемь лучших, занявших третье место, и то, в какие слоты плей‑офф они попадут, зависит от того, из каких групп они пришли.
Есть 495 способов выбрать восемь групп из двенадцати (12 по 8), и каждый даёт свой набор пар в 1/16 финала. Чистой формулы нет — FIFA просто публикует таблицу. Поэтому я (точнее, мой очень способный коллега Cursor) захардкодил все 495 комбинаций в отображение, взяв за основу официальную таблицу.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Каждый ключ, вроде EFGHIJKL, перечисляет, какие восемь групп дали вышедших третьих, а значения размещают каждую из этих команд (3E, 3F и т. д.) в конкретный матч 1/16. Это одна запись; полное отображение повторяет её 495 раз — по одной на комбинацию.
Три хозяйки турнира (США, Канада и Мексика) требуют дополнительной обработки. Когда хозяин играет матч в своей стране, симуляция применяет поправку на фактор своего поля для этой встречи, а остальная часть турнира считается нейтральной.
Имея прогнозы и правила, симуляция проигрывает турнир 10 000 раз. В каждом прогоне выполняется процедура:
По 10 000 симуляций доля прогонов, в которых команда доходит до финала или берёт трофей, становится её вероятностью. Один прогон — предположение; десять тысяч — прогноз.
Каждый описанный запуск, в обоих режимах, логируется в MLflow (на DagsHub). Трекинг экспериментов — это систематическая запись входов, настроек, результатов и выходов каждого запуска, чтобы любой можно было сравнить или точно воспроизвести. Несколько моментов достойны внимания:
Обученные модели и сами файлы прогнозов (турнирные вероятности, таблицы групп и поматчевые предсказания) сохраняются как артефакты запусков — именно их читает живая панель. Кольцо замкнуто: от сырых результатов через обучение и симуляцию к цифрам, которые вы видите онлайн.
Последний компонент запускается после завершения матчей. По мере поступления реальных результатов поматчевые прогнозы оцениваются и сравниваются с простым базовым средним ориентиром. Если полные модели начинают уступать модели, ничего не знающей о командах, это сигнал о дрейфе: закономерности, выученные до турнира, больше не соответствуют происходящему на поле.
Следить за этим — стандартная практика для любой системы с живыми прогнозами. Подробнее о детекции — в этом руководстве по дрейфу данных и моделей.
После всей этой машинерии — вот ради чего всё.
На 10 июня 2026 года, за день до старта, вердикт модели на вершине ясен, а сразу за ней — плотная группа преследователей. Испания и Аргентина лидируют, примерно по 16% шансов поднять трофей. То, что действующие чемпионы мира (Аргентина) и действующие чемпионы Европы (Испания) оказываются на вершине, — отрезвляющая проверка здравым смыслом: модель приземлена в реальность.
Позади — плотная погоня: Франция, Англия, Бразилия и Колумбия замыкают круг самых вероятных победителей. Эти цифры живые и начнут меняться с первыми результатами, так что относитесь к ним как к снимку на 10 июня, а не к пророчеству. Панель всегда показывает актуальные числа с максимум двухчасовой задержкой.
К слову: все числа в статье берутся из живого приложения Streamlit, которое обновляется автоматически вместе с конвейером. Открывайте wc2026-predictions.streamlit.app и следите за турниром. В нём четыре основных вида:
Одна оговорка в виде матчей: у пары команд одновременно отображаются два возможных слота в 1/16. Это не баг. Так бывает, когда группа настолько ровная, что модель не может уверенно определить, какое квалификационное место займёт команда. В сочетании с неопределённостью по лучшим третьим это ведёт к разным слотам плей‑офф. В случае с Турцией это даже привело к тому, что они «оказались» дважды в 1/8.
Ниже — визуализация финальных раундов (с четвертьфиналов до финала), которые модель XGBoost проецирует перед стартом турнира:
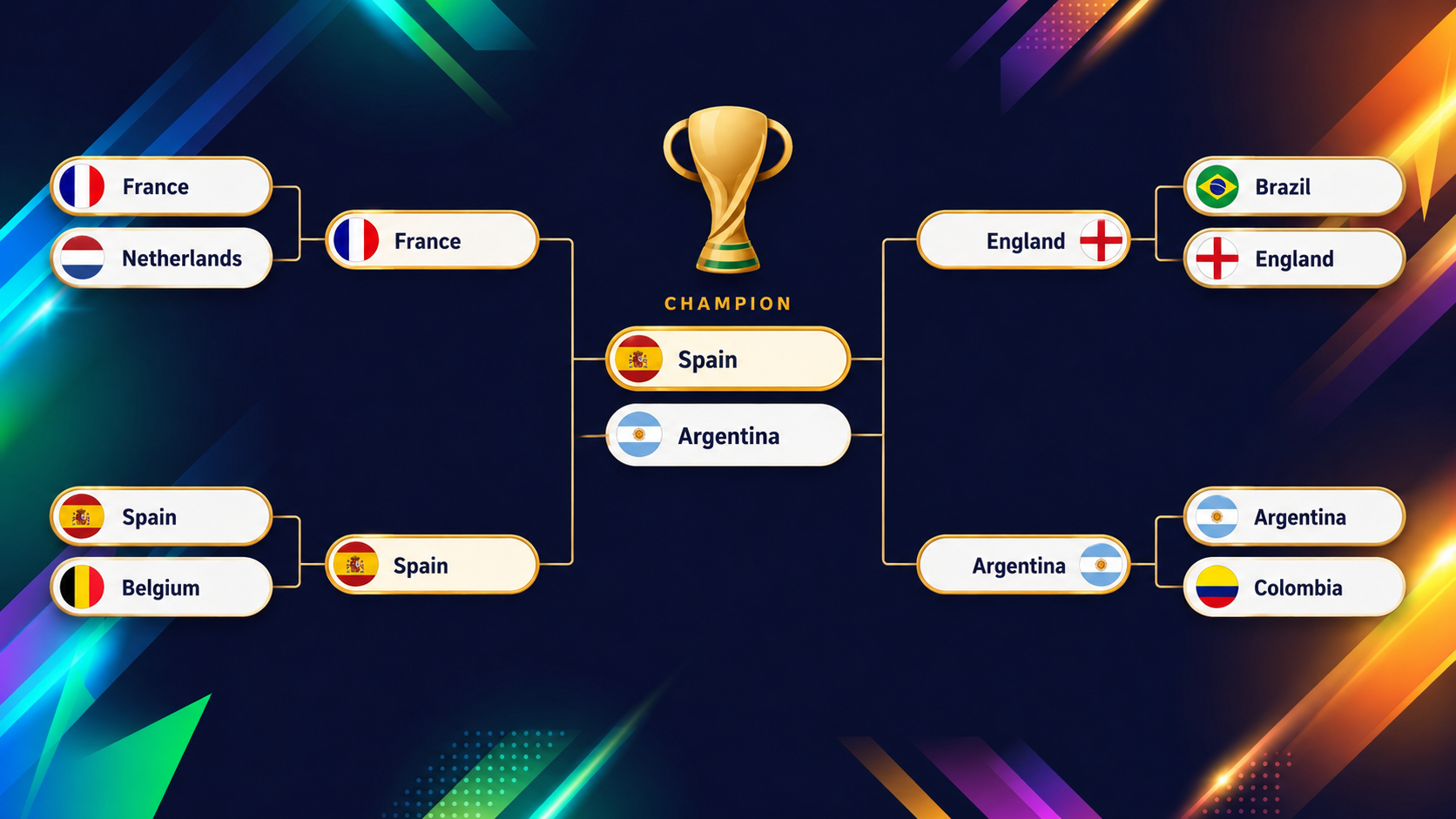
Самое интересное в такой модели — команды, которые расходятся с «тестом на глаз», и самый яркий пример — США. В обзоре турнира на панели вы сразу заметите, что США выделяются цветом.
Как соорганизаторы, играя дома, они могли бы ожидать комфортного старта, но модель куда осторожнее: всего около 54,6% шансов выйти из группы — это 13‑й с конца показатель в целом поле (помните, что из групп выходит целых две трети!), потому что их группа с Австралией, Парагваем и Турцией необычно ровная.
Интересно дальше. Пройдя на тоненького, США затем балансируют примерно на уровне «орёл‑решка» в каждом следующем раунде. Накопив эти подбрасывания, они получают около 2% шансов выиграть весь турнир — 13‑й показатель сверху из 48 команд.
Команда, которая идёт 13‑й снизу по шансам выйти из группы и 13‑й сверху по шансам выиграть турнир, — почти идеальное определение «команды‑подброса монеты»: никогда не фаворит, но и никогда не выбывает из борьбы.
Проект потребовал много работы и охватывает гораздо больше, чем вмещает одна статья. В репозитории есть многое, что не попало сюда: полный набор кандидатных моделей, инженерия признаков и оркестрация, которая всё это держит в работе.
А пока модель сделала свой выбор, и судить будет турнир. Независимо от того, пришли ли вы ради MLOps или ради футбола, надеюсь, вы будете наблюдать за его развитием с таким же интересом, как и я. Следите за живым прогнозом по мере поступления результатов и смотрите, насколько хорошо держатся предсказания.
Если хотите глубже взглянуть на некоторые упомянутые концепции, рекомендую наш курс MLOps Concepts.
Лучшие курсы по машинному обучению
Course
Course
Course