course
Wprowadzenie do uczenia maszynowego
2 godz.
299.3K
Prognoza jest tak dobra, jak dane wejściowe, więc warto zacząć od surowców. Model uczy się z dwóch źródeł na żywo i łączy je w jedną, uporządkowaną tabelę cech.
Wszystko opiera się na dwóch miejscach. API-Football dostarcza terminarze i statystyki meczowe: kto z kim grał, kiedy, gdzie i jak się skończyło. eloratings.net dostarcza rankingi Elo dla każdej reprezentacji.
Ocena Elo to pojedyncza liczba oddająca siłę drużyny. Każda ekipa ma swoje miejsce na skali, a po każdym meczu rating się aktualizuje: pokonasz silniejszego – zyskujesz dużo; przegrasz ze słabszym – mocno spadasz. Pomysł pochodzi z szachów i dobrze adaptuje się do piłki. Jeśli chcesz pełnej intuicji, ten wcześniejszy tekst DataCamp omawia to na przykładzie mundialu 2022.
Razem te źródła dają zbiór Gold ok. 6900 meczów międzynarodowych od 2018 r., na których można się uczyć.
Oto pierwszy ważny wybór projektowy. Zamiast bezpośrednio przewidywać wynik jako wygraną, remis lub porażkę, model przewiduje coś bardziej granularnego: liczbę goli każdej z drużyn w meczu. Liczby goli w piłce nożnej w przybliżeniu podlegają rozkładowi Poissona, standardowemu sposobowi modelowania tego, jak często rzadkie zdarzenie zachodzi w stałym oknie czasu.
Przewidywanie goli zamiast wyniku umożliwia wszystko, co dalej. Gdy model potrafi wygenerować wiarygodny wynik bramkowy dla dowolnego starcia, na pytania, które wszystkich naprawdę interesują – kto wyjdzie z grupy i kto podniesie puchar – można odpowiedzieć, symulując te wyniki tysiące razy.
Każdy mecz opisuje niewielki, starannie dobrany zestaw cech:
Każda cecha jest ściśle bezwyciekowa, czyli korzysta wyłącznie z informacji dostępnych przed pierwszym gwizdkiem. Brzmi banalnie, ale to jeden z najłatwiejszych sposobów, by niechcący zbudować model błyszczący w testach i rozsypujący się w realu.
Pomysł, który odpadł: planowałem zestaw cech „stylu gry” zbudowanych przez klastrowanie drużyn na podstawie statystyk meczowych, czyli krok uczenia bez nadzoru. W praktyce zespoły nie podzieliły się na sensowne grupy, więc zamiast karmić model szumem, odpuściłem. Negatywne wyniki to też wyniki.
Przy danych napływających z dwóch źródeł w trybie ciągłym, ścieżka od plików surowych do cech gotowych pod model musi być identyczna za każdym razem. Tę gwarancję daje architektura medalionowa. Organizuje ona dane w trzy warstwy:
Każda warstwa zasila następną, więc gdy coś wygląda podejrzanie, mogę śledzić problem etap po etapie zamiast rozplątywać wszystko naraz. Aby całą ścieżkę uczynić odtwarzalną, używam DVC (Data Version Control). Gdy pojawią się świeże wyniki, jedno dvc repro odbudowuje Silver i Gold z Bronze, ponownie uruchamiając krok tylko wtedy, gdy zmieniły się jego wejścia, i wersjonuje powstałe zbiory, by każde wcześniejsze stadium dało się dokładnie odtworzyć.
Prognozowanie goli jest dobrze zbadanym problemem i nie ma jednego oczywistego narzędzia. Zamiast więc od razu wiązać się z jedną metodą, zbudowałem dziesięć i pozwoliłem im rywalizować.
Dziesięć modeli obejmuje pięć rodzin plus prosty baseline. Nie musisz znać wnętrzności każdego; ważne, że przyjmują bardzo różne założenia co do powstawania goli.
| Rodzina | Modele | Główny pomysł |
|---|---|---|
| Baseline | Poisson o średniej częstości | Zakłada, że każda drużyna strzela po prostu swoją długookresową średnią, ignorując wszystkie cechy. Poprzeczka do pobicia przez pozostałych. |
| Statystyczne | Biwariacyjny Poisson, Ujemny dwumian | Modelują bezpośrednio obie liczby goli rozkładami zbudowanymi do zliczania zdarzeń. |
| Bayesowskie | Bayesowski Poisson (MCMC) | Ten sam pomysł zliczania, ale zwraca pełen zakres niepewności wokół każdej estymaty. Znacznie bardziej wymagający obliczeniowo: ok. 100 razy wolniejszy w dopasowaniu od reszty. |
| Szeregowe | SARIMAX | Traktuje wyniki drużyny jako sekwencję w czasie i rzutuje ją w przód. |
| Uczenie maszynowe | Ridge, Random Forest, XGBoost | Uczą wzorców prosto z cech bez narzucania stałego równania. |
| Głębokie uczenie | LSTM, 1D CNN | Sieci neuronowe szukające wzorców sekwencyjnych i lokalnych w danych. |
Przy dziesięciu kandydatach wybieranie zwycięzcy „na oko” nie miało sensu. Zamiast tego każdy model przechodzi trzy etapy i to kod decyduje, czy idzie dalej. O to chodzi w wdrożeniu sterowanym kodem: modele są promowane z jednego środowiska do następnego przez automatyczne testy, a nie ręczne strojenie, więc cały wybór pozostaje odtwarzalny i łatwy do audytu.
Które podejście okazało się najlepsze? Oto pełna tabela wyników na zbiorze testowym, oceniona RPS (niżej = lepiej):
| Model | RPS holdout |
|---|---|
| XGBoost | 0.18289 |
| Bayesowski Poisson | 0.18316 |
| Ujemny dwumian | 0.18373 |
| Biwariacyjny Poisson | 0.18389 |
| Random Forest | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| Poisson o średniej częstości (baseline) | 0.22872 |
Z tych wyników wynikają cztery rzeczy:
 W turnieju na żywo nie uruchamiam całej dziesiątki. Zostawiam mniejszy skład: baseline o średniej jako punkt odniesienia oraz trzy najlepsze. XGBoost i Bayesowski Poisson zajmują dwa pierwsze miejsca.
W turnieju na żywo nie uruchamiam całej dziesiątki. Zostawiam mniejszy skład: baseline o średniej jako punkt odniesienia oraz trzy najlepsze. XGBoost i Bayesowski Poisson zajmują dwa pierwsze miejsca.
Trzecie miejsce to de facto remis: Ujemny dwumian i Biwariacyjny Poisson kończą w różnicy 0,0002 RPS i zamieniają się miejscami w zależności od ziarna losowego, więc spośród statystycznie nieodróżnialnych modeli wybrałem Biwariacyjnego Poissona, którego sformułowanie ma silniejsze umocowanie w literaturze przewidywania futbolu (Karlis i Ntzoufras, 2004).
To zostawia skład: XGBoost (uczenie maszynowe), Biwariacyjny Poisson (statystyka klasyczna) i Bayesowski Poisson (wnioskowanie bayesowskie). W następnej sekcji – jak te modele działają, uczą się na nowo i zamieniają prognozy pojedynczych meczów w przewidywania całego turnieju.
Model żyjący w notatniku jest użyteczny tylko wtedy, gdy siedzisz przed nim. By przewidywać mecze przez miesiąc trwania turnieju, wszystko musi działać samo: pobierać nowe wyniki, trenować się na nowo, symulować i odświeżać prognozę bez czyjejkolwiek ingerencji. To rola pipeline’u.
Cały projekt działa jako jedno zadanie harmonogramowane na Google Cloud Run. Przed turniejem budzi się raz dziennie; od meczu otwarcia 11 czerwca – co dwie godziny. Każdy przebieg to ten sam cykl:
dvc repro odbudowuje warstwy Silver i Gold, by cechy były aktualne.Ponieważ każdy krok wyzwala kod według harmonogramu, w trakcie turnieju nie ma ręcznego klikania. Nowy wynik wpada – odświeżona prognoza wypada.
Tu projekt pełni też rolę eksperymentu. W trakcie turnieju skład działa równolegle w dwóch trybach, a różnica między nimi to pytanie, na które chcę odpowiedzieć danymi: czy ponowne trenowanie w miarę trwania turnieju poprawia trafność prognoz?
Uruchamianie obu obok siebie pozwala po wszystkim porównać je na dwóch frontach: surowej trafności i tego, jak szybko rozwiązuje się niepewność, gdy pole się zawęża. Jeśli wygrywa tryb na rundę, regularne ponowne trenowanie ma sens; jeśli zamrożony daje radę, dodatkowa maszyneria może nie być warta zachodu.
Przewidzieć jeden mecz to jedno. Zamienić to w „jakie są szanse każdej drużyny na mistrzostwo” – tu wchodzi symulacja Monte Carlo.
Najpierw inferencja. Zamiast przewidywać tylko znane już pary, model przewiduje każde możliwe zestawienie 48 drużyn. Brzmi przesadnie, ale w turnieju każda może trafić na każdą w fazie pucharowej, więc prognoza musi być gotowa dla każdej pary.
Potem trzeba zakodować zasady, a format 2026 szczególnie to komplikuje. Z 12 grup dwie pierwsze awansują automatycznie, ale także osiem najlepszych ekip z trzecich miejsc, a to, w które miejsce drabinki trafi każda z tych ośmiu, zależy od tego, z których grup pochodzą.
Jest 495 sposobów wyboru ośmiu kwalifikujących się grup z dwunastu („dwanaście po osiem”), a każdy daje inny zestaw par w 1/16 finału. Nie ma na to eleganckiego wzoru; FIFA po prostu publikuje tabelę. Więc ja (a właściwie mój bardzo sprawny kolega Cursor) zahardkodowałem wszystkie 495 kombinacji do mapowania, biorąc za źródło oficjalną tabelę.
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...Każdy klucz, jak EFGHIJKL, wymienia, które osiem grup dostarczyło awansujące ekipy z trzecich miejsc, a wartości wstawiają każdą z tych drużyn (3E, 3F itd.) do konkretnego numeru meczu w 1/16 finału. To jeden wpis; pełne mapowanie powtarza to 495 razy, po jednym na kombinację.
Trzej gospodarze (Stany Zjednoczone, Kanada i Meksyk) dostają dodatkowe traktowanie. Gdy gospodarz gra mecz w swoim kraju, symulacja stosuje korektę atutu własnego boiska w tym spotkaniu, podczas gdy reszta turnieju jest traktowana jako teren neutralny.
Mając prognozy i zasady, symulacja rozgrywa cały turniej 10 000 razy. W każdym przebiegu postępuje tak:
W 10 000 symulowanych turniejach udział przebiegów, w których drużyna dociera do finału lub podnosi puchar, staje się jej prawdopodobieństwem. Jeden przebieg to zgadywanka; dziesięć tysięcy – prognoza.
Każdy opisany dotąd przebieg, w obu trybach, jest logowany do MLflow (hostowanego na DagsHub). Śledzenie eksperymentów oznacza systematyczne zapisywanie wejść, ustawień, wyników i wyjść każdego przebiegu, by dowolny z nich dało się porównać z innymi lub dokładnie odtworzyć. Warto wymienić kilka rzeczy, które rejestruje:
Wytrenowane modele i same pliki z prognozami (prawdopodobieństwa turniejowe, tabele grup i przewidywania meczów) są zapisywane jako artefakty przebiegów i to dokładnie te pliki czyta live dashboard. Domyka to pętlę: od surowych wyników, przez trenowanie i symulację, po liczby widoczne online.
Ostatni element działa po zakończeniu meczów. Gdy spływają realne wyniki, prognozy dla nich są punktowane i porównywane z prostym baseline’em o średniej częstości. Jeśli pełne modele zaczynają przegrywać z modelem, który nic nie wie o drużynach, to sygnał dryfu: wzorce wyuczone przed turniejem mogą nie pasować do tego, co dzieje się na boisku.
Takie monitorowanie to standard w systemach z prognozami na żywo, a więcej o wykrywaniu przeczytasz w tym przewodniku po dryfie danych i modeli.
Po całej tej maszynerii – o to w niej chodzi.
Na 10 czerwca 2026, dzień przed meczem otwarcia, werdykt modelu jest jasny na samym szczycie i ciasny tuż za nim. Hiszpania i Argentyna prowadzą w stawce, każda z ok. 16% szans na tytuł. To, że aktualni mistrzowie świata (Argentyna) i aktualni mistrzowie Europy (Hiszpania) są na czele, to kojący sanity check, że model stoi twardo na ziemi.
Za nimi jest równy pościg: Francja, Anglia, Brazylia i Kolumbia domykają grono najbardziej prawdopodobnych zwycięzców. To liczby na żywo i ruszą się, gdy tylko spłyną realne wyniki, więc traktuj je jako migawkę z 10 czerwca, nie wyrocznię. Dashboard zawsze pokazuje aktualne dane, z maksymalnym opóźnieniem dwóch godzin.
A skoro o tym mowa: każda liczba w tym artykule pochodzi z live aplikacji Streamlit, która aktualizuje się automatycznie wraz z pipeline’em. Otworzysz ją pod wc2026-predictions.streamlit.app i możesz śledzić turniej. Ma cztery główne widoki:
Jedna rzecz warta uwagi w widoku meczów: kilka drużyn pojawia się naraz w dwóch możliwych slotach 1/16 finału. To nie błąd. Dzieje się tak, gdy grupa jest tak wyrównana, że model nie potrafi pewnie wskazać pozycji kwalifikacyjnej zespołu. W połączeniu z niepewnością najlepszych trzecich te dwa scenariusze prowadzą do różnych miejsc w drabince. W przypadku Turcji skończyło się to nawet podwójną obecnością w 1/8 finału.
Poniższa grafika pokazuje ostatnie rundy (ćwierćfinały aż do finału), które model XGBoost prognozuje przed startem turnieju:
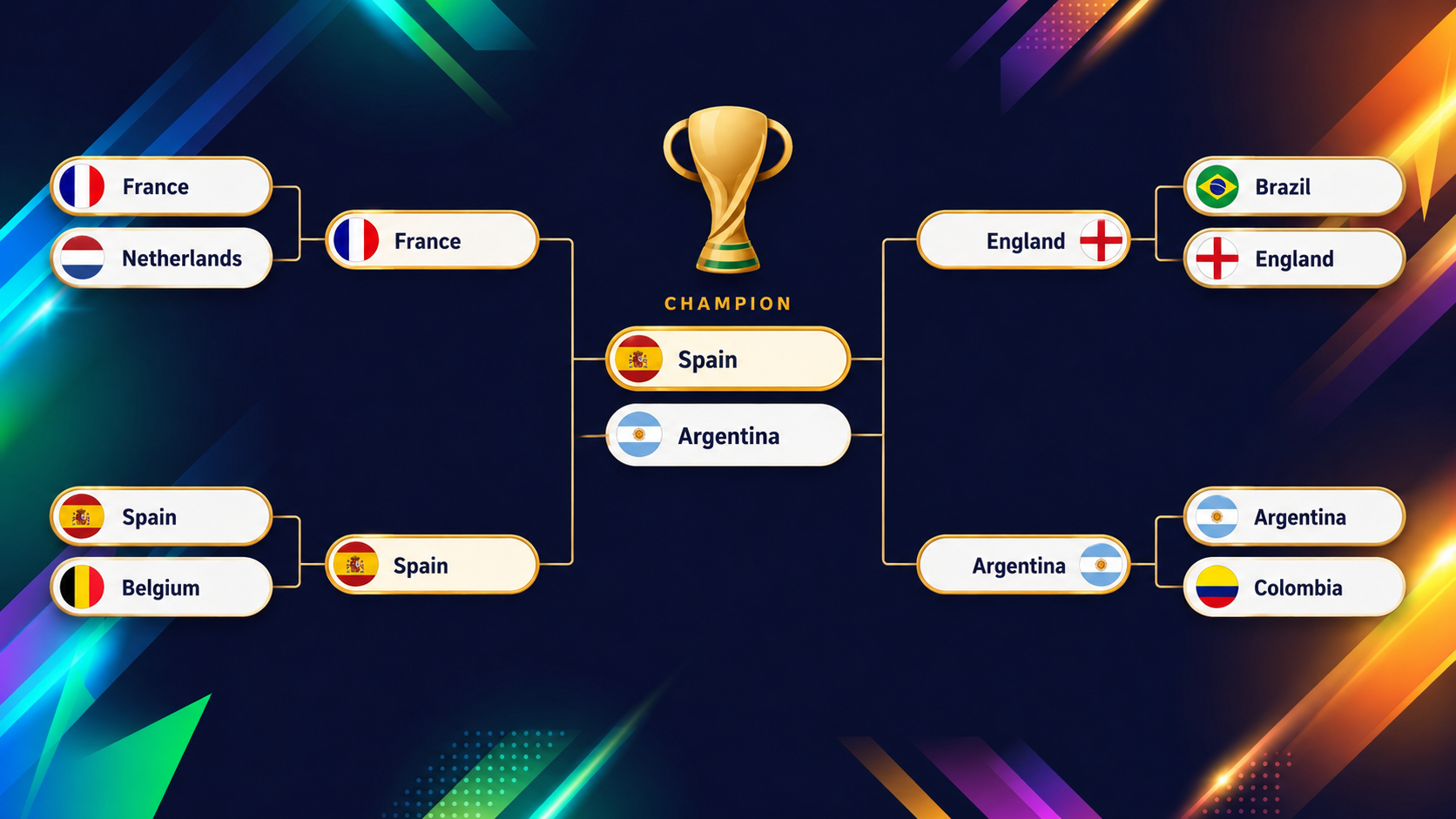
Frajda z takiego modelu tkwi w ekipach, które przeczą „testowi oka”, a najczystszy przykład to Stany Zjednoczone. Jeśli wejdziesz do przeglądu turnieju na dashboardzie, od razu zauważysz, że USA wyróżniają się kolorem.
Jako współgospodarze, grając u siebie, możesz oczekiwać komfortowego startu, ale model jest znacznie ostrożniejszy: daje im tylko ok. 54,6% szans na wyjście z grupy – 13. najniższy wynik w całym polu (pamiętaj, że awansuje dwie trzecie drużyn!) – bo ich grupa z Australią, Paragwajem i Turcją jest wyjątkowo równa.
Ciekawe jest to, co później. Po wydostaniu się z grupy USA balansują mniej więcej na rzucie monetą w każdej kolejnej rundzie. Zsumuj te monety i wychodzi ok. 2% szans na wygranie całego turnieju, co jest 13. najwyższym wynikiem z 48.
Ekipa, która jest 13. od dołu pod względem wyjścia z grupy i 13. od góry pod względem tytułu, to niemal idealna definicja „drużyny rzutów monetą”: nigdy faworyt, nigdy bez szans.
Ten projekt wymagał sporo pracy i obejmuje więcej, niż zmieści jeden artykuł. W repo znajdziesz rzeczy, które tu się nie zmieściły: pełen zestaw modeli kandydujących, inżynierię cech i orkiestrację, która to wszystko spina.
Na teraz model wytypował swoich faworytów, a sędzią będzie turniej. Niezależnie, czy przyszedłeś po MLOps, czy po piłkę, mam nadzieję, że będziesz czerpać z tego tyle frajdy co ja. Możesz śledzić prognozy na żywo wraz z napływem meczów i zobaczyć, jak trzymają się przewidywania.
Jeśli chcesz przyjrzeć się bliżej niektórym wspomnianym koncepcjom, polecam nasz kurs MLOps Concepts.
Najlepsze kursy uczenia maszynowego
course
course
course