
Kurs
Machine Learning verstehen
2 Std.
299.3K
Eine Prognose ist nur so gut wie ihre Zutaten – deshalb beginnen wir mit dem Rohmaterial. Das Modell lernt aus zwei Live-Datenquellen und formt daraus eine einzige, saubere Feature-Tabelle.
Alles basiert auf zwei Quellen. API-Football liefert Spielpläne und Matchstatistiken: Wer spielte gegen wen, wann, wo und wie es endete. eloratings.net liefert Elo-Ratings für jedes Nationalteam.
Ein Elo-Rating ist eine Zahl, die die Stärke eines Teams abbildet. Jedes Team liegt irgendwo auf dieser Skala, und nach jedem Spiel aktualisiert sich der Wert: Sieg gegen einen stärkeren Gegner bringt viel Plus, Niederlage gegen einen schwächeren viel Minus. Die Idee kommt aus dem Schach und passt gut auf Fußball. Eine ausführliche Einführung findest du in diesem früheren DataCamp-Artikel zur WM 2022.
Zusammen ergeben beide Quellen ein Gold-Dataset mit rund 6.900 Länderspielen seit 2018 zum Lernen.
Hier die erste wichtige Designentscheidung: Statt das Ergebnis direkt als Sieg, Remis oder Niederlage zu tippen, sagt das Modell etwas Feineres voraus – die Anzahl der Tore pro Team. Torzahlen im Fußball folgen näherungsweise einer Poisson-Verteilung, dem Standard, um seltene Ereignisse in einem festen Zeitfenster zu modellieren.
Tore statt Resultate zu prognostizieren macht alles Weitere möglich. Sobald das Modell für jedes Duell plausible Spielstände liefern kann, lassen sich die eigentlichen Fragen – wer übersteht die Gruppe, wer holt den Pokal – beantworten, indem man diese Spielstände tausendfach simuliert.
Jedes Spiel wird durch eine kleine, bewusst ausgewählte Feature-Menge beschrieben:
Alle Features sind strikt leakage-sicher – sie nutzen ausschließlich Informationen, die vor Anpfiff vorlagen. Klingt selbstverständlich, ist aber einer der häufigsten Wege, versehentlich ein Modell zu bauen, das im Test glänzt und in der Praxis scheitert.
Ein verworfener Ansatz: Geplant waren "Spielstil"-Features aus Clustering der In-Game-Statistiken, also ein Schritt Unsupervised Learning. In der Praxis ergaben sich keine sinnvollen Cluster – statt Rauschen zu füttern, habe ich es weggelassen. Auch negative Ergebnisse sind Ergebnisse.
Wenn Daten fortlaufend aus zwei Quellen eintrudeln, muss der Weg von Rohdaten zu modellfertigen Features jedes Mal identisch sein. Genau das liefert eine Medallion-Architektur mit drei Schichten:
Jede Schicht speist die nächste. Wenn etwas komisch aussieht, kann ich schrittweise zurückverfolgen, statt alles auf einmal zu entwirren. Für Reproduzierbarkeit nutze ich DVC (Data Version Control). Kommen neue Ergebnisse rein, baut ein dvc repro Silver und Gold aus Bronze neu – Schritte werden nur neu gerechnet, wenn sich ihre Inputs geändert haben – und versioniert die resultierenden Datasets, sodass frühere Stände exakt wiederherstellbar sind.
Tore vorherzusagen ist gut erforscht – ein klares "One-Size-Fits-All"-Tool gibt es nicht. Also habe ich zehn Ansätze gebaut und gegeneinander antreten lassen.
Die zehn Modelle decken fünf Familien plus eine einfache Baseline ab. Die Interna musst du nicht kennen – wichtig ist, dass sie sehr unterschiedliche Annahmen darüber treffen, wie Tore entstehen.
| Familie | Modelle | Kernidee |
|---|---|---|
| Baseline | Mean-rate Poisson | Nimmt an, jedes Team erzielt einfach seinen langfristigen Durchschnitt – ignoriert alle Features. Die Unterkante, die alle anderen schlagen müssen. |
| Statistik | Bivariate Poisson, Negative Binomial | Modelliert die beiden Torzahlen direkt mit Zählverteilungen. |
| Bayes | Bayesian Poisson (MCMC) | Gleiche Grundidee, liefert aber eine vollständige Unsicherheitsverteilung um jede Schätzung. Deutlich rechenintensiver: etwa 100-mal langsamer zu fitten. |
| Zeitreihen | SARIMAX | Behandelt Teamresultate als Sequenz über die Zeit und projiziert sie nach vorn. |
| Machine Learning | Ridge, Random Forest, XGBoost | Lernt Muster direkt aus den Features ohne feste Funktionsform. |
| Deep Learning | LSTM, 1D CNN | Neuronale Netze, die sequentielle und lokale Muster suchen. |
Bei zehn Kandidaten geht Augenmaß nicht. Jedes Modell durchläuft drei Stufen – und der Code entscheidet, ob es weiterkommt. Das ist Code-basierte Deployment: Modelle werden per automatischer Checks in die nächste Umgebung befördert, nicht per Handabstimmung – dadurch bleibt die Auswahl reproduzierbar und prüfbar.
Welcher Ansatz gewann? Hier das vollständige Holdout-Ranking nach RPS (niedriger ist besser):
| Modell | Holdout RPS |
|---|---|
| XGBoost | 0,18289 |
| Bayesian Poisson | 0,18316 |
| Negative Binomial | 0,18373 |
| Bivariate Poisson | 0,18389 |
| Random Forest | 0,18392 |
| SARIMAX | 0,18583 |
| Ridge | 0,18813 |
| LSTM | 0,19299 |
| 1D CNN | 0,20916 |
| Mean-rate Poisson (Baseline) | 0,22872 |
Vier Punkte stechen heraus:
 Für das Live-Turnier laufen nicht alle zehn Modelle. Ich behalte eine kleinere Auswahl: die Mean-Rate-Baseline als Referenz und die drei besten Performer. XGBoost und Bayesian Poisson belegen die ersten beiden Plätze.
Für das Live-Turnier laufen nicht alle zehn Modelle. Ich behalte eine kleinere Auswahl: die Mean-Rate-Baseline als Referenz und die drei besten Performer. XGBoost und Bayesian Poisson belegen die ersten beiden Plätze.
Platz drei ist de facto ein Unentschieden: Negative Binomial und Bivariate Poisson liegen innerhalb von 0,0002 RPS und tauschen je nach Zufallssamen die Plätze. Zwischen zwei statistisch nicht unterscheidbaren Modellen habe ich den Bivariate Poisson gewählt – seine Formulierung ist in der Fußball-Modeling-Literatur (Karlis & Ntzoufras, 2004) besser verankert.
Damit besteht das Aufgebot aus XGBoost (Machine Learning), Bivariate Poisson (klassische Statistik) und Bayesian Poisson (Bayes-Inferenz). Im nächsten Abschnitt geht es darum, wie diese Modelle laufen, neu trainieren und aus Spielprognosen eine Turnierprognose werden lassen.
Ein Modell im Notebook ist nur nützlich, solange du davor sitzt. Für ein einmonatiges Turnier muss alles autonom laufen: neue Ergebnisse ziehen, neu trainieren, neu simulieren und die Prognose aktualisieren – ohne manuelles Zutun. Das übernimmt die Pipeline.
Das gesamte Projekt läuft als geplanter Job auf Google Cloud Run. Vor Turnierstart einmal täglich; ab dem Eröffnungsspiel am 11. Juni alle zwei Stunden. Jeder Lauf folgt demselben Zyklus:
dvc repro die Silver- und Gold-Schichten aktualisiert.Weil jeder Schritt zeitgesteuert per Code läuft, braucht es während des Turniers keine manuellen Klicks. Neue Ergebnisse rein, frische Prognose raus.
Hier wird das Projekt zum Experiment. Während des Turniers laufen zwei Modi parallel – und der Unterschied beantwortet die Kernfrage: Verbessert Retraining im Turnierverlauf die Vorhersagen?
Beides nebeneinander erlaubt nach Turnierende den Vergleich in zwei Dimensionen: reine Prognosegüte und wie schnell sich die Unsicherheit abbaut, wenn das Feld schrumpft. Setzt sich der rundenweise Modus durch, lohnt sich regelmäßiges Retraining; hält das Eingefrorene mit, ist der Mehraufwand fraglich.
Ein einzelnes Spiel zu prognostizieren ist das eine. Daraus die Frage "Wie hoch ist die Chance jedes Teams, das Turnier zu gewinnen?" zu beantworten, ist die Aufgabe der Monte-Carlo-Simulation.
Zuerst die Inferenz. Das Modell sagt nicht nur feststehende Paarungen voraus, sondern alle möglichen Duelle der 48 Teams. Das klingt viel, ist aber nötig – im K.-o.-Baum kann jede Paarung auftreten, also braucht es eine Vorhersage für jedes mögliche Matchup.
Dann müssen die Turnierregeln codiert werden – das 2026-Format ist dabei besonders sperrig. Aus 12 Gruppen kommen die Top 2 sicher weiter, dazu die 8 besten Dritten. Welche K.-o.-Slots diese acht belegen, hängt davon ab, aus welchen Gruppen sie stammen.
Es gibt 495 Möglichkeiten, aus zwölf Gruppen acht zu wählen (zwölf über acht) – jede führt zu einem anderen Round-of-32-Schema. Eine saubere Formel gibt es nicht; die FIFA veröffentlicht schlicht eine Tabelle. Also habe ich (genauer: mein sehr fähiger Kollege Cursor) alle 495 Kombinationen anhand der offiziellen Tabelle hart codiert.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Jeder Schlüssel wie EFGHIJKL listet, aus welchen acht Gruppen die Drittplatzierten kamen; die Werte ordnen diese Teams (3E, 3F usw.) konkreten Spielen der Runde der 32 zu. Das ist ein Eintrag – die vollständige Mapping-Datei wiederholt das 495-mal, einmal pro Kombination.
Die drei Gastgeber (USA, Kanada, Mexiko) brauchen eine Sonderbehandlung. Spielt ein Gastgeber im eigenen Land, wendet die Simulation für diese Partie einen Heimvorteil an; der Rest des Turniers gilt als neutrales Terrain.
Mit Vorhersagen und Regeln ausgestattet, läuft die Simulation 10.000 Turniere durch. Pro Lauf passiert Folgendes:
Über 10.000 simulierte Turniere wird der Anteil der Läufe, in denen ein Team das Finale erreicht oder den Pokal holt, zu dessen Wahrscheinlichkeit. Ein Lauf ist ein Ratespiel; zehntausend Läufe sind eine Prognose.
Jeder Lauf in beiden Modi wird in MLflow (gehostet auf DagsHub) geloggt. Experiment-Tracking heißt: Inputs, Einstellungen, Ergebnisse und Outputs systematisch erfassen, um Läufe zu vergleichen oder exakt zu reproduzieren. Ein paar Highlights:
Trainierte Modelle und Vorhersagedateien (Turnierwahrscheinlichkeiten, Gruppenstände, Spielprognosen) werden als Artefakte gespeichert – genau diese Dateien liest das Live-Dashboard. Damit schließt sich der Kreis: von Rohdaten über Training und Simulation bis zu den Zahlen, die du online siehst.
Der letzte Baustein läuft, sobald Spiele entschieden sind. Echte Ergebnisse werden mit den dafür abgegebenen Prognosen abgeglichen und gegen die einfache Mean-Rate-Baseline verglichen. Wenn die großen Modelle gegenüber einem Team-blinden Basismodell an Boden verlieren, ist das ein Drift-Signal: Die vor dem Turnier gelernten Muster passen nicht mehr zum Geschehen auf dem Platz.
Solches Monitoring ist Standard für jedes System mit Live-Prognosen. Mehr dazu in diesem Guide zu Data Drift und Model Drift.
Nach all der Technik kommt hier der Zweck dahinter.
Stand 10. Juni 2026, einen Tag vor dem Eröffnungsspiel, ist das Bild an der Spitze klar – und dahinter eng. Spanien und Argentinien führen das Feld mit jeweils rund 16 % Titelchance an. Dass der amtierende Weltmeister (Argentinien) und der amtierende Europameister (Spanien) oben stehen, ist ein gutes Plausibilitätszeichen.
Dahinter jagt ein enges Feld: Frankreich, England, Brasilien und Kolumbien komplettieren die wahrscheinlichsten Sieger. Diese Zahlen sind live und bewegen sich mit jedem Ergebnis – also Schnappschuss vom 10. Juni, keine Weissagung. Das Dashboard zeigt stets den aktuellen Stand, mit maximal zwei Stunden Verzögerung.
Alle Zahlen in diesem Artikel stammen aus einer laufenden Streamlit-App, die sich automatisch mit der Pipeline aktualisiert. Du findest sie unter wc2026-predictions.streamlit.app. Vier Hauptansichten:
Eine Besonderheit in der Spielansicht: Einige Teams tauchen gleichzeitig in zwei möglichen Round-of-32-Slots auf. Das ist kein Bug. Es passiert, wenn eine Gruppe so ausgeglichen ist, dass das Modell die genaue Quali-Position nicht sicher trennen kann. Zusammen mit der Unsicherheit um die besten Dritten führt das zu unterschiedlichen K.-o.-Slots. Bei der Türkei resultierte das sogar in einem doppelten Achtelfinal-Einzug.
Die folgende Grafik zeigt die Schlussrunden (Viertelfinale bis Finale), die das XGBoost-Modell vor Turnierstart projiziert:
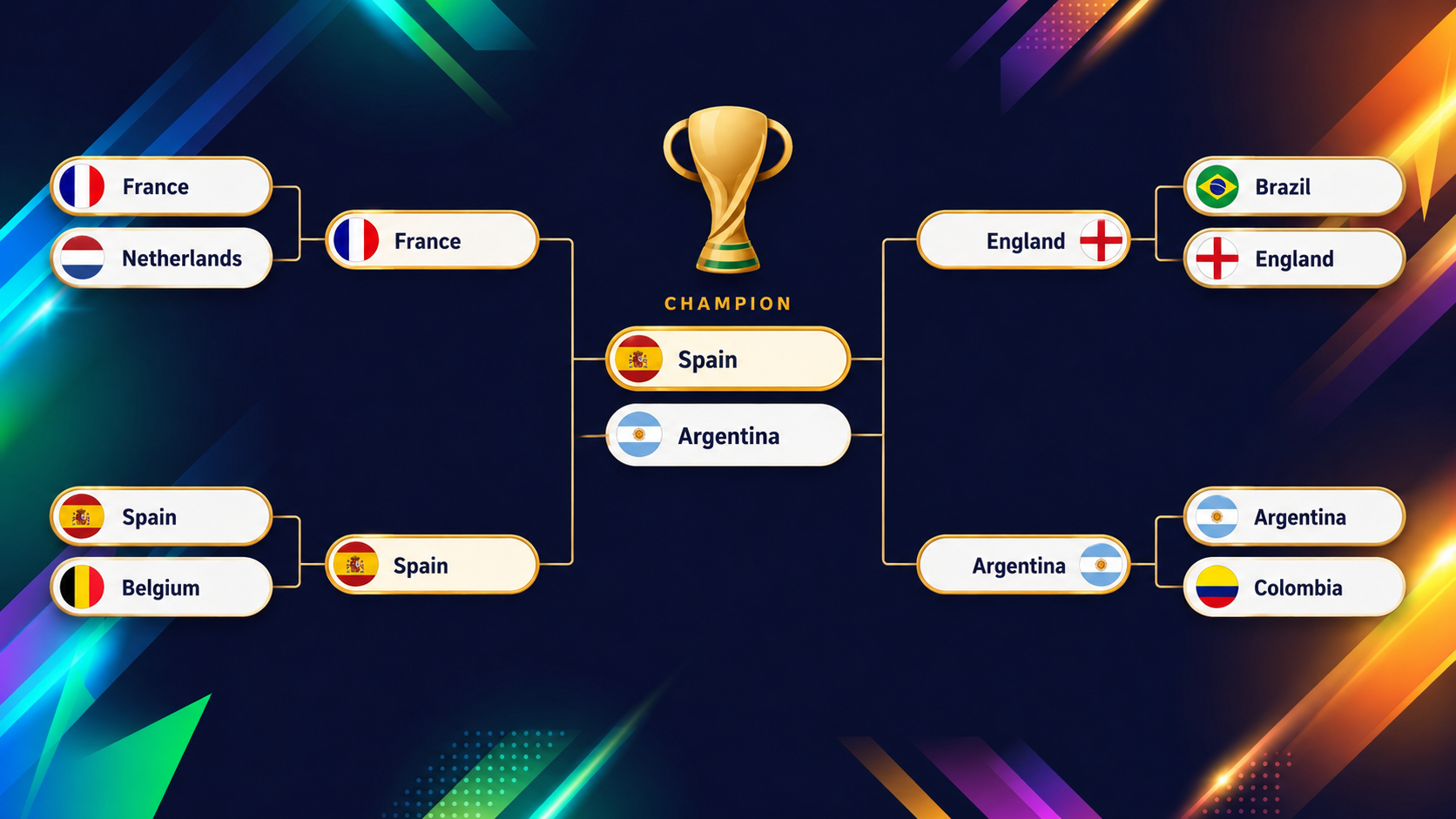
Der Reiz eines solchen Modells liegt in Teams, die dem Bauchgefühl widersprechen – bestes Beispiel: die USA. Im Turnierüberblick fällt die USA sofort farblich auf.
Als Co-Gastgeber mit Heimfans könnte man einen bequemen Start erwarten, doch das Modell ist vorsichtiger: Es gibt ihnen nur etwa 54,6 % Chance, die Gruppe zu überstehen – die 13.-niedrigste im gesamten Feld (denk daran: Zwei Drittel der Teams kommen weiter!). Grund ist eine ungewöhnlich ausgeglichene Gruppe mit Australien, Paraguay und der Türkei.
Interessant wird es danach: Schaffen sie es durch die Gruppe, liegen die USA in jeder folgenden Runde ungefähr bei Münzwurfchancen. Stapelst du diese Münzwürfe, ergibt sich rund 2 % Titelchance – die 13.-höchste unter allen 48 Teams.
Ein Team, das beim Gruppenaus 13.-schlechteste und beim Titelgewinn 13.-beste Chancen hat, ist die perfekte Definition eines Münzwurf-Teams: selten Favorit, nie chancenlos.
Das Projekt war viel Arbeit und deckt mehr ab, als in einen Artikel passt. Im Repo findest du vieles, das hier fehlte – die komplette Modellkandidatenliste, Feature Engineering und die Orchestrierung, die alles am Laufen hält.
Fürs Erste hat das Modell getippt – das Turnier spricht das Urteil. Ob du wegen MLOps oder wegen Fußball hier bist: Ich hoffe, du hast beim Verfolgen genauso viel Spaß wie ich. Das Live-Forecast aktualisiert sich mit jedem Spiel – schau, wie gut die Prognosen halten.
Wenn du einige der Konzepte vertiefen willst, empfehlen wir unseren Kurs MLOps Concepts.
Top-Kurse zu Machine Learning
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Zoumana Keita
15 Min.
Blog
Matt Crabtree
14 Min.
Tutorial
Matt Crabtree
Tutorial
Laiba Siddiqui
