Courses
理解机器学习
2小时
299.3K
预测的好坏取决于输入的数据,因此从原材料讲起很有必要。模型从两个实时数据源学习,并将其整理为一张整洁的特征表。
一切都来自两个地方。API-Football 提供赛程与逐场统计:谁对谁、何时、何地、比分如何。eloratings.net 提供各国家队的 Elo 评分。
Elo 评分是衡量球队强弱的单一数值。每支球队都位于这条刻度上的某处,每场比赛后评分都会更新:击败更强对手涨分更多,输给更弱对手会大幅降分。该理念源自国际象棋,非常适合迁移到足球。若想全面理解,这篇早前的 DataCamp 文章以 2022 年世界杯为例进行了讲解。
两者结合后,得到一份金层(Gold)数据集,可从 2018 年以来约 6,900 场国家队比赛中学习。
首先要做的关键设计选择是:与其直接预测胜、平、负,不如预测更细颗粒的目标——双方各自的进球数。足球的进球数在相当好的近似下服从泊松分布,这是对固定时间窗口内相对罕见事件发生次数的标准建模方式。
预测进球而非赛果,使后续一切成为可能。一旦模型能为任意对阵给出合理的比分,大家真正关心的“谁能出线、谁能捧杯”等问题,就可通过对这些比分进行上千次模拟来回答。
每场比赛由一组小而精心挑选的特征描述:
所有特征都严格避免信息泄露,意味着仅使用开球前可获得的信息。听起来显而易见,但这恰恰是最容易让模型在测试中“神乎其神”、现实中却崩盘的坑之一。
一个未被采纳的想法:我原计划基于比赛内统计对球队聚类,构建一组“打法风格”特征,这是一次无监督学习尝试。实际中,球队并未分成有意义的群组;与其喂给模型噪声,不如舍弃它。负面结果也是结果。
当数据以滚动方式从两个来源到达,从原始文件到可用于建模的特征的路径必须每次都完全一致。这正是勋章式架构所提供的:将数据分为三层:
各层逐级馈送,因此一旦出现异常,我可以逐层回溯而非一次性解开所有结。为使整条路径可复现,我使用 DVC(数据版本控制)。每当有新赛果到来,运行一次 dvc repro 即可从铜层重建银层与金层;仅当输入发生变化时才会重跑相应步骤,并为产出的数据集打版本,以便精确还原任意早期状态。
预测进球是个研究充分的问题,没有单一显而易见的工具。因此,我没有先入为主,而是构建了十个模型让它们同台竞争。
这十个模型覆盖五大家族外加一个简单基线。您无需了解各自内部细节;关键在于它们对进球生成机制的假设截然不同。
| 家族 | 模型 | 核心思想 |
|---|---|---|
| 基线 | 平均速率泊松 | 假设每支球队仅按长期平均水平进球,忽略所有特征。是其他模型需要超越的下限。 |
| 统计 | 二元泊松、负二项 | 直接用适合计数事件的分布来建模双方进球数。 |
| 贝叶斯 | 贝叶斯泊松(MCMC) | 与上述计数思路相同,但能为每个估计给出完整的不确定性范围。计算代价高得多:拟合速度约比其他模型慢 100 倍。 |
| 时间序列 | SARIMAX | 把球队表现视为随时间推移的序列,并对其向前预测。 |
| 机器学习 | Ridge、随机森林、XGBoost | 直接从特征中学习模式,而不预设固定方程。 |
| 深度学习 | LSTM、1D CNN | 神经网络,寻找数据中的序列与局部模式。 |
有十个候选者,凭肉眼很难选出优胜者。因此每个模型都要经过三个阶段,由代码决定是否晋级。这就是基于代码的部署:模型从一个环境晋升到下一个环境依靠自动化检查而非人工微调,从而保证选择过程可复现且便于审计。
那么,谁最终胜出?以下是以 RPS(越低越好)计的完整留出集排行榜:
| 模型 | 留出集 RPS |
|---|---|
| XGBoost | 0.18289 |
| 贝叶斯泊松 | 0.18316 |
| 负二项 | 0.18373 |
| 二元泊松 | 0.18389 |
| 随机森林 | 0.18392 |
| SARIMAX | 0.18583 |
| Ridge | 0.18813 |
| LSTM | 0.19299 |
| 1D CNN | 0.20916 |
| 平均速率泊松(基线) | 0.22872 |
从这些结果中有四点值得注意:
 在实况赛事中,我不会同时运行全部十个模型,而是保留一个更小的阵容:作为参照的平均速率基线,加上三名表现最佳者。XGBoost 与贝叶斯泊松稳居前二。
在实况赛事中,我不会同时运行全部十个模型,而是保留一个更小的阵容:作为参照的平均速率基线,加上三名表现最佳者。XGBoost 与贝叶斯泊松稳居前二。
第三名几乎是平局:负二项与二元泊松仅相差 0.0002 RPS,且会随随机种子互换位置。两者在统计上无可区分,我选择了在足球预测文献中基础更扎实的二元泊松(Karlis 与 Ntzoufras,2004)。
最终阵容为 XGBoost(机器学习)、二元泊松(经典统计)与贝叶斯泊松(贝叶斯推断)。下一节将介绍这些模型如何运行、再训练,以及如何把单场预测转化为完整赛事预测。
只存在于笔记本里的模型,只有当您坐在它面前时才有用。要在为期一个月的赛事中持续预测,整个系统必须自动运行:拉取新赛果、再训练、重模拟、刷新预测,无需人工干预。这正是流水线的职责。
整个项目作为一个计划任务运行在 Google Cloud Run 上。赛前每天唤醒一次;自 6 月 11 日揭幕战起,每两小时运行一次。每次运行遵循相同流程:
dvc repro 重建银层与金层,确保特征最新。由于每一步都由定时触发的代码执行,整个赛事期间无需人工点击。新赛果进,最新预测出。
项目在赛事期间也兼作一项实验。阵容以两种并行模式运行,两者差异正是我希望用数据回答的问题:随着赛事推进进行再训练,是否能提升预测效果?
并行运行让赛后可以从两个维度比较:原始预测准确性,以及随着赛程收窄各自不确定性的消解速度。若分轮更优,则定期再训练物有所值;若冻结也能抗衡,则额外机制或许并不必要。
预测一场比赛是一回事,把它转化为“每支球队的夺冠概率”为何,则要用到蒙特卡罗模拟。
首先是推断。模型不仅预测已知赛程,还会预测 48 支球队间的所有可能对阵。听起来很多,但在锦标赛中,任何球队都有可能在淘汰赛遭遇任何对手,因此必须为每个配对准备预测。
接着要编码规则,而 2026 赛制尤其棘手。12 个小组各取前两名自动出线,同时 8 个成绩最好的第三名也晋级;这 8 支队伍分别进入哪一个 32 强签位,还取决于它们来自哪些小组。
从 12 个小组中选出 8 个的组合共有 495 种(从 12 取 8),每种组合都会产生不同的 32 强对阵方案。这没有简洁公式;FIFA 直接公布了一张对照表。因此我(准确说是我非常能干的同事 Cursor)将全部 495 种组合硬编码进一个映射,以上述官方表为依据。
"best_third_mappings": {
"EFGHIJKL": {
"74": "3F",
"77": "3G",
"79": "3E",
"80": "3K",
"81": "3I",
"82": "3H",
"85": "3J",
"87": "3L"
},
"DFGHIJKL": ...每个键(如 EFGHIJKL)列出晋级的第三名来自哪些 8 个小组;对应的值则把这些球队(3E、3F 等)放入特定的 32 强场次编号。这只是其中一条;完整映射共 495 条,每种组合一条。
三支东道主(美国、加拿大、墨西哥)需要额外处理。当东道主在本国进行比赛时,模拟会对该场次施加主场优势调整;其余场次视作中立场地。
有了预测与规则,模拟将整届赛事运行 10,000 次。每次运行遵循下列流程:
在 10,000 次模拟中,一个队伍进入决赛或捧杯的占比,就是该队的概率。一次运行只是一次猜测;一万次运行才称得上预测。
上述两种模式下的每一次运行,都会记录到 MLflow(托管在 DagsHub)。实验追踪意味着系统化记录每次运行的输入、设置、结果与输出,方便相互比较或精确复现。值得一提的包括:
训练后的模型与预测文件(赛事概率、小组排名、比赛预测)作为运行工件保存,正是这些文件为在线仪表板提供数据。至此闭环:从原始赛果,经训练与模拟,到您在线可见的数字。
最后一环在比赛结束后运行。真实赛果到来时,会对对应的预测进行评分,并与简单的平均速率基线对比。若完整模型开始不如一个对球队“一无所知”的模型,那就是漂移警讯:赛前学到的模式可能已不再符合场上发生的情况。
这类监控是任何在线预测系统的标准做法,您可在这篇关于数据漂移与模型漂移的指南中了解其检测方式。
说了这么多,下面是这些机械装置存在的意义。
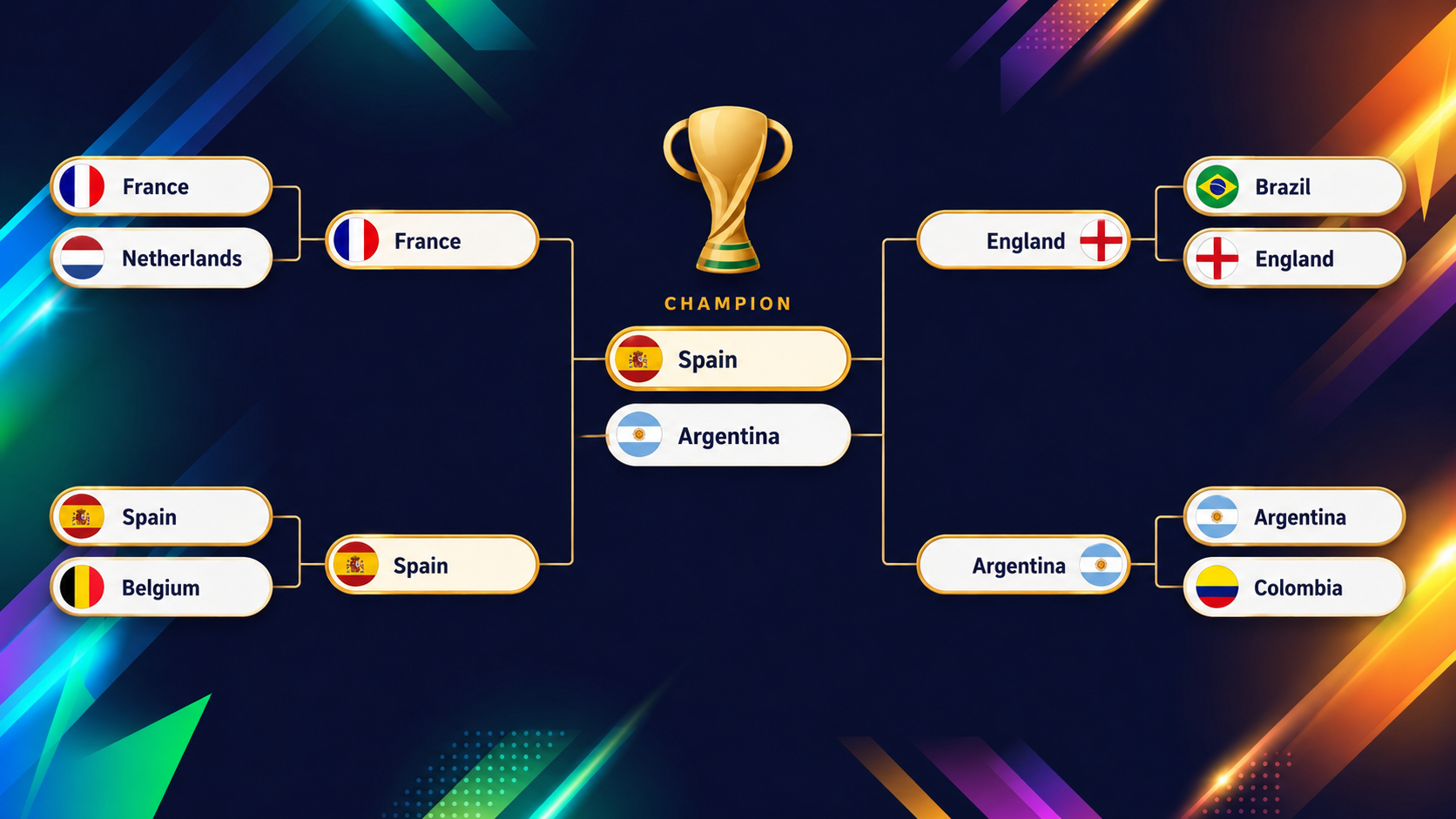
截至 2026 年 6 月 10 日(揭幕战前一天),模型在最顶端给出了明确判断,紧随其后的差距则很小。西班牙与阿根廷领跑,各有约 16% 的夺冠概率。现任世界冠军(阿根廷)与现任欧洲冠军(西班牙)位居前二,这也是模型贴近现实的一次理性校验。
其后是紧密的追赶集团:法国、英格兰、巴西与哥伦比亚构成最有可能夺冠的阵营。这些数字会随着真实赛果的落地而变化,因此请将其视为 6 月 10 日的快照,而非铁板钉钉的预言。仪表板始终显示当前数值,延迟不超过两小时。
说到这里:本文中的每个数字都来自一款会随流水线自动更新的 Streamlit 应用。您可访问 wc2026-predictions.streamlit.app,在赛事期间实时查看。共有四个主要视图:
比赛视图中有一处需要说明:个别球队会同时出现在两个可能的 32 强签位中。这不是 Bug。当一个小组过于均衡,模型无法有把握地判定某队的出线名次时,就会出现这种情况。再叠加最佳第三的不确定性,这两种结果会对应不同的淘汰赛签位。以土耳其为例,甚至曾在 16 强中“出现两次”。
下图展示了 XGBoost 模型在开赛前对后几轮(四分之一决赛至决赛)的投射:
这种模型的乐趣在于那些挑战直觉的球队,最明显的例子是美国。打开仪表板的赛事总览,您会立刻注意到美国的颜色很显眼。
作为东道主之一,主场作战似乎该有一个轻松的起步,但模型更为谨慎:他们小组出线概率仅约 54.6%,在全部 48 队中倒数第 13(别忘了有三分之二的球队能出线!),原因在于与澳大利亚、巴拉圭、土耳其同组,整体极为均衡。
更有意思的是之后的走势。即便侥幸出线,美国在随后的每一轮基本都徘徊在“五五开”。把这些硬币抛在一起,他们的总夺冠概率约为 2%,在所有球队中位列第 13。
一个小组出线概率排名倒数第 13、而夺冠概率排名正数第 13 的队,几乎就是“抛硬币队”的完美定义:从不是热门,也从未出局。
这个项目工作量不小,覆盖面也远超一篇文章所能容纳。仓库里还有许多本文未涉及的内容:完整的候选模型集合、特征工程细节,以及维系一切运行的编排等。
目前,模型已经给出了选择,赛事将给出裁决。无论您是为 MLOps 而来,还是为足球而来,都希望您能和我一样享受它的展开。随着比赛推进,您可以关注实时预测,看看这些预测经得起多少考验。
如果您想更深入了解文中提到的一些概念,推荐学习我们的 MLOps 概念 课程。